MIPS实现冒泡排序
程序目标
从键盘输入10个无符号字数并从大到小进行排序,排序结果在屏幕上显示出来。
准备工作
- 编程的入门级知识:循环、冒泡排序、内存和堆栈的概念
- MIPS语法:程序基本结构
- 汇编语言:不同寄存器作用、数据存储、系统调用
- 编辑器:最低级的记事本就够了,保存为.asm文件即可
- PCSpim模拟器:用于运行代码
- MIPS指令的参照表:不会表达的语义随手一查
写在前面
汇编代码的可读性比较差,它的操作变量是寄存器,有时候要用到很多,就有点反应不过来。不过,代码读百遍,其义自现,如果这是你的第一个汇编程序,弄懂之后收获还是很大的。
另,如果你知道小火龙的话,hmmm,那么校友你好!网上有很多这样的程序参考啦,但是不要照搬代码呀,完全理解只需要一个下午,加油!
写汇编的时候一小件事都要写一行代码,就会很吝啬去做一些不必要的操作。比如,在以前用C/C++语言写冒泡内存循环的时候总是会在声明j变量同时初始化为0,现在一点也不想这样做了,因为不是什么顺手就能完成的事。我觉得汇编语言程序员一定是短码编程的忠实粉丝。
思路
首先回忆了一下高级语言中冒泡排序的做法,脑海中有个大致的印象
//输入,存到数组
for(int i = 0; i < 10; ++i) // 从大到小排的冒泡
for(int j = i; j < 10; ++j)
if(a[j] < a[j + 1]) swap(a[j], a[j + 1]);第一个问题
汇编语言是如何实现从键盘录入数据的?以及它存在哪?
这个问题比较简单,这涉及一组系统调用命令,形如li $v0, 5(读入一个int),不同的数字编号对应着不同的数据类型,读进来的数就放在$v0中,随用随取。
第二个问题
连续读进来一组数放到哪里?
答案是内存,并用堆栈指针寄存器保存数组的起始地址,之后来一个数就把这个地址往后挪4个字节用sw命令保存到内存,形如sw $v0, 0($t1)。
第三个问题
怎样做循环和比较大小?
汇编语言是没有loop这样的循环语句的,但是有跳转语句和条件判断语句。又可以给每个代码块分区,在该段代码前面加上取的名字和“:”,在跳转的时候就可以用上这个名字来指示跳转位置了。比较大小有一个sltu命令,它可以比较后两个操作数的相等关系,并把比较结果(1/0)存到第一个操作数。
其中关于跳转指令,有三种:j XXX 就是单纯的跳转到XXX的位置;jr和jal则与程序调用函数有关。程序调用函数,当函数调用结束后需要重新继续执行原来的程序,所以在调用函数之前,必须先存储函数返回起始点地址,用于存储这一地址的寄存器在MIPS中是$ra。jal的意思就是跳转到某个地址同时把返回调用点的地址存储在$ra中。而jr用法常见jr $ra,一般是函数调用结束后,用于跳转到返回地址。
第四个问题
有结构有调用函数的程序怎么写?
这里头除了跳转的时候要传参数还有一个比较重要的事情就是开辟栈空间来保存需要使用的局部变量。堆栈向内存地址低的方向增长,所以要用几个参数,一般就*4,让堆栈寄存器保存的指针减掉这个值,形如addi $sp, $sp, -20,意为在栈中开辟5个新地址。
图片说明
现在有了上面那些知识,我们已经可以完成程序的大体了。我的程序的结构:
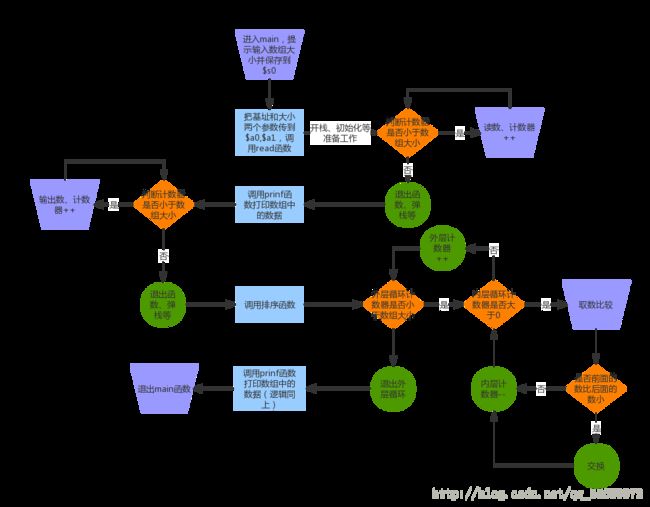
排序的时候时候会发现最好画张图,因为用到的变量比较多,容易忘记寄存器里面装的是什么。

运行结果
写好程序之后放到仿真软件里面里面运行,略微改了几个语法错误之后就可以正常跑了。但是输入数据的时候一开始有点懵逼,不知道要在英文输入法下输。下面是正常运行的截图:

完整代码
.text
.globl main
#$gp存数组基址
#$s0存数组大小
#函数调用的时候分别传给a0和a1
main:
la $a0, str_1 # 输出提示用户输入数组大小
li $v0, 4
syscall
li $v0, 5 # 系统调用把控制台中的数据读入寄存器
syscall
move $s0, $v0 # 把数组大小保存到s0
la $a0, str_2 # 输出提示用户开始输入数据
li $v0, 4
syscall
#调用read函数
move $a0, $gp # 把$gp作为参数传递给read函数拿到数组基址,不要认为现在gp里面是空
move $a1, $s0
jal read # 跳转到read函数的同时保存主函数地址到$ra
#打印刚才用户的输入结果
li $v0, 4
la $a0, str_5
syscall
move $a0, $gp
move $a1, $s0
jal prinf
#调用排序函数
move $a0, $gp
move $a1, $s0
jal sort
#调用输出函数
li $v0, 4
la $a0, str_3
syscall
move $a0, $gp
