视频编解码之H.264快速入门
视频编解码快速学习入门
- 视频编解码快速学习入门
- 架构
- 编码
- 解码
- 帧内宏块预测
- 初认识
- 4X4亮度块预测模式
- 16X16亮度块预测模式
- 8X8色度块预测模式
- 帧内预测模式编码
- P片帧间预测
- 初认识
- 树结构的运动补偿
- 次像素运动矢量
- 运动矢量预测
- 变换和量化
- 初认识
- 4X4残差变换和量化块0-1518-25
- 从4X4 DCT推出的整数变换
- 量化
- 改变标度逆量化
- 4X4亮度DC系数变换和量化只在16X16 帧内模式中使用
- 2X2色度直流系数变换和量化
- 完整的变换量化逆量化和逆变换过程
- 重建滤镜
- 架构
本学习心得是看通过学习H.264MPEG4 Part 10 White Paper 而来,视频编解码H.264现在已经非常普遍,而且现在H.265已经出来了。但是H.265主要是在宏块设置上与H.264有了很大的区别,所以学会了H.264再学习H.265那么就相对简单:
架构
编码
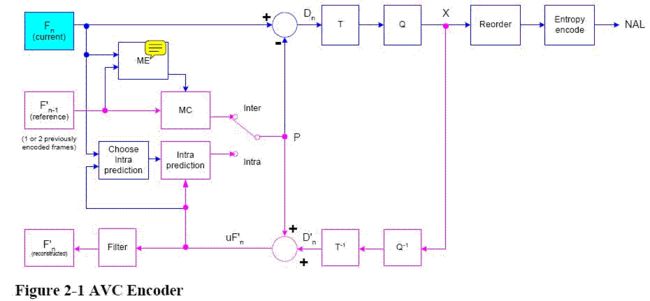
蓝色的就是前向路径,用于生成最终的宏块。当一个输入帧Fn被提交编码。该帧以宏块(相当于16X16像素的原始图像)为单位来进行处理。 每个宏块被编码成帧内模式或帧间模式。在这两种情况下,会产生一个基于重建帧的预测宏块P。在帧内模式下,P根据之前已经编码,解码,重建的当前帧n中的采样产生(图中以uF’n表示。注意是未经过滤的采样用来产生P)。在帧间模式下,P根据采用一个或多个参考帧的运动补偿预测来产生。在图中,参考帧表示为之前已经编码的帧F’n-1;然而,每个宏块的预测可能根据过去或将来(以时间为序)的一或多个已经编码并重构的帧来产生。
粉色的就是重建路径。为了编码更进一步的宏块,需通过解码宏块量化系数X来重建一帧。系数X被重新调整(Q-1)并且进行逆变换(T-1)来产生一个不同的宏块Dn’,这与原始的差异宏块Dn不同;它在量化过程中有了损耗,所以Dn’是Dn的一个失真版本。预测宏块P被加到Dn’中来创建一个重建宏块uF’n(原始宏块的一个失真版本)。为了减少阻断失真的影响使用了一个滤镜,重建参考帧从一系列的宏块F’n中创建。
解码

解码器从NAL(网络抽象层)接收压缩的比特流。数据元素被熵解码并且重新排列来产生一个量化系数集X。它们被重新调整并进行逆转换来生成Dn’(与编码器中所示的Dn’相同)。使用比特流中解码出的头部信息,解码器生成一个预测宏块P,与在编码器中生成的原始预测帧P相同。P被加到Dn’中来生成uFn’,uF’n经过过滤生成了解码的宏块Fn’。
编码器的重建路径应该从图示和上面的讨论中清除,它实际上是为了确保编码器和解码器使用相同的参考帧来生成预测帧P。如果不这样做,编码器和解码器中的预测帧P就不会相同,导致编码器和解码器之间存在一个越来越大的误差或是“偏移”。
ITU-T Rec. H.264 / ISO/IEC 11496-10, “Advanced Video Coding”, Final Committee Draft, Document JVTE022,September 2002
参考以上论文,可以加深理解。以上就是H.264的大概架构,由编码和解码两个部分组成。接下来介绍视频编解码的各个部分。
帧内宏块预测
初认识
如果一个块或宏块按帧内模式编码,会基于之前已经编码并重构(未过滤)的块生成一个预测宏块。这个预测块P被从之前已经编码的当前宏块中减去。对于亮度(luma)采样,P可能为每个4X4子块或16X16宏块产生。对于每个4X4的亮度块总共有9种可选的预测模式;对于16X16亮度块有4种可供选择的模式;而每个4X4的色度块只有一种预测模式(注:此处当理解成只有一种8X8的色度分块模式)。
4X4亮度块预测模式
Figure 1显示在一个QCIF帧中的一个亮度宏块和一个需要进行预测的4X4的亮度块。该块左边和上边的采样(即像素对应值)已经被编码、重建并且因而能够在编码器和解码器中用来生成预测块。

