【论文系列】Long-term Visual Localization using Semantically Segmented Images--语义位置识别/ICRA2018
未经允许,不得转载
读Long-term Visual Localization using Semantically Segmented Images (语义位置识别)
这一篇是发表于ICRA2018的一篇文章,结合深度学习去解决SLAM中位置识别的问题,主要是针对长时间运行的、跨季节的、光照变化显著条件下运行的SLAM系统,由于传统描述子在这些条件下的表达或匹配不鲁棒而不能准确定位的问题。本文的一个核心idea就是利用图像语义分割后得到的描述子代替传统描述子,然后再建模去考虑2D点到3D点的映射关系。此外还需要注意的是,这个系统是在一个已有3D map的基础上结合语义分割特征一起进行的,换句话说,rely on pre-constructed maps.(不是没有环境先验的)。
目录
读Long-term Visual Localization using Semantically Segmented Images
Abstract
Introduction
Problem statement
观测量
地图,如何表示地图
MODELS
PROCESS MODEL
MEASUREMENT MODEL
SIFT map
Semantic map
Algorithm Details
SIFT FILTER
SEMANTIC FILTER
Experiment Evaluation
Setup:
MAP CREATION
GROUND TRUTH
Conclusion
附录知识点
还是那个顺序,我们首先来看摘要
Abstract
Abstract— Robust cross-seasonal localization is one of the major challenges in long-term visual navigation of autonomous vehicles. In this paper, we exploit recent advances in semantic segmentation of images, i.e., where each pixel is assigned a label related to the type of object it represents, to attack the problem of long-term visual localization. We show that semantically labeled 3D point maps of the environment, together with semantically segmented images, can be efficiently used for vehicle localization without the need for detailed feature descriptors (SIFT, SURF, etc.). Thus, instead of depending on hand-crafted feature descriptors, we rely on the training of an image segmenter. The resulting map takes up much less storage space compared to a traditional descriptor based map. A particle filter based semantic localization solution is compared to one based on SIFT-features, and even with large seasonal variations over the year we perform on par with the larger and more descriptive SIFT-features, and are able to localize with an error below 1 m most of the time.
作者主要想解决一个什么问题呢,想解决在长时间的跨季节的系统运行下,位置识别能够保证一个鲁棒的结果。
作者的策略是不用传统的人工描述子,而是利用图像的语义。通过结合有标注语义的3D点的环境地图和语义分割之后的图像,利用粒子滤波进行语义定位以实现一个误差小于1m的长时间视觉定位功能。
Introduction
