云计算,大数据,人工智能三者有何关系?
原创:http://cloud.idcquan.com/yjs/115806.shtml
云计算
最初的目标是对资源的管理,管理的主要是计算资源,网络资源,存储资源三个方面。想象你有一大堆的服务器,交换机,存储设备,放在你的机房里面,你最想做的事情就是把这些东西统一的管理起来,最好能达到当别人向你请求分配资源的时候(例如1核1G内存,10G硬盘,1M带宽的机器),能够达到想什么时候要就能什么时候要,想要多少就有多少的状态。
这就是所谓的弹性,俗话说就是灵活性。灵活性分两个方面,想什么时候要就什么时候要,这叫做时间灵活性,想要多少就要多少,这叫做空间灵活性。

物理机显然是做不到这一点的。虽然物理设备是越来越牛了:
服务器用的是物理机,例如戴尔,惠普,IBM,联想等物理服务器,随着硬件设备的进步,物理服务器越来越强大了,64核128G内存都算是普通配置。
网络用的是硬件交换机和路由器,例如思科的,华为的,从1GE到10GE,现在有40GE和100GE,带宽越来越牛。
存储方面有的用普通的磁盘,也有了更快的SSD盘。容量从M,到G,连笔记本电脑都能配置到T,更何况磁盘阵列。
但是物理设备有着大大的缺点:
1、人工运维:如果你在一台服务器上安装软件,把系统安装坏了,怎么办?只有重装。当你想配置一下交换机的参数,需要串口连上去进行配置。当你想增加一块磁盘,总要买一块插进服务器。这些都需要人工来,而且很大可能要求机房。你们公司在北五环,机房在南六环,这酸爽。
2、浪费资源:其实你只想部署一个小小的网站,却要用128G的内存。混着部署吧,就有隔离性的问题。
3、隔离性差:你把好多的应用部署在同一台物理机上,他们之间抢内存,抢cpu,一个写满了硬盘,另一个就没法用了,一个弄挂了内核,另一个也同时挂了,如果部署两个相同的应用,端口还会冲突,动不动就会出错。
所以人们想到的第一个办法叫做虚拟化。所谓虚拟化,就是把实的变成虚的。
物理机变为虚拟机:
cpu是虚拟的,内存是虚拟的。
物理交换机变为虚拟交换机:
网卡是虚拟的,交换机是虚拟的,带宽也是虚拟的。
物理存储变成虚拟存储:
多块硬盘虚拟成一个存储池,从中虚拟出多块小硬盘。
虚拟化很好的解决了上面的三个问题:
人工运维:
虚拟机的创建和删除都可以远程操作,虚拟机被玩坏了,删了再建一个分钟级别的。虚拟网络的配置也可以远程操作,创建网卡,分配带宽都是调用接口就能搞定的。
浪费资源:
虚拟化了以后,资源可以分配的很小很小,比如1个cpu,1G内存,1M带宽,1G硬盘,都可以被虚拟出来。
隔离性差:
每个虚拟机有独立的cpu, 内存,硬盘,网卡,不同虚拟机的应用互不干扰。
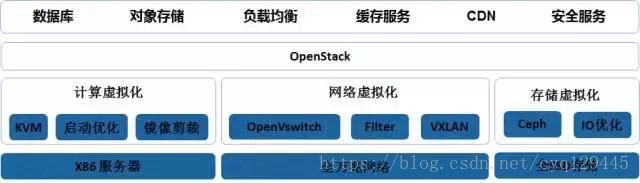
在虚拟化阶段,领跑者是VMware,可以实现基本的计算,网络,存储的虚拟化。
当然这个世界有闭源,就有开源,有Windows就有Linux,有iOS就有Andord,有VMware,就有Xen和KVM。在开源虚拟化方面,Citrix的Xen做的不错,后来Redhat在KVM发力不少。
对于网络虚拟化,有Open vSwitch,可以通过命令创建网桥,网卡,设置VLAN,设置带宽。
对于存储虚拟化,对于本地盘,有LVM,可以将多个硬盘变成一大块盘,然后在里面切出一小块给用户。
但是虚拟化也有缺点,通过虚拟化软件创建虚拟机,需要人工指定放在哪台机器上,硬盘放在哪个存储设备上,网络的VLAN ID,带宽具体的配置,都需要人工指定。所以单单使用虚拟化的运维工程师往往有一个Excel表格,有多少台机器,每台机器部署了哪些虚拟机。所以,一般虚拟化的集群数目都不是特别的大。
为了解决虚拟化阶段的问题,人们想到的一个方式为池化,也就是说虚拟化已经将资源分的很细了,但是对于如此细粒度的资源靠Excel去管理,成本太高,能不能打成一个大的池,当需要资源的时候,帮助用户自动的选择,而非用户指定。所以这个阶段的关键点:调度器Scheduler。
于是VMware有了自己的vCloud。
于是基于Xen和KVM的私有云平台CloudStack,后来Citrix将其收购后开源。
当这些私有云平台在用户的 数据中心
里面卖的其贵无比,赚的盆满钵满的时候。有其他的公司开始了另外的选择,这就是AWS和Google,开始了公有云领域的探索。
AWS最初就是基于Xen技术进行虚拟化的,并且最终形成了公有云平台。也许AWS最初只是不想让自己的电商领域的利润全部交给私有云厂商吧,于是自己的云平台首先支撑起了自己的业务,在这个过程中,AWS自己严肃的使用了自己的云计算平台,使得公有云平台不是对于资源的配置更加友好,而是对于应用的部署更加友好,最终大放异彩。
公有云的第一名AWS活的很爽,第二名Rackspace就不太爽了,没错,互联网行业嘛,基本上就是一家独大。第二名如何逆袭呢?开源是很好的办法,让整个行业大家一起为这个云平台出力,兄弟们,大家一起上。于是Rackspace与美国航空航天局(NASA)合作创始了开源云平台OpenStack。OpenStack现在发展的和AWS有点像了,所以从OpenStack的模块组成,可以看到云计算池化的方法。

OpenStack包含哪些组件呢?