基于Figure 2中标识为A-M的采样计算出预测块P。注意在有些情况下,不是所有的采样A-M都在当前切片(即分块)中可用:为了保持切片解码的独立性,只有在当前切片中可用的采样才会用来进行预测。直流(DC)预测(模式2)根据A-M中的哪些采样可用来修改;其它模式(1-8)或许只能使用在所有预测中用到的采样都可用的情况(除了E,F,G,H不可用的情况。这些值可从D中复制)。

Figure 3中的箭头标出了每种模式下预测的方向。在模式3-8中,预测值根据预测采样A-Q的加权平均来产生。编码器可能为每个块选择一种预测模式来减小P和被编码块之间的误差。

例:对Figure 1中所示的4X4块使用9种预测模式(0-8)计算。Figure 4显示了每种预测生成的预测块P。每种预测模式的绝对误差和(SAE)表明了预测误差的规模。在这种例子中,与实际当前块匹配最好的是模式7(垂直向左),因为这种模式给出了最小的SAE;经过视觉上的比较可以看出P块与原始的4X4块非常相似。

16X16亮度块预测模式
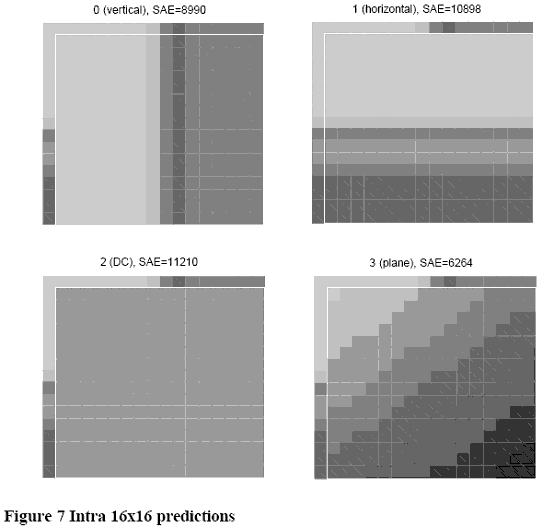
16X16亮度块预测模式是一个上述4X4亮度块预测模式的一种替代方法,整个16X16的亮度块可以被预测。有四种模式可以使用。如Figure 5所示:

模式0(垂直):从块上部的采样推出(H)。
模式1(水平):从块左侧的采样推出(V)。
模式2(直流):从块上部和左侧的采样的均值推出(H+V)
模式3(平面):对块上部和左侧的采样H和V使用一个线性“平面”函数,这在平滑的亮度区域中效果最好。
Figure 6 显示了一个左侧和上部采样已经编码的亮度宏块。预测结果(Figure 7)表明最佳匹配由模式3给出。帧内16X16模式在分布均匀的图像区域中效果比较好。

8X8色度块预测模式
一个宏块的每个8X8的色度分量从之前已编码重构的上部和(或)左侧的色度采样中预测。色度块的四种预测模式和第3部分中描述(Figure 5所示)的16X16亮度块预测模式非常相似,除了模式号不同:直流(模式0),横向(模式1),垂直(模式2)和平面(模式3)。相同的预测模式在色度块中也始终适用(色度和亮度的相同预测模式的预测方法相同)。
注意:如果亮度分量中的8X8块被编码成帧内预测模式,色度块也要编码成帧内预测模式。
帧内预测模式编码
每个4X4块所选择的帧内预测模式必须传递给解码器,这就要求一个大量的位来存储。然而,相邻4X4块帧内预测模式高度相关。例如,如果Figure 8中的之前已经编码的4X4块A和B使用模式2,很可能块C(当前编码块)的最佳预测模式也是模式2。