首先讲为什么要在有预先建造的地图下进行自动驾驶(大多数目的在于日常活动,比如下班通勤的自动驾驶技术都依赖于一个pre-constructed地图)→而这之中最重要的是定位→定位需要信息,并且会创建landmarks来辅助理解信息:对于相机,landmark就是点特征,关联地图就利用这些点特征建立;定位时,寻找2D-3D的联系并且solvePnP求解位姿。→然后camera也有些问题啦:比如光下,季节天气变化下不鲁棒/光照强变化下没用,树这种没纹理的搞不定。!对光照变化非常敏感,就算描述子对环境鲁棒,但是匹配也会出现问题,由于探测器在定位期间不像在映射期间那样在相同点处触发。
所以!在充分不相似的场景下很难去依靠图像和地图的特征匹配完成建图和定位。
所以!问题可以归结于要找到一个环境描述,既可以用于定位,并且长时间不变,而且还紧凑。否则,你就只能一直更新地图。
好了 上作者方法。 作者主要是想证明语义的特征比传统的特征好
作者利用语义分割后的图片和语义点地图设计了一个定位算法。每一个点由它空间中的三维位置和语义类别来描述,不再使用传统的描述子来描述。这样从描述子到语义分割,算法具备了季节不变性。对比实验的话,就是在同系统下,利用每一个点由它空间中的三维位置和SIFT描述子来描述,同数据集作对比。
Problem statement
接下来是问题陈述:讲的是有关观测值的观测细节并引入map的一些注释。
首先,研究的问题是什么?: 本文关心的是在一个点特征的地图中,利用在线相机,能够顺序查找车的当前位置/或者说能时刻找到车的位置。
用的什么数据集:CMU,video+GPS
-
观测量
- 在时间 t下的测量值:速度和图像
- 里程: 速度
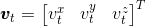 和角速度
和角速度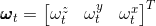 (假设所有速度都受到高斯噪声的影响,并且角速度的测量值还被一个缓慢变化的bias影响)
(假设所有速度都受到高斯噪声的影响,并且角速度的测量值还被一个缓慢变化的bias影响) - 图像: (选用的是双目相机),对于图像这个观测值,常用的办法是将图像压缩成一组有对应特征向量的特征点。其观测值
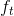 ,点的图像坐标正则化后的表示为
,点的图像坐标正则化后的表示为 ,点的描述符为
,点的描述符为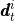 ,所以图像观测值可以表示为
,所以图像观测值可以表示为  。
。
|
|
本文方法 |
基于SIFT的 |
| 比较dense,并且每个点都会容纳进去 |
比较稀疏,且只有sift特征点才会出现在中 |
-
地图,如何表示地图
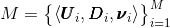 其中
其中![]() 是特征点的全局坐标,分别代表其在向东、向北、向上方向的值;
是特征点的全局坐标,分别代表其在向东、向北、向上方向的值;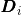 则是这个特征点对应的描述向量;最后
则是这个特征点对应的描述向量;最后![]() 表示它的可见性。
表示它的可见性。![]() 。特征点可见性
。特征点可见性![]() 由可见概率
由可见概率![]() 和可见体积(
和可见体积(![]() )来参数化表示。
)来参数化表示。
这样空间点![]() 被建模后具有一个可被检测概率
被建模后具有一个可被检测概率![]() :即,在由角
:即,在由角![]() 定义的角度(黄色涂抹的夹角区域),由
定义的角度(黄色涂抹的夹角区域),由![]() 控制长度(蓝色箭头指示方向)的一个楔形体积内的可检测概率
控制长度(蓝色箭头指示方向)的一个楔形体积内的可检测概率![]() ,看图说话!
,看图说话!
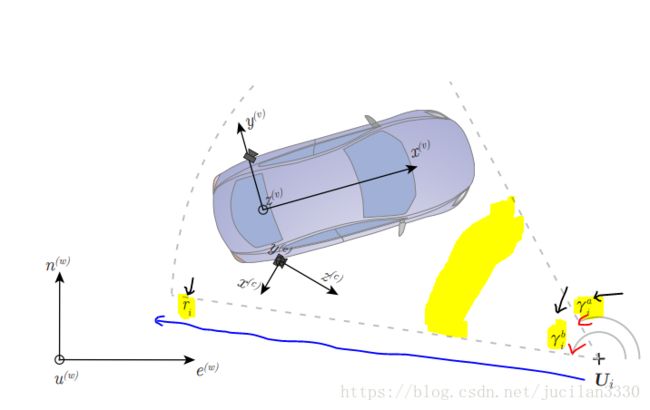
- 问题的数学表达
问题可以理解成 在给定所有观察的情况下递归地计算相对于地图M的车辆姿态的后验密度。
假设已知在t时刻下的车的pose状态量是![]() ,
,![]() ,其中
,其中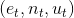 d代表的是global坐标,
d代表的是global坐标, ![]() 代表yaw,pitch,roll角度,要顺序计算其后验概率密度
代表yaw,pitch,roll角度,要顺序计算其后验概率密度 ![]() 。
。
MODELS
作者是通过滤波的方法来解决的,滤波问题的解决可以看做两个模型的求解。(或者说一个运动方程一个观测方程?)
