Shell脚本的学习心得和知识总结(四)|函数和正则表达式
2020年3月15日11:56:20
注:今天的学习内容主要是shell函数和正则表达式!
文章目录
- shell函数
- 正则表达式
- 基础正则表达式
- 扩展正则表达式
- 正则表达式的练习
shell函数
shell中允许将一组命令集合或语句形成一段可用代码,这些代码块称为shell函数。给这段代码起个名字称为函数名,后续可以直接调用该段代码。
| shell函数详解 |
# 函数格式如下:
funcname() { #指定函数名
command #函数体(执行的命令)
}
实例如下:
[root@localhost myshell_study]# vim function.sh
[root@localhost myshell_study]# cat function.sh
#!/bin/bash
function hello1
{
echo -n "hello "
}
hello2()
{
echo "songjinzhou"
}
hello1 #通过函数名直接调用
hello2
[root@localhost myshell_study]# bash function.sh
hello songjinzhou
[root@localhost myshell_study]#
#-------------------------------------------------------
[root@localhost myshell_study]# vim function.sh
[root@localhost myshell_study]# cat function.sh
#!/bin/bash
myfunc()
{
echo "hello songjinzhou"
return 1
}
myfunc
echo "函数的返回值是:$?"
[root@localhost myshell_study]# bash function.sh
hello songjinzhou
函数的返回值是:1
[root@localhost myshell_study]#
注:return 在函数中定义状态返回值,返回并终止函数,但返回的只能是 0-255 的数字,类似于 exit。
# 函数传参数如下:
[root@localhost myshell_study]# vim function.sh
[root@localhost myshell_study]# cat function.sh
#!/bin/bash
myfunc()
{
echo -n "hello $1"
echo " $2"
return 1
}
myfunc songjinzhou 666 #后面两个是参数
[root@localhost myshell_study]# bash function.sh
hello songjinzhou 666
[root@localhost myshell_study]#
正则表达式
作用:匹配 过滤符合预期要求的字符串。 正则表达式就是为了处理大量的文本|字符串而定义的一套规则和方法。通过定义的这些特殊符号的辅助,我们就可以快速过滤,替换或输出需要的字符串。Linux正则表达式一般以行为单位处理。 shell正则表达式一般分为两种:
- 基础正则表达式
- 扩展正则表达式,主要是这四种:{ + ? | ()}
| 从 *和? 出发,看正则表达式和通配符的本质区别 |
具体的区分方法如下:
- 在三剑客awk,sed,grep,egrep都是正则表达式,除此之外都是通配符
- 文件、目录名的匹配都是通配符;文件内容(字符串,文本【文件】内容)的匹配是使用正则表达式
下面主要是以grep 为例,详解常用正则表达式符号:(注意:在匹配模式中一定要加上引号)
基础正则表达式
| 符号 | 描述 | 实例 |
|---|---|---|
| . | 匹配任意单个字符(单个字符必须存在:即一个点匹配一个字符) | l. .e可以匹配的有:love、like、leee;而不可以匹配le、lee 、lacbde |
| ^ | 匹配后面字符串开头 | 匹配以 abc 开头的行:echo -e “abc\nxyz” l grep ^abc |
| $ | 匹配前面字符串结尾 | 匹配以 xyz 结尾的行:echo -e “abc\nxyz” l grep xyz$ |
| * | 匹配前一个字符的零个或多个 | a* 表示出现任意个a的情况;a*b 表示b前面有任意个a的情况(包括没有a的情况) |
| .* | 表示任意长度的任意字符 | 过滤出一行中a在前,b在后的行,包含 a 和 b,且字母 a 必须在 b前面。grep “a.*b” test1.sh |
| [] | 表示范围内的一个字符 | 过滤出包含小写字母的行 grep [a-z] a.txt;过滤出包含大写字母的行 grep [A-Z] a.txt;过滤出包含数字的行 grep [0-9] a.txt ;过滤出包含数字和小写字母的行 grep [0-9a-z] a.txt;过滤出包含字母asf的行 grep [asf] a.txt |
