node.js react_使用Node和React.js构建实时Twitter流
node.js react
介绍 (Introduction)
Welcome to the second installation of Learning React, a series of articles focused on becoming proficient and effective with Facebook's React library. If you haven't read the first installation, Getting Started and Concepts, it is highly recommended that you do so before proceeding.
欢迎来到Learning React的第二次安装,该系列的文章重点介绍如何熟练使用Facebook的React库。 如果您尚未阅读第一个安装入门和入门 ,则强烈建议您在继续之前进行阅读。
Today we are going to build an application in React using Isomorphic Javascript.
今天,我们将使用同构Javascript在React中构建应用程序。
Iso-what?
等一下
Isomorphic. Javascript. It means writing one codebase that can run on both the server side and the client side.
同构。 Javascript。 这意味着编写一个可以同时在服务器端和客户端运行的代码库。
This is the concept behind frameworks like Rendr, Meteor & Derby. You can also accomplish this using React, and today we are going to learn how.
这是Rendr , Meteor和Derby等框架背后的概念。 您还可以使用React来完成此任务,今天我们将学习如何做。
为什么这么棒? (Why is this awesome?)
I'm an Angular fan just like everybody else, but one pain point is the potential SEO impact.
我和其他所有人一样都是Angular粉丝,但一个痛点是对SEO的潜在影响。
But I thought Google executes and indexes javascript?
但是我以为Google执行并编制JavaScript索引?
Yeah, not really. They just give you an opportunity to serve up static HTML. You still have to generate that HTML with PhantomJS or a third party service.
是的,不是真的。 它们只是为您提供了提供静态HTML的机会。 您仍然必须使用PhantomJS或第三方服务生成该HTML。
Enter React.
输入React。

React is amazing on the client side, but it's ability to be rendered on the server side makes it truly special. This is because React uses a virtual DOM instead of the real one, and allows us to render our components to markup.
React在客户端方面是惊人的,但是它在服务器端呈现的能力使其真正与众不同。 这是因为React使用的是虚拟DOM而不是真实的DOM,并允许我们将组件呈现为标记。
入门 (Getting Started)
Alright gang, lets get down to brass tacks. We are going to build an app that shows tweets about this article, and loads new ones in real time. Here are the requirements:
好的帮派,让我们开始讨论。 我们将构建一个应用程序,以显示有关本文的推文,并实时加载新推文。 要求如下:
- It should listen to the Twitter streaming API and save new tweets as they come in. 它应该侦听Twitter流API,并保存新的推文。
- On save, an event should be emitted to the client side that will update the views. 保存时,应向客户端发出一个事件,该事件将更新视图。
- The page should render server side initially, and the client side should take it from there. 该页面最初应呈现服务器端,而客户端应从那里获取。
- We should use infinity scroll pagination to load blocks of 10 tweets at a time. 我们应该使用无穷大滚动分页来一次加载10条推文。
- New unread tweets should have a notification bar that will prompt the user to view them. 新的未读推文应具有一个通知栏,提示用户查看它们。
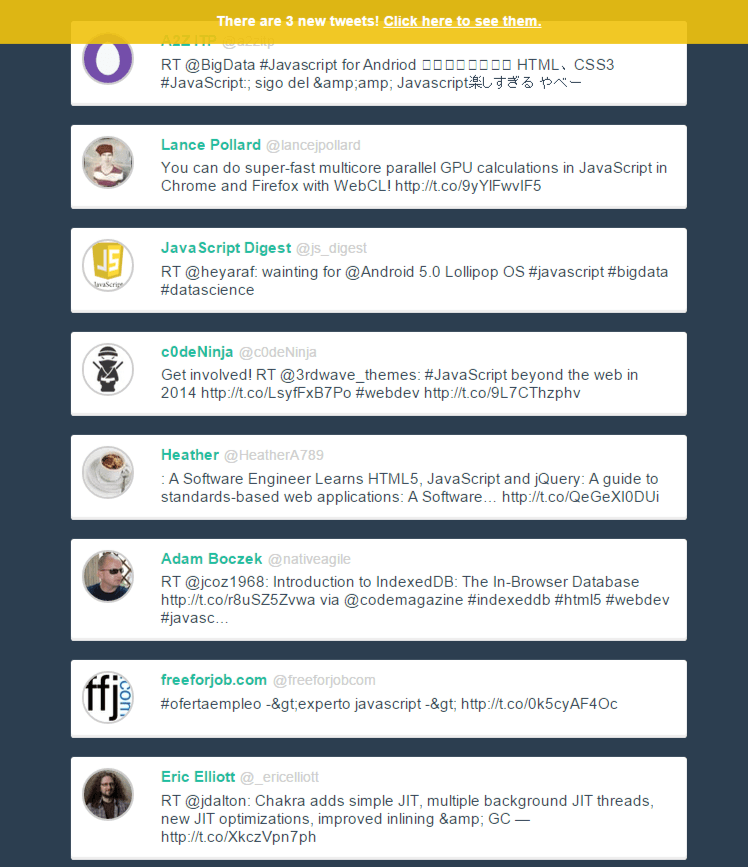
Here is a quick look at what we'll be building. Make sure you check out the demo and to see everything happen in real time.
