Android GraphicBuffer分配过程
Android系统定义GraphicBuffer数据类型来描述一块图形buffer,该对象可以跨进程传输。

IGraphicBufferAlloc是专门用于分配GraphicBuffer对象的工具类,该类是基于Binder进程间通信机制框架设计的,其类继承关系如下:
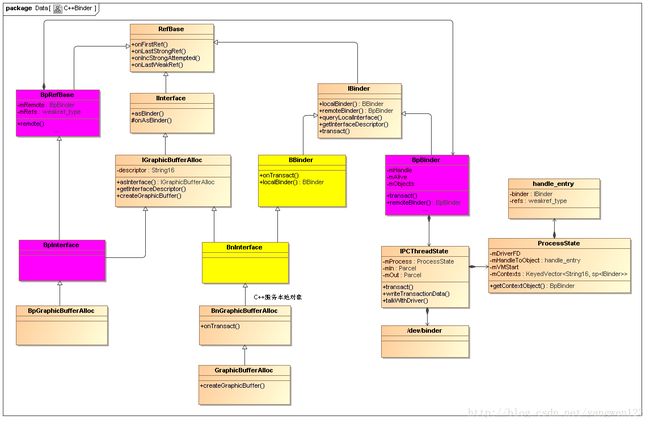
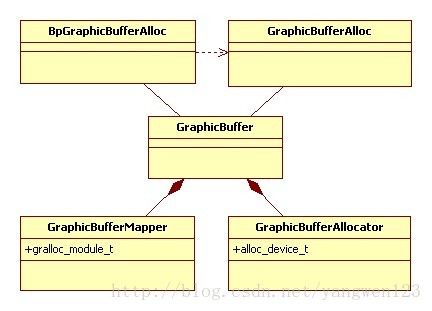
由于IGraphicBufferAlloc是基于Binder进程间通信框架设计的,因此该类的实现分客户端进程和服务端进程两方面。从上图可以知道,客户端进程通过BpGraphicBufferAlloc对象请求服务端进程中的GraphicBufferAlloc对象来创建GraphicBuffer对象。
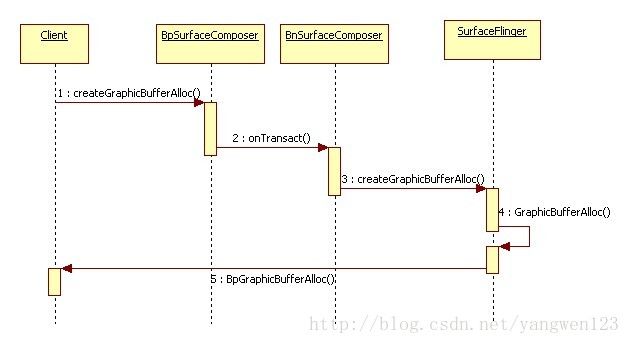
那如何获取IGraphicBufferAlloc的远程Binder代理对象呢?IGraphicBufferAlloc被定义为无名Binder对象,并没有注册到ServiceManager进程中,但SurfaceFlinger是有名Binder对象,因此可以通过SurfaceFlinger创建IGraphicBufferAlloc的本地对象GraphicBufferAlloc,并返回其远程代理对象BpGraphicBufferAlloc给客户端进程。那客户端进程又是如何请求SurfaceFlinger创建IGraphicBufferAlloc的本地对象的呢?客户端进程首先从ServiceManager进程中查询SurfaceFlinger的远程代理对象BpSurfaceComposer:
sp composer(ComposerService::getComposerService()); mGraphicBufferAlloc = composer->createGraphicBufferAlloc();virtual sp createGraphicBufferAlloc()
{
uint32_t n;
Parcel data, reply;
data.writeInterfaceToken(ISurfaceComposer::getInterfaceDescriptor());
remote()->transact(BnSurfaceComposer::CREATE_GRAPHIC_BUFFER_ALLOC, data, &reply);
return interface_cast(reply.readStrongBinder());
}
status_t BnSurfaceComposer::onTransact(uint32_t code, const Parcel& data, Parcel* reply, uint32_t flags)
{
switch(code) {
case CREATE_GRAPHIC_BUFFER_ALLOC: {
CHECK_INTERFACE(ISurfaceComposer, data, reply);
sp b = createGraphicBufferAlloc()->asBinder();
reply->writeStrongBinder(b);
} break;
default:
return BBinder::onTransact(code, data, reply, flags);
}
return NO_ERROR;
} sp SurfaceFlinger::createGraphicBufferAlloc()
{
sp gba(new GraphicBufferAlloc());
return gba;
} 关于Binder进程间通信过程请参考Android服务函数远程调用源码分析。这样就在服务进程创建了一个GraphicBufferAlloc本地对象,同时将代理对象BpGraphicBufferAlloc返回到客户进程。客户进程获得IGraphicBufferAlloc的代理对象后,就可以请求服务端GraphicBufferAlloc创建GraphicBuffer对象了。
客户端进程BpGraphicBufferAlloc请求创建GraphicBuffer:
frameworks\native\include\gui\IGraphicBufferAlloc.h
virtual sp createGraphicBuffer(uint32_t w, uint32_t h,
PixelFormat format, uint32_t usage, status_t* error) {
Parcel data, reply;
data.writeInterfaceToken(IGraphicBufferAlloc::getInterfaceDescriptor());
data.writeInt32(w);