| 【点-点】] | 匹配中括号中范围内的任意一个字符 | 匹配所有字母:echo -e “a\nb\nc” 竖线 grep ‘[a-z]’ |
| [^] | 匹配 [^ 字符 ] 之外的任意一个字符 | 见下面实例:除了【】里面的字符都可以取到 |
| ^ [^] | 匹配不是中括号内任意 一个字符开头的行 | 见下面实例: |
| {n}或者{n,} | {n}:表示严格匹配n个字符; {n,}匹配花括号前面字符至少 n个字符 | 见下面实例: |
| {n,m} | 匹配花括号前面字符至少 n个字符,最多 m 个字符 | “ac \ {2,5 \ }b” 匹配a和b之间有最少2个c最多5个c的行; “ac \ {,5 \ }b” 匹配a和b之间有最多5个c的行;“ac \ {2, \ }b” 匹配a和b之间有最少2个c的行 |
| \ < | 锚定单词首部(单词一般以空格或特殊字符做分隔) | 见下面实例: |
| \ > | 锚定单词尾部(单词一般以空格或特殊字符做分隔) | 见下面实例: |
| () | \1 调用前面的第一个分组 | 小括号里面的为一个分组,\1就是为了调用这个分组 |
具体的实力展示如下:
[root@localhost myshell_study]# ls
check_free.sh computing.sh datatype.sh nohup.out
[root@localhost myshell_study]# rm -f ./* 当然这是通配符
[root@localhost myshell_study]# ls
[root@localhost myshell_study]# head /etc/passwd >test.txt
[root@localhost myshell_study]# ls
test.txt
[root@localhost myshell_study]# cat test.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost myshell_study]#
#------------------------下面是匹配root的方式:使用 点-------------
[root@localhost myshell_study]# grep "root" test.txt
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost myshell_study]# grep "r..t" test.txt
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
#------------------------下面是匹配root开头的行:使用 ^-------------
[root@localhost myshell_study]# echo -e "abc\nxyz" |grep ^abc
abc
[root@localhost myshell_study]# echo -e "abc\nxyz"
abc
xyz
[root@localhost myshell_study]# grep "^root" test.txt
root:x:0:0:root:/root:/bin/bash
#------------------------下面是匹配sync结尾的行:使用 $-------------
[root@localhost myshell_study]# echo -e "abc\nxyz"
abc
xyz
[root@localhost myshell_study]# echo -e "abc\nxyz" |grep xyz$
xyz
[root@localhost myshell_study]# grep "sync$" test.txt
sync:x:5:0:sync:/sbin:/bin/sync
#------------------------下面是匹配a*b的行:使用 *-------------
[root@localhost myshell_study]# cat test1.sh
a
ab
aaab
ccca
bbbb
abcfgnb
66b
[root@localhost myshell_study]# grep "a*b" test1.sh
ab
aaab
bbbb
abcfgnb
66b
[root@localhost myshell_study]# grep ".*b" test1.sh #虽然内容一致,颜色不一样
ab
aaab
bbbb
abcfgnb
66b
#------------------------下面是匹配a.*b的行:使用 .*-------------
[root@localhost myshell_study]# grep ".*" test1.sh
a
ab
aaab
ccca
bbbb
abcfgnb
66b
[root@localhost myshell_study]# grep "a.*b" test1.sh
ab
aaab
abcfgnb
注:因为很多匹配结果需要 有颜色的支持。下面的实例以图片形式呈现:








![]()




基础正则表达式的总结:
一、字符匹配
.