对每个当前块C,编码器和解码器计算出最可能模式(most_probable_mode).如果A和B都使用了4X4帧内预测模式并且都包含在当前切片中,最可能模式就是A和B中模式号最小的预测模式;否则最可能模式设置为2(直流预测)。
编码器给每个4X4块发送标志use_most_probable_mode,如果标志为”1”,参数most_probable_mode被使用。如果标志为”0”,另一个参数remaining_mode_selector被发送,表明需改变模式。如果remaining_mode_selector比当前most_probable_mode小,预测模式就设置成remaining_mode_selector; 否则预测模式设置成remaining_mode_selector+1.采用这种方法,remaining_mode_selector只需使用8个值(0到7)来标志当前帧内预测模式(0到8)。
参考论文:
ITU-T Rec. H.264 / ISO/IEC 11496-10, “Advanced Video Coding”, Final Committee Draft, Document JVTF100,December 2002
Iain E G Richardson, “H.264 and MPEG-4 Video Compression”, John Wiley & Sons, published late 2003
P片帧间预测
初认识
帧间预测从一个或多个之前已经编码的视频帧中生成一个预测模型。这个模型由对参考帧中的采样进行漂移产生(运动补偿预测)。AVC CODEC 使用基于块的运动补偿,与从H.261以来的主要编码标准中采用的规则相同。然而,它与早期标准有着重要的区别:(1) 支持多种块大小(最小4X4)的预测;(2) 细粒度的次像素运动矢量(量度分量可精确到1/4像素)。
树结构的运动补偿
AVC对亮度采样支持16X16到4X4之间多种块大小的运动补偿。每个宏块(16X16采样)的亮度分量能以Figure2-1中所示的4种方式分割:16X16,16X8,8X16或8X8。每个细分区域是一个宏块分区。如果选择8X8分割模式,宏块内的四个8X8宏块分区都能够以4种方式再次分割。

如图Figure2-2所示:8X8,8X4,4X8或4X4(称作宏块子分区)。这些分区和子分区使得每个宏块内都可以有很多种组合方式。这种将宏块分割成不同大小运动补偿子块的方法称作树结构运动补偿。

每个分区或子分区都有一个独立的运动矢量。每个运动矢量必须编码并传输;另外,分区(分割方式)的选择也必须被编码到压流的比特流中。选择大的分区(如16X16,16X8,8X16)意味着只需很少的比特来标记运动矢量的选择和分区的类型;然而,运动补偿残差可能包含了大量的帧中高细节部分信息。选择一个小的分区大小(8X4,4X4等等)可以在运动补偿后得到一个较小的残差,但它需要更多的比特来标记运动矢量和分区的类型。因此分区大小的选择对压缩效果有着很大的影响。通常情况下,一个大的分区适用于帧内分布均匀的区域而一个小的分区将有利于细节区域的描述。
宏块(Cr和Cb)中每个色度分量的分辨率为亮度分量的一半。每个色度块和亮度块的分割方式相同,只是分区大小是水平和垂直方向的分辨率的一半(如一个8X16亮度分区对应一个4X8的色度分区;一个8X4亮度分区对应一个4X2的色度分区)。每个运动矢量(每个分区一个)的水平和垂直分量运用到色度块上时减半。
例:Figure 2-3显示了一个残留帧(未经过运动补偿)。AVC参考编码器为帧的每个部分选择了“最好的”分区大小。这种分区大小尽量减小编码残差和运动矢量。为每个区域选择的宏块分区显示在残留帧上(图示)。在帧间变化很小的区域(残留帧上显示为灰色)采用16X16分区方式;在运动的细节描述部分(残留帧上显示为黑色或白色)采用较小的分区效果更好。

