Python爬虫的urllib.error.HTTPError: HTTP Error 418错误
在家办公无聊,最近开始研究了下Python,刚了解了下爬虫,想自己尝试下,一上来就来了一个418的错误。
from urllib.request import urlopen
url = 'https://movie.douban.com/top250?start=%s&filter='
ret = urlopen(url)
aa = ret.read().decode('utf-8')
print(aa)

看到这个错误,以前是玩java的就想到可能有反爬虫机制,多半要模拟浏览器访问,直接爬取会被拦截。
于是打开浏览器按f12,随便访问一个网站,选中连接,找Headers,往下拉找到其中User-Agent代表用的哪个请求的浏览器
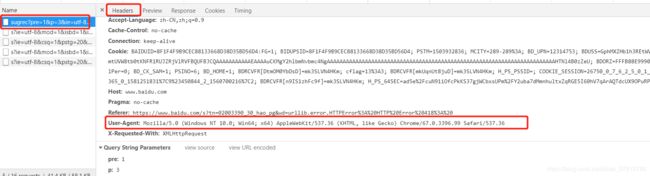
代码修改如下:
from urllib.request import urlopen, Request
url = 'https://movie.douban.com/top250?start=%s&filter='
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
ret = Request(url, headers=headers)
res = urlopen(ret)
aa = res.read().decode('utf-8')
print(aa)
就能爬取到你想要的信息了

获取User-Agent的进阶