
前言:近期,智能大数据服务商“个推”推出了应用统计产品“个数”,今天我们就和大家来谈一谈个数实时统计与AI数据智能平台整合架构设计。
很多人可能好奇,拥有数百亿SDK的个推,专注消息推送服务多年,现在为什么要做应用统计?毕竟市面上已经有非常多的类似产品了。我认为答案是“天时地利人和”。
首先是天时。目前,互联网行业已发展到了所谓的“下半场”甚至是“加时赛”,运营工作走向精细化,DAU和效果被放到第一位,从业者们也逐步认识到数据优化及使用良好的模型的重要性。
其二是地利。个推经过多年的积累,拥有了坚实的数据基础;另外,个推基础架构也非常成熟,并在诸多垂直领域实实在在提供了很多数据服务。
第三是人和。内部的研发人员在实战中积累了丰富的经验,公司与外部应用开发者和合作伙伴建立了长期紧密的联系。
正是在这样的背景下,我们推出了这一款应用统计产品“个数”。
前段时间流行的词汇是“growth hacker”,而现阶段,单纯的用户增长已经无法满足发展,公司及产品的思考点都在于“效果”。相比于其他统计产品,个数产品的灵魂是运营,即围绕着核心KPI,保持应用的活跃度,提高整体的收益。
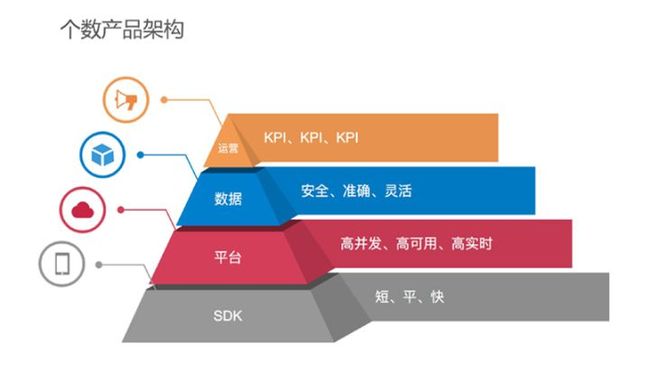
安全、准确、灵活的数据能够保证运营工作的有效开展;而承载数据的平台则需做到高并发、高可用、高实时;SDK作为基础,其核心在于包的体积足够小,并且集成方便,能够快速运行。这样一个从上到下的金字塔,构建起了个数产品。
四大核心能力,打造智能化统计
首先,实时的多维统计是整个应用统计的基础功能。其中,稳定与实时是两大关键;在颗粒度方面,页面级统计最适合运营者。
第二部分是数据整合。利用个推的大数据能力,我们能够提供独特的第三方视角,帮助应用认清自身,并找到它在行业内的地位。
第三部分是自动建模预测。这是个数非常独特的功能点。我们希望通过一整套解决方案,帮助应用开发者真正体验到模型的价值,并通过实际数据反馈,不断优化改进产品。
第四部分是精准推送。个推最广为人知的能力就是推送服务,而将应用内的统计数据与推送系统有效整合,能够辅助更加精细化的运营。
技术架构:业务域+数据域
