Prometheus+Grafana监控系统
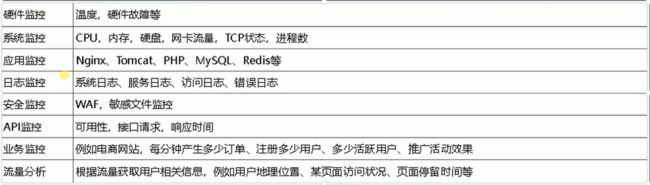
- 监控内容
Prometheus官网
Github地址
- Prometheus特点:
- 多维度数据模型:由度量名称和键值对标识的时间序列数据
- PromSQL:一种灵活的查询语言,可以利用多维数据完成复杂的查询
- 不依赖分布式存储,单个服务器节点可直接工作
- 基于HTTP的pull方式采集时间序列数据
- 推送时间序列数据通过PushGateway组件支持
- 通过服务发现或静态配置发现目标
- 多种图形模式及仪表盘支持(grafana)
- Prometheus组成与架构
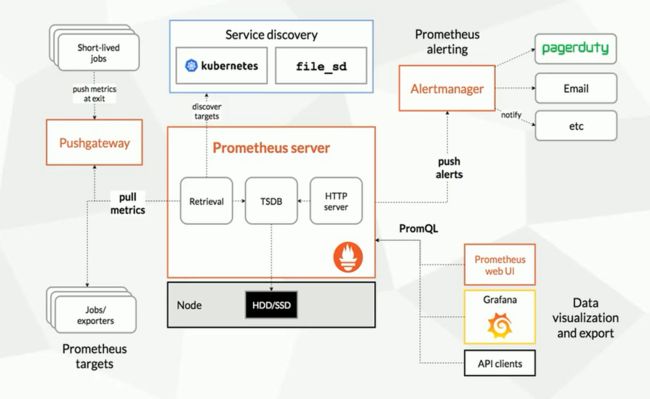
Prometheus Server:收集指标和存储时间序列数据,并提供查询接口
ClientLibrary:客户端库
Push Gateway:短期存储指标数据,主要用于临时性的任务
Exporters:采集已有的第三方服务监控指标并暴露metrics
Alertmanager:告警
Web UI:简单的Web控制台 - 数据模型
- Prometheus将所有数据存储为时间序列;具有相同度量名称以及标签属于同一个指标。
- 每个时间序列都由
度量标准名称和一组键值对(标签)作为唯一标识。 - 时间序列格式:
{
饭粒:api_http_requests_total{method=“POST”, handle="/messages"}
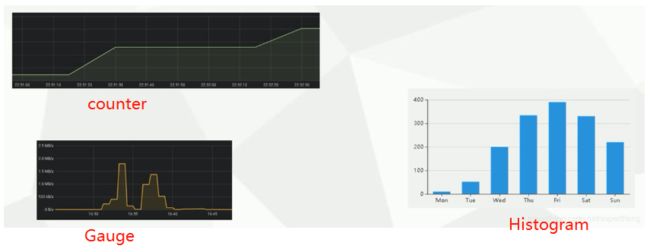
- 指标类型
- counter:递增的计数器
- Gauge:可以任意变化的数值
- Histogram:对一段时间范围内数据进行采样,并对所有数值求和与同级数量
- Summary:与Histogram类似
- 实例:可以抓取的目标称为实例(instances)
- 作业:具有相同目标的实例集合称为作业(Job)
scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['localhost:9090'] - job_name: 'node' static_configs: - targets: ['192.168.1.10:9090']
部署Prometheus
- 安装
- 二进制
下载 解压后执行同名可执行文件即可(注意:2.18.1不可用)
进入解压目录执行./prometheus --config.file=prometheus.yml - docker
docker run --name prometheus -d -p 127.0.0.1:9090:9090 prom/prometheus
在浏览器访问 http://192.168.33.7:9090
- 二进制
- 使用systemd管理Prometheus服务(二进制部署适用)
# vim /usr/lib/systemd/system/prometheus.service [Unit] Description=prometheus.io [Service] Restart=on-failure ExecStart=/usr/local/src/prometheus-2.18.0.linux-amd64/prometheus --config.file=/usr/local/src/prometheus-2.18.0.linux-amd64/prometheus.yml [Install] WantedBy=multi-user.target # systemctl daemon-reload # systemctl start prometheus # ps -ef
- 配置文件 官文
- 检查配置文件是否有问题
./promtool check config [配置文件]
- 基于文件的服务发现
- 添加本机监控
- 将默认配置文件中
static_configs两行配置注释 - 同级加上以下配置
file_sd_configs: - files: ['/usr/local/src/prometheus-2.18.0.linux-amd64/sd_config/local.yml'] refresh_interval: 5s - 创建服务发现目录
mkdir /usr/local/src/prometheus-2.18.0.linux-amd64/sd_config - 重启prometheus服务