快速浏览一下我们将要构建的内容。 确保您查看了演示,并实时查看了所有事件。

Let's take a look at some of the tools we are going to use besides React:
让我们看一下除了React之外我们还将使用的一些工具:
- Express - A node.js web application framework Express-一个Node.js Web应用程序框架
- Handlebars - A templating language we are going to write our layout templates in 把手 -一种模板语言,我们将在其中编写布局模板
- Browserify - A dependency bundler that will allow us to use CommonJS syntax Browserify-一个依赖包,它将允许我们使用CommonJS语法
- Mongoose - A mongoDB object modeling library Mongoose-一个mongoDB对象建模库
- Socket.io - Real time bidirectional event based communication Socket.io-基于实时双向事件的通信
- nTwitter - Node.js Twitter API library nTwitter -Node.js Twitter API库
服务器端 (Server Side)
Lets start by building out the server side of our app. Download the project files here, and follow along below:
让我们从构建应用程序的服务器端开始。 在此处下载项目文件,然后执行以下操作:
目录结构 (Directory Structure)
components/ // React Components Directory
---- Loader.react.js // Loader Component
---- NotificationBar.react.js // Notification Bar Component
---- Tweet.react.js // Single Tweet Component
---- Tweets.react.js // Tweets Component
---- TweetsApp.react.js // Main App Component
models/ // Mongoose Models Directory
---- Tweet.js // Our Mongoose Tweet Model
public/ // Static Files Directory
---- css
---- js
---- svg
utils/
----streamHandler.js // Utility method for handling Twitter stream callbacks
views/ // Server Side Handlebars Views
----layouts
-------- main.handlebars
---- home.handlebars
app.js // Client side main
config.js // App configuration
package.json
routes.js // Route definitions
server.js // Server side mainpackage.json (package.json)
{
"name": "react-isomorph",
"version": "0.0.0",
"description": "Isomorphic React Example",
"main": "app.js",
"scripts": {
"watch": "watchify app.js -o public/js/bundle.js -v",
"browserify": "browserify app.js | uglifyjs > public/js/bundle.js",
"build": "npm run browserify ",
"start": "npm run watch & nodemon server.js"
},
"author": "Ken Wheeler",
"license": "MIT",
"dependencies": {
"express": "~4.9.7",
"express-handlebars": "~1.1.0",
"mongoose": "^3.8.17",
"node-jsx": "~0.11.0",
"ntwitter": "^0.5.0",
"react": "~0.11.2",
"socket.io": "^1.1.0"
},
"devDependencies": {
"browserify": "~6.0.3",
"nodemon": "^1.2.1",
"reactify": "~0.14.0",
"uglify-js": "~2.4.15",
"watchify": "~2.0.0"
},
"browserify": {
"transform": [
"reactify"
]
}
}If you're following along, simply run npm install and go get a glass of water. When you get back, we should have all of our dependencies in place, and its time to get our build on.
如果您遵循此步骤,只需运行npm install即可获得一杯水。 当您回来时,我们应该拥有所有依赖关系,并有时间继续构建。
We now have a couple of commands we can use:
现在,我们可以使用几个命令:
npm run watch- Running this command starts a watchify watch, so when we edit our js files, they get browserified on save.npm run watchwatch-运行此命令将启动watchify监视,因此当我们编辑js文件时,会在保存时对它们进行浏览器化。npm run build- Running this command builds our bundle.js and minifies it for productionnpm run buildbuild-运行此命令将构建我们的bundle.js并将其最小化以进行生产npm start- Running this command sets up a watch and runs our app via nodemonnpm startstart-运行此命令可以设置手表并通过nodemon运行我们的应用node server- This command is what we use to run our app. In a production environment, I would recommend using something like forever or pm2.node server-这是我们用于运行应用程序的命令。 在生产环境中,我建议使用诸如ever或pm2之类的东西。
设置我们的服务器 (Setting Up Our Server)
For the purposes of keeping our focus on React, I am going to assume we are working with a working knowledge of Express based server configurations. If you aren't familiar with what is going on below, you can read up on any of the helpful articles on this site about the subject, most notably ExpressJS 4.0 - New Features & Upgrading from 3.0
为了专注于React,我假设我们正在使用基于Express的服务器配置的工作知识。 如果您不熟悉下面的情况,则可以阅读本网站上有关该主题的任何有用文章,尤其是ExpressJS 4.0-新功能和从3.0升级
In the file below, we are doing 4 specific things:
在下面的文件中,我们正在做4件事:
- Setting up a server via Express 通过Express设置服务器
- Connecting to our MongoDB database 连接到我们的MongoDB数据库
- Initializing our socket.io connection 初始化我们的socket.io连接