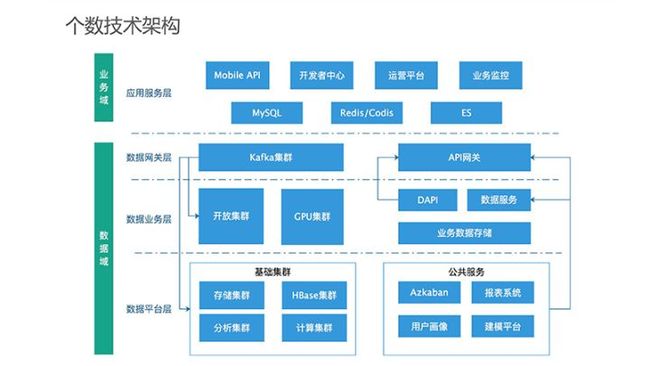
个数的整体架构分为业务域与数据域。其中,数据域分为三个层面:数据网关层、数据业务层和数据平台层。
数据网关层主要做业务层与数据层之间的承载,包括Kafka集群与API网关,使得上下数据互通。数据业务层部分主要基于特定业务的研发工作,由于这部分工作不在平台间通用,因而是独立的一层。在这一层下,产品根据功能的不同配置了若干个独立的Hadoop集群,同时把核心能力包装成公共服务,提供给业务研发人员使用。
业务域部分包括了传统的微服务及相应的存储模块。
第一,这两层之间的数据防火墙非常重要,二级数据防火墙可确保系统内部数据的有效隔离。
第二,数据域的分层。对此,个数架构上设立的三层对应三个不同的职能团队,数据网管层—数据运维,数据业务层—业务线的研发团队,数据平台层—数据部门,这样的职能划分可以有效提升业务线产品研发效率。
第三,集群资源的隔离。业务线的开放集群需要通过资源划分的方式,实现资源的隔离。此外,隔离GPU计算集群资源也是非常有必要的。
第四,实时与离线的兼顾。在开发时,无论是何种产品,我们始终需要把实时和离线两种情况考虑在内。
最后,数据储存。业务线、数据层、平台层都要有相应的数据储存。此外,应通过合理的规划,确保每一类数据存放在合适的位置。
实时多维统计架构解析
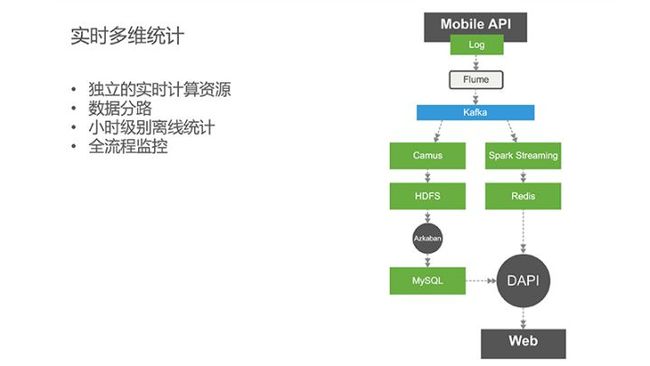
Mobile API从SDK收集到上报的数据,以文件形式Log保存下来,通过Flume进入到Kafka,接下来通过实时与离线两条路进行处理,最后通过数据API封装提供给上层的业务系统使用。
在离线统计方面,个数可支持到小时级别。同时,我们会全流程监控数据的流转情况,当出现数据丢失或者延迟等情况时,确保第一时间监测到。
在这里需要补充几个关键的、需要解决的点:用户去重、页面的唯一性标识、多维度统计的处理策略,以及保证数据在各个环节中不丢失。
数据整合,提供多维指标
个推拥有强大的大数据能力,可以为应用统计产品提供丰富的数据维度。
首先,设备指纹。目前移动设备存在兼容性混乱等问题,个推则通过为应用打上唯一的设备ID标识来解决这个问题。