| process model |
描述系统状态量的变化 | |
| measurement model | 描述状态量和观测量之间的关系 |
这里插播一下后验概率公式![]() 。
。
-
PROCESS MODEL
process模型套用的是一个点质量模型(point mass model):
![]()
可以把这个模型拆解为两个部分,![]() 。① 前一个
。① 前一个![]() 以速度作为输入描述的是两个相邻时间上pose 的关系:
以速度作为输入描述的是两个相邻时间上pose 的关系:![]() 的含义由下方第一个式子得到,
的含义由下方第一个式子得到,
>>>> (1)
其中噪声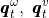 服从正态分布:
服从正态分布:![]() 。
。
②后一个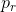 为的是确保road上永远有一个很小的后验概率密度。这样可以使得丢失的滤波器再重新获得它的横向位置。
为的是确保road上永远有一个很小的后验概率密度。这样可以使得丢失的滤波器再重新获得它的横向位置。
怎么做呢,通过轨迹上的投影,密度的一小部分会赋给road,所以是![]() 在road上的投影。最终获得(1)式的process model。
在road上的投影。最终获得(1)式的process model。
这里,road是由绘制的车辆已驾驶的路线route定义,route与地图中的3-D地标一起存储。
======================================
-
MEASUREMENT MODEL
为了方便读者对后文的理解,我们先把几个概率值的定义给出解释,如有误解,欢迎评论讨论
![]() 一共有
一共有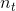 个feature,注意在semantic map中,
个feature,注意在semantic map中,![]() 与
与![]() 相互独立
相互独立
| 概率表达式子 | 以i进行解释,假设i描述的类别是building(building就是它的feature)/当然 |
| 假设此时 |
|
| 抛去语义。t时刻,在点云里与feature i 相对应的3D点 |
|
t时刻,在点云里与feature i 相对应的且类别为 上,对应的图像特征点的label为 上,对应的图像特征点的label为 |
记得前文提到的,已知量是map,观测量是速度和图像。这里的输入量考虑的是图像,图像观测值可以表示为 ![]() 。作者的measurement model 是指当前图像
。作者的measurement model 是指当前图像![]() 给出的特征点(SIFT/semantic feature)的被测量概率的model,【一般的measurement likelihood值的是粒子权重(详见附录知识点1)】。
给出的特征点(SIFT/semantic feature)的被测量概率的model,【一般的measurement likelihood值的是粒子权重(详见附录知识点1)】。
*measurement likelihood function会根据预测值与测量值之间的误差大小来计算每个粒子的权值(likelihood)。与观测值越接近的粒子权值越大,反之越小。
这里为了likelihood表述简明,假设了已知图像中的点与地图中的点的对应关系。这样就有了一个数据关联矢量![]() ,其中
,其中 ![]() 代表的是图像特征
代表的是图像特征 相匹配的是地图特征
相匹配的是地图特征 (其中>0,代表图像特征有对应的特征出现在map中的,=0,代表在map中没有对应点)。然后,再假设pairs对
(其中>0,代表图像特征有对应的特征出现在map中的,=0,代表在map中没有对应点)。然后,再假设pairs对 ![]() 与
与![]() 条件独立【pairs:
条件独立【pairs:![]() (点的图像坐标正则化后的表示)和
(点的图像坐标正则化后的表示)和 ![]() (点的描述符),条件独立见见附录知识点2】,我们得到了似然的表达式:
(点的描述符),条件独立见见附录知识点2】,我们得到了似然的表达式:
其中
顾名思义,是指在Map M中对应图像特征的3D点,![]()
![]() 是最终的每一类特征的measurement likelihood model
是最终的每一类特征的measurement likelihood model
接下来对两种不同的特征的地图,p的建模![]() 有所不同。
有所不同。
——————————————————
-
SIFT map
