使用队列+多线程爬取泼辣有图的图片
关于泼辣有图
官网介绍:
所以可以放心使用,泼辣有图上面的照片我个人觉得还是很不错的,觉得都挺好看的,有很多适合当壁纸、各种背景、插图什么的。
关于队列queue和多线程的使用
可以参考这篇文章python利用队列(queue)实现多线程同步(生产者-消费者模型)
分析泼辣有图网页
网站还是很简单,也没有反爬措施,稍微看一下就一目了然。
每张图片下面都有作者、地点、图片介绍等信息。
然后通过一直下拉会显示往期的更多照片,所以可以猜测应该是通过ajax动态更新的。
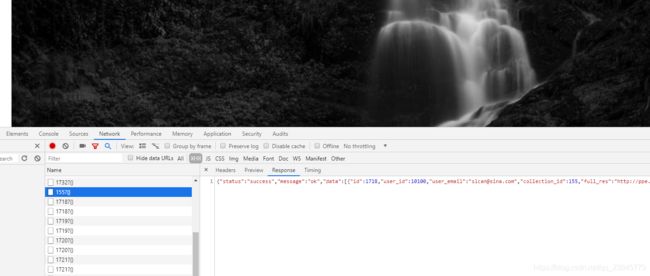
通过分析发现,网站是通过一期一期的获取数据url后面的数字就是对应的期数,而且返回的是个json格式
开始编写爬取程序
总体思路: 创建两个线程类,一个用来获取并解析每一期的数据,将每一期的每张图片url和其它相关信息放入队列,另一个类用来从队列中取出图片url和相应信息,将图片和相关信息下载到本地。
导入用到的库:
import requests
import threading
import os
import queue
编写解析类:
class scrawler_page(threading.Thread):
def __init__(self,Q_page,Q_imgurl):
super().__init__()
self.page_queue=Q_page #存放期数的队列
self.imgurl_queue=Q_imgurl#存放图片url和相关信息的队列
def run(self):
while True:
if not self.page_queue.empty():
page=self.page_queue.get()#从队列中取出一个期数
result=self.parse(page)#通过parse方法返回该期数的解析结果
# print(result)
self.imgurl_queue.put(result)#将结果放入队列
self.page_queue.task_done()#任务完成信号
else:
break
def parse(self,page):
url='http://www.polaxiong.com/collections/get_entries_by_collection_id/%s?{}'%page
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
r = requests.get(url,headers=headers)
data = r.json().get('data')
imgurls = []
storys = []
for item in data:
imgurl = item.get('full_res')
story = item.get('story')
imgurls.append(imgurl)
storys.append(story)
#print(page,imgurls,storys)
return (page,imgurls,storys)#返回一个元组,其中包括期数、包含该期所有图片url的list、包含该期所有图片相关信息的list
编写下载类:
class down_img(threading.Thread):
def __init__(self,Q_imgurl):
super().__init__()
self.imgurl_queue=Q_imgurl
def run(self):
while True:
if self.imgurl_queue.empty():#死循环,直到imgurl_queue队列中有数据后再退出(防止下载线程刚启动时,imgurl_queue队列中没有数据导致直接退出,还可以设置个超时,当超过设定时间后队列仍然是空的,就结束该线程)
pass
else:
break
while True:
if not self.imgurl_queue.empty():
imgurls=self.imgurl_queue.get()#从队列取出一条数据
self.download(imgurls)#进行下载
self.imgurl_queue.task_done()
else:
break
def download(self,imgurls):
page=imgurls[0]#期数
imgurl=imgurls[1]#包含该期所有图片url的list
story=imgurls[2]#包含该期所有图片相关信息的list
path='image/{}'.format(page)#保存到本地的路径(每期单独一个文件夹)
if not os.path.exists(path):#如果该期的文件夹路径不存在就创建一个
os.makedirs(path)
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
i=1
for url in imgurl:
r=requests.get(url,headers=headers)
with open('{}/{}.jpg'.format(path,i),'wb') as f:
f.write(r.content)
print('######下载第{}期第{}张图片完成!'.format(page,i))
i+=1
with open('{}/storys.txt'.format(path),'a',encoding='utf-8') as f:
j=1
for s in story:
f.write('#####{}####'.format(j)+':'+s+'\n')
f.write('\n')
j+=1