systemctl restart prometheus - 添加服务发现配置文件
在web端查看:# vim sd_config/local.yml - targets: ['localhost:9090'] labels: idc: sz
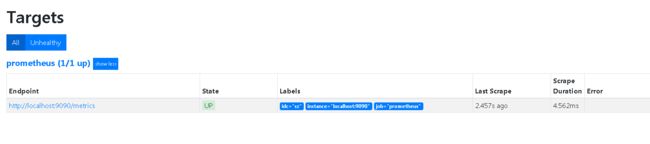
- 添加其他服务器节点监控(在上面的基础下操作)
- 在需要被监控的node节点下载node_exporter并解压 官文
- 配置systemd管理,启动
# /usr/lib/systemd/system/node_exporter.service [Unit] Description=node_exporter [Service] Restart=on-failure ExecStart=/usr/local/src/node_exporter-1.0.0.linux-amd64/node_exporter [Install] WantedBy=multi-user.target # systemctl daemon-reload # systemctl start node_exporter # curl 192.168.33.6:9100/metrics - 服务端:配置文件中加入
- job_name: 'node' file_sd_configs: - files: ['/usr/local/src/prometheus-2.18.0.linux-amd64/sd_config/server_*.yml'] refresh_interval: 5s - 重启prometheus服务
systemctl restart prometheus - 添加服务发现配置文件
在web端查看:# vim sd_config/server_node.yml - targets: ['192.168.33.6:9100', '192.168.33.9:9100']
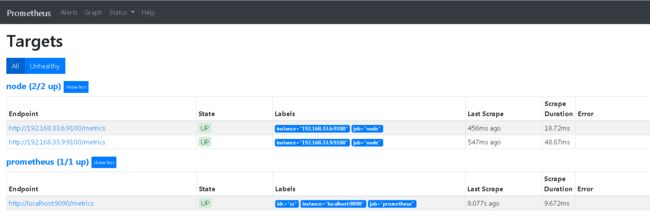
- 监控资源消耗情况
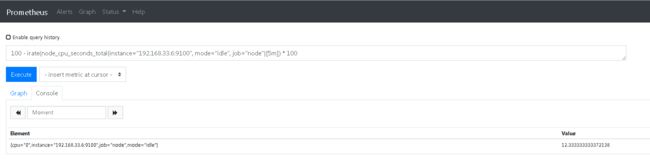
- cpu使用率:
100 - irate(node_cpu_seconds_total{instance="192.168.33.6:9100", mode="idle", job="node"}[5m]) * 100
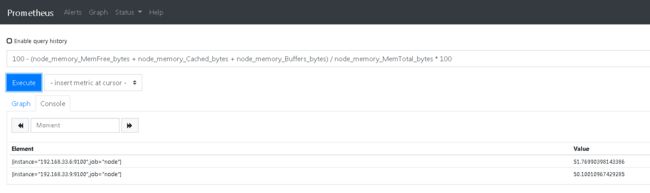
- 内存使用率:
100 - (node_memory_MemFree_bytes + node_memory_Cached_bytes + node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100
- 根分区剩余空间:
node_filesystem_free_bytes{mountpoint="/",fstype=~"ext4|xfs" } / node_filesystem_size_bytes{mountpoint="/",fstype=~"ext4|xfs" } * 100
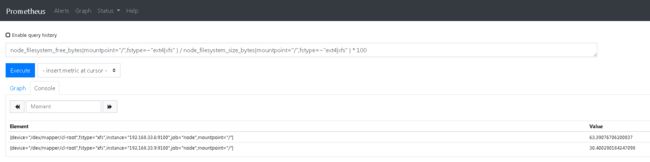
- cpu使用率:
- 监控服务运行状态
- 修改node_exporter.service启动脚本,写入需要监控的服务(可以使用正则匹配),重启
# vim /usr/lib/systemd/system/node_exporter.service ... ExecStart=/usr/local/src/node_exporter-1.0.0.linux-amd64/node_exporter --collector.systemd --collector.systemd.unit-whitelist=(docker|etcd).service ... # systemctl daemon-reload # systemctl restart node_exporter - 稍等片刻到web端查找:
node_systemd_unit_state{state="active"}
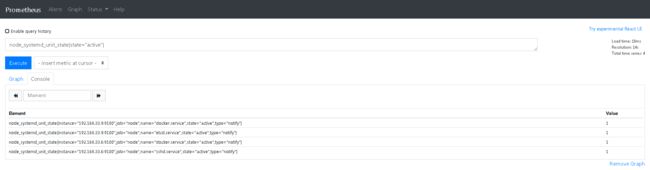
监控数据图形化展示 Grafana
-
安装grafana:
docker run -d -p 3000:3000 --name grafana grafana/grafana
在浏览器访问 192.168.33.9:3000,初识账号密码都是admin
添加Prometheus数据源
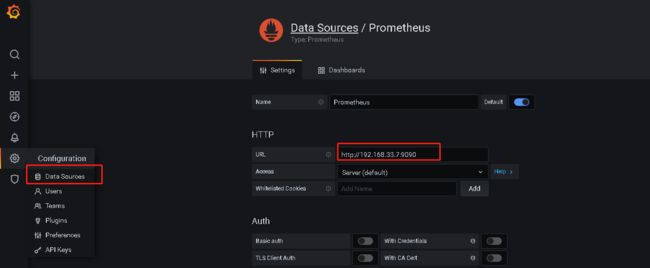
- 手动添加dashboard:
左边点击添加Dashboard -> 右上点击Add panel
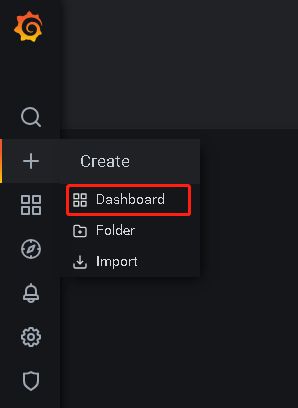
下面填入Prometheus公式(如计算CPU使用率),左边填入监控标题,Apply应用即可
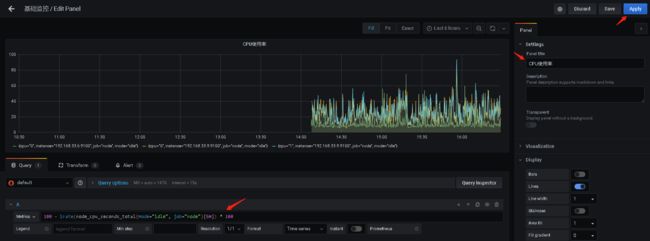
- 手动添加dashboard:
-
导入模板:
在官网查找对应数据源的模板,输入模板ID -> load

9276模板:基础监控
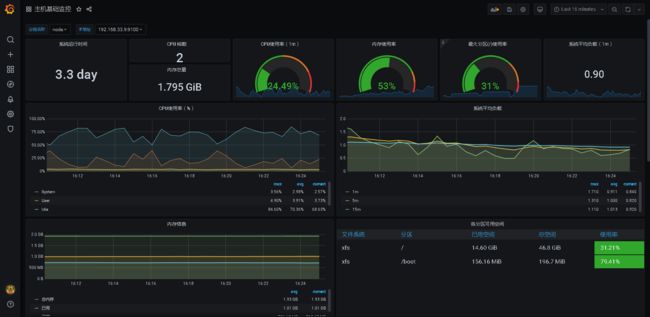
-
常见监控项
- 监控容器运行
- 在被监控的机器运行cadvisor:
docker run --volume=/:/rootfs:ro --volume=/var/run:/var/run:ro --volume=/sys:/sys:ro --volume=/var/lib/docker/:/var/lib/docker:ro --volume=/dev/disk/:/dev/disk:ro --publish=8080:8080 --detach=true --name=cadvisor --privileged --device=/dev/kmsg google/cadvisor
测试浏览器访问:192.168.33.6:8080/metrics - 在Prometheus服务端配置文件加入数据监控
# vim prometheus.yml - job_name: 'docker' static_configs: - targets: ['192.168.33.6:8080', '192.168.33.9:8080'] # systemctl restart prometheus - 在web端查看监控情况(搜索以container开头的数据)
- grafana中配置模板监控docker容器:模板
193
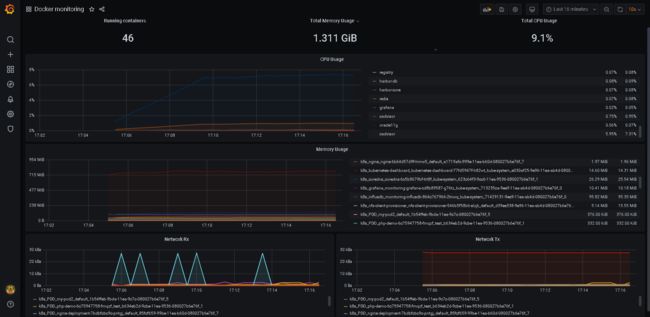
- 监控MySQL服务器
- 在被监控服务器安装运行mysqld_exporter
注意:docker运行不好使。# 1. 授权用户 # mysql -uroot -p > CREATE USER 'exporter'@'localhost' IDENTIFIED BY '111111' WITH MAX_USER_CONNECTIONS 3; > GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'exporter'@'localhost'; # 2. 创建免交互登陆文件 # vim /usr/local/src/mysqld_exporter-0.12.1.linux-amd64/.my.cnf [client] user=exporter password=111111 # 3. 创建systemd管理配置文件 # vim /usr/lib/systemd/system/mysqld_exporter.service [Unit] Description=mysqld-exporter [Service] Restart=on-failure ExecStart=/usr/local/src/mysqld_exporter-0.12.1.linux-amd64/mysqld_exporter --config.my-cnf=/usr/local/src/mysqld_exporter-0.12.1.linux-amd64/.my.cnf [Install] WantedBy=multi-user.target # systemctl daemon-reload # systemctl start mysqld_exporter # curl 192.168.33.6:9104/metrics - grafana中配置监控模板
7362

监控告警Alertmanager
- 下载 安装
- 配置Prometheus与Alertmanager通信