SIFTmap中,对于给定的数据关联,SIFT描述子对likelihood p不做贡献。【因为是指在Map M中对应图像特征的3D点,所以此处的![]() 只代表SIFT特征点。】再假设检测SIFT关键点的位置受到噪声的影响:三维点的投影误差为零均值正态分布。
只代表SIFT特征点。】再假设检测SIFT关键点的位置受到噪声的影响:三维点的投影误差为零均值正态分布。
可以得到 (没有descriptor)。
其中![]() 代表有透镜畸变的针孔相机模型,
代表有透镜畸变的针孔相机模型,![]() 是detector误差的方差。 相对于车辆坐标系的摄像机安装及其内部参数都隐含在
是detector误差的方差。 相对于车辆坐标系的摄像机安装及其内部参数都隐含在![]() 。
。
------------------------------------------------------
-
Semantic map
1)单个特征点的似然表示
首先,描述子:图像中的![]() ,map中的,都只是代表其语义类别的标签。(特征点)包含了图像中所有的点。作者又开始假设了,像素坐标
,map中的,都只是代表其语义类别的标签。(特征点)包含了图像中所有的点。作者又开始假设了,像素坐标 ![]() 与像素类别
与像素类别![]() 独立,因此可以将单个特征点的likelihood划分为:
独立,因此可以将单个特征点的likelihood划分为:
2)![]() 的常量概率解释
的常量概率解释
但6式的表达会导致对观测值的过度置信,测量值越多,结果越糟。而且第一个因子,![]() 代表的是在pixel i中特征被检测到的可能性【第i个特征的对应点
代表的是在pixel i中特征被检测到的可能性【第i个特征的对应点![]() 检测到
检测到![]() 的概率】,显然这是一个常量,所以我们讲(6)式改写成(7)
的概率】,显然这是一个常量,所以我们讲(6)式改写成(7)
即t时刻,在点云里与feature i 相对应的且类别为![]() 的3D点上,对应的图像特征点的label为
的3D点上,对应的图像特征点的label为![]() 的概率。
的概率。
3)关于![]() 的讨论,像素点能否在map中存在
的讨论,像素点能否在map中存在
而对于(7)式右边的![]() ,我们又可以分为两个情况考虑:pixel i 到底在map中有没有对应的投影点,即,
,我们又可以分为两个情况考虑:pixel i 到底在map中有没有对应的投影点,即,![]()
-
 。 不能从map中得到类别信息,假设这些像素的分布服从所有类别上的边缘分布:(所有类别应该是独立的)
。 不能从map中得到类别信息,假设这些像素的分布服从所有类别上的边缘分布:(所有类别应该是独立的)

-
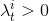 。在这个情况里,虽然像素点和地图点对应,但是我们仍然不确定我们是否在图像中检测到该3D点的对应点还是被某物(例如车辆或行人)遮挡。为了处理这种不确定性,我们引入了检测变量
。在这个情况里,虽然像素点和地图点对应,但是我们仍然不确定我们是否在图像中检测到该3D点的对应点还是被某物(例如车辆或行人)遮挡。为了处理这种不确定性,我们引入了检测变量  ,如果在图像中检测到地图点,则为1,否则为0。 使用这个检测变量,我们可以表示具有相应地图点的像素的可能性:
,如果在图像中检测到地图点,则为1,否则为0。 使用这个检测变量,我们可以表示具有相应地图点的像素的可能性:
和式的前一项代表的是给定特定地图点被遮挡或可见的像素类别概率。其中,![]() 代表点被遮挡,也就是
代表点被遮挡,也就是![]() 时像素类别的概率,
时像素类别的概率,![]() 是在图像中可见情况下的像素类别的概率。 这些是传感器特定的模型,也取决于所使用的语义分割算法的属性。
是在图像中可见情况下的像素类别的概率。 这些是传感器特定的模型,也取决于所使用的语义分割算法的属性。
后一项描述了给定地图点可见的概率,具体表达为
回想在map中定义的楔形,如果观测量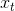 在这个楔形区域内,则
在这个楔形区域内,则 ![]() 的值为1。
的值为1。![]() 指定可见地图点被遮挡的概率。
指定可见地图点被遮挡的概率。
![]() 为
为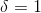 的倒数
的倒数
4)总结
总的来说,将可能性分解为像素坐标的一个部分和描述符的一个部分。 像素部分![]() ,值为1;而
,值为1;而![]() 是由(4)式中所有帖子的乘积得到的,并且根据它有没有对应的map point而分两种情况计算:
是由(4)式中所有帖子的乘积得到的,并且根据它有没有对应的map point而分两种情况计算:
#这一章真的是绕......