- Creating our Twitter stream connection 创建我们的Twitter流连接
server.js (server.js)
// Require our dependencies
var express = require('express'),
exphbs = require('express-handlebars'),
http = require('http'),
mongoose = require('mongoose'),
twitter = require('ntwitter'),
routes = require('./routes'),
config = require('./config'),
streamHandler = require('./utils/streamHandler');
// Create an express instance and set a port variable
var app = express();
var port = process.env.PORT || 8080;
// Set handlebars as the templating engine
app.engine('handlebars', exphbs({ defaultLayout: 'main'}));
app.set('view engine', 'handlebars');
// Disable etag headers on responses
app.disable('etag');
// Connect to our mongo database
mongoose.connect('mongodb://localhost/react-tweets');
// Create a new ntwitter instance
var twit = new twitter(config.twitter);
// Index Route
app.get('/', routes.index);
// Page Route
app.get('/page/:page/:skip', routes.page);
// Set /public as our static content dir
app.use("/", express.static(__dirname + "/public/"));
// Fire it up (start our server)
var server = http.createServer(app).listen(port, function() {
console.log('Express server listening on port ' + port);
});
// Initialize socket.io
var io = require('socket.io').listen(server);
// Set a stream listener for tweets matching tracking keywords
twit.stream('statuses/filter',{ track: 'scotch_io, #scotchio'}, function(stream){
streamHandler(stream,io);
});nTwitter allows us to access the Twitter streaming API, so we use the statuses/filter endpoint, along with the track property, to return tweets that use a #scotchio hash tag or mention scotch_io. You can modify this query to your liking by using the settings outlined within the Twitter Streaming API.
nTwitter允许我们访问Twitter流API,因此我们使用statuses/filter端点以及track属性,以返回使用#scotchio哈希标记或提及scotch_io的推文。 您可以使用Twitter Streaming API中概述的设置,根据自己的喜好修改此查询。
楷模 (Models)
In our app we use Mongoose to define our Tweet model. When receiving our data from our Twitter stream, we need somewhere to store it, and a static query method to return subsets of data based upon app parameters:
在我们的应用程序中,我们使用Mongoose定义我们的Tweet模型。 从Twitter流中接收数据时,我们需要在某个地方存储数据,并需要一个静态查询方法来根据应用程序参数返回数据的子集:
Tweet.js (Tweet.js)
var mongoose = require('mongoose');
// Create a new schema for our tweet data
var schema = new mongoose.Schema({
twid : String
, active : Boolean
, author : String
, avatar : String
, body : String
, date : Date
, screenname : String
});
// Create a static getTweets method to return tweet data from the db
schema.statics.getTweets = function(page, skip, callback) {
var tweets = [],
start = (page * 10) + (skip * 1);
// Query the db, using skip and limit to achieve page chunks
Tweet.find({},'twid active author avatar body date screenname',{skip: start, limit: 10}).sort({date: 'desc'}).exec(function(err,docs){
// If everything is cool...
if(!err) {
tweets = docs; // We got tweets
tweets.forEach(function(tweet){
tweet.active = true; // Set them to active
});
}
// Pass them back to the specified callback
callback(tweets);
});
};
// Return a Tweet model based upon the defined schema
module.exports = Tweet = mongoose.model('Tweet', schema);After defining our schema, we create a static method called getTweets. It takes 3 arguments, page, skip & callback.
定义架构之后,我们创建一个名为getTweets的静态方法。 它需要3个参数, page , skip和callback 。
When we have an application that not only renders server side, but has an active stream saving to the database behind the scenes, we need to create a way to make sure that when we request our next page of tweets, it takes into account that Tweets may have been added since the app has been running on the client.
当我们拥有一个不仅可以呈现服务器端的应用程序,而且可以将活动流保存到后台的数据库中时,我们需要创建一种方法来确保当我们请求下一页推文时,要考虑到推文由于该应用程序已在客户端上运行,因此可能已添加。
This is where the skip argument comes into play. If we have 2 new tweets come in, and then request the next page, we need to skip 2 indexes forward so that our application's pages are relative to it's original count, and we don't end up with duplicate tweets.