move $a1, $s0
jal prinf
#从控制台读数据的read函数
read:
addi $sp, $sp, -4 # 栈中开辟1个新地址保存数组元素个数
sw $s0, 0($sp)
li $s0, 0 # 把s0寄存器置零,作为读数个数的计数器
#下面是利用跳转语句和条件控制的读数循环
#t0做判断标志位,t1做存储地址
read_1:
sltu $t0, $s0, $a1 # s0
beq $t0, $zero, exit_1 # t0=zero 则跳转到exit_1
sll $t0, $s0, 2 # s0左移两位
add $t1, $a0, $t0 # a0加上t0生成新地址
move $t2, $a0
li $v0, 5 # 读数
syscall
sw $v0, 0($t1) # 保存读入的数据到主存
move $a0, $t2
addi $s0, $s0, 1 # s0++
j read_1
exit_1:
lw $s0, 0($sp) # 把栈里面的东西(数组大小)写回寄存器
addi $sp, $sp, 4 #弹栈,就是堆栈指针归位
jr $ra
#排序函数
sort:
addi $sp, $sp, -20 # 在栈中开辟5个新地址
#依次把要用变量的位置定出来并压栈
sw $ra, 16($sp) # 返回地址
sw $s3, 12($sp) # 数组大小
sw $s2, 8($sp) # 数组基址
sw $s1, 4($sp) # j
sw $s0, 0($sp) # i
move $s2, $a0
move $s3, $a1
move $s0, $zero
forOut:
slt $t0, $s0, $s3 # 如果i
beq $t0, $zero, exit1 # 如果t0=0,跳转到exit1退出外层循环
addi $s1, $s0, -1 # j = i - 1
forIn:
slti $t0, $s1, 0 # 如果s1<0,则t0=1
bne $t0, $zero, exit2 # 如果t0!=0,跳转到exit2
sll $t1, $s1, 2 # $tl = j*4
add $t2, $s2, $t1 # $t2存了arr[j]的地址
lw $t3, 0($t2) # 取出arr[j]的数据到$t3
lw $t4, 4($t2) # 取出arr[j+1]的数据到$t4
slt $t0, $t3, $t4 # 如果arr[j]
beq $t0, $zero, exit2 # 不满足上面条件,跳转到exit2退出内层循环
move $a0, $s2 # 把数组地址这个参数传给swap函数
move $a1, $s1 # 另一个参数j也传过去
jal swap
addi $s1, $s1, -1 # j--
j forIn
exit2:
addi $s0, $s0, 1 # i++
j forOut # 跳至外层循环
exit1:
lw $s0, 0($sp)
lw $s1, 4($sp)
lw $s2, 8($sp)
lw $s3, 12($sp)
lw $ra, 16($sp)
addi $sp, $sp, 20
jr $ra
swap:
sll $t0, $a1, 2 # j左移两位放到t0中
add $t0, $a0, $t0 # 基址值加上偏移量arr[j]的地址
lw $t1, 0($t0) # 把arr[j]的值放入t1中
lw $t2, 4($t0) # 把arr[j+1]的值放入t2中
sw $t1, 4($t0) # arr[j]=arr[j+1]
sw $t2, 0($t0) # arr[j+1]=arr[j]
jr $ra # 返回调用前的地址处
#输出函数prinf部分,功能是打印一个数组的所有元素,实现和读入差不多
prinf:
addi $sp, $sp, -4
sw $s0, 0($sp) #保存寄存器s0 s1
li $s0, 0 #将s0置零
prinf_1:
sltu $t0, $s0, $a1
beq $t0, $zero, exit_2
sll $t0, $s0, 2
add $t1, $a0, $t0
move $t2, $a0
lw $a0, 0($t1)
li $v0, 1
syscall
li $a0, ','
li $v0, 11
syscall
move $a0, $t2
addi $s0, $s0, 1
j prinf_1
exit_2:
lw $s0, 0($sp)
addi $sp, $sp, 4
jr $ra
.data
str_1:
.asciiz "请输入要排序的数组的大小:\n"
str_2:
.asciiz "请输入要排序的数:\n"
str_3:
.asciiz "\n排序的结果为:\n"
str_5:
.asciiz "输入的数为:\n"