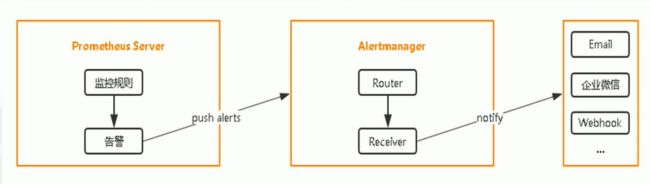
- 修改alertmanager配置并启动
# 1. 编辑配置文件 # vim alertmanager.yml global: resolve_timeout: 5m # 邮件告警配置 smtp_smarthost: 'mail.xxx.com:25' smtp_from: 'xxx' smtp_auth_username: 'xxx' smtp_auth_password: 'xxx' smtp_require_tls: false route: group_by: ['alertname'] # 根据标签进行分组 group_wait: 10s # 发送告警等待时间(在这个时间内如果有同类告警就合并以后一起发送) group_interval: 10s # 发送告警间隔时间(两个告警的间隔) repeat_interval: 5m # 重复告警的间隔时间 receiver: 'mail' receivers: - name: 'mail' email_configs: - to: '[email protected]' # 告警收敛,暂时不用,先注释 #inhibit_rules: # - source_match: # severity: 'critical' # target_match: # severity: 'warning' # equal: ['alertname', 'dev', 'instance'] # 2. 保存退出,检查配置文件是否正确 # ./amtool check-config alertmanager.yml # 3. 配置systemd管理文件 # vim /usr/lib/systemd/system/alertmanager.service [Unit] Description=alertmanager [Service] Restart=on-failure ExecStart=/usr/local/src/alertmanager-0.20.0.linux-amd64/alertmanager --config.file=/usr/local/src/alertmanager-0.20.0.linux-amd64/alertmanager.yml [Install] WantedBy=multi-user.target # 4. 启动alertmanager # systemctl daemon-reload # systemctl start alertmanager - 修改Prometheus配置开启alertmanager告警
在web端查看告警配置信息# vim prometheus.yml # 修改12行 - 127.0.0.1:9093 # 修改16行 - "rules/*.yml" # mkdir rules # vim rules/alert_test.yml groups: - name: general.rules # 注意不同规则文件的这个值要用不同值 rules: - alert: InstanceDown expr: up == 0 # 检测条件,可以在Prometheus中执行的公式 for: 1m # 持续1分钟up值为0就报警 labels: severity: error # 告警级别 annotations: description: '{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes.' summary: 'Instance {{ $labels.instance }} down' # ./promtool check config prometheus.yml # systemctl restart prometheus
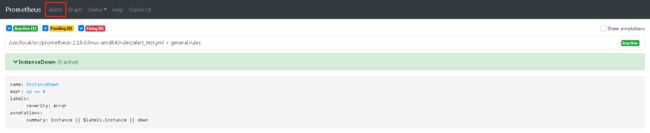
- 测试告警
关闭docker cadvisor服务,观察web端界面
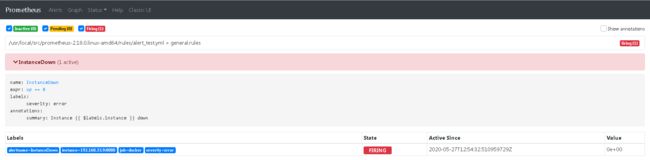
告警邮件:
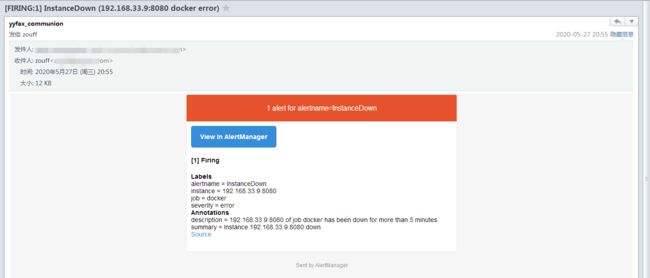
编写服务器基础告警内容:
/usr/local/src/prometheus-2.18.0.linux-amd64/rules/base_node.ymlgroups: - name: node.rules rules: - alert: DiskWillFull expr: node_filesystem_free_bytes{fstype=~"ext4|xfs" } / node_filesystem_size_bytes{fstype=~"ext4|xfs" } * 100 > 85 for: 1m labels: severity: warning annotations: description: '{{ $labels.instance }} 磁盘使用率过高' summary: 'Instance {{ $labels.instance }} :分区 {{ $labels.mountpoint }} 使用率超过85%。(当前值:{{ $value }})' - alert: CPUTooHigh expr: 100 - irate(node_cpu_seconds_total{mode="idle", job="node"}[5m]) * 100 > 80 for: 2m labels: severity: error annotations: description: '{{ $labels.instance }} CPU使用率过高' summary: 'Instance {{ $labels.instance }} CPU使用率超过80%。(当前值:{{ $value }})' - alert: MemoryTooHigh expr: 100 - (node_memory_MemFree_bytes + node_memory_Cached_bytes + node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100 > 80 for: 2m labels: severity: error annotations: description: '{{ $labels.instance }} 内存使用率过高' summary: 'Instance {{ $labels.instance }} 内存使用率超过80%。(当前值:{{ $value }})'
- 测试告警
- 告警状态
Inactive:无事发生。
Pending:已触发阈值,但未满足告警持续时间。
Firing:已触发阈值且满足告警持续时间,警报发送给接收者。 - 告警通知分组发送
route: # 当所有的规则都不匹配时使用默认的 default-receiver receiver: 'default-receiver' group_wait: 30s group_interval: 5m repeat_interval: 4h group_by: [cluster, alertname] routes: - receiver: 'database-pager' group_wait: 10s # 正则匹配 match_re: service: mysql|cassandra - receiver: 'frontend-pager' group_by: [product, environment] match: team: frontend - 告警收敛
告警分发流程:
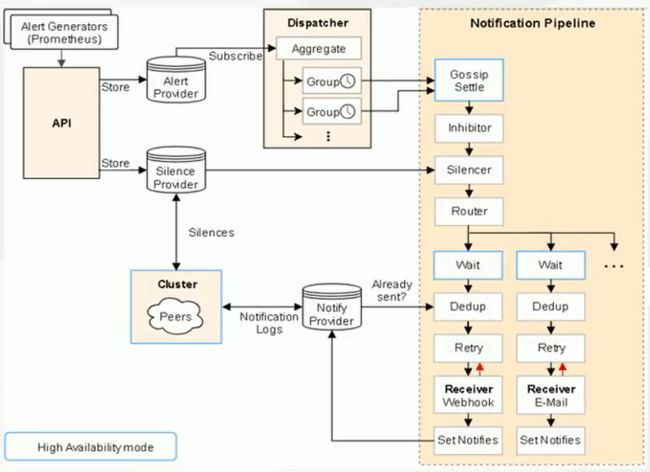
- 分组(group):将类似性质的警报分类为单个通知。
作用:
- 减少告警消息的数量
- 同类告警的聚合,帮助运维排查问题
- 抑制(inhibition):当告警发出后,停止重复发送由此警报引发的其他警报。
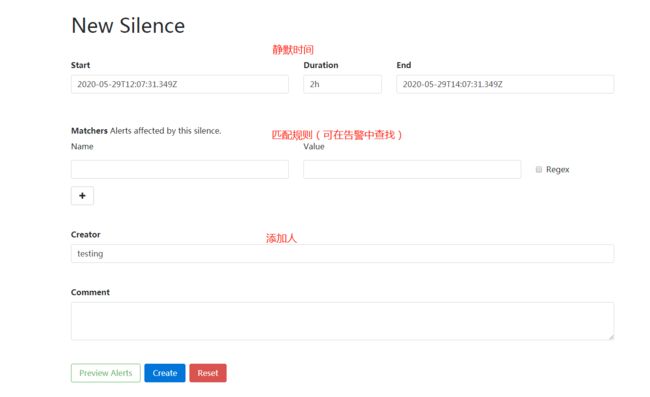
作用:消除冗余告警。 - 静默(silences):一种简单的特定时间静音提醒的机制。
作用:在维护阶段阻止相应告警。
在alertmanager后台web界面 192.168.33.8:9093 右上角创建静默规则
- 分组(group):将类似性质的警报分类为单个通知。
- 告警触发流程:
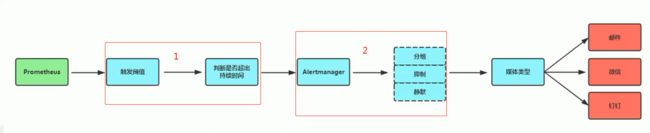
- Prometheus告警规则rules/alert_test.yml
expr: up == 0 for: 5m - alertmanager配置文件
... route: group_by: ['alertname'] group_wait: 10s group_interval: 10s repeat_interval: 5m ... inhibit_rules: ...