data.writeInt32(h);
data.writeInt32(format);
data.writeInt32(usage);
remote()->transact(CREATE_GRAPHIC_BUFFER, data, &reply);
sp graphicBuffer;
status_t result = reply.readInt32();
if (result == NO_ERROR) {
graphicBuffer = new GraphicBuffer();
reply.read(*graphicBuffer);
}
*error = result;
return graphicBuffer;
} status_t BnGraphicBufferAlloc::onTransact(
uint32_t code, const Parcel& data, Parcel* reply, uint32_t flags)
{
switch(code) {
case CREATE_GRAPHIC_BUFFER: {
CHECK_INTERFACE(IGraphicBufferAlloc, data, reply);
uint32_t w = data.readInt32();
uint32_t h = data.readInt32();
PixelFormat format = data.readInt32();
uint32_t usage = data.readInt32();
status_t error;
sp result =createGraphicBuffer(w, h, format, usage, &error);
reply->writeInt32(error);
if (result != 0) {
reply->write(*result);
reply->writeStrongBinder( new BufferReference(result) );
}
return NO_ERROR;
} break;
default:
return BBinder::onTransact(code, data, reply, flags);
}
} sp GraphicBufferAlloc::createGraphicBuffer(uint32_t w, uint32_t h,
PixelFormat format, uint32_t usage, status_t* error) {
sp graphicBuffer(new GraphicBuffer(w, h, format, usage));
status_t err = graphicBuffer->initCheck();
*error = err;
if (err != 0 || graphicBuffer->handle == 0) {
if (err == NO_MEMORY) {
GraphicBuffer::dumpAllocationsToSystemLog();
}
return 0;
}
return graphicBuffer;
} GraphicBuffer::GraphicBuffer(uint32_t w, uint32_t h,
PixelFormat reqFormat, uint32_t reqUsage)
: BASE(), mOwner(ownData), mBufferMapper(GraphicBufferMapper::get()),
mInitCheck(NO_ERROR), mIndex(-1)
{
width =
height =
stride =
format =
usage = 0;
handle = NULL;
mInitCheck = initSize(w, h, reqFormat, reqUsage);
}status_t GraphicBuffer::initSize(uint32_t w, uint32_t h, PixelFormat format,
uint32_t reqUsage)
{
GraphicBufferAllocator& allocator = GraphicBufferAllocator::get();
status_t err = allocator.alloc(w, h, format, reqUsage, &handle, &stride);
if (err == NO_ERROR) {
this->width = w;
this->height = h;
this->format = format;
this->usage = reqUsage;
}
return err;
}sp result = createGraphicBuffer(w, h, format, usage, &error);
reply->writeInt32(error);
if (result != 0) {
reply->write(*result);