计算池化模块Nova:
OpenStack的计算虚拟化主要使用KVM,然而到底在那个物理机上开虚拟机呢,这要靠nova-scheduler。
网络池化模块Neutron:
OpenStack的网络虚拟化主要使用Openvswitch,然而对于每一个Openvswitch的虚拟网络,虚拟网卡,VLAN,带宽的配置,不需要登录到集群上配置,Neutron可以通过SDN的方式进行配置。
存储池化模块Cinder:
OpenStack的存储虚拟化,如果使用本地盘,则基于LVM,使用哪个LVM上分配的盘,也是用过scheduler来的。后来就有了将多台机器的硬盘打成一个池的方式Ceph,则调度的过程,则在Ceph层完成。
有了OpenStack,所有的私有云厂商都疯了,原来VMware在私有云市场实在赚的太多了,眼巴巴的看着,没有对应的平台可以和他抗衡。现在有了现成的框架,再加上自己的硬件设备,你可以想象到的所有的IT厂商的巨头,全部加入到社区里面来,将OpenStack开发为自己的产品,连同硬件设备一起,杀入私有云市场。
网易当然也没有错过这次风口,上线了自己的OpenStack集群,网易云基础服务(网易蜂巢)基于OpenStack自主研发了IaaS服务,在计算虚拟化方面,通过裁剪KVM镜像,优化虚拟机启动流程等改进,实现了虚拟机的秒级别启动。在网络虚拟化方面,通过SDN和Openvswitch技术,实现了虚拟机之间的高性能互访。在存储虚拟化方面,通过优化Ceph存储,实现高性能云盘。
但是网易并没有杀进私有云市场,而是使用OpenStack支撑起了自己的应用,仅仅是资源层面弹性是不够的,还需要开发出对应用部署友好的组件。
随着公有云和基于OpenStack的私有云越来越成熟,构造一个成千上万个物理节点的云平台以及不是问题,而且很多云厂商都会采取多个数据中心部署多套云平台,总的规模数量就更加大了,在这个规模下,对于客户感知来说,基本上可以实现想什么时候要什么时候要,想要多少要多少。
云计算解决了基础资源层的弹性伸缩,却没有解决应用随基础资源层弹性伸缩而带来的批量、快速部署问题。比如在双十一期间,10个节点要变成100个节点,如果使用物理设备,再买90台机器肯定来不及,仅仅有IaaS实现资源的弹性是不够的,再创建90台虚拟机,也是空的,还是需要运维人员一台一台地部署。于是有了PaaS层,PaaS主要用于管理应用层。我总结为两部分:一部分是你自己的应用应当自动部署,比如Puppet、Chef、Ansible、 Cloud Foundry,CloudFormation等,可以通过脚本帮你部署;另一部分是你觉得复杂的通用应用不用部署,比如数据库、缓存等可以在云平台上一点即得。
要么就是自动部署,要么就是不用部署,总的来说就是应用层你也少操心,就是PaaS的作用。当然最好还是都不用去部署,一键可得,所以公有云平台将通用的服务都做成了PaaS平台。另一些你自己开发的应用,除了你自己其他人不会知道,所以你可以用工具变成自动部署。
