TensorFlow Serving是google开源的一个适用于部署机器学习模型,具有灵活、高性能、可用于生产环境的模型框架。
它支持模型版本控制和回滚;支持并发;支持多模型部署;支持模型热更新等,由于这些特性,使得我们不需要为部署线上服务而操心,只需要训练好线下模型即可。
同时,TensorFlow Serving还提供gRPC和REST API两种接口访问形式,其中gRPC接口对应的端口号为8500,而REST API对应的端口号为8501。
基于TensorFlow Serving的持续集成框架还是挺简明的,基本分三个步骤:
模型训练:这是大家最熟悉的部分,主要包括数据的收集和清洗、模型的训练、评测和优化;
模型上线:前一个步骤训练好的模型在TF Server中上线;
服务使用:客户端通过gRPC和RESTfull API两种方式同TF Servering端进行通信,并获取服务。
本文从实例出发,详细介绍TensorFlow Serving基础用法。主要包括以下几方面内容:
- TensorFlow Serving安装
- 将ckpt模型转换为pb模型
- 模型部署
- 多模型部署
- 新增模型
- 可能出现的错误
1. TensorFlow Serving安装
目前TensorFlow Serving提供Docker、APT(二进制安装)和源码编译三种安装方式,其中Docker方式的安装相对来说较为简单,而且对后期项目部署的环境依赖不强,项目部署与迁移较为容易,推荐使用Docker方式进行TensorFlow Serving的安装。
其中关于docker的安装方式的基本实用方法,请参考 docker从入门到实践
1.1. 拉取镜像
docker pull tensorflow/serving
1.2. 下载官方代码
mkdir -p /tmp/tfserving
cd /tmp/tfserving
git clone https://github.com/tensorflow/serving
1.3. 运行TF Serving
docker run -p 8501:8501 --mount type=bind,source=/home/docker_AI/tfserving/serving/tensorflow_serving/servables/tensorflow/testdata/saved_model_half_plus_two_cpu,target=/models/half_plus_two -e MODEL_NAME=half_plus_two -t tensorflow/serving &
参数说明
--mount: 表示要进行挂载
source: 指定要运行部署的模型地址, 也就是挂载的源,这个是在宿主机上的servable模型目录(pb格式模型而不是checkpoint模型)
target: 这个是要挂载的目标位置,也就是挂载到docker容器中的哪个位置,这是docker容器中的目录,模型默认挂在/models/目录下,如果改变路径会出现找不到model的错误
-t: 指定的是挂载到哪个容器
-d: 后台运行
-p: 指定主机到docker容器的端口映射
-e: 环境变量
-v: docker数据卷
--name: 指定容器name,后续使用比用container_id更方便
&: 后台运行
1.4. 客户端验证
curl -d '{"instances": [1.0, 2.0, 5.0]}' -X POST http://localhost:8501/v1/models/half_plus_two:predict
返回结果
{ "predictions": [2.5, 3.0, 4.5] }
2. 将ckpt模型转换为pb模型
TensorFlow Serving安装完成,并且示例模型也加载成功,此时就需要加载自己训练的模型到该框架中,实现自定义模型部署与接口调用。
然而我们在用TensorFlow训练模型的时候,常用saver.save和saver.restore来进行模型的保存与导入。
# 保存模型
model = create_model(config)
model.saver.save(sess, checkpoint_path)
# 导入模型
model = create_model(config)
model.saver.restore(session, path+'/ner.ckpt')
此方式保存的模型输出文件格式如下
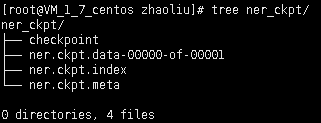
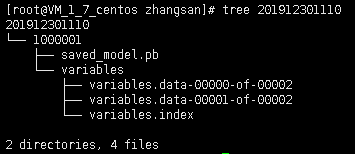
然而TensorFlow Serving中需要的模型格式如下,这就需要我们将TensorFlow训练的ckpt模型转换为如下图所示的pb模型格式。
经过不(多)懈(次)努(百)力(度),终于转换成功。先贴出源码,以供参考。
在转换的过程中需要用到模型中定义的操作名称,需要通过graph.get_operation_by_name来获取操作名称对应的变量,所以最好是在构建模型的时候给每个输入输出变量定义一个名字是很有必要的。
当不确定graph中变量名字的时候,可以输出图中每个节点的名字(在源码中注释掉了)。
for node in graph.as_graph_def().node:
print(node.name)
ps: 网上虽然有较多的博客介绍此类模型转换,但好多不可用(有可能过时了),最后在该博文https://www.jianshu.com/p/d11a5c3dc757中找到兼容版本,在此感谢!