reply->writeStrongBinder( new BufferReference(result) );
} status_t Parcel::write(const Flattenable& val)
{
status_t err;
// size if needed
size_t len = val.getFlattenedSize();
size_t fd_count = val.getFdCount();
//写入数据长度
err = this->writeInt32(len);
if (err) return err;
//写入句柄个数
err = this->writeInt32(fd_count);
if (err) return err;
//写入数据
void* buf = this->writeInplace(PAD_SIZE(len));
if (buf == NULL)
return BAD_VALUE;
int* fds = NULL;
if (fd_count) {
fds = new int[fd_count];
}
//写入句柄值
err = val.flatten(buf, len, fds, fd_count);
for (size_t i=0 ; iwriteDupFileDescriptor( fds[i] );
}
if (fd_count) {
delete [] fds;
}
return err;
} size_t GraphicBuffer::getFlattenedSize() const {
return (8 + (handle ? handle->numInts : 0))*sizeof(int);
}size_t GraphicBuffer::getFdCount() const {
return handle ? handle->numFds : 0;
}status_t GraphicBuffer::flatten(void* buffer, size_t size,
int fds[], size_t count) const
{
size_t sizeNeeded = GraphicBuffer::getFlattenedSize();
if (size < sizeNeeded) return NO_MEMORY;
size_t fdCountNeeded = GraphicBuffer::getFdCount();
if (count < fdCountNeeded) return NO_MEMORY;
int* buf = static_cast(buffer);
buf[0] = 'GBFR';
buf[1] = width;
buf[2] = height;
buf[3] = stride;
buf[4] = format;
buf[5] = usage;
buf[6] = 0;
buf[7] = 0;
if (handle) {
buf[6] = handle->numFds;
buf[7] = handle->numInts;
native_handle_t const* const h = handle;
memcpy(fds, h->data, h->numFds*sizeof(int));
memcpy(&buf[8], h->data + h->numFds, h->numInts*sizeof(int));
}
return NO_ERROR;
} 
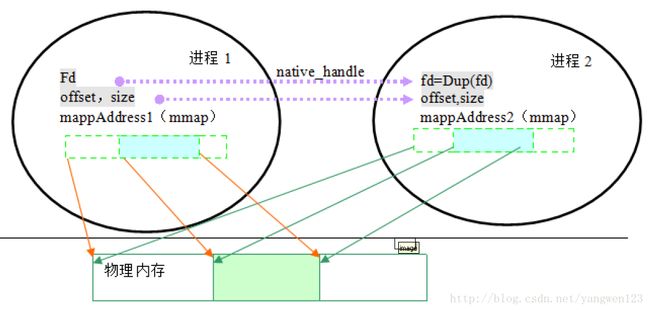
numFds=1表示有一个文件句柄:fd
numInts= 8表示后面跟了8个INT型的数据:magic,flags,size,offset,base,lockState,writeOwner,pid;
服务进程将创建的GraphicBuffer对象的成员变量handle写回到请求创建图形缓冲区的客户进程,这时客户进程通过以下方式就可以读取服务进程返回的关于创建图形buffer的信息数据。
sp graphicBuffer;
status_t result = reply.readInt32();
if (result == NO_ERROR) {
graphicBuffer = new GraphicBuffer();
reply.read(*graphicBuffer);
} status_t Parcel::read(Flattenable& val) const
{
// size
const size_t len = this->readInt32();
const size_t fd_count = this->readInt32();
// payload
void const* buf = this->readInplace(PAD_SIZE(len));
if (buf == NULL)
return BAD_VALUE;