当然这种部署方式也有一个问题,就是无论Puppet、 Chef、Ansible把安装脚本抽象的再好,说到底也是基于脚本的,然而应用所在的环境千差万别。文件路径的差别,文件权限的差别,依赖包的差别,应用环境的差别,Tomcat、 PHP、 Apache等软件版本的差别,JDK、Python等版本的差别,是否安装了一些系统软件,是否占用了哪些端口,都可能造成脚本执行的不成功。所以看起来是一旦脚本写好,就能够快速复制了,但是环境稍有改变,就需要把脚本进行新一轮的修改、测试、联调。例如在数据中心写好的脚本移到AWS上就不一定直接能用,在AWS上联调好了,迁移到Google Cloud上也可能会再出问题。

容器是Container,Container另一个意思是集装箱,其实容器的思想就是要变成软件交付的集装箱。集装箱的特点,一是打包,二是标准。

在没有集装箱的时代,假设将货物从A运到B,中间要经过三个码头、换三次船。每次都要将货物卸下船来,摆的七零八落,然后搬上船重新整齐摆好。因此在没有集装箱的时候,每次换船,船员们都要在岸上待几天才能走。
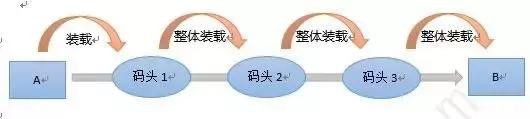
有了集装箱以后,所有的货物都打包在一起了,并且集装箱的尺寸全部一致,所以每次换船的时候,一个箱子整体搬过去就行了,小时级别就能完成,船员再也不能上岸长时间耽搁了。
这是集装箱“打包”、“标准”两大特点在生活中的应用。
部署任何一个应用,也包含很多零零散散的东西,权限,用户,路径,配置,应用环境等!这就像很多零碎地货物,如果不打包,就需要在开发、测试、生产的每个环境上重新查看以保证环境的一致,有时甚至要将这些环境重新搭建一遍,就像每次将货物卸载、重装一样麻烦。中间稍有差池,都可能导致程序的运行失败。

那么容器如何对应用打包呢?还是要学习集装箱,首先要有个封闭的环境,将货物封装起来,让货物之间互不干扰,互相隔离,这样装货卸货才方便。
封闭的环境主要使用了两种技术,一种是看起来是隔离的技术,称为namespace,也即每个namespace中的应用看到的是不同的IP地址、用户空间、程号等。另一种是用起来是隔离的技术,称为cgroup,也即明明整台机器有很多的CPU、内存,而一个应用只能用其中的一部分。
有了这两项技术,集装箱的铁盒子我们是焊好了,接下来就是如何将这个集装箱标准化,从而在哪艘船上都能运输。这里的标准一个是镜像,一个是容器的运行环境。
所谓的镜像,就是将你焊好集装箱的那个时刻,将集装箱的状态保存下来,就像孙悟空说定,集装箱里面就定在了那一刻,然后将这一刻的状态保存成一系列文件。这些文件的格式是标准的,谁看到这些文件,都能还原当时定住的那个时刻。将镜像还原成运行时的过程(就是读取镜像文件,还原那个时刻的过程)就是容器的运行的过程。
有了容器,云计算才真正实现了应用层和资源层的完全弹性。
在云计算的发展过程中,云计算逐渐发现自己除了资源层面的管理,还能够进行应用层面的管理,而 大数据