[]
[^]
二、次数匹配
*
{m,n}
三、锚定
^
$
\ <
\ >
四、分组
\ ( \ )
\1
扩展正则表达式
注:
- 正则表达式中的{}以及()都需要加上\进行转义,而扩展正则表达式不需要
- | ? +是扩展正则独有的
- 锚定单词首部和尾部在扩展正则以及基础正则中都需要加上\
扩展正则是兼容基础正则的!
| 符号 | 描述 | 实例 |
|---|---|---|
| +(扩展正则) | 表示其前面的字符出现最少一次的情况 | |
| ?(扩展正则) | 表示其前面的字符出现最多一次的情况(可以0个) | |
| l(扩展正则) | 匹配竖杠两边的任意一个 |
下面是扩展正则 实例:



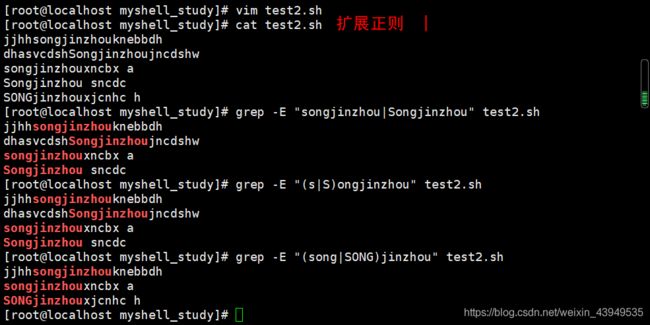
注:上面只是仅做分组,可以并不调用
扩展正则表达式的总结:
一、字符匹配
.
[]
[^]
二、次数匹配
*
{m,n}
+表示其前面的字符出现最少一次的情况
?表示其前面的字符出现最多一次的情况
三、锚定
^
$
\ <
\ >
四、分组
()
\1
\2
五、或
|
针对于 Posix字符的使用,简单记下如下即可:
[root@localhost myshell_study]# grep -E " +" test.txt
# this is a testing file.
#Oh,my god.Songjinzhou is 666
# Oh,my god.Songjinzhou is 666
#
[root@localhost myshell_study]# grep -E "[[:space:]]+" test.txt
# this is a testing file.
#Oh,my god.Songjinzhou is 666
# Oh,my god.Songjinzhou is 666
#
[root@localhost myshell_study]#
正则表达式的练习
正则表达式的练习1
背景如下:

需求:
- 过滤出包含大写字母的行
- 匹配非数字字符
- 过滤出一行中a在前,b在后的行
- 匹配a和b之间有最少2个c最多5个c的行
- 过滤出以# 为开头,且第二个字符是空格的行
- 过滤出行首和行位字母相同的行
- 过滤出第一个字符是#,且第二个字符串是非空字符,而且结尾是数字的行
- 过滤出一行包含相同数字的行
结果按照题目顺序展示如下:

![]()


正则表达式的练习2
需求如下:
1. 每一秒钟输出/root/myshell_study下的文件至屏幕
2. 打印出包含某个关键词的文件(关键词执行脚本时接收)
3. 统计系统中以.sh结尾的文件总大小,输出结果以kb为单位
背景如下:
[root@localhost myshell_study]# pwd
/root/myshell_study
[root@localhost myshell_study]# ls
test1.sh test2.sh test.txt
[root@localhost myshell_study]# ll
total 12
-rw-r--r--. 1 root root 32 Mar 15 13:10 test1.sh
-rw-r--r--. 1 root root 108 Mar 15 22:29 test2.sh
-rw-r--r--. 1 root root 674 Mar 15 14:52 test.txt
[root@localhost myshell_study]#
解题如下:
#-----------------------------------------------------
[root@localhost myshell_study]# vim work.sh
[root@localhost myshell_study]# cat work.sh
#!/bin/bash
for file in `ls /root/myshell_study`
do
echo $file
sleep 1
done
[root@localhost myshell_study]# bash work.sh
test1.sh
test2.sh
test.txt
work.sh
[root@localhost myshell_study]#
#-----------------------------------------------------
[root@localhost myshell_study]# find . -type f
./test1.sh
./test.txt
./test2.sh
./work.sh
[root@localhost myshell_study]# vim work.sh
[root@localhost myshell_study]# cat work.sh
#!/bin/bash
:<<!
for file in `ls /root/myshell_study`
do
echo $file
sleep 1
done
!
