1、索引结构。第一张图是索引的官方图解,右侧是存储方式的图解。

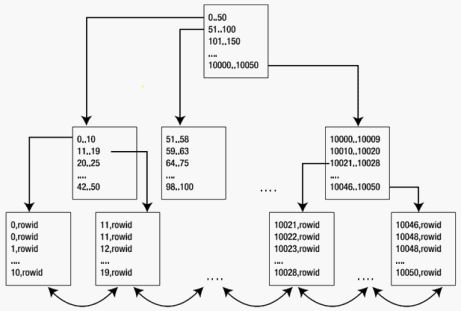
图中很清晰的展示了索引存储的状况。
在leaf 节点中存储了一列,索引所对应项的 :值,rowId,长度,头信息(控制信息)
这样我们就能很清楚、如果通过索引查找数据,而只需要这个索引的值的时候,写上列名,就可以不需要回表。
2、索引在一般的数据量情况下,只有三层。leaf 是目录,branch 是目录的目录。可以做一个测试


1 drop table t1 purge; 2 drop table t2 purge; 3 drop table t3 purge; 4 drop table t4 purge; 5 drop table t5 purge; 6 drop table t6 purge; 7 drop table t7 purge; 8 9 10 create table t1 as select rownum as id ,rownum+1 as id2,rpad('*',1000,'*') as contents from dual connect by level<=1; 11 create table t2 as select rownum as id ,rownum+1 as id2,rpad('*',1000,'*') as contents from dual connect by level<=10; 12 create table t3 as select rownum as id ,rownum+1 as id2,rpad('*',1000,'*') as contents from dual connect by level<=100; 13 create table t4 as select rownum as id ,rownum+1 as id2,rpad('*',1000,'*') as contents from dual connect by level<=1000; 14 create table t5 as select rownum as id ,rownum+1 as id2,rpad('*',1000,'*') as contents from dual connect by level<=10000; 15 create table t6 as select rownum as id ,rownum+1 as id2,rpad('*',1000,'*') as contents from dual connect by level<=100000; 16 create table t7 as select rownum as id ,rownum+1 as id2,rpad('*',1000,'*') as contents from dual connect by level<=1000000; 17 18 19 create index idx_id_t1 on t1(id); 20 create index idx_id_t2 on t2(id); 21 create index idx_id_t3 on t3(id); 22 create index idx_id_t4 on t4(id); 23 create index idx_id_t5 on t5(id); 24 create index idx_id_t6 on t6(id); 25 create index idx_id_t7 on t7(id); 26 27 set linesize 1000 28 set autotrace off 29 select index_name, 30 blevel, 31 leaf_blocks, 32 num_rows, 33 distinct_keys, 34 clustering_factor 35 from user_ind_statistics 36 where table_name in( 'T1','T2','T3','T4','T5','T6','T7'); 37 38 索引的名字 层级 leaf 块 39 INDEX_NAME BLEVEL LEAF_BLOCKS NUM_ROWS DISTINCT_KEYS CLUSTERING_FACTOR 40 ------------------ ----------- ---------- ------------- ----------------- 41 IDX_ID_T1 0 1 1 1 1 42 IDX_ID_T2 0 1 10 10 2 43 IDX_ID_T3 0 1 100 100 15 44 IDX_ID_T4 1 3 1000 1000 143 45 IDX_ID_T5 1 21 10000 10000 1429 46 IDX_ID_T6 1 222 100000 100000 14286 47 IDX_ID_T7 2 2226 1000000 1000000 142858
数据在一千万条的时候也只有三层(查到数据只需要四个逻辑读),所以即便上亿数据,也无非十个左右的逻辑读,充分了体现了索引的优点。如果不建索引,那么全表扫描是很恐怖的。
3、索引在函数运算上能起到优化作用,比如sum,avg,count
在没有主键,只有索引的表中count*的时候,由于索引不记录空值,所以它不会走索引,如果对索引列加上 not null“select count(*) from user where userId not null”,就能走索引、当然如果有主键自然就不必了。
各种函数,运算列如果是索引列的话效率就会大幅度提高,可以看下面例子
1 SUM/AVG的优化 2 drop table t purge; 3 create table t as select * from dba_objects; 4 create index idx1_object_id on t(object_id); 5 set autotrace on 6 set linesize 1000 7 set timing on 8 9 select sum(object_id) from t; 10 执行计划 11 ---------------------------------------------------------------------------------------- 12 | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | 13 ---------------------------------------------------------------------------------------- 14 | 0 | SELECT STATEMENT | | 1 | 13 | 49 (0)| 00:00:01 | 15 | 1 | SORT AGGREGATE | | 1 | 13 | | | 16 | 2 | INDEX FAST FULL SCAN| IDX1_OBJECT_ID | 92407 | 1173K| 49 (0)| 00:00:01 | 17 ---------------------------------------------------------------------------------------- 18 统计信息 19 ---------------------------------------------------------- 20 0 recursive calls 21 0 db block gets 22 170 consistent gets 23 0 physical reads 24 0 redo size 25 432 bytes sent via SQL*Net to client 26 415 bytes received