- Prometheus告警规则rules/alert_test.yml
K8s监控
-
监控方案
- cAdvisor + Heapster + InfluxDB + Grafana(淘汰)
劣势:仅对k8s资源级对象进行监控,无法对业务进行监控;在报警方面也有诸多不足。
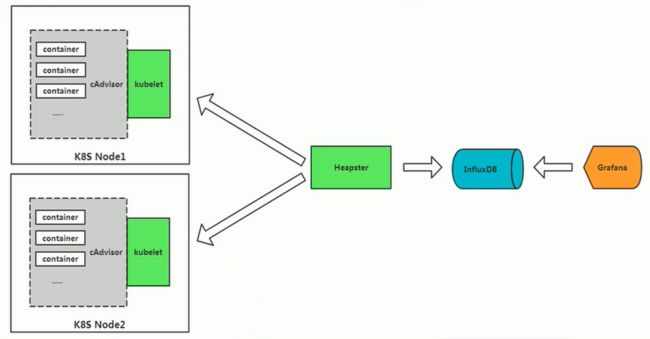
- cAdvisor/exporter + Prometheus + Grafana(目前主流)
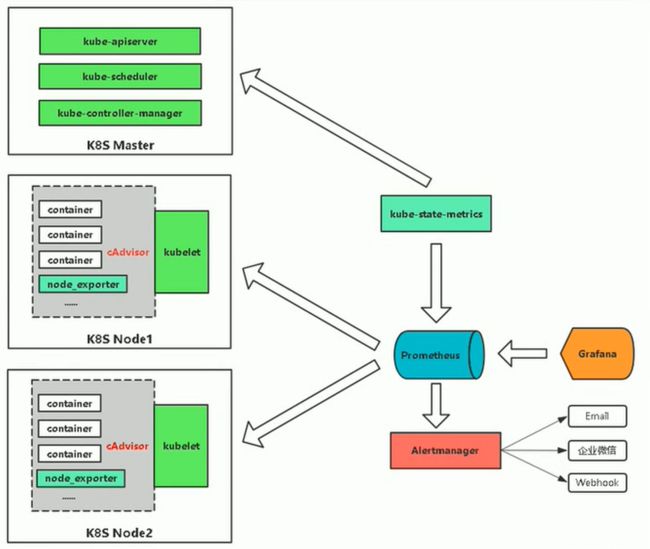
- cAdvisor + Heapster + InfluxDB + Grafana(淘汰)
-
Kubernetes监控指标:
- Kubernetes本身监控:
Node资源利用率
node数量
pods数量
资源对象监控 - Pod监控
Pod数量(项目)
容器资源利用率
应用程序
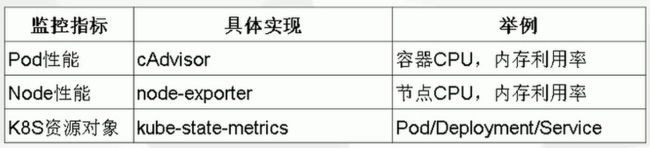
官文 - 服务发现
- Kubernetes本身监控:
-
在K8s中部署Prometheus
Yaml文件 (官方github中已下线)
应用/启动顺序:kubectl apply -f prometheus-rbac.yaml kubectl apply -f prometheus-configmap.yaml kubectl apply -f prometheus-statefulset.yaml kubectl apply -f prometheus-service.yaml通过
kubectl get pod, svc -n kube-system查看启动情况,并在浏览器访问service/prometheus暴露端口进入Prometheus web界面。
kubelet的节点使用cadvisor提供的metrics接口获取该节点所有容器相关的性能指标数据。
暴露接口地址:
http://[NodeIp]:10255/metrics/cadvisor
http://[NodeIp]:10255/metrics
进入Prometheus容器:kubectl exec -it prometheus-0 sh -c prometheus-server -n kube-system -
在k8s中部署grafana
apiVersion: apps/v1 kind: StatefulSet metadata: name: grafana namespace: kube-system spec: serviceName: "grafana" replicas: 1 selector: matchLabels: app: grafana template: metadata: labels: app: grafana spec: containers: - name: grafana image: grafana/grafana ports: - containerPort: 3000 protocol: TCP resources: limits: cpu: 100m memory: 256Mi requests: cpu: 100m volumeMounts: - name: grafana-data mountPath: /var/lib/grafana subPath: grafana securityContext: fsGroup: 472 runAsUser: 472 volumeClaimTemplates: - metadata: name: grafana-data spec: storageClassName: managed-nfs-storage accessModes: - ReadWriteOnce resources: requests: storage: "1Gi" --- apiVersion: v1 kind: Service metadata: name: grafana namespace: kube-system spec: type: NodePort ports: - port: 80 nodePort: 30007 targetPort: 3000 selector: app: grafana通过
kubectl get pod,svc -n kube-system查看状态
在浏览器访问192.168.33.8:30007进入(默认用户名密码都是admin)- 推荐模板:
集群资源监控:3119
集群资源状态监控:6417
Node监控:9276
- 推荐模板:
-
监控K8s集群Node
- node_exporter:用于UNIX/Linux系统监控,使用Go语言编写的收集器。
源码
安装参考 官文 (上文有详细讲解)
- node_exporter:用于UNIX/Linux系统监控,使用Go语言编写的收集器。
-
监控k8s集群资源对象 (查看所有对象信息
kubectl get all)

使用上文提到的 Yaml文件 部署kube-state-metrics,应用/启动顺序:# kubectl apply -f kube-state-metrics-rbac.yaml # vim kube-state-metrics-deployment.yaml # 下面内容全部覆盖 apiVersion: extensions/v1beta1 kind: Deployment metadata: name: kube-state-metrics namespace: kube-system labels: k8s-app: kube-state-metrics kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile version: v1.3.0 spec: selector: matchLabels: k8s-app: kube-state-metrics version: v1.3.0 replicas: 1 template: metadata: labels: k8s-app: kube-state-metrics version: v1.3.0 annotations: scheduler.alpha.kubernetes.io/critical-pod: '' spec: priorityClassName: system-cluster-critical serviceAccountName: kube-state-metrics containers: - name: kube-state-metrics image: lizhenliang/kube-state-metrics:v1.3.0 ports: - name: http-metrics containerPort: 8080 - name: telemetry containerPort: 8081 readinessProbe: httpGet: path: /healthz port: 8080 initialDelaySeconds: 5 timeoutSeconds: 5 - name: addon-resizer image: lizhenliang/addon-resizer:1.8.3 resources: limits: cpu: 100m memory: 30Mi requests: cpu: 100m memory: 30Mi env: - name: MY_POD_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: MY_POD_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace volumeMounts: - name: config-volume mountPath: /etc/config command: - /pod_nanny - --config-dir=/etc/config - --container=kube-state-metrics - --cpu=100m - --extra-cpu=1m - --memory=100Mi - --extra-memory=2Mi - --threshold=5 - --deployment=kube-state-metrics volumes: - name: config-volume configMap: name: kube-state-metrics-config --- apiVersion: v1 kind: ConfigMap metadata: name: kube-state-metrics-config namespace: kube-system labels: k8s-app: kube-state-metrics kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile data: NannyConfiguration: |- apiVersion: nannyconfig/v1alpha1 kind: NannyConfiguration # kubectl apply -f kube-state-metrics-deployment.yaml # kubectl apply -f kube-state-metrics-service.yaml # kubectl get pod.svc -n kube-system -o wide # 检查在Prometheus web界面查找以
kube_开头的数据,如果可以匹配则表示kube-state-metrics部署成功。
在grafana中导入模板6417 -
在K8s中部署alertmanager实现告警
- 部署alertmanager
使用上文提到的 Yaml文件 部署alertmanager,应用/启动顺序:# vim alertmanager-pvc.yaml # 将存储改为部署的nfs(通过kubectl get sc查看) storageClassName: managed-nfs-storage # kubectl apply -f alertmanager-configmap.yaml # kubectl apply -f alertmanager-pvc.yaml # kubectl apply -f alertmanager-deployment.yaml # kubectl apply -f alertmanager-service.yaml - 配置Prometheus与alertmanager通信
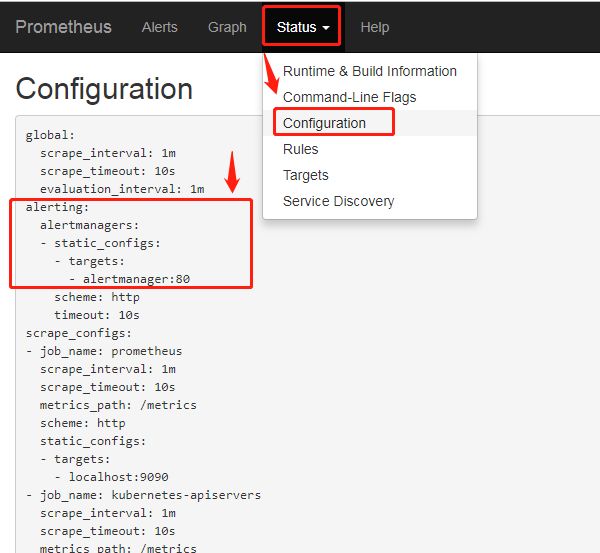
在Prometheus构建配置的yaml文件中修改最底的alerting配置,重新构建让他生效
在浏览器Prometheus web界面 Status - Configuration 查看配置是否生效# vim prometheus-configmap.yaml alerting: alertmanagers: - static_configs: - targets: ["alertmanager:80"] # kubectl apply -f prometheus-configmap.yaml
- 配置告警
- Prometheus指定rules目录
在Prometheus构建配置的yaml文件中添加规则匹配,重新构建让他生效(检查方法同上)# vim prometheus-configmap.yaml data: prometheus.yml: | # 加入以下两行 rule_files: - /etc/config/rules/*.rules # kubectl apply -f prometheus-configmap.yaml - configmap存储告警规则