这就是skip参数起作用的地方。 如果有2条新的tweet进入,然后请求下一页,则需要向前跳过2个索引,以便我们的应用程序的页面相对于其原始计数,并且最终不会出现重复的tweet。
流处理 (Stream Handling)
When our Twitter stream connection sends a new Tweet event, we need a method to take that data, save it to our database, and emit an event to the client side with the tweet data:
当我们的Twitter流连接发送一个新的Tweet事件时,我们需要一种方法来获取该数据,将其保存到我们的数据库中,并使用tweet数据向客户端发出一个事件:
streamHandler.js (streamHandler.js)
var Tweet = require('../models/Tweet');
module.exports = function(stream, io){
// When tweets get sent our way ...
stream.on('data', function(data) {
// Construct a new tweet object
var tweet = {
twid: data['id'],
active: false,
author: data['user']['name'],
avatar: data['user']['profile_image_url'],
body: data['text'],
date: data['created_at'],
screenname: data['user']['screen_name']
};
// Create a new model instance with our object
var tweetEntry = new Tweet(tweet);
// Save 'er to the database
tweetEntry.save(function(err) {
if (!err) {
// If everything is cool, socket.io emits the tweet.
io.emit('tweet', tweet);
}
});
});
};We start by requiring our Model, and when our stream emits an event, we grab the data we want to save, save it, and emit our socket event to the client with the Tweet we just saved.
我们从需要模型开始,当我们的流发出一个事件时,我们抓取我们想要保存的数据,保存它,并使用刚刚保存的Tweet将套接字事件发送给客户端。
路线 (Routes)
Our routes are where the majority of the magic is going to happen today. Lets take a look at routes.js:
我们的路线是今天大多数魔术发生的地方。 让我们看一下routes.js :
routes.js (routes.js)
var JSX = require('node-jsx').install(),
React = require('react'),
TweetsApp = require('./components/TweetsApp.react'),
Tweet = require('./models/Tweet');
module.exports = {
index: function(req, res) {
// Call static model method to get tweets in the db
Tweet.getTweets(0,0, function(tweets, pages) {
// Render React to a string, passing in our fetched tweets
var markup = React.renderComponentToString(
TweetsApp({
tweets: tweets
})
);
// Render our 'home' template
res.render('home', {
markup: markup, // Pass rendered react markup
state: JSON.stringify(tweets) // Pass current state to client side
});
});
},
page: function(req, res) {
// Fetch tweets by page via param
Tweet.getTweets(req.params.page, req.params.skip, function(tweets) {
// Render as JSON
res.send(tweets);
});
}
}In the code above, we have two specific requirements:
在上面的代码中,我们有两个特定的要求:
- For our index route, we want to return a full page rendered from our React source 对于我们的索引路由,我们想返回从React源渲染的完整页面
- For our page route, we want to return a JSON string containing additional tweets based upon our params. 对于我们的页面路由,我们想返回一个JSON字符串,其中包含基于我们的参数的其他推文。
By requiring our React components, and calling the renderComponentToString method, we are converting them to a string, which is then passed into our home.handlebars template.
通过需要我们的React组件,并调用renderComponentToString方法,我们将它们转换为字符串,然后将其传递到我们的home.handlebars模板中。
We leverage our Tweets model to find tweets that have been stored in the database after coming in from our stream connection. Upon receiving the results of our query, we render our component to a String.
我们利用Tweets模型来查找从流连接传入后已存储在数据库中的Tweets。 收到查询结果后,我们将组件呈现为String 。
Notice that we are using non-JSX syntax when defining the component we want to render. This is because we are in our routes file and it is not being transformed.
请注意,在定义要渲染的组件时,我们使用非JSX语法。 这是因为我们位于路线文件中,并且尚未进行转换。
Lets take a look at our render method:
让我们看一下我们的render方法:
// Render our 'home' template
res.render('home', {
markup: markup, // Pass rendered react markup
state: JSON.stringify(tweets) // Pass current state to client side
});Not only are we passing our stringified markup, but we also pass a state property. In order for our server rendered application to pick up where it left off on the client, we need to pass the last state to the client so we can keep them in sync.
我们不仅传递字符串化的标记,而且传递状态属性。 为了使我们的服务器渲染的应用程序能够在客户端上停止的地方继续工作,我们需要将最后一个状态传递给客户端,以便使它们保持同步。
范本 (Templates)
Our app has two main templates, both of which are ridiculously simple. We start with a layout view, which wraps our target template.
我们的应用程序具有两个主要模板,这两个模板都非常简单。 我们从布局视图开始,该视图包装了目标模板。
主把手 (main.handlebars)
React Tweets
{{{ body }}}
{{{body}}} is where our template home.handlebars is loaded into. On this page we also add script tags for socket.io and our bundle.js that Browserify outputs.
{{{body}}}是我们的模板home.handlebars加载到的位置。 在此页面上,我们还添加了socket.io脚本脚本标签和Browserify输出的bundle.js。
home.handlebars (home.handlebars)
{{{ markup }}} In our home.handlebars template, we take the component markup that we generated in our routes, and insert at {{{markup}}}.
在home.handlebars模板中,我们采用在路线中生成的组件标记,然后插入{{{markup}}} 。
Directly below we transfer our state. We use a script tag to hold a JSON string of our server's state. When initializing our React components on the client side, we pull our state from here and then remove it.