# -*- coding: utf-8 -*-
# @Time : 2019/12/27 10:43
# @Author : tianyunzqs
# @Description :
import tensorflow as tf
def restore_and_save(input_checkpoint, export_path):
checkpoint_file = tf.train.latest_checkpoint(input_checkpoint)
graph = tf.Graph()
with graph.as_default():
session_conf = tf.ConfigProto(allow_soft_placement=True, log_device_placement=False)
sess = tf.Session(config=session_conf)
with sess.as_default():
# 载入保存好的meta graph,恢复图中变量,通过SavedModelBuilder保存可部署的模型
saver = tf.train.import_meta_graph("{}.meta".format(checkpoint_file))
saver.restore(sess, checkpoint_file)
print(graph.get_name_scope())
# for node in graph.as_graph_def().node:
# print(node.name)
builder = tf.saved_model.builder.SavedModelBuilder(export_path)
# 建立签名映射,需要包括计算图中的placeholder(ChatInputs, SegInputs, Dropout)和
# 我们需要的结果(project/logits,crf_loss/transitions)
"""
build_tensor_info
建立一个基于提供的参数构造的TensorInfo protocol buffer,
输入:tensorflow graph中的tensor;
输出:基于提供的参数(tensor)构建的包含TensorInfo的protocol buffer
get_operation_by_name
通过name获取checkpoint中保存的变量,能够进行这一步的前提是在模型保存的时候给对应的变量赋予name
"""
char_inputs = tf.saved_model.utils.build_tensor_info(
graph.get_operation_by_name("ChatInputs").outputs[0])
seg_inputs = tf.saved_model.utils.build_tensor_info(
graph.get_operation_by_name("SegInputs").outputs[0])
dropout = tf.saved_model.utils.build_tensor_info(
graph.get_operation_by_name("Dropout").outputs[0])
logits = tf.saved_model.utils.build_tensor_info(
graph.get_operation_by_name("project/Reshape").outputs[0])
transition = tf.saved_model.utils.build_tensor_info(
graph.get_operation_by_name("crf_loss/transitions").outputs[0])
flag = tf.saved_model.utils.build_tensor_info(
graph.get_operation_by_name("ModelFlag").outputs[0])
"""
signature_constants
SavedModel保存和恢复操作的签名常量。
在序列标注的任务中,这里的method_name是"tensorflow/serving/predict"
"""
# 定义模型的输入输出,建立调用接口与tensor签名之间的映射
labeling_signature = (
tf.saved_model.signature_def_utils.build_signature_def(
inputs={
"charinputs": char_inputs,
"dropout": dropout,
"seginputs": seg_inputs,
},
outputs={
"logits": logits,
"transitions": transition,
"flag": flag
},
method_name="tensorflow/serving/predict"
))
"""
tf.group
创建一个将多个操作分组的操作,返回一个可以执行所有输入的操作
"""
# legacy_init_op = tf.group(tf.tables_initializer(), name='legacy_init_op')
"""
add_meta_graph_and_variables
建立一个Saver来保存session中的变量,输出对应的原图的定义,这个函数假设保存的变量已经被初始化;
对于一个SavedModelBuilder,这个API必须被调用一次来保存meta graph;
对于后面添加的图结构,可以使用函数 add_meta_graph()来进行添加
"""
# 建立模型名称与模型签名之间的映射
builder.add_meta_graph_and_variables(
sess, [tf.saved_model.tag_constants.SERVING],
# 保存模型的方法名,与客户端的request.model_spec.signature_name对应
signature_def_map={
tf.saved_model.signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY:
labeling_signature
})
builder.save()