Algorithm Details
好了,模型搞清楚之后我们进入滤波器部分。
-
SIFT FILTER
- 采用的是UKF无损卡尔曼滤波。在proposal的匹配上用RANSAC提取内点。UKF利用(1)运动方程和(5)观测方程来完成定位。
- *前文公式(0)的“on road” 还包括从最近的道路点可见的地图点,而不是仅从当前估计得到。
- the data associations:SIFT里不像Semantic里有简单的得到正确匹配的方法。这里作者基于相机位姿和可见点集,从M中选择一个可能可视的子集
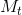 ,再选择
,再选择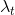 。这样,以及观察到的SIFT特征就会匹配到它们在中的最邻近点;再利用Lowe's ratio creation 选择候选,3点的RANSAC方法去剔除错误匹配。最后根据重投影误差给出最接近的内点,再用于UKF中。
。这样,以及观察到的SIFT特征就会匹配到它们在中的最邻近点;再利用Lowe's ratio creation 选择候选,3点的RANSAC方法去剔除错误匹配。最后根据重投影误差给出最接近的内点,再用于UKF中。
-
SEMANTIC FILTER
(这部分不细细解读了,说来说去也是作者对一些参数的设置,一些情况的解决,直接翻译了)
- 对于使用语义数据的定位,我们选择了一个自举粒子滤波器来递归地估计后验分布作为加权狄拉克函数的总和。
- 为了能够评估粒子的似然,我们首先需要确定地图中哪些点可能是可见的。这类似于对SIFT情况所做的,并且仅需要近似地进行,因此可以同时计算几个附近的粒子,例如,使用它们的平均位置以及地图中的可见性参数。
- 然后将潜在可见点投影到图像平面,为每个粒子创建从地图到像素的唯一分配 。
 map points 投影到语义分割的图像
map points 投影到语义分割的图像
- 用(11)式子除以常数
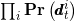 项,简化权重更新,因为我们只需要考虑投影到其中的点的像素.(不再考虑了 )
项,简化权重更新,因为我们只需要考虑投影到其中的点的像素.(不再考虑了 ), 【
注意这个i是任意的,so除掉一部分 还有一部分做分母】 - 因为我们选择将测量建模为条件独立的,而实际上并非如此,这样得到的状态更新过于相信测量值,为了减少这种影响,我们将测量可能性提高到小于1的正数,这样粒子j的重量更新变为
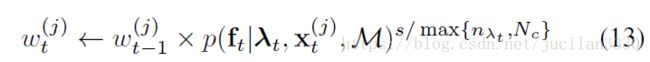
其中![]() 是与具有状态
是与具有状态![]() 的
的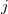 粒子的权重,s是设置为3的缩放倍数,
粒子的权重,s是设置为3的缩放倍数,![]() 是在图像中投影的地图点的数量,并且
是在图像中投影的地图点的数量,并且![]() = 400是限制的最大值,而更多图像中的投影地图点不会提供更多信息,理由是更多点意味着它们在图像中的间距更小,因此它们相应的测量值彼此更相关。
= 400是限制的最大值,而更多图像中的投影地图点不会提供更多信息,理由是更多点意味着它们在图像中的间距更小,因此它们相应的测量值彼此更相关。
Experiment Evaluation
-
Setup:
- 数据集:卡内基梅隆大学视觉定位数据集上进行评估,双目,在2010年9月1日至2010年9月2日期间在匹兹堡大约9公里的路线上行驶了16次。由城市和郊区以及绿色公园组成,其中大部分植被在摄像机中可见。