#--------------------------------------
keyword=$1
for file in `find /root/myshell_study -type f`
do
grep "$keyword" $file &>/dev/null
if [ $? -eq 0 ];then
echo $file
fi
done
[root@localhost myshell_study]# bash work.sh root
/root/myshell_study/test.txt
/root/myshell_study/work.sh
[root@localhost myshell_study]#
#-----------------------------------------------------
[root@localhost myshell_study]# find . -name "*.sh"
./test1.sh
./test2.sh
./work.sh
[root@localhost myshell_study]# find . -name "*.sh" -exec ls -l {} \;
-rw-r--r--. 1 root root 32 Mar 15 13:10 ./test1.sh
-rw-r--r--. 1 root root 108 Mar 15 22:29 ./test2.sh
-rw-r--r--. 1 root root 265 Mar 15 23:08 ./work.sh
[root@localhost myshell_study]# find . -name "*.sh" -exec ls -l {} \; | cut -d " " -f 5
32
108
265
[root@localhost myshell_study]#
# 下面是第三题的解决方案:
[root@localhost myshell_study]# vim work.sh
[root@localhost myshell_study]# cat work.sh
#!/bin/bash
:<<!
for file in `ls /root/myshell_study`
do
echo $file
sleep 1
done
!
#----------------------------------------------
:<<!
keyword=$1
for file in `find /root/myshell_study -type f`
do
grep "$keyword" $file &>/dev/null
if [ $? -eq 0 ];then
echo $file
fi
done
!
#----------------------------------------------
sum=0
for filesize in `find . -name "*.sh" -exec ls -l {} \; | cut -d " " -f 5`
do
let sum+=$filesize
done
echo "脚本文件总大小:$((sum/1024))kb,即:"$sum"b"
[root@localhost myshell_study]# bash work.sh
脚本文件总大小:0kb,即:637b
[root@localhost myshell_study]# ll
total 16
-rw-r--r--. 1 root root 32 Mar 15 13:10 test1.sh
-rw-r--r--. 1 root root 108 Mar 15 22:29 test2.sh
-rw-r--r--. 1 root root 674 Mar 15 14:52 test.txt
-rw-r--r--. 1 root root 497 Mar 15 23:24 work.sh
[root@localhost myshell_study]#
正则表达式的练习3
需求如下:
1、批量创建加密用户
----------------
[root@localhost shell_study]# vim user_add.sh
[root@localhost shell_study]# ls
user_add.sh
[root@localhost shell_study]# bash user_add.sh
Changing password for user user1.
passwd: all authentication tokens updated successfully.
Changing password for user user2.
passwd: all authentication tokens updated successfully.
[root@localhost shell_study]# ls
user_add.sh userinfo.txt
[root@localhost shell_study]# cat userinfo.txt
userid:user1 sec:0a1d53
userid:user2 sec:22aa47
[root@localhost shell_study]# su user1
[user1@localhost shell_study]$ su user2
Password:
[user2@localhost shell_study]$
----------------------------------------------------------
[root@localhost shell_study]# ls
user_add.sh user_del.sh userinfo.txt
[root@localhost shell_study]# cat user_del.sh
#!/bin/bash
# 批量删除加密用户
# ----------------
for i in {1..2}
do
userdel user$i &>/dev/null
done
[root@localhost shell_study]# bash user_del.sh
[root@localhost shell_study]# ls
user_add.sh user_del.sh userinfo.txt
[root@localhost shell_study]# su user1
su: user user1 does not exist
[root@localhost shell_study]# su user2
su: user user2 does not exist
[root@localhost shell_study]#
2020年3月21日09:18:31