print("Build Done")
# 模型格式转换
restore_and_save(
r'D:/pyworkspace/201912301350/ner_ckpt',
r'D:/pyworkspace/201912301350/ner_ckpt2'
)
3. 模型部署
ckpt模型转换成TensorFlow Serving可识别的pb模型后,需要将模型挂载到该框架中,以供后续接口调用。由于我们是docker方式安装的TensorFlow Serving,故只需启动一个docker容器即可。
docker run -p 8501:8501 --mount type=bind,source=/home/docker_AI/ner_origin,target=/models/ner_origin -e MODEL_NAME=ner_origin -t tensorflow/serving &

TensorFlow Serving启动画面中显示运行了两个接口,一个是REST API 接口(端口号 8501),另一个是gRPC接口(端口号 8500)
gRPC是HTTP/2协议,REST API 是HTTP/1协议;
gRPC只有POST/GET两种请求方式,REST API还有其余很多种 列如 PUT/DELETE 等
TensorFlow Serving启动完成后,可查看该模型的输入输出元数据格式。
curl http://localhost:8501/v1/models/ner_origin/metadata
根据第2节模型转换中定义的输入输出格式,或者metadata输入输出格式,组织我们在预测时的数据,利用curl命令请求模型预测接口predict
curl -d '{"instances": [{"charinputs":[804, 209, 793, 1428, 603], "seginputs": [1, 3, 0, 1, 3], "dropout": 1.0}]}' -X POST http://localhost:8501/v1/models/ner_origin:predict
如果通过python代码请求,其实就是一个request请求
class NumpyEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, np.ndarray):
return obj.tolist()
return json.JSONEncoder.default(self, obj)
def tfserving_http():
p_data = {"charinputs": charinputs, "dropout": 1.0, "seginputs": seginputs}
param = {"instances": [p_data]}
param = json.dumps(param, cls=NumpyEncoder)
res = requests.post('http://62.234.66.244:8501/v1/models/admin:predict', data=param)
print(res.json())
如果将启动端口8501换成8500,也即将REST api请求方式换成gRPC方式,则其python请求代码
def tfserving_grpc():
server = 'ip:8500'
channel = grpc.insecure_channel(server)
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
request = predict_pb2.PredictRequest()
request.model_spec.name = 'admin'
# request.model_spec.version.value = 1000001
request.model_spec.signature_name = 'serving_default'
request.inputs["charinputs"].CopyFrom(tf.contrib.util.make_tensor_proto(charinputs))
request.inputs["seginputs"].CopyFrom(tf.contrib.util.make_tensor_proto(seginputs))
request.inputs["dropout"].CopyFrom(tf.contrib.util.make_tensor_proto(1.0))
response = stub.Predict(request, 10.0)
results = {}
for key in response.outputs:
tensor_proto = response.outputs[key]
results[key] = tf.contrib.util.make_ndarray(tensor_proto)
logits = results["logits"]
transitions = results["transitions"]
flag = results["flag"]
print(logits)
print(transitions)
print(flag)
输出
{
"predictions": [
{
"logits": [
[2.53046727, 0.429246396, -0.546410441, -0.132351086, -0.622273862, -0.813277066, -0.831595659],
[4.16336536, 0.640145, -0.640701056, -0.545457542, -0.783653438, -1.21482062, -1.08649766],
[4.69853115, 0.762846708, -0.855348706, -0.65174526, -0.813595951, -1.38415384, -1.11371565],
[4.0974865, 0.742037654, -1.00731039, -0.278052419, -0.915860176, -0.954916656, -0.971908212],