print('-----------第{}期图片全部下载完成,共{}张-----------'.format(page,i-1))
全部代码:
import requests
import threading
import os
import queue
class scrawler_page(threading.Thread):
def __init__(self,Q_page,Q_imgurl):
super().__init__()
self.page_queue=Q_page
self.imgurl_queue=Q_imgurl
def run(self):
while True:
if not self.page_queue.empty():
page=self.page_queue.get()
result=self.parse(page)
# print(result)
self.imgurl_queue.put(result)
self.page_queue.task_done()
else:
break
def parse(self,page):
url='http://www.polaxiong.com/collections/get_entries_by_collection_id/%s?{}'%page
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
r = requests.get(url,headers=headers)
data = r.json().get('data')
imgurls = []
storys = []
for item in data:
imgurl = item.get('full_res')
story = item.get('story')
imgurls.append(imgurl)
storys.append(story)
#print(page,imgurls,storys)
return (page,imgurls,storys)
class down_img(threading.Thread):
def __init__(self,Q_imgurl):
super().__init__()
self.imgurl_queue=Q_imgurl
def run(self):
while True:
if self.imgurl_queue.empty():
pass
else:
break
while True:
if not self.imgurl_queue.empty():
imgurls=self.imgurl_queue.get()
self.download(imgurls)
self.imgurl_queue.task_done()
else:
break
def download(self,imgurls):
page=imgurls[0]
imgurl=imgurls[1]
story=imgurls[2]
path='image/{}'.format(page)
if not os.path.exists(path):
os.makedirs(path)
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
i=1
for url in imgurl:
r=requests.get(url,headers=headers)
with open('{}/{}.jpg'.format(path,i),'wb') as f:
f.write(r.content)
print('######下载第{}期第{}张图片完成!'.format(page,i))
i+=1
with open('{}/storys.txt'.format(path),'a',encoding='utf-8') as f:
j=1
for s in story:
f.write('#####{}####'.format(j)+':'+s+'\n')
f.write('\n')
j+=1
print('-----------第{}期图片全部下载完成,共{}张-----------'.format(page,i-1))
if __name__ == '__main__':
page_queue=queue.Queue()#创建无大小限制存放期数的队列
imgurl_queue=queue.Queue()#创建无大小限制存放图片url、相关信息的队列
#page_queue.put(155)
#page_queue.put(156)
for i in range(1,157):#目前网站上总共有156期
page_queue.put(i)
for i in range(4):#开启4个解析期数的线程
crawler_thread=scrawler_page(page_queue,imgurl_queue)
crawler_thread.setDaemon(True)
crawler_thread.start()
for i in range(20):#开启20个下载线程
down_thread=down_img(imgurl_queue)
down_thread.setDaemon(True)
down_thread.start()
page_queue.join()
imgurl_queue.join()
运行截图:

下载结果:
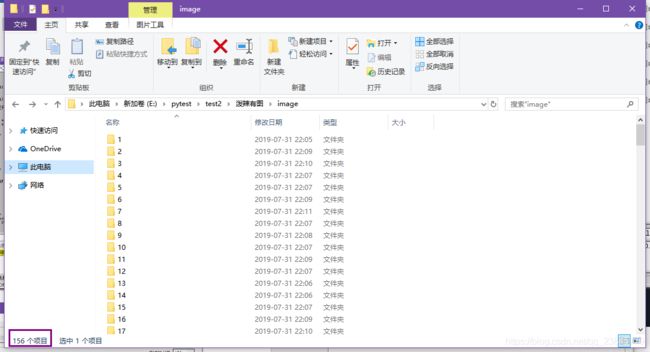
总共156期,一个不少。


每期的图片和相应的信息。
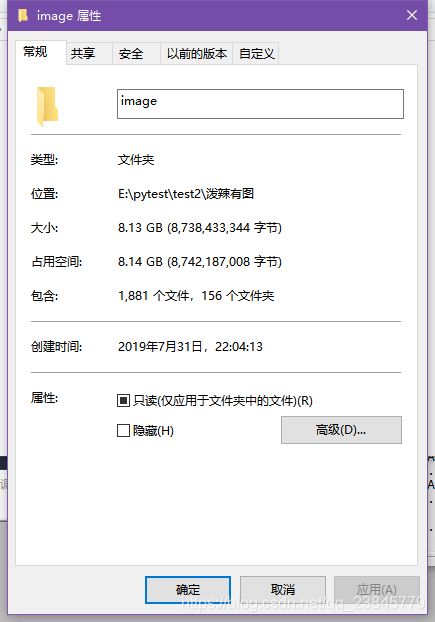
总共8个多G,1700多张照片,我平均4-5M/s的网速都要几十分钟才下载完。
OVER