via SQL*Net from client 27 2 SQL*Net roundtrips to/from client 28 0 sorts (memory) 29 0 sorts (disk) 30 1 rows processed 31 32 --比较一下假如不走索引的代价,体会一下这个索引的重要性 33 select /*+full(t)*/ sum(object_id) from t; 34 SUM(OBJECT_ID) 35 -------------- 36 2732093100 37 执行计划 38 --------------------------------------------------------------------------- 39 | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | 40 --------------------------------------------------------------------------- 41 | 0 | SELECT STATEMENT | | 1 | 13 | 292 (1)| 00:00:04 | 42 | 1 | SORT AGGREGATE | | 1 | 13 | | | 43 | 2 | TABLE ACCESS FULL| T | 92407 | 1173K| 292 (1)| 00:00:04 | 44 --------------------------------------------------------------------------- 45 统计信息 46 ---------------------------------------------------------- 47 0 recursive calls 48 0 db block gets 49 1047 consistent gets 50 0 physical reads 51 0 redo size 52 432 bytes sent via SQL*Net to client 53 415 bytes received via SQL*Net from client 54 2 SQL*Net roundtrips to/from client 55 0 sorts (memory) 56 0 sorts (disk) 57 1 rows processed 58 59 --起来类似的比如AVG,和SUM是一样的,如下: 60 select avg(object_id) from t; 61 AVG(OBJECT_ID) 62 -------------- 63 37365.5338 64 执行计划 65 ---------------------------------------------------------------------------------------- 66 | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | 67 ---------------------------------------------------------------------------------------- 68 | 0 | SELECT STATEMENT | | 1 | 13 | 49 (0)| 00:00:01 | 69 | 1 | SORT AGGREGATE | | 1 | 13 | | | 70 | 2 | INDEX FAST FULL SCAN| IDX1_OBJECT_ID | 92407 | 1173K| 49 (0)| 00:00:01 | 71 ---------------------------------------------------------------------------------------- 72 统计信息 73 ---------------------------------------------------------- 74 0 recursive calls 75 0 db block gets 76 170 consistent gets 77 0 physical reads 78 0 redo size 79 448 bytes sent via SQL*Net to client 80 415 bytes received via SQL*Net from client 81 2 SQL*Net roundtrips to/from client 82 0 sorts (memory) 83 0 sorts (disk) 84 1 rows processed 85 86 --不知大家注意到没,这里的试验已经告诉我们了,OBJECT_ID列是否为空,也不影响SUM/AVG等聚合的结果。
可以从执行计划中看到 consistent gets 走索引是 一百多, 而不走索引就上千,效率成倍增加。
4、索引本身有序
通过索引列排序,不会产生排序 ,但是io多,代价小。排序代价是很大的。 由于本身有序,获取最大值,最小值,也是高效的。
二、组合索引。(索引只适合返回少量记录)
1、适用在单独查询返回记录很多,组合查询后忽然返回记录很少的情况
比如:1某地区的贷款条数很多,2涉农贷款条数很多,3某地区贷款金额在某区间的贷款数很多
但是,某地区,涉农贷款,金额某区间的 贷款条数 就很少。
当涉及某些组合条件检索数据时,就可以采用组合索引的形式,
create index area_loanType_ on t(area_id,loan_type);
而时间是做了分区表的,所以在这种情况下、检索速度会大大提高。
2.组合索引第一个索引的重要性。
由于组合索引是仅仅相对于前一个索引有意义,所以,当查询时,只通过第二个索引列查询,是不会走索引的,它的存在的意义只能是在使用第一个索引的情况下。
但是,只通过第一个索引列 查询、是会走索引的。所以第一个索引也是常用,并且有单独查寻需要的列。
当然如果前一个索引的值很少,比如loanType(涉农,个体,工业,慈善..) 共六七个而已,那么Oracle 收集了统计信息后,可以索引跳跃扫描,类似与 SELECT * from loans where areaId="" and loanType in (慈善,个体,工业...)and(第三个组合索引 的条件)
3.仅等值无范围查询时,组合索引顺序不影响性能
比如:
1 --3.仅等值无范围查询时,组合索引顺序不影响性能(比如where col1=xxx and col2=xxx,无论COL1+COL2组合还是COL2+COL1组合) 2 3 drop table t purge; 4 create table t as select * from dba_objects; 5 insert into t select * from t; 6 insert into t select * from t; 7 insert into t select * from t; 8 update t set object_id=rownum ; 9 commit; 10 create index idx_id_type on t(object_id,object_type); 11 create index idx_type_id on t(object_type,object_id); 12 set autotrace off 13 alter session set statistics_level=all ; 14 set linesize 366 15 16 select /*+index(t,idx_id_type)*/ * from t where object_id=20 and object_type='TABLE'; 17 select * from table(dbms_xplan.display_cursor(null,null,'allstats last')); 18 ----------------------------------------------------------------------------------------------------- 19 | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | 20 ----------------------------------------------------------------------------------------------------- 21 | 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.01 | 5 | 22 | 1 | TABLE ACCESS BY INDEX ROWID| T | 1 | 57 | 1 |00:00:00.01 | 5 | 23 |* 2 | INDEX RANGE SCAN | IDX_ID_TYPE | 1 | 9 | 1 |00:00:00.01 | 4 | 24 ----------------------------------------------------------------------------------------------------- 25 26 select /*+index(t,idx_type_id)*/ * from t where object_id=20 and object_type='TABLE'; 27 select * from table(dbms_xplan.display_cursor(null,null,'allstats last')); 28 Plan hash value: 3420768628 29 30 ----------------------------------------------------------------------------------------------------- 31 | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | 32 ----------------------------------------------------------------------------------------------------- 33 | 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.01 | 5 | 34 | 1 | TABLE ACCESS BY INDEX ROWID| T | 1 | 57 | 1 |00:00:00.01 | 5 | 35 |* 2 | INDEX RANGE SCAN | IDX_TYPE_ID | 1 | 9 | 1 |00:00:00.01 | 4 | 36 ----------------------------------------------------------------------------------------------------- 37 38 39 --4.组合索引最佳顺序一般是将列等值查询的列置前。(测试组合索引在条件是不等的情况下的情况,条件经常是不等的,要放在后面,让等值的在前面) 40 41 select /*+index(t,idx_id_type)*/ * from t where object_id>=20 and object_id<2000 and object_type='TABLE'; 42 select * from table(dbms_xplan.display_cursor(null,null,'allstats last')); 43 ----------------------------------------------------------------------------------------------------- 44 | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | 45 ----------------------------------------------------------------------------------------------------- 46 | 0 | SELECT STATEMENT | | 1 | | 469 |00:00:00.01 | 86 | 47 | 1 | TABLE ACCESS BY INDEX ROWID| T | 1 | 14 | 469 |00:00:00.01 | 86 | 48 |* 2 | INDEX RANGE SCAN | IDX_ID_TYPE | 1 | 1 | 469 |00:00:00.01 | 40 | 49 ----------------------------------------------------------------------------------------------------- 50 51 52 53 54 select /*+index(t,idx_type_id)*/ * from t where object_id>=20 and object_id<2000 and object_type='TABLE'; 55 ----------------------------------------------------------------------------------------------------- 56 | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | 57 ----------------------------------------------------------------------------------------------------- 58 | 0 | SELECT STATEMENT | | 1 | | 469 |00:00:00.01 | 81 | 59 | 1 | TABLE ACCESS BY INDEX ROWID| T | 1 | 469 | 469 |00:00:00.01 | 81 | 60 |* 2 | INDEX RANGE SCAN | IDX_TYPE_ID | 1 | 469 | 469 |00:00:00.01 | 35 | 61 -----------------------------------------------------------------------------------------------------
4、组合索引排序 如果对组合索引中列进行排序,可以走索引。
三、创建索引的一些规则
1、权衡索引个数与DML之间关系,DML也就是插入、删除数据操作。
这里需要权衡一个问题,建立索引的目的是为了提高查询效率的,但建立的索引过多,会影响插入、删除数据的速度,因为我们修改的表数据,索引也要跟着修改。这里需要权衡我们的操作是查询多还是修改多。
2、把索引与对应的表放在不同的表空间。
当读取一个表时表与索引是同时进行的。如果表与索引和在一个表空间里就会产生资源竞争,放在两个表这空就可并行执行。
3、最好使用一样大小是块。
Oracle默认五块,读一次I/O,如果你定义6个块或10个块都需要读取两次I/O。最好是5的整数倍更能提高效率。
4、如果一个表很大,建立索引的时间很长,因为建立索引也会产生大量的redo信息,所以在创建索引时可以设置不产生或少产生redo信息。只要表数据存在,索引失败了大不了再建,所以可以不需要产生redo信息。