[4.47188616, 0.737567186, -0.924560308, -0.578656435, -0.661592305, -1.11467135, -1.06694698]
],
"transitions": [
[-0.0427044295, -0.32763353, 0.349263608, 0.310742259, -0.485399961, -0.0757263377, 0.311962426, -0.475627959],
[-0.270459533, 0.495500267, -0.201387107, -0.0261076558, 0.200797811, -0.607848883, 0.103821024, -0.332163453],
[0.157096833, 0.523860455, 0.140555486, 0.0998892561, 0.179801, 0.587823749, 0.389340162, -0.398559749],
[-0.35563, 0.547142625, -0.556600034, 0.478965372, -0.401651204, 0.237679332, -0.163087636, 0.0659950376],
[0.381318182, 0.46145615, -0.474834502, 0.15242289, -0.503959656, 0.427230358, 0.191766813, 0.320839047],
[-0.0843381807, 0.228642449, -0.0705256537, -0.142665327, 0.269085824, 0.491911, -0.0604625307, 0.0279729366],
[-0.353649795, 0.344409823, -0.501548529, -0.445917934, -0.206717357, -0.269293785, 0.0649886504, -0.42325142],
[-0.24967739, 0.0976051763, -0.427930981, -0.343548924, -0.309804618, -0.438262403, 0.561979473, -0.549243093]
]
}
]
}
如果出现如下错误,请参考错误1
{ "error": "Tensor name: transitions has inconsistent batch size: 8 expecting: 1" }
4. 多模型部署
在上一节中我们介绍了TensorFlow Serving单模型部署过程,然而在实际生产过程中,必然存在多模型场景,如模型1用来抽取实体,模型2用来分类文本,模型3用来抽取关系。。。同样会存在多个版本的模型。
有了单模型部署基础,再来部署多模型就显得简单多了。TensorFlow Serving提供配置文件models.config(文件名可自行修改)对多个模型进行相关配置,配置完成后直接输入启动命令即可。
docker run -p 8500:8500 --mount type=bind,source=/home/docker_AI/ner_models/,target=/models/ner_models -t tensorflow/serving --model_config_file=/models/ner_models/models.config
多模型的部署存在以下2种情况:
多(单)用户单模型:一个或多个用户均只拥有一个模型,如果模型路径中存在多个模型,则取最新的模型。
tensorflow_serving自动启用新模型,同时卸载旧模型。
新模型的版本号,必须大于旧版本。tensorflow_serving默认读取版本号最大的模型。
多(单)用户多模型:一个或多个用户拥有一个或多个模型
4.1 多(单)用户单模型
当出现模型版本更新的时候,只需要将新模型设置版本号放于模型保存路径下即可,tensorflow_serving自动启用新模型,同时卸载旧模型。
其模型文件目录结构图及配置文件如下
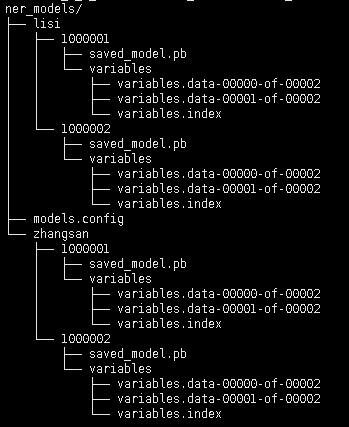
多(单)用户单模型配置文件models.config
model_config_list:{
config:{
name: "zhangsan",
base_path: "/models/ner_models/zhangsan",
model_platform: "tensorflow"
},
config: {
name: "lisi",
base_path: "/models/ner_models/lisi",
model_platform: "tensorflow"
}
}
4.2 多(单)用户多模型
当多个或单个用户训练多个模型都要部署时,也即每个模型都不能被覆盖,此时只需要更改模型文件的目录结构和模型配置文件即可实现。
其模型文件目录结构图及配置文件如下
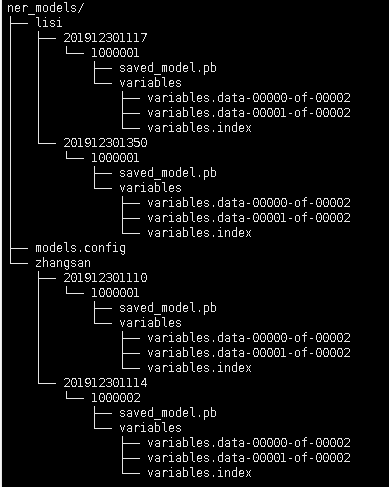
多(单)用户多模型配置文件models.config
model_config_list:{
config:{
name: "zhangsan_201912301110",
base_path: "/models/ner_models/zhangsan/201912301110",
model_platform: "tensorflow"
},
config:{
name: "zhangsan_201912301114",
base_path: "/models/ner_models/zhangsan/201912301114",
model_platform: "tensorflow"
},
config: {
name: "lisi_201912301117",
base_path: "/models/ner_models/lisi/201912301117",
model_platform: "tensorflow"
}
}
4.3. 接口请求
多模型部署完成后,可参考 模型部署 章节中接口请求方式来请求对应模型的接口。
5. 新增模型
模型部署上线完成后,突然在某一天需要扩展系统功能,需要添加一个或多个新的模型以满足业务需求,而此时系统已经不能随便重启,需要在不影响现有业务、用户零感知的前提下扩展系统功能。这该如何实现呢???