- 我们在评估中使用了这16个序列中的12个。选定的运行数据集记录了整个季节环境的变化,以及各种天气和照明条件的变化。
- 使用VLFeat提取SIFTfeatures,并使用Dilation 10完成语义分割。
-
MAP CREATION
怎么制作Map呢,作者简单介绍了下,并强调重点还是model。
- 利用数据集的第一个序列图像制作,剩下的数据集不用以map制作,只作为定位验证集。
- pipeline:SFM。并利用GPS和里程计约束来获取内置轨迹,光束法平差得到landmark和poses。
- 计算效率问题解决:①去除静止和慢速图像,减少运算负担;②将sequence分为几个小序列各自map。
- 再给map point增加描述子:① 对于SIFT图,将3-D点对应的每个视图的描述符的算术平均值作为3-D点的SIFT描述符。 ②对于语义地图,每个检测点的7×7像素的邻域内,将这些像素的类上的归一化直方图直接用作
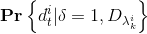 。 根据数据计算(8)的边缘函数,作为映射序列中所有图像中所有像素的归一化直方图。
。 根据数据计算(8)的边缘函数,作为映射序列中所有图像中所有像素的归一化直方图。  是边缘PMF的手动调整。 汽车和行人等动态物体出现,静止物体减少时,概率增加。
是边缘PMF的手动调整。 汽车和行人等动态物体出现,静止物体减少时,概率增加。 - 关于描述子:图4:SIFT描述符的大小相比语义大了太多。 同时,观察到通常每个点只有三个或更少类的概率质量,所以如果只为每个点编码前三个最可能的类,则描述符大小可以减少到39位。
-
GROUND TRUTH
数据集提供“车辆状态”的地面实况数据,其中包括pose,但是不足以评估定位。 为了获得更可靠的ground truth,通过与地图创建中相同的SFM方法,添加序列图像和优化pose之间的手动对应来对齐图像序列。 里程计测量值是根据地面真实姿势之间的相对运动产生的,然后再加上噪声和偏差。

Conclusion
-
result
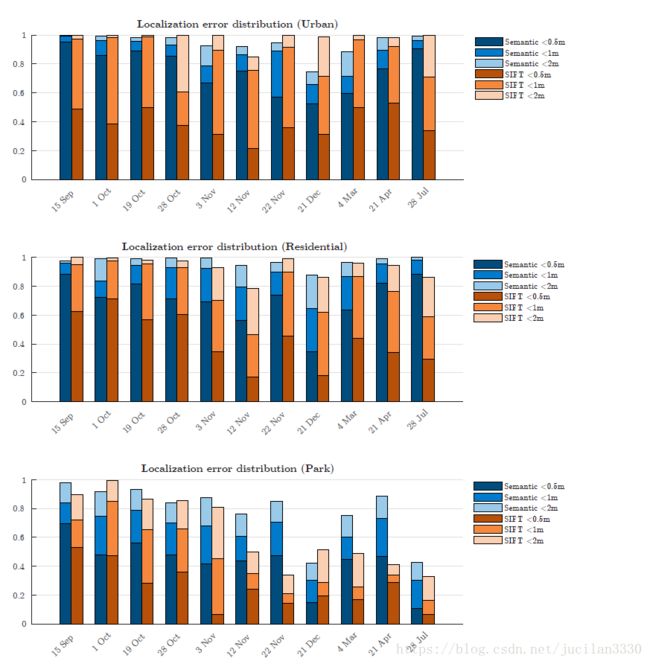
- localization error is within 0.5m, 1m,and 2m, for each of the 11 localization trials
语义失败原因:
- 一个或者两个都被误分类了。---解决:语义分割更精确
- 有些场景无纹理--解决:添加更多的类
SIFT失败原因:
- 找不到足够多的匹配点
-
disucussion
的确效果还没有太好,但的确是给出了一个语义定位的方案,虽然有些繁琐,但的确开启了思路,具有它的独创性,也可以喊大家一起来填填坑。interesting。
附录知识点
- 测量似然函数:在预测下一个状态之后,您可以使用来自传感器的测量值来校正预测的状态。通过在粒子过滤器对象中指定测量似然函数,您可以使用正确的函数来校正预测的粒子。这个测量似然函数,根据定义,给出基于给定测量的状态假设(粒子)的权重。从本质上讲,它给了你观察到的测量结果与每个粒子观察到的结果相匹配的可能性。这种可能性被用作预测粒子的权重,以帮助校正它们并得到最好的估计。--来自网址 https://www.cnblogs.com/21207-iHome/p/7097772.html
-
条件独立:给定第三个事件 ,如果 ,则称X和Y是条件独立事件,符号表示为 。 若X,Y关于事件Z条件独立,则有以下一些理解:①事件 Z 的发生,使本来可能不独立的事件A和事件B变得独立起来;②事件Z 的出现或发生,解开了X 和 Y 的依赖关系。
-
狄拉克函数:在概念上,它是这么一个“函数”:在除了零以外的点函数值都等于零,而其在整个定义域上的积分等于1
2018.9.14