应用作为越来越重要的应用之一,云计算也可以放入PaaS层管理起来,而大数据也发现自己越来越需要大量的计算资源,而且想什么时候要就什么时候要,想要多少就要多少,于是两者相遇,相识,相知,走在了一起。
说到大数据,首先我们来看一下数据的分类,我们生活中的数据总体分为两种: 结构化数据和非结构化数据。
结构化数据:
指具有固定格式或有限长度的数据,如数据库,元数据等。
非结构化数据:
指不定长或无固定格式的数据,如邮件, word 文档等
当然有的地方还会提到第三种,半结构化数据
,如 XML, HTML 等,当根据需要可按结构化数据来处理,也可抽取出纯文本按非结构化数据来处理。
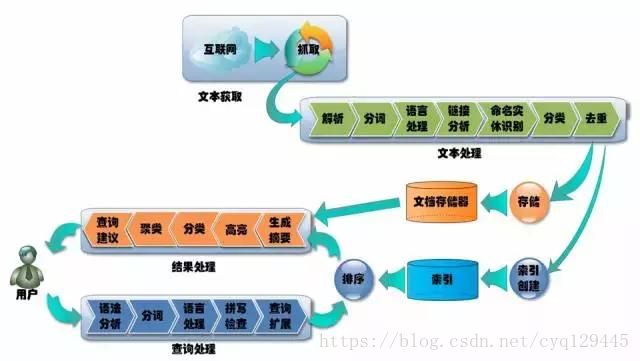
随着互联网的发展,非结构化数据越来越多,当我们遇到这么多数据的时候,怎么办呢?分为以下的步骤:
数据的收集:
即将散落在互联网世界的数据放到咱们的系统中来。数据收集分两个模式,推和拉,所谓的推,即推送,是在互联网世界里面放很多自己的小弟程序,这些小弟程序收集了数据后,主动发送给咱们的系统。所谓的拉,即爬取,通过运行程序,将互联网世界的数据下载到咱们的系统中。
数据的传输:
收到的数据需要通过一个载体进行传输,多采用队列的方式,因为大量的数据同时过来,肯定处理不过来,通过队列,让信息排好队,一部分一部分的处理即可。
数据的存储:好不容易收集到的数据,对于公司来讲是一笔财富,当然不能丢掉,需要找一个很大很大的空间将数据存储下来。
数据的分析:
收到的大量的数据,里面肯定有很多的垃圾数据,或者很多对我们没有用的数据,我们希望对这些数据首先进行清洗。另外我们希望挖掘出数据之间的相互关系,或者对数据做一定的统计,从而得到一定的知识,比如盛传的啤酒和尿布的关系。
数据的检索和挖掘:
分析完毕的数据我们希望能够随时把我们想要的部分找出来,搜索引擎是一个很好的方式。另外对于搜索的结果,可以根据数据的分析阶段打的标签进行分类和聚类,从而将数据之间的关系展现给用户。
当数据量很少的时候,以上的几个步骤其实都不需要云计算,一台机器就能够解决。然而量大了以后,一台机器就没有办法了。
所以大数据想了一个方式,就是聚合多台机器的力量,众人拾柴火焰高,看能不能通过多台机器齐心协力,把事情很快的搞定。
对于数据的收集,对于IoT(物联网)来讲,外面部署这成千上万的检测设备,将大量的温度,适度,监控,电力等等数据统统收集上来,对于互联网网页的搜索引擎来讲,需要将整个互联网所有的网页都下载下来,这显然一台机器做不到,需要多台机器组成网络爬虫系统,每台机器下载一部分,同时工作,才能在有限的时间内,将海量的网页下载完毕。开源的网络爬虫大家可以关注一下Nutch。
对于数据的传输,一个内存里面的队列肯定会被大量的数据挤爆掉,于是就产生了Kafka这样基于硬盘的分布式队列,也即kafka的队列可以多台机器同时传输,随你数据量多大,只要我的队列足够多,管道足够粗,就能够撑得住。
对于数据的存储,一台机器的硬盘肯定是放不下了,所以需要一个很大的分布式存储来做这件事情,把多台机器的硬盘打成一块大硬盘(而非存储池,注意两者的区别),hadoop的HDFS可以做到,也有很多地方用对象存储,同样可以有非常大的空间保存海量的数据。