经过不(多)懈(次)努(百)力(度),在Stack Overflow中找到了对应的解答,贴上链接以供参考,同时贴上模型更新的代码。代码主要功能就是更新模型配置文件models.config,然后TensorFlow Serving根据配置文件检测新增的模型,并将其挂载上去,实现模型的新增效果。
https://stackoverflow.com/questions/54440762/tensorflow-serving-update-model-config-add-additional-models-at-runtime
def update_model(config_file, host_and_port, model_name, base_path):
channel = grpc.insecure_channel(host_and_port)
stub = model_service_pb2_grpc.ModelServiceStub(channel)
request = model_management_pb2.ReloadConfigRequest()
# read config file
config_content = open(config_file, "r").read()
model_server_config = model_server_config_pb2.ModelServerConfig()
model_server_config = text_format.Parse(text=config_content, message=model_server_config)
# create a new one config
config_list = model_server_config_pb2.ModelConfigList()
new_config = config_list.config.add()
new_config.name = model_name
new_config.base_path = base_path
new_config.model_platform = "tensorflow"
# add to origin config message
model_server_config.model_config_list.MergeFrom(config_list)
request.config.CopyFrom(model_server_config)
request_response = stub.HandleReloadConfigRequest(request, 10)
if request_response.status.error_code == 0:
open(config_file, "w").write(str(request.config))
logger.info("TF Serving config file updated.")
return True
else:
logger.error("Failed to update config file.")
logger.error(request_response.status.error_code)
logger.error(request_response.status.error_message)
return False
6. 可能出现的错误
错误1:
{ "error": "Tensor name: transitions has inconsistent batch size: 8 expecting: 1" }
产生原因:transitions变量维度是[8, 8],TensorFlow Serving在预测时,将batch_size当成了8 (预测时输入样本只有一个,其batch_size为1)。
解决方法:将transitions变量维度转换成[1, 8, 8],在运算过程中再将其维度转换为[8, 8]
发生这个错误的时候,百度出来了这样一个问题
https://github.com/tensorflow/serving/issues/1047
然而这个是TensorFlow Serving本身的问题,还是没有解决到我的问题。但是里面有错误提示出现的源码,
https://github.com/tensorflow/serving/blob/master/tensorflow_serving/util/json_tensor.cc#L979
const int cur_batch_size = tensor.tensor_shape().dim(0).size();
if (cur_batch_size < 1) {
return errors::InvalidArgument(
"Tensor name: ", name, " has invalid batch size: ", cur_batch_size);
}
if (batch_size != 0 && batch_size != cur_batch_size) {
return errors::InvalidArgument(
"Tensor name: ", name,
" has inconsistent batch size: ", cur_batch_size,
" expecting: ", batch_size);
}
从源码中我们可以看到只要保证batch_size和cur_batch_size相等即可解决该错误,于是想到了一种迂回的办法,将定义模型中的transitions变量在定义的时候将其维度变为[1, 8, 8],然而在参与计算的时候将其reshape为[8, 8]。修改过后,果然可以正常运行。现贴上相关代码
self.trans = tf.get_variable(
"transitions",
shape=[1, self.num_tags + 1, self.num_tags + 1],
initializer=self.initializer)
log_likelihood, self.trans = crf_log_likelihood(
inputs=logits,
tag_indices=targets,
transition_params=tf.reshape(self.trans, shape=[self.num_tags + 1, self.num_tags + 1]),
sequence_lengths=lengths+1)
self.trans = tf.reshape(self.trans, shape=[1, self.num_tags + 1, self.num_tags + 1])
当然,预测的时候也需要转换维度
trans = np.squeeze(self.trans.eval(session=sess))
错误2:
curl: (7) Failed to connect to ::1: No route to host
产生原因:请求路径与端口号不正确
解决方法:检查请求路径与端口号是否正确。
我这边是由于端口号不一致导致该错误
错误3:
curl: (56) Recv failure: Connection reset by peer
产生原因:tensorflow/serving挂载了多个模型到同一个容器中,而且多个端口
解决方法:杀死其他运行容器,只启动一个,端口号指定5001
错误4:
docker: Error response from daemon: driver failed programming external connectivity on endpoint serene_poincare (0373ce708fe3f7c8cd4ce5420134750843bcd849321c442d4935411ef3fa01b5): Bind for 0.0.0.0:8501 failed: port is already allocated.