int* fds = NULL;
if (fd_count) {
fds = new int[fd_count];
}
status_t err = NO_ERROR;
for (size_t i=0 ; ireadFileDescriptor());
if (fds[i] < 0) err = BAD_VALUE;
}
if (err == NO_ERROR) {
err = val.unflatten(buf, len, fds, fd_count);
}
if (fd_count) {
delete [] fds;
}
return err;
} status_t GraphicBuffer::unflatten(void const* buffer, size_t size,
int fds[], size_t count)
{
if (size < 8*sizeof(int)) return NO_MEMORY;
int const* buf = static_cast(buffer);
if (buf[0] != 'GBFR') return BAD_TYPE;
const size_t numFds = buf[6];
const size_t numInts = buf[7];
const size_t sizeNeeded = (8 + numInts) * sizeof(int);
if (size < sizeNeeded) return NO_MEMORY;
size_t fdCountNeeded = 0;
if (count < fdCountNeeded) return NO_MEMORY;
if (handle) {
// free previous handle if any
free_handle();
}
if (numFds || numInts) {
width = buf[1];
height = buf[2];
stride = buf[3];
format = buf[4];
usage = buf[5];
//创建native_handle对象
native_handle* h = native_handle_create(numFds, numInts);
memcpy(h->data, fds, numFds*sizeof(int));
memcpy(h->data + numFds, &buf[8], numInts*sizeof(int));
handle = h;
} else {
width = height = stride = format = usage = 0;
handle = NULL;
}
mOwner = ownHandle;
if (handle != 0) {
//将创建的图形缓冲区映射到客户进程的地址空间来,这样客户端进程就可以直接在图形buffer映射的地址空间绘图
status_t err = mBufferMapper.registerBuffer(handle);
//地址空间映射错误
if (err != NO_ERROR) {
//关闭handle
native_handle_close(handle);
//释放handle
native_handle_delete(const_cast(handle));
handle = NULL;
return err;
}
}
return NO_ERROR;
} native_handle_t* native_handle_create(int numFds, int numInts)
{
native_handle_t* h = malloc(sizeof(native_handle_t) + sizeof(int)*(numFds+numInts));
h->version = sizeof(native_handle_t);
h->numFds = numFds;
h->numInts = numInts;
return h;
}客户端进程读取到服务进程创建的图形buffer的描述信息native_handle后,通过GraphicBufferMapper对象mBufferMapper的registerBuffer函数将创建的图形buffer映射到客户端进程地址空间,关于图形缓冲区的映射过程请参考Android图形缓冲区映射过程源码分析。
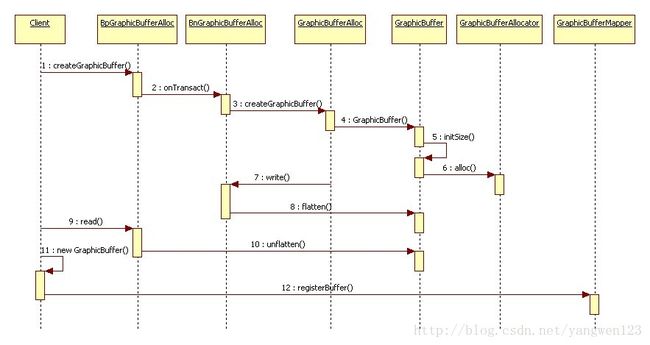
这样就将Private_native_t中的数据:magic,flags,size,offset,base,lockState,writeOwner,pid复制到了客户端进程。服务端(SurfaceFlinger)分配了一段内存作为Surface的作图缓冲区,客户端怎样在这个作图缓冲区上绘图呢?两个进程间如何共享内存,这就需要GraphicBufferMapper将分配的图形缓冲区映射到客户端进程地址空间。对于共享缓冲区,他们操作同一物理地址的内存块。