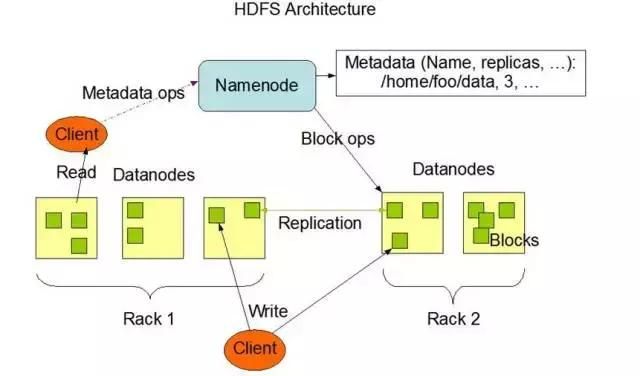
这个图描述的HDFS的一个架构,可以产出来,HDFS将很多个DataNode管理在一起,将数据分成很多小块,分布在多台机器上,从而实现了海量数据的存储。
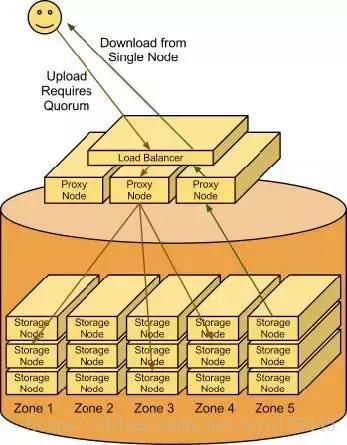
这个图描述的是swift对象存储的架构,也是将很多的storage node聚合在一起,实现海量的存储。
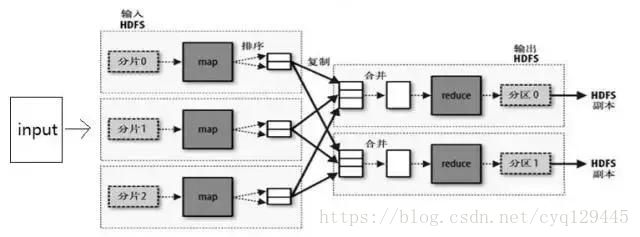
对于数据的分析,一台机器一篇一篇的分析,那要处理到猴年马月也分析不完,于是就有了map-reduce算法,将海量的数据分成多个部分,使用大规模的hadoop集群,每台机器分析一部分,这个过程叫做map,分析完毕之后,还需要汇总一下,得到最终结果,汇总的过程称为reduce。最初的map-reduce算法是每一轮分析都将结果写入文件系统的,后来人们发现往往复杂的分析需要多轮计算才能有结果,而每一轮计算都落盘对速度影响比较大,于是有了Spark这种中间计算全部放入内存的分布式计算框架。对于数据的分析有全量的离线的计算,例如将所有的用户的购买行为进行分类,也有需要实时处理实时分析的,例如股票资讯的分类,实时的计算框架有storm,spark streaming等等。
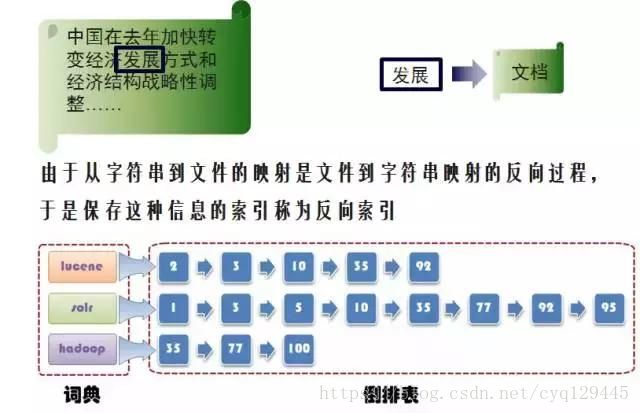
对于数据的搜索,如果使用顺序扫描法 (Serial Scanning), 比如要找内容包含某一个字符串的文件,就是一个文档一个文档的看,对于每一个文档,从头看到尾,如果此文档包含此字符串,则此文档为我们要找的文件,接着看下一个文件,直到扫描完所有的文件。如利用windows的搜索也可以搜索文件内容,只是相当的慢。为什么慢呢?其实是由于我们想要搜索的信息和非结构化数据中所存储的信息不一致造成的。
非结构化数据中所存储的信息是每个文件包含哪些字符串,也即已知文件,欲求字符串相对容易,也即是从文件到字符串的映射。而我们想搜索的信息是哪些文件包含此字符串,也即已知字符串,欲求文件,也即从字符串到文件的映射。两者恰恰相反。
如果我们通过对于非结构化数据进行处理,形成索引文件,里面保存从字符串到文件的映射,则会大大提高搜索速度。
由于从字符串到文件的映射是文件到字符串映射的反向过程,于是保存这种信息的索引称为反向索引 。
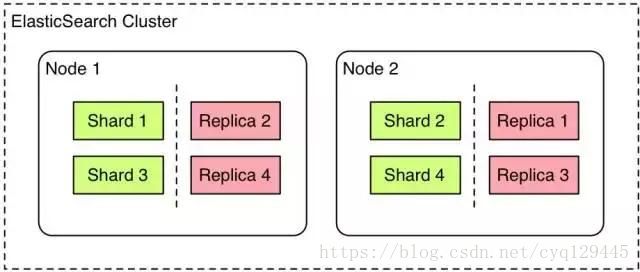
当数据量非常大的时候,一个索引文件已经不能满足大数据量的搜索,所以要分成多台机器一起搜索,如图所示,将索引分成了多个shard也即分片,分不到不同的机器上,进行并行的搜索。
所以说大数据平台,什么叫做大数据,说白了就是一台机器干不完,大家一起干。随着数据量越来越大,很多不大的公司都需要处理相当多的数据,这些小公司没有这么多机器可怎么办呢?