产生原因:端口号被占用
解决方法:更换端口号
错误5:
2019-12-27 07:33:11.635432: I tensorflow_serving/model_servers/server_core.cc:462] Adding/updating models.
2019-12-27 07:33:11.635457: I tensorflow_serving/model_servers/server_core.cc:573] (Re-)adding model: ner_cpu
2019-12-27 07:33:11.736358: I tensorflow_serving/core/basic_manager.cc:739] Successfully reserved resources to load servable {name: ner_cpu version: 123}
2019-12-27 07:33:11.736403: I tensorflow_serving/core/loader_harness.cc:66] Approving load for servable version {name: ner_cpu version: 123}
2019-12-27 07:33:11.736417: I tensorflow_serving/core/loader_harness.cc:74] Loading servable version {name: ner_cpu version: 123}
2019-12-27 07:33:11.736449: I external/org_tensorflow/tensorflow/cc/saved_model/reader.cc:31] Reading SavedModel from: /models/ner_cpu/00000123
2019-12-27 07:33:11.753845: I external/org_tensorflow/tensorflow/cc/saved_model/reader.cc:54] Reading meta graph with tags { serve }
2019-12-27 07:33:11.758208: I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc:311] SavedModel load for tags { serve }; Status: fail. Took 21748 microseconds.
2019-12-27 07:33:11.758254: E tensorflow_serving/util/retrier.cc:37] Loading servable: {name: ner_cpu version: 123} failed: Not found: Could not find meta graph def matching supplied tags: { serve }. To inspect available tag-sets in the SavedModel, please use the SavedModel CLI: `saved_model_cli`
产生原因:pb模型转换出错
解决方法:重新转换,参考第2节 将ckpt模型转换为pb模型。
错误6:
Traceback (most recent call last):
File "F:\Python3.6\setup\lib\site-packages\grpc\beta\_client_adaptations.py", line 193, in _blocking_unary_unary
credentials=_credentials(protocol_options))
File "F:\Python3.6\setup\lib\site-packages\grpc\_channel.py", line 550, in __call__
return _end_unary_response_blocking(state, call, False, None)
File "F:\Python3.6\setup\lib\site-packages\grpc\_channel.py", line 467, in _end_unary_response_blocking
raise _Rendezvous(state, None, None, deadline)
grpc._channel._Rendezvous: <_Rendezvous of RPC that terminated with:
status = StatusCode.UNAVAILABLE
details = "Trying to connect an http1.x server"
debug_error_string = "{"created":"@1577432532.376000000","description":"Error received from peer","file":"src/core/lib/surface/call.cc","file_line":1036,"grpc_message":"Trying to connect an http1.x server","grpc_status":14}"
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "E:/pyworkspace/AIMiddlePlatform/ChineseNER/ckpt_to_pb.py", line 154, in
response = stub.Predict(request, 10.0)
File "F:\Python3.6\setup\lib\site-packages\grpc\beta\_client_adaptations.py", line 309, in __call__
self._request_serializer, self._response_deserializer)
File "F:\Python3.6\setup\lib\site-packages\grpc\beta\_client_adaptations.py", line 195, in _blocking_unary_unary
raise _abortion_error(rpc_error_call)
grpc.framework.interfaces.face.face.AbortionError: AbortionError(code=StatusCode.UNAVAILABLE, details="Trying to connect an http1.x server")
