推荐算法4—基于物品的协同过滤算法
(1) 计算物品之间的相似度。
(2) 根据物品的相似度和用户的历史行为给用户生成推荐列表。
1 基础算法
我们可以用下面的公式定义物品的相似度:
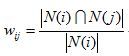
分母|N(i)|是喜欢物品i的用户数,而分子是同时喜欢物品i和物品j的用户数。因此,上述公式可以理解为喜欢物品i的用户中有多少比例的用户也喜欢物品j。上述公式虽然看起来很有道理,但是却存在一个问题。如果物品j很热门,很多人都喜欢,那么Wij就会很大,接近1。因此,该公式会造成任何物品都会和热门的物品有很大的相似度。
为了避免推荐出热门的物品,可以用下面的公式:
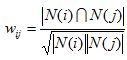
这个公式惩罚了物品j的权重,因此减轻了热门物品会和很多物品相似的可能性。从上面的定义可以看到,在协同过滤中两个物品产生相似度是因为它们共同被很多用户喜欢,也就是说每个用户都可以通过他们的历史兴趣列表给物品“贡献”相似度。
和UserCF算法类似,用ItemCF算法计算物品相似度时也可以首先建立用户—物品倒排表(即对每个用户建立一个包含他喜欢的物品的列表),然后对于每个用户,将他物品列表中的物品两两在共现矩阵C中加1。详细代码如下所示:
def ItemSimilarity(train):
#calculate co-rated users between items
C = dict()
N = dict()
for u, items in train.items():
for i in users:
N[i] += 1
for j in users:
if i == j:
continue
C[i][j] += 1
#calculate finial similarity matrix W
W = dict()
for i,related_items in C.items():
for j, cij in related_items.items():
W[u][v] = cij / math.sqrt(N[i] * N[j])
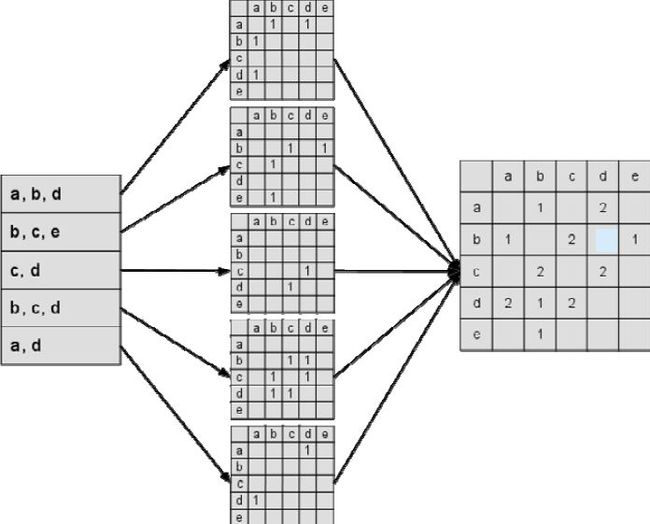
return W下图是一个根据上面的程序计算物品相似度的简单例子。图中最左边是输入的用户行为记录,每一行代表一个用户感兴趣的物品集合。然后,对于每个物品集合,我们将里面的物品两两加一,得到一个矩阵。最终将这些矩阵相加得到上面的C矩阵。其中C[i][j]记录了同时喜欢物品i和物品j的用户数。最后,将C矩阵归一化可以得到物品之间的余弦相似度矩阵W。
在得到物品之间的相似度后,ItemCF通过如下公式计算用户u对一个物品j的兴趣:![]()
这里N(u)是用户喜欢的物品的集合,S(j,K)是和物品j最相似的K个物品的集合,wji是物品j和i的相似度,rui是用户u对物品i的兴趣。(对于隐反馈数据集,如果用户u对物品i有过行为,即可令rui=1。)该公式的含义是,和用户历史上感兴趣的物品越相似的物品,越有可能在用户的推荐列表中获得比较高的排名。该公式的实现代码如下所示。
def Recommendation(train, user_id, W, K):
rank = dict()
ru = train[user_id]
for i,pi in ru.items():
for j, wj in sorted(W[i].items(), key=itemgetter(1), reverse=True)[0:K]:
if j in ru:
continue
rank[j] += pi * wj
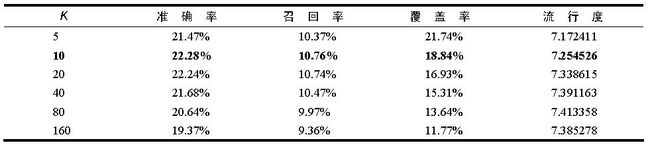
return rank精度(准确率和召回率) 可以看到ItemCF推荐结果的精度也是不和K成正相关或者负相关的,因此选择合适的K对获得最高精度是非常重要的。
流行度 和UserCF不同,参数K对ItemCF推荐结果流行度的影响也不是完全正相关的。随着K的增加,结果流行度会逐渐提高,但当K增加到一定程度,流行度就不会再有明显变化。
覆盖率 K增加会降低系统的覆盖率。
2 用户活跃度对物品相似度的影响
John S. Breese中提出了一个称为IUF(Inverse User Frequence),即用户活跃度对数的倒数的参数,他也认为活跃用户对物品相似度的贡献应该小于不活跃的用户,他提出应该增加IUF参数来修正物品相似度的计算公式:

当然,上面的公式只是对活跃用户做了一种软性的惩罚,但对于很多过于活跃的用户,,为了避免相似度矩阵过于稠密,我们在实际计算中一般直接忽略他的兴趣列表,而不将其纳入到相似度计算的数据集中。ItemCF-IUF算法如下
def ItemSimilarity(train):
#calculate co-rated users between items
C = dict()
N = dict()
for u, items in train.items():
for i in users:
N[i] += 1
for j in users:
if i == j:
continue
C[i][j] += 1 / math.log(1 + len(items) * 1.0)
#calculate finial similarity matrix W
W = dict()
for i,related_items in C.items():
for j, cij in related_items.items():
W[u][v] = cij / math.sqrt(N[i] * N[j])
return W3 物品相似度的归一化
Karypis在研究中发现如果将ItemCF的相似度矩阵按最大值归一化,可以提高推荐的准确率。其研究表明,如果已经得到了物品相似度矩阵w,那么可以用如下公式得到归一化之后的相似度矩阵w':
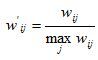
其实,归一化的好处不仅仅在于增加推荐的准确度,它还可以提高推荐的覆盖率和多样性。