在正下方,我们转移状态。 我们使用脚本标签来保存服务器状态的JSON字符串。 在客户端初始化我们的React组件时,我们从这里拉出我们的状态,然后将其删除。
客户端渲染 (Client Side Rendering)
On the server we use renderComponentToString to generate markup for our components, but when using Browserify, we need a client side entry point to pick up the state we just saved, and mount our application component.
在服务器上,我们使用renderComponentToString为我们的组件生成标记,但是在使用Browserify时,我们需要一个客户端入口点来拾取刚刚保存的状态,并挂载我们的应用程序组件。
app.js (app.js)
/** @jsx React.DOM */
var React = require('react');
var TweetsApp = require('./components/TweetsApp.react');
// Snag the initial state that was passed from the server side
var initialState = JSON.parse(document.getElementById('initial-state').innerHTML)
// Render the components, picking up where react left off on the server
React.renderComponent(
,
document.getElementById('react-app')
); We start by getting our intitial state from the script element that we added in home.handlebars. We parse the JSON data and then call React.renderComponent.
我们首先从在home.handlebars添加的script元素获取初始状态。 我们解析JSON数据,然后调用React.renderComponent 。
Because we are working with a file that will be bundled with Browserify and will have access to JSX transforms, we can use JSX syntax when passing our component as an argument.
因为我们正在使用将与Browserify捆绑在一起并且可以访问JSX转换的文件,所以在将组件作为参数传递时可以使用JSX语法。
We initialize our component by adding the state we just grabbed to an attribute on our component. This makes it available via this.props within our component's methods.
我们通过将刚抓取的状态添加到组件上的属性来初始化组件。 这使得它可以通过组件方法中的this.props获得。
Finally, our second argument mounts our rendered component to our #react-app div element from home.handlebars.
最后,第二个参数将渲染的组件从home.handlebars安装到我们的#react-app div元素。
同构分量 (Isomorphic Components)
Now that we have all of our setup out of the way, it is time to get down to business. In our previous files, we rendered a custom component named TweetsApp.
现在我们已经完成所有设置,现在该开始做生意了。 在之前的文件中,我们渲染了一个名为TweetsApp的自定义组件。
Let's create our TweetsApp class.
让我们创建我们的TweetsApp类。
module.exports = TweetsApp = React.createClass({
// Render the component
render: function(){
return (
)
}
});Our app is going to have 4 child components. We need a Tweets display, A singular Tweet, a loading spinner for loading paged results, and a notification bar. We wrap them in a div element with the tweets-app class.
我们的应用程序将包含4个子组件。 我们需要一个Tweets显示,一个奇异的Tweet,一个用于加载分页结果的加载微调器以及一个通知栏。 我们使用tweets-app类将它们包装在div元素中。
Very similarly to the way we passed our state via component props when transferring our server's state, we pass our current state down to the child components via props.
与传输服务器状态时通过组件道具传递状态的方式非常相似,我们通过道具将当前状态传递给子组件。
But where does the state come from?
但是国家从哪里来?
In React, setting state via props is generally considered an anti-pattern. However when setting an initial state, and transferring a state from the server, this is not the case. Because the getInitialState method is only called before the first mount of our component, we need to use the componentWillReceiveProps method to make sure that if we mount our component again, that it will receive the state:
在React中,通过props设置状态通常被认为是反模式。 但是,在设置初始状态并从服务器传输状态时,情况并非如此。 因为getInitialState方法仅在首次安装组件之前被调用,所以我们需要使用componentWillReceiveProps方法来确保如果再次安装组件,它将接收状态:
// Set the initial component state
getInitialState: function(props){
props = props || this.props;
// Set initial application state using props
return {
tweets: props.tweets,
count: 0,
page: 0,
paging: false,
skip: 0,
done: false
};
},
componentWillReceiveProps: function(newProps, oldProps){
this.setState(this.getInitialState(newProps));
},Aside from our tweets, which we pass down from the server, our state on the client contains some new properties. We use the count property to track how many tweets are currently unread. Unread tweets are ones that have been loaded via socket.io, that came in after the page loaded, but are not active yet. This resets every time we call showNewTweets.
除了我们从服务器传递的推文外,客户端的状态还包含一些新属性。 我们使用count属性来跟踪当前未读的推文数量。 未读的推文是通过socket.io加载的,它们在页面加载后出现,但尚未激活。 每次我们调用showNewTweets时,都会重置。
The page property keeps track of how many pages we have currently loaded from the server. When starting a page load, in between the event kicking off, and when the results are rendered to the page, our paging property is set to true, preventing the event from starting again until the current request has completed. The done property is set to true when we have run out of pages.
page属性跟踪我们当前从服务器加载的页面数。 当开始页面加载时,在事件开始到结果呈现到页面之间,我们的paging属性设置为true,以防止事件在当前请求完成之前再次开始。 当页面用完时, done属性设置为true。
Our skip property is like count, but never gets reset. This gives us a value for how many tweets are now in the database that we need to skip because our initial load doesn't account for them. This prevent us from rendering duplicate tweets to the page.