# vim prometheus-rules.yaml apiVersion: v1 kind: ConfigMap metadata: name: prometheus-rules namespace: kube-system data: general.rules: | groups: - name: general.rules rules: - alert: InstanceDown expr: up == 0 for: 5m labels: severity: error annotations: description: '{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes.' summary: 'Instance {{ $labels.instance }} down' - name: node.rules rules: - alert: DiskWillFull expr: node_filesystem_free_bytes{fstype=~"ext4|xfs" } / node_filesystem_size_bytes{fstype=~"ext4|xfs" } * 100 > 85 for: 2m labels: severity: warning annotations: description: '{{ $labels.instance }} 磁盘使用率过高' summary: 'Instance {{ $labels.instance }} :分区 {{ $labels.mountpoint }} 使用率超过85%。(当前值:{{ $value }})' - alert: CPUTooHigh expr: 100 - irate(node_cpu_seconds_total{mode="idle", job="node"}[5m]) * 100 > 80 for: 2m labels: severity: error annotations: description: '{{ $labels.instance }} CPU使用率过高' summary: 'Instance {{ $labels.instance }} CPU使用率超过80%。(当前值:{{ $value }})' - alert: MemoryTooHigh expr: 100 - (node_memory_MemFree_bytes + node_memory_Cached_bytes + node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100 > 80 for: 2m labels: severity: error annotations: description: '{{ $labels.instance }} 内存使用率过高' summary: 'Instance {{ $labels.instance }} 内存使用率超过80%。(当前值:{{ $value }})' # kubectl apply -f prometheus-rules.yaml - configmap挂载到容器rules目录
在数据卷位置加上rules的配置并重新构建
注意:这里加入的name要与规则文件base_node.yml内容中的name对应,否则会出错。# vim prometheus-statefulset.yaml ... volumeMounts: - name: config-volume mountPath: /etc/config - name: prometheus-data mountPath: /data subPath: "" # 加上以下两行 - name: prometheus-rules mountPath: /etc/config/rules terminationGracePeriodSeconds: 300 volumes: - name: config-volume configMap: name: prometheus-config # 加上以下三行 - name: prometheus-rules configMap: name: prometheus-rules # kubectl apply -f prometheus-statefulset.yaml # kubectl get pod -n kube-system
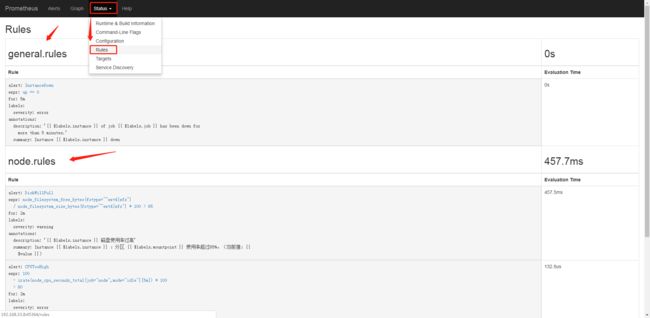
在浏览器Prometheus web界面 Status - Rules 查看规则配置是否生效
- alertmanager加入发送邮件配置并生效
# vim alertmanager-configmap.yaml alertmanager.yml: | global: # 加入以下6行 resolve_timeout: 5m smtp_smarthost: 'mail.xxx.com:25' smtp_from: '[email protected]' smtp_auth_username: '[email protected]' smtp_auth_password: 'xxx' smtp_require_tls: false receivers: - name: default-receiver # 加入以下两行:接收人 email_configs: - to: '[email protected]' # kubectl apply -f alertmanager-configmap.yaml - 分别进入Prometheus和alertmanager容器查看规则是否写入
手动关闭某个服务测试告警功能。# kubectl exec -it prometheus-0 sh -c prometheus-server -n kube-system /prometheus $ ls /etc/config/rules/ general.rules /prometheus $ vi /etc/config/rules/general.rules /prometheus $ exit # kubectl exec -it alertmanager-5bb796cb48-fbp77 sh -n kube-system /alertmanager # ls /etc/config/ alertmanager.yml /alertmanager # vi /etc/config/alertmanager.yml /alertmanager # exit
- Prometheus指定rules目录
- 总结
- 标签很重要:可以按照环境、部门、项目、管理者划分资源标签
- Grafana灵活配置模板
- PromSQL
- 利用服务发现动态加入目标
- 拓展:对业务监控
- 学习指南
- prometheus-book