产生原因:grpc和http的端口号不一样
解决方法:https://stackoverflow.com/questions/53857989/tensorflow-predict-grpc-not-working-but-restful-api-working-fine
错误7:
Traceback (most recent call last):
File "E:/pyworkspace/AIMiddlePlatform/ChineseNER/ckpt_to_pb.py", line 168, in
response = stub.Predict(request, 10.0)
File "F:\Python3.6\setup\lib\site-packages\grpc\_channel.py", line 550, in __call__
return _end_unary_response_blocking(state, call, False, None)
File "F:\Python3.6\setup\lib\site-packages\grpc\_channel.py", line 467, in _end_unary_response_blocking
raise _Rendezvous(state, None, None, deadline)
grpc._channel._Rendezvous: <_Rendezvous of RPC that terminated with:
status = StatusCode.INVALID_ARGUMENT
details = "Invalid reduction dimension (1 for input with 1 dimension(s)
[[{{node Sum}}]]"
debug_error_string = "{"created":"@1577436000.370000000","description":"Error received from peer","file":"src/core/lib/surface/call.cc","file_line":1036,"grpc_message":"Invalid reduction dimension (1 for input with 1 dimension(s)\n\t [[{{node Sum}}]]","grpc_status":3}"
产生原因:TensorFlow Serving输入的是一个向量,而模型graph图中定义的是一个矩阵类型的tensor,维度[batch_size, num_steps],相当于降了一维。
解决方法:在预测时候,将输入变量的维度增加一维即可。
产生该问题后,还是想从网上查找答案,然而经过一番不懈努力,终于放弃了,没找到 ~_~
于是干脆从问题本身出发寻找原因,其实错误提示已经很明显了,只是思考角度没到位。找到问题原因后,修改模型代码,验证猜想,问题解决 ^_^
只需要将输入变量增加一个维度即可,现贴上代码
self.char_inputs = tf.cond(tf.greater(self.dropout, tf.constant(0.9999999)),
lambda: tf.reshape(self.char_inputs, shape=[1, -1]), lambda: self.char_inputs)
self.seg_inputs = tf.cond(tf.greater(self.dropout, tf.constant(0.9999999)),
lambda: tf.reshape(self.seg_inputs, shape=[1, -1]), lambda: self.seg_inputs)
错误8
Traceback (most recent call last):
File "/home/wuyenan/LiZeB/tensorflow-serving-example/python/grpc_mnist_client.py", line 55, in
run(args.host, args.port, args.image, args.model, args.signature_name)
File "/home/wuyenan/LiZeB/tensorflow-serving-example/python/grpc_mnist_client.py", line 33, in run
result = stub.Predict(request, 10.0)
File "/home/wuyenan/anaconda3/envs/tensorflow-serving-example/lib/python2.7/site-packages/grpc/_channel.py", line 565, in __call__
return _end_unary_response_blocking(state, call, False, None)
File "/home/wuyenan/anaconda3/envs/tensorflow-serving-example/lib/python2.7/site-packages/grpc/_channel.py", line 467, in _end_unary_response_blocking
raise _Rendezvous(state, None, None, deadline)
grpc._channel._Rendezvous: <_Rendezvous of RPC that terminated with:
status = StatusCode.FAILED_PRECONDITION
details = "Serving signature key "serving_default" not found."
debug_error_string = "{"created":"@1562657172.223509298","description":"Error received from peer ipv4:127.0.0.1:8500","file":"src/core/lib/surface/call.cc","file_line":1052,"grpc_message":"Serving signature key "serving_default" not found.","grpc_status":9}"
产生原因:服务签名信息对不上
解决方法:saved_model_cli show --dir /tmp/saved_model_dir --tag_set serve命令查看服务签名,详情见原博文https://blog.csdn.net/weixin_38498050/article/details/95206413。