我们的skip属性就像count ,但是永远不会重置。 这为我们提供了一个值,该值是数据库中现在需要跳过的tweet数量,因为初始负载并未解决这些问题。 这样可以防止我们向页面呈现重复的tweet。
As it stands, we are good to go on the server side rendering of our component. However, our client side is where our state changes from UI interaction and socket events, so we need to set up some methods to handle that.
就目前而言,我们很高兴继续进行组件的服务器端渲染。 但是,客户端是状态从UI交互和套接字事件发生变化的地方,因此我们需要设置一些方法来处理此问题。
We can use the componentDidMount method to accomplish this safely, because it only runs when a component is mounted on the client:
我们可以使用componentDidMount方法安全地完成此操作,因为它仅在组件安装在客户端上时运行:
// Called directly after component rendering, only on client
componentDidMount: function(){
// Preserve self reference
var self = this;
// Initialize socket.io
var socket = io.connect();
// On tweet event emission...
socket.on('tweet', function (data) {
// Add a tweet to our queue
self.addTweet(data);
});
// Attach scroll event to the window for infinity paging
window.addEventListener('scroll', this.checkWindowScroll);
},In the code above, we set up two event listeners to modify the state and subsequent rendering of our components. The first is our socket listener. When a new tweet is emitted, we call our addTweet method to add it to an unread queue.
在上面的代码中,我们设置了两个事件侦听器,以修改组件的状态和随后的呈现。 首先是我们的套接字监听器。 发出新的tweet时,我们调用addTweet方法将其添加到未读队列中。
// Method to add a tweet to our timeline
addTweet: function(tweet){
// Get current application state
var updated = this.state.tweets;
// Increment the unread count
var count = this.state.count + 1;
// Increment the skip count
var skip = this.state.skip + 1;
// Add tweet to the beginning of the tweets array
updated.unshift(tweet);
// Set application state
this.setState({tweets: updated, count: count, skip: skip});
},Tweets in the unread queue are on the page, but not shown until the user acknowledges them in the NotificationBar component. When they do, an event is passed back via onShowNewTweets which calls our showNewTweets method:
未读队列中的推文在页面上,但直到用户在NotificationBar组件中确认它们后才显示。 当他们这样做时,将通过onShowNewTweets传递回一个事件,该事件调用我们的showNewTweets方法:
// Method to show the unread tweets
showNewTweets: function(){
// Get current application state
var updated = this.state.tweets;
// Mark our tweets active
updated.forEach(function(tweet){
tweet.active = true;
});
// Set application state (active tweets + reset unread count)
this.setState({tweets: updated, count: 0});
},This method loops through our tweets and sets their active property to true, and then sets our state. This makes any unshown tweets now show (via CSS).
该方法遍历我们的tweet,并将其active属性设置为true,然后设置我们的状态。 这使得所有未显示的推文现在都可以显示(通过CSS)。
Our second event listens to the window scroll event, and fires our checkWindowScroll event to check whether we should load a new page.
我们的第二个事件侦听window滚动事件,并触发checkWindowScroll事件以检查是否应该加载新页面。
// Method to check if more tweets should be loaded, by scroll position
checkWindowScroll: function(){
// Get scroll pos & window data
var h = Math.max(document.documentElement.clientHeight, window.innerHeight || 0);
var s = document.body.scrollTop;
var scrolled = (h + s) > document.body.offsetHeight;
// If scrolled enough, not currently paging and not complete...
if(scrolled && !this.state.paging && !this.state.done) {
// Set application state (Paging, Increment page)
this.setState({paging: true, page: this.state.page + 1});
// Get the next page of tweets from the server
this.getPage(this.state.page);
}
},In our checkWindowScroll method, if we have reached the bottom of the page, aren't currently in the paging process, and haven't reached the last page, we call our getPage method:
在我们的checkWindowScroll方法中,如果我们到达页面的底部,当前不在分页过程中,并且尚未到达最后一页,则调用getPage方法:
// Method to get JSON from server by page
getPage: function(page){
// Setup our ajax request
var request = new XMLHttpRequest(), self = this;
request.open('GET', 'page/' + page + "/" + this.state.skip, true);
request.onload = function() {
// If everything is cool...
if (request.status >= 200 && request.status < 400){
// Load our next page
self.loadPagedTweets(JSON.parse(request.responseText));
} else {
// Set application state (Not paging, paging complete)
self.setState({paging: false, done: true});
}
};
// Fire!
request.send();
},In this method we pass our incremented page index, along with our skip property of our state object to our /page route. If there are no more tweets, we set paging to false and done to true, ending our ability to page.