次像素运动矢量
帧间编码宏块的每个分区根据参考图片中的一个相同大小的区域预测。两个区域间的偏移(运动矢量)的分辨率(亮度分量)为1/4像素。次像素位置的亮度和色度采样在参考图片中不存在,所以它们必须通过对附近的图像采样进行插补来创建。Figure 3-1给出了一个例子。当前帧(a)中的一个4X4的子分区根据参考图像的一个邻近区域来预测。如果运动矢量的水平和垂直分量为整数(b),则参考块中的相关采样实际已经存在(灰点)。如果一个或两个向量分量都为分数值(c),预测采样(灰点)根据参考帧中相邻采样(白点)间的插补产生。

次像素运动补偿的效果明显优于整数像素补偿,但是却增加了复杂性。1/4像素精度效果优于半像素精度。
在亮度分量中,半像素位置的次像素采样首先产生,它使用一个6头有限脉冲响应滤波器(6-tap Finite Impulse Response filter)从邻近的整数像素采样中插值。这意味着每个半像素采样是6个邻近整数采样的加权和。一旦所有的半像素采样可用,每个1/4像素采样通过对相邻的半像素和整数像素使用双线性插值得到。如果视频源采样比是4:2:0,色度分量需使用1/8像素采样(与亮度的1/4像素采样对应)。这些采样通过对整数像素的色度采样进行插值(线性插值)得到。
运动矢量预测
为每个分区编码一个运动矢量需要大量的比特,特别是在选择小的分区的时候。通常情况下邻近分区的运动矢量都高度相关,所以每个运动矢量可以通过相邻并且之前已经编码的分区的矢量预测。预测矢量MVp基于之前已计算出的运动矢量产生。当前矢量和预测矢量间的差异MVD被编码并传输。预测矢量MVp的生成方法取决于运动补偿块的大小和相邻矢量是否可用。“基本”预测值是当前分区或子分区相邻上部和对角线方向右下和相邻左侧的宏块分区或子分区的运动矢量的中间值。如果(a)选择16X8或8X16的分区并且(或者)(b)有些邻近分区不可用作预测值,则预测值会作出改变。如果当前宏块被跳过(未传输),则会产生一个预测矢量,即使宏块以16X16分区模式编码。
在解码器中,预测矢量MVp以相同的方式形成并加到解码后的矢量差异MVD中。若有跳过宏块,则这里没有解码矢量(MVD),这时会根据MVp的规模产生一个运动补偿宏块。
ITU-T Rec. H.264 / ISO/IEC 11496-10, “Advanced Video Coding”, Final Committee Draft, Document JVTG050,March 2003
变换和量化
初认识
每个残差宏块被传输,量化并编码。之前的标准如MPEG-1,MPEG-2,MPEG-4和H.263使用了8X8离散余弦变换(DCT)作为基本变换。H.264的基本规范使用三种变换,采用何种变换取决于被编码的残差数据:(1)对宏块内部(以16X16模式预测)的亮度直流系数4X4数组进行变换。(2)对(任何宏块中的)色度直流系数2X2数组进行变换(3)对所有其它的4X4块的残差数据进行变换。如果使用了“自适应块大小变换”选项,则根据运动补偿块大小(4X8,8X4,8X8,16X8等等)选择更进一步的变换。
宏块中的数据以图Figure 1-1中所示顺序进行传输。如果宏块以16X16帧内模式编码,则标注为“-1”的块(包含每个4X4亮度块的直流系数)首先被传输。然后,亮度残差块0-15按所示顺序传输(16X16宏块内部直流系数被设为0)。块16和块17各自包含一个来自色度分量Cb和Cr的2X2排列。最后,色度残差块18-25(直流系数为0)被发送。

4X4残差变换和量化(块0-15,18-25)
在运动补偿预测和帧内预测后对4X4残差数据块(在Figure 1-1中标志为0-15和18-25)使用这个变换。这个变换基于DCT但是有一些基本的区别:
(1)它是一个整数变换(所有的操作可以用整数算术进行,没有降低精度)。
(2)逆变换在H.264标准中已经被充分描述,如果这个描述被正确的继承,那么编码器与解码器之间不应该存在不匹配。
(3)变换的核心部分是没有乘法的,即它只需进行加、减和移位。
(4)一个缩放乘法(完整变换的一部分)被融入到量化器中(减少了总的乘法次数)。
变换和量化的整个过程可以使用16位整数算术来进行,并且每个系数只乘一次,没有降低精度。
从4X4 DCT推出的整数变换
对一个输入阵列X进行4X4 DCT变换:

在这里:

这个矩阵乘法可以被分解成下面的等价形式(等式Equation 2-2):

CXC^T(即CXC’)是一个“核心”2-D变换。E是一个比例因子矩阵,并且符号⊕(圆圈中实为X号)表示(CXC’)的每个元素与E中对应位置的比例因子相乘(用点乘代替矩阵乘法)。常量a和b与之前值相等,d=c/b(近似于0.414)。为简化变换实现过程,d被近似成0.5。为了确保变换仍然正交,b也需要进行改变。所以 a=1/2 b=(2/5)^(1/2) d=1/2。
矩阵C的第2行和第4行和矩阵C’的第2列和第4列以一个2为比例因子缩放(乘以2)并且后缩放矩阵E也被按比例缩小来进行补偿。(这就避免了核心变换CXC’中乘1/2的运算,使得使用整数算术运算不会降低精度)。最终的变换变成:

这个变换是4X4 DCT变换的一个近似变换。因为改变了因子d和b,所以新的变换的输出不会与4X4 DCT变换完全相同。
逆变换的形式为:

这次,Y的每个系数与矩阵Ei中对应位置的合适加权因子相乘,以此来进行预缩放。注意矩阵C和C’中的+/-(1/2)因子;它们可以通过一个右移来实现并且不会造成明显的精度损失,因为Y已经经过了预缩放。
正变换和逆变换都是正交的,即T^-1(T(X))=X。
量化
H.264使用了一个纯量量化器。它的定义和实现因为实际要求而变得复杂。它有以下要求:
(1)避免除法和(或)浮点算术运算。
(2)使上述的后缩放和预缩放矩阵Ef,Ei中的因子统一。
基本的正变换量化器操作如下:
Zij = round(Yij/Qstep)
Yij是上述变换的一个系数,Qstep是量化步长,Zij是一个量化系数。
标准支持的量化步长有52种,量化步长根据量化参数QP建立索引。每个量化参数对应的量化步长的值如表Table 2-1所示。注意QP每增加6,量化步长约增加一倍;QP每增加1,量化步长增加12.5%.各种各样的量化步长使得编码器可以精确,灵活的在比特率和质量之间权衡。亮度和色度的QP值可能不同,虽然两个参数的变化范围都是0-51,但QPChroma是从QPy中得来的,QPc比QPy小,QPy的值大于30。一个用户定义的QPy和QPc之间的偏移量或许可以从一个图像参数集中得到。

后缩放因子a^2,ab/2或b^2/4(Equation 2-3)是正量化器的一部分。首先,输入块X经过变换产生一个系数未经缩放的块W=CXC’。然后,每个系数Wij被量化并且缩放(在单一操作中)。
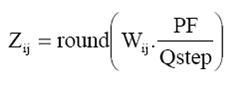
PF根据位置(i,j)来决定是为a^2,ab/2 或是b^2/4(如式Equation 2-3所示):
| Position | PF |
|---|---|
| (0,0),(2,0),(0,2),(2,2) | a^2 |
| (1,1),(1,3),(3,1),(3,3) | b^2/4 |
| 其它 | ab/2 |
因子(PF/Qstep)在H.264参考模型程序[3]中的实现方法是乘以MF(一个乘法因子)再进行一次右移,这样就避免了除法操作。
改变标度(逆量化)
4X4亮度DC系数变换和量化(只在16X16 帧内模式中使用)
2X2色度直流系数变换和量化
完整的变换,量化,逆量化和逆变换过程
参考文章:
ITU-T Rec. H.264 / ISO/IEC 11496-10, “Advanced Video Coding”, Final Committee Draft, Document JVTF100,December 2002
2 A. Hallapuro and M. Karczewicz, “Low complexity transform and quantization – Part 1: Basic
Implementation”, JVT document JVT-B038, February 20013 JVT Reference Software version 4.0, ftp://ftp.imtc-files.org/jvt-experts/reference_software/