于是大数据人员想起来想要多少要多少,想什么时候要什么时候要的云平台。空间的灵活性让大数据使用者随时能够创建一大批机器来计算,而时间的灵活性可以保证整个云平台的资源,不同的租户你用完了我用,我用完了他用,大家都不浪费资源。
于是很多人会利用公有云或者私有云平台部署大数据集群,但是完成集群的部署还是有难度的,云计算的人员想,既然大家都需要,那我就把他集成在我的云计算平台里面,当大家需要一个大数据平台的时候,无论是Nutch, Kafka,hadoop,ElasticSearch等,我能够马上给你部署出来一套。我们管这个叫做PaaS平台。
大数据平台于是作为PaaS融入了云计算的大家庭。
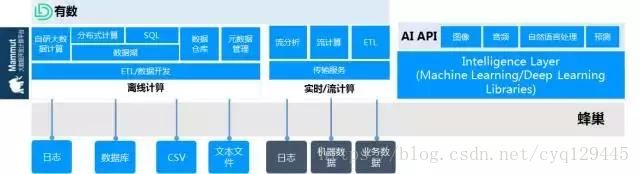
作为国内最早诞生的互联网公司之一,网易在过去十余年的产品研发、孵化和运维过程中,各个部门对数据有着不同且繁杂的需求。而如何把这些繁杂的需求用统一的手段来解决,网易在大数据分析方面同样进行了十余年的探索,并自去年开始通过“网易云”将这些能力开放出来
“网易猛犸”与“网易有数”两大数据分析平台就是在这个阶段逐渐成型的。
网易猛犸大数据平台可以实现从各种不同数据源提取数据,同步到内核存储系统,同时对外提供便捷的操作体验。现在每天约有130亿条数据进入网易猛犸平台,经过数据建模和清洗,进行数据分析预测。
网易的另一大数据分析平台,网易有数则可以极大简化数据探索,提高数据可视化方面的效率,提供灵活报表制作等,以帮助分析师专注于自己的工作内容。
有了大数据平台,对于数据的处理和搜索已经没有问题了,搜索引擎着实火了一阵,当很多人觉得搜索引擎能够一下子帮助用户搜出自己想要的东西的时候,还是非常的开心的。
但是过了一阵人们就不满足于信息仅仅被搜索出来了。信息的搜索还是一个人需要适应机器的思维的过程,要想搜到想要的信息,有时候需要懂得一些搜索或者分词的技巧。机器还是没有那么懂人。什么时候机器能够像人一样懂人呢,我告诉机器我想要什么,机器就会像人一样的体会,并且做出人一样的反馈,多好啊。
这个思想已经不是一天两天了,在云计算还不十分兴起的时候,人们就有了这样的想法。那怎么做的这件事情呢?
人们首先想到的是,人类的思维方式有固有的规律在里面,如果我们能够将这种规律表达出来,告诉机器,机器不就能理解人了吗?
人们首先想到的是告诉计算机人类的推理能力,在这个阶段,人们慢慢的能够让机器来证明数学公式了,多么令人欣喜的过程啊。然而,数学公式表达相对严谨的,推理的过程也是相对严谨,所以比较容易总结出严格个规律来。然而一旦涉及到没有办法那么严谨的方面,比如财经领域,比如语言理解领域,就难以总结出严格的规律来了。
看来仅仅告知机器如何推理还不够,还需要告诉机器很多很多的知识,很多知识是有领域的,所以一般人做不来,专家可以,如果我们请财经领域的专家或者语言领域的专家来总结规律,并且将规律相对严格的表达出来,然后告知机器不就可以了么?所以诞生了一大批专家系统。然而专家系统遭遇的瓶颈是,由人来把知识总结出来再教给计算机是相当困难的,即便这个人是专家。
于是人们想到,看来机器是和人完全不一样的物种,干脆让机器自己学习好了。机器怎么学习呢?既然机器的统计能力这么强,基于统计学习,一定能从大量的数字中发现一定的规律。
其实在娱乐圈有很好的一个例子,可见一斑
有一位网友统计了知名歌手在大陆发行的 9 张专辑中 117 首歌曲的歌词,同一词语在一首歌出现只算一次,形容词、名词和动词的前十名如下表所示(词语后面的数字是出现的次数):
如果我们随便写一串数字,然后按照数位依次在形容词、名词和动词中取出一个词,连在一起会怎么样呢?