在此方法中,我们将递增的页面索引以及状态对象的skip属性传递到/page路由。 如果没有更多的推文,则将paging设置为false并将done为true,从而终止分页功能。
If tweets are returned, we will return JSON data based upon the given arguments, which we then load with the loadPagedTweets method:
如果返回了tweets,我们将根据给定的参数返回JSON数据,然后使用loadPagedTweets方法加载该loadPagedTweets :
// Method to load tweets fetched from the server
loadPagedTweets: function(tweets){
// So meta lol
var self = this;
// If we still have tweets...
if(tweets.length > 0) {
// Get current application state
var updated = this.state.tweets;
// Push them onto the end of the current tweets array
tweets.forEach(function(tweet){
updated.push(tweet);
});
// This app is so fast, I actually use a timeout for dramatic effect
// Otherwise you'd never see our super sexy loader svg
setTimeout(function(){
// Set application state (Not paging, add tweets)
self.setState({tweets: updated, paging: false});
}, 1000);
} else {
// Set application state (Not paging, paging complete)
this.setState({done: true, paging: false});
}
},This method takes our current set of tweets in our state object, and pushes our new tweets onto the end. I use a setTimeout before calling setState, so that we can actually see the loader component for at least a little while.
此方法在状态对象中获取当前的一组tweet,并将新的tweet推送到末尾。 我在调用setState之前使用了setTimeout,这样我们实际上可以看到加载器组件至少一小会儿。
Check out our finished component below:
在下面查看我们完成的组件:
TweetsApp (TweetsApp)
/** @jsx React.DOM */
var React = require('react');
var Tweets = require('./Tweets.react.js');
var Loader = require('./Loader.react.js');
var NotificationBar = require('./NotificationBar.react.js');
// Export the TweetsApp component
module.exports = TweetsApp = React.createClass({
// Method to add a tweet to our timeline
addTweet: function(tweet){
// Get current application state
var updated = this.state.tweets;
// Increment the unread count
var count = this.state.count + 1;
// Increment the skip count
var skip = this.state.skip + 1;
// Add tweet to the beginning of the tweets array
updated.unshift(tweet);
// Set application state
this.setState({tweets: updated, count: count, skip: skip});
},
// Method to get JSON from server by page
getPage: function(page){
// Setup our ajax request
var request = new XMLHttpRequest(), self = this;
request.open('GET', 'page/' + page + "/" + this.state.skip, true);
request.onload = function() {
// If everything is cool...
if (request.status >= 200 && request.status < 400){
// Load our next page
self.loadPagedTweets(JSON.parse(request.responseText));
} else {
// Set application state (Not paging, paging complete)
self.setState({paging: false, done: true});
}
};
// Fire!
request.send();
},
// Method to show the unread tweets
showNewTweets: function(){
// Get current application state
var updated = this.state.tweets;
// Mark our tweets active
updated.forEach(function(tweet){
tweet.active = true;
});
// Set application state (active tweets + reset unread count)
this.setState({tweets: updated, count: 0});
},
// Method to load tweets fetched from the server
loadPagedTweets: function(tweets){
// So meta lol
var self = this;
// If we still have tweets...
if(tweets.length > 0) {
// Get current application state
var updated = this.state.tweets;
// Push them onto the end of the current tweets array
tweets.forEach(function(tweet){
updated.push(tweet);
});
// This app is so fast, I actually use a timeout for dramatic effect
// Otherwise you'd never see our super sexy loader svg
setTimeout(function(){
// Set application state (Not paging, add tweets)
self.setState({tweets: updated, paging: false});
}, 1000);
} else {
// Set application state (Not paging, paging complete)
this.setState({done: true, paging: false});
}
},
// Method to check if more tweets should be loaded, by scroll position
checkWindowScroll: function(){
// Get scroll pos & window data
var h = Math.max(document.documentElement.clientHeight, window.innerHeight || 0);
var s = document.body.scrollTop;
var scrolled = (h + s) > document.body.offsetHeight;
// If scrolled enough, not currently paging and not complete...
if(scrolled && !this.state.paging && !this.state.done) {
// Set application state (Paging, Increment page)
this.setState({paging: true, page: this.state.page + 1});
// Get the next page of tweets from the server
this.getPage(this.state.page);
}
},
// Set the initial component state
getInitialState: function(props){
props = props || this.props;
// Set initial application state using props
return {
tweets: props.tweets,
count: 0,
page: 0,
paging: false,
skip: 0,
done: false
};
},
componentWillReceiveProps: function(newProps, oldProps){
this.setState(this.getInitialState(newProps));
},
// Called directly after component rendering, only on client
componentDidMount: function(){
// Preserve self reference
var self = this;
// Initialize socket.io
var socket = io.connect();
// On tweet event emission...