第二,以第三方视角提供应用留存、安装、卸载,活跃等中立的分析数据。
第三,用户画像。无论是性别、年龄段等静态标签,还是兴趣爱好等标签,都可通过个推的大数据平台获得。
自动建模预测&模型评估
一个标准化的建模工作大体包含以下几个步骤:首先选取一批正负样本用户;然后对其进行特征补全,把无关特征进行降维操作;之后,选择合适的模型进行训练,这也是一个非常消耗CPU的过程;接下来是目标预测,我们需要整理或补齐目标用户的所有特征,再将数据投入模型中,获得预测结果;最后是模型评估。模型评估之后,再进行下一个迭代调整,循环往复。
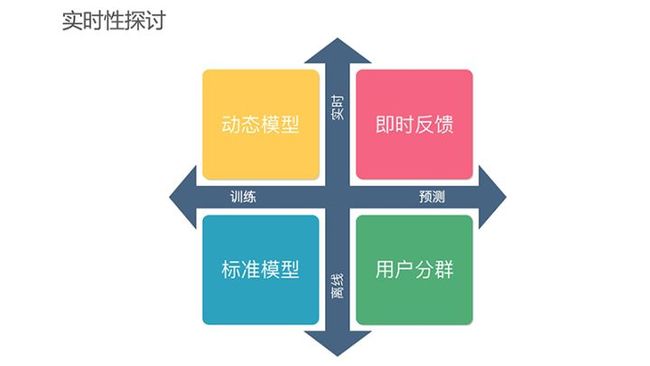
在建模环节,实时性是需要考虑的重要因素之一。最传统的离线训练是很常规的建模方式。预测可以选择高性能的离线方式,但它的缺点是反馈太慢,有可能导致结果出来之前没有其他的机会实施运营方案,因而我们需要提供更实时的预测功能。比如用户新安装或完成某个操作之后,系统实时获得预测结果,并立即进行运营干预。
最后是实时训练,从我个人的角度来看,这是未来发展的一个方向。
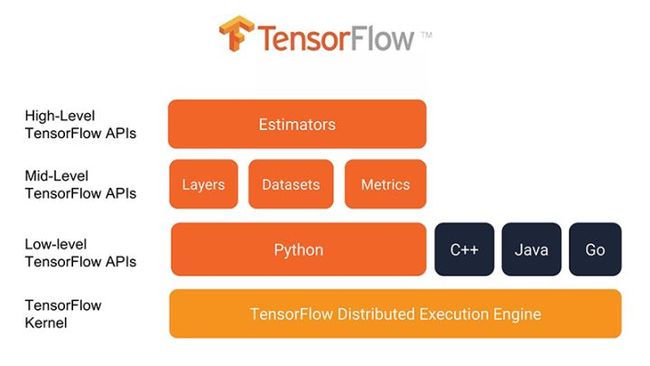
对于整个建模的基础架构,毫无疑问我们选择了tensorflow,目前主流的模型都可以在tensorflow下实现。它拥有诸多优点:支持分布式部署,可并发、集成扩展,可支撑集群Serving,能够以API形式提供模型服务……因而它非常适合预测服务的技术架构。
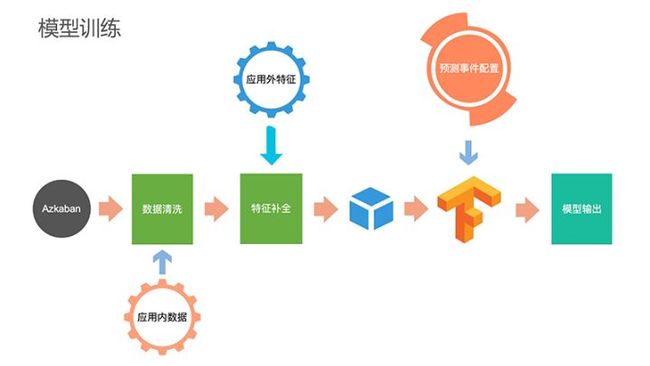
离线建模过程如下:数据落到HDFS之后,先通过Azkaban进行任务调度,数据清洗后把应用内的统计数据收集汇总,接下来将个推拥有的大数据能力与之进行整合,形成整体的数据Cube输入到TF集群,TF集群会根据预测事件的配置,综合进行模型训练,最后输出结果。
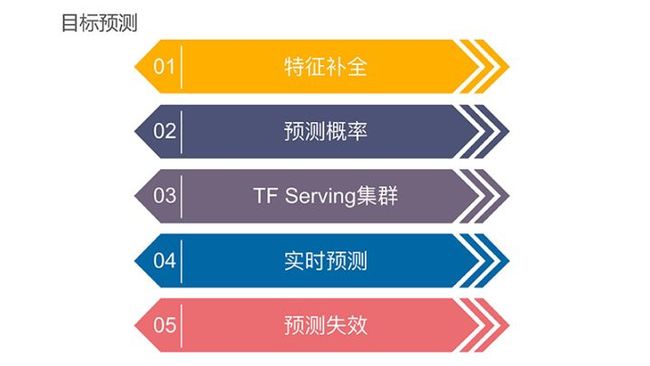
目标预测实现方案相对简单,只需要把模型导入到tensorflow的Serving集群即可。预测结果再通过DAPI封装出来,给到上层业务层调用。