例如取圆周率 3.1415926,对应的词语是:坚强,路,飞,自由,雨,埋,迷惘。稍微连接和润色一下:
坚强的孩子,
依然前行在路上,
张开翅膀飞向自由,
让雨水埋葬他的迷惘。
是不是有点感觉了?当然真正基于统计的学习算法比这个简单的统计复杂的多。
然而统计学习比较容易理解简单的相关性,例如一个词和另一个词总是一起出现,两个词应该有关系,而无法表达复杂的相关性,并且统计方法的公式往往非常复杂,为了简化计算,常常做出各种独立性的假设,来降低公式的计算难度,然而现实生活中,具有独立性的事件是相对较少的。
于是人类开始从机器的世界,反思人类的世界是怎么工作的。
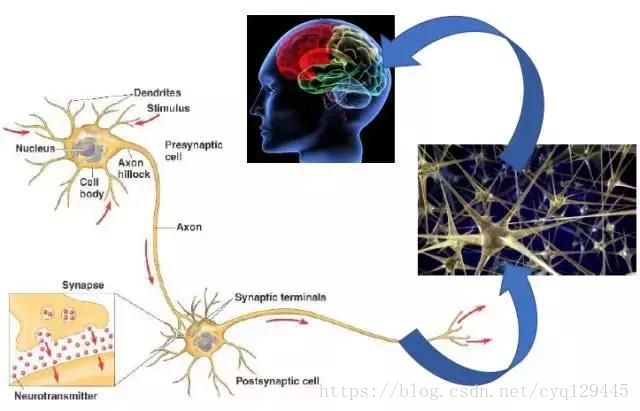
人类的脑子里面不是存储着大量的规则,也不是记录着大量的统计数据,而是通过神经元的触发实现的,每个神经元有从其他神经元的输入,当接收到输入的时候,会产生一个输出来刺激其他的神经元,于是大量的神经元相互反应,最终形成各种输出的结果。例如当人们看到美女瞳孔放大,绝不是大脑根据身材比例进行规则判断,也不是将人生中看过的所有的美女都统计一遍,而是神经元从视网膜触发到大脑再回到瞳孔。在这个过程中,其实很难总结出每个神经元对最终的结果起到了哪些作用,反正就是起作用了。
于是人们开始用一个数学单元模拟神经元
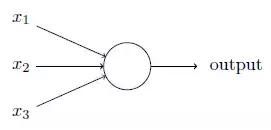
这个神经元有输入,有输出,输入和输出之间通过一个公式来表示,输入根据重要程度不同(权重),影响着输出。
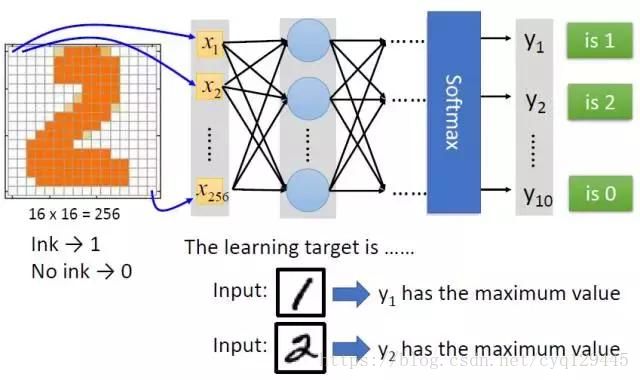
于是将n个神经元通过像一张神经网络一样连接在一起,n这个数字可以很大很大,所有的神经元可以分成很多列,每一列很多个排列起来,每个神经元的对于输入的权重可以都不相同,从而每个神经元的公式也不相同。当人们从这张网络中输入一个东西的时候,希望输出一个对人类来讲正确的结果。例如上面的例子,输入一个写着2的图片,输出的列表里面第二个数字最大,其实从机器来讲,它既不知道输入的这个图片写的是2,也不知道输出的这一系列数字的意义,没关系,人知道意义就可以了。正如对于神经元来说,他们既不知道视网膜看到的是美女,也不知道瞳孔放大是为了看的清楚,反正看到美女,瞳孔放大了,就可以了。
对于任何一张神经网络,谁也不敢保证输入是2,输出一定是第二个数字最大,要保证这个结果,需要训练和学习。毕竟看到美女而瞳孔放大也是人类很多年进化的结果。学习的过程就是,输入大量的图片,如果结果不是想要的结果,则进行调整。如何调整呢,就是每个神经元的每个权重都向目标进行微调,由于神经元和权重实在是太多了,所以整张网络产生的结果很难表现出非此即彼的结果,而是向着结果微微的进步,最终能够达到目标结果。当然这些调整的策略还是非常有技巧的,需要算法的高手来仔细的调整。正如人类见到美女,瞳孔一开始没有放大到能看清楚,于是美女跟别人跑了,下次学习的结果是瞳孔放大一点点,而不是放大鼻孔。
听起来也没有那么有道理,但是的确能做到,就是这么任性。
神经网络的普遍性定理是这样说的,假设某个人给你某种复杂奇特的函数,f(x):
不管这个函数是什么样的,总会确保有个神经网络能够对任何可能的输入x,其值f(x)(或者某个能够准确的近似)是神经网络的输出。
如果在函数代表着规律,也意味着这个规律无论多么奇妙,多么不能理解,都是能通过大量的神经元,通过大量权重的调整,表示出来的。
这让我想到了经济学,于是比较容易理解了。