socket.on('tweet', function (data) {
// Add a tweet to our queue
self.addTweet(data);
});
// Attach scroll event to the window for infinity paging
window.addEventListener('scroll', this.checkWindowScroll);
},
// Render the component
render: function(){
return (
)
}
});子组件 (Child Components)
Our main component uses 4 child components to compose an interface based upon our current state values. Lets review them and how they work with their parent component:
我们的主要组件使用4个子组件根据当前状态值组成一个接口。 让我们查看它们以及它们如何与父组件一起工作:
鸣叫 (Tweets)
/** @jsx React.DOM */
var React = require('react');
var Tweet = require('./Tweet.react.js');
module.exports = Tweets = React.createClass({
// Render our tweets
render: function(){
// Build list items of single tweet components using map
var content = this.props.tweets.map(function(tweet){
return (
{content}
)
}
});Our Tweets component is passed our current state's tweets via its tweets prop and is used to render our tweets. In our render method, we build a list of tweets by executing the map method on our array of tweets. Each iteration creates a new rendering of a child Tweet component, and the results are inserted into an unordered list.
我们的推文组件通过其tweets道具传递当前状态的推tweets ,并用于呈现我们的推文。 在我们的render方法中,我们通过在tweets数组上执行map方法来构建tweets列表。 每次迭代都会创建子Tweet组件的新呈现,并将结果插入到无序列表中。
鸣叫 (Tweet)
/** @jsx React.DOM */
var React = require('react');
module.exports = Tweet = React.createClass({
render: function(){
var tweet = this.props.tweet;
return (

{tweet.author}
@{tweet.screenname}
{tweet.body}
)
}
});Our singular Tweet component renders each individual tweet as a list item. We conditionally render an active class based upon the tweet's active status, that helps us hide it while it is still in the queue.
我们的奇异Tweet组件将每个单独的Tweet渲染为一个列表项。 我们根据推文的活动状态有条件地渲染一个active类,这有助于我们在推文仍在队列中时将其隐藏。
Each tweet's data is then used to fill in the predefined tweet template, so that our tweet display looks legit.
然后,使用每个推文的数据来填充预定义的推文模板,以便我们的推文显示看起来合法。
通知栏 (NotificationBar)
/** @jsx React.DOM */
var React = require('react');
module.exports = NotificationBar = React.createClass({
render: function(){
var count = this.props.count;
return (
0 ? ' active' : '')}>
There are {count} new tweets! Click here to see them.
)
}
});Our Notification Bar is fixed to the top of the page, and displays the current count of unread tweets, and when clicked, shows all the tweets currently in the queue.
我们的通知栏固定在页面顶部,并显示未读推文的当前计数,当单击时,将显示队列中当前的所有推文。
We conditionally display an active class based upon whether we actually have any unread tweets, using the count prop.
我们使用count属性,根据是否有未读推文,有条件地显示一个活动类。
On our anchor tag, an onClick handler calls our components own prop onShowNewTweets which is bound to showNewTweets in it's parent. This allows us to pass the event back upwards so it can be handled in our parent component, where we keep our state management.
在我们的定位标记上,一个onClick处理函数调用我们组件自己的道具onShowNewTweets ,该道具绑定到showNewTweets中的showNewTweets 。 这使我们可以向上传递事件,以便可以在父组件中处理该事件,并在其中保留状态管理。
装载机 (Loader)
/** @jsx React.DOM */
var React = require('react');
module.exports = Loader = React.createClass({
render: function(){
return (
 )
}
});
)
}
});Our loader component is a fancy svg loading animation. It is used during paging to indicate that we are loading a new page. An active class is set using our paging prop, that controls whether our component is shown or not (via CSS).
我们的加载器组件是精美的svg加载动画。 在分页过程中使用它来指示我们正在加载新页面。 使用我们的paging道具设置一个active类,该类控制是否显示组件(通过CSS)。
结语 (Wrap Up)
All that's left to do now is to run node server on your command line! You can run this locally or just check out the live demo below. If you want to see a tweet come in live, the easiest way is to just share this article with the demo open and you can see it in real time!
现在剩下要做的就是在命令行上运行node server ! 您可以在本地运行,也可以查看下面的实时演示。 如果您想实时看到一条推文,最简单的方法是在演示打开的情况下共享这篇文章,您可以实时查看它!
In the next installment of Learning React, we will be learning how to leverage Facebook's Flux Architecture to enforce unidirectional data flow. Flux is Facebook's recommended complementary architecture for React applications. We will also be reviewing some open source Flux libraries that make implementing the Flux architecture a breeze.
在下一期的Learning React中 ,我们将学习如何利用Facebook的Flux Architecture来实施单向数据流。 Flux是Facebook建议的用于React应用程序的补充架构。 我们还将审查一些开源的Flux库,这些库使实现Flux架构变得轻而易举。
Look for it soon!
快找吧!
翻译自: https://scotch.io/tutorials/build-a-real-time-twitter-stream-with-node-and-react-js
node.js react