目标预测首先要进行特征补全。这项工作极富挑战,需要针对每一个新用户的要求尽快预测并完美地补全特征。
第二部分是预测结果。预测最终得到的是概率值,我们需要去评估概率值是否处在合理范围内,概率分布是否符合我们的预期。如果不达标,我们就需要重新评估这个模型,或者认为预测是失效的。
第三部分是tensorflow集群。通过容器化部署,可以将预测服务部署到独立的Pod上。根据不同的实时性要求,个数可通过API的形式提供对外服务,也可以提供实时回调。
模型评估是预测的关键步骤,评价体系不完备可能直接导致最后的结果不可用。
精准率与召回率,这两个与预测准确度相关的基础指标是需要重点关注的。由于精确度与阈值相关,我们也支持开发者自主调整。
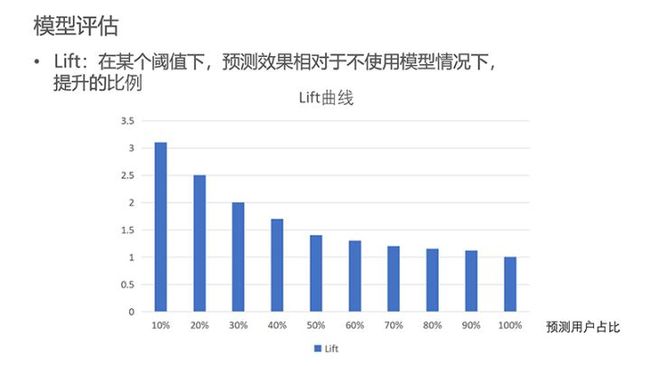
Lift也是一项重要指标,它反映了我们的预测能够产生多大的效果提升。显而易见,筛选的人群比例越大,提升的比例会逐渐递减。具体应用的时候,我们需要根据场景或需求来选择一个合理的值。
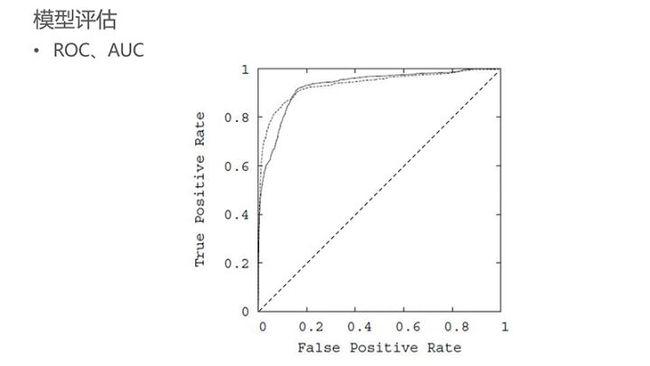
ROC与AOC,这两个指标作为模型整体评估指标,用于评估在不同阈值下模型的表现。为提升模型的区分能力,我们势必会追求AOC最大化。AOC值是一个定量的指标,适合做模型的持续监控。此外,对模型做每日评估也是必要的,如果AOC值不能够达到预期,我们可以及时选择其他模型。
在监控方面,首先要确保测试用户的选择足够随机。我们每天会选择一批测试用户来验证模型的效果,然后评估准确率、召回率以及AOC。除了内部校验,我们也会把这个指标提供给开发者。同时,缓存预测结果的历史数据,可以辅助每天的效果评估。
精准推送集成,增能实际场景
应用内埋点数据和预测结果可以通过个数传递到推送系统,方便开发者在推送环节直接以人群包的形式选择目标用户,或者下载这个人群包,上传到广点通等平台做广告投放。
个数Roadmap
个数产品在5月份已经正式对外开放,大家可以在http://www.getui.com/cn/geshu.html自由注册并使用。模型预测功能目前处于测试阶段,我们希望到Q4时,能够正式把能力对外开放出来,帮助大家认识模型、使用模型,并享受模型带来的价值。