我们把每个神经元当成社会中从事经济活动的个体。于是神经网络相当于整个经济社会,每个神经元对于社会的输入,都有权重的调整,做出相应的输出,比如工资涨了,菜价也涨了,股票跌了,我应该怎么办,怎么花自己的钱。这里面没有规律么?肯定有,但是具体什么规律呢?却很难说清楚。
基于专家系统的经济属于计划经济,整个经济规律的表示不希望通过每个经济个体的独立决策表现出来,而是希望通过专家的高屋建瓴和远见卓识总结出来。专家永远不可能知道哪个城市的哪个街道缺少一个卖甜豆腐脑的。于是专家说应该产多少钢铁,产多少馒头,往往距离人民生活的真正需求有较大的差距,就算整个计划书写个几百页,也无法表达隐藏在人民生活中的小规律。
基于统计的宏观调控就靠谱的多了,每年统计局都会统计整个社会的就业率,通胀率,GDP等等指标,这些指标往往代表着很多的内在规律,虽然不能够精确表达,但是相对靠谱。然而基于统计的规律总结表达相对比较粗糙,比如经济学家看到这些统计数据可以总结出长期来看房价是涨还是跌,股票长期来看是涨还是跌,如果经济总体上扬,房价和股票应该都是涨的。但是基于统计数据,无法总结出股票,物价的微小波动规律。
基于神经网络的微观经济学才是对整个经济规律最最准确的表达,每个人对于从社会中的输入,进行各自的调整,并且调整同样会作为输入反馈到社会中。想象一下股市行情细微的波动曲线,正是每个独立的个体各自不断交易的结果,没有统一的规律可循。而每个人根据整个社会的输入进行独立决策,当某些因素经过多次训练,也会形成宏观上的统计性的规律,这也就是宏观经济学所能看到的。例如每次货币大量发行,最后房价都会上涨,多次训练后,人们也就都学会了。
然而神经网络包含这么多的节点,每个节点包含非常多的参数,整个参数量实在是太大了,需要的计算量实在太大,但是没有关系啊,我们有大数据平台,可以汇聚多台机器的力量一起来计算,才能在有限的时间内得到想要的结果。
于是工智能程序作为SaaS平台进入了云计算。
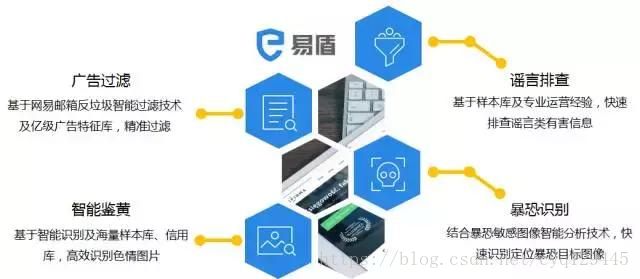
网易将人工智能这个强大的技术,应用于反垃圾工作中,从网易1997年推出邮箱产品开始,我们的反垃圾技术就在不停的进化升级,并且成功应用到各个亿量级用户的产品线中,包括影音娱乐,游戏,社交,电商等产品线。比如网易新闻、博客相册、云音乐、云阅读、有道、BOBO、考拉、游戏等产品。总的来说,反垃圾技术在网易已经积累了19年的实践经验,一直在背后默默的为网易产品保驾护航。现在作为云平台的SaaS服务开放出来。
回顾网易反垃圾技术发展历程,大致上我们可以把他分为三个关键阶段,也基本对应着人工智能发展的三个时期:
第一阶段主要是依赖关键词,黑白名单和各种过滤器技术,来做一些内容的侦测和拦截,这也是最基础的阶段,受限于当时计算能力瓶颈以及算法理论的发展,第一阶段的技术也能勉强满足使用。
第二个阶段时,基于计算机行业里有一些更新的算法,比如说贝叶斯过滤(基于概率论的算法),一些肤色的识别,纹理的识别等等,这些比较优秀成熟的论文出来,我们可以基于这些算法做更好的特征匹配和技术改造,达到更优的反垃圾效果。
最后,随着人工智能算法的进步和计算机运算能力的突飞猛进,反垃圾技术进化到第三个阶段:大数据和人工智能的阶段。我们会用海量大数据做用户的行为分析,对用户做画像,评估用户是一个垃圾用户还是一个正常用户,增加用户体验更好的人机识别手段,以及对语义文本进行理解。还有基于人工智能的图像识别技术,更准确识别是否是色情图片,广告图片以及一些违禁品图片等等。
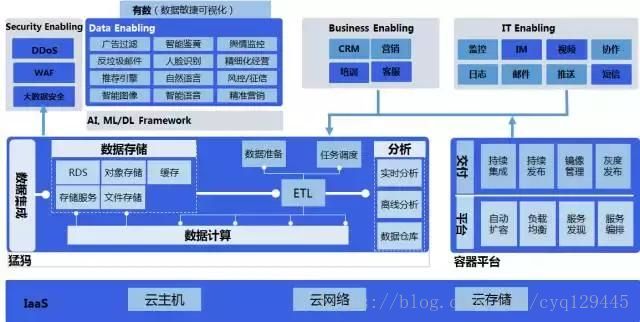
云计算
大数据
人工智能