Druid数据源
文章目录
- Druid简介
- druid官方给出的性能对比
- 从C3P0迁移到Druid
- maven坐标
- 相关Bean的配置
- 监控功能开启
- 结果
- druid--为监控而生
- 过滤器与过滤链
Druid简介
Druid是Java语言中最好的数据库连接池。Druid能够提供强大的监控和扩展功能(官方)。
druid官方给出的性能对比
表格来源于网络
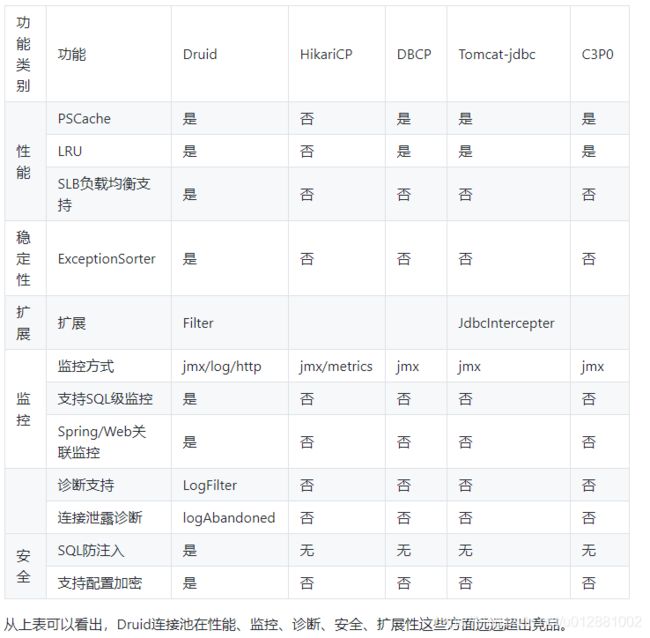
https://github.com/alibaba/druid/wiki/各种连接池性能对比测试
从C3P0迁移到Druid
maven坐标
com.alibaba
druid
1.1.8
相关Bean的配置
监控功能开启
在druid配置中将filters设置为stat
DruidStatView
com.alibaba.druid.support.http.StatViewServlet
resetEnable
true
DruidStatView
/druid/*
结果
druid–为监控而生
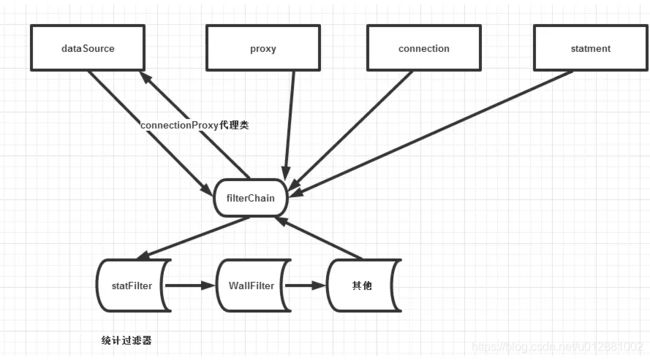
相比于其他的数据源,druid一个最大的亮点是它强大监控。因为最近在弄我们自己的系统的监控日志,所以想学习下。
所谓监控,也可理解为探针,有个成语叫见缝插针,如果没有缝隙,那就制造缝隙。所以就要建造一个代理类,而缝隙就在我们的代理类和被代理类之间,同时代理对象持有被代理对象。这个与前面C3P0的代理方式一样,但是目的不一样,一个是为了封装,一个是为了监控。
druid称自己能够支持SQL级监控,那么它是如何实现的呢?
public class PreparedStatementProxyImpl extends StatementProxyImpl implements PreparedStatementProxy
public ResultSet executeQuery() throws SQLException {
this.firstResultSet = true;
this.updateCount = null;
this.lastExecuteSql = this.sql;
this.lastExecuteType = StatementExecuteType.ExecuteQuery;
this.lastExecuteStartNano = -1L;
this.lastExecuteTimeNano = -1L;
//创建一个过滤链,并由过滤链执行SQL语句
return this.createChain().preparedStatement_executeQuery(this);
}
public class FilterChainImpl implements FilterChain
public ResultSetProxy preparedStatement_executeQuery(PreparedStatementProxy statement) throws SQLException {
if (this.pos < this.filterSize) {
return this.nextFilter().preparedStatement_executeQuery(this, statement);
} else {
//statement执行SQL语句
ResultSet resultSet = statement.getRawObject().executeQuery();
//将执行结果包装成一个代理对象
return resultSet == null ? null : new ResultSetProxyImpl(statement, resultSet, this.dataSource.createResultSetId(), statement.getLastExecuteSql());
}
}
从这两段代码可以发现一个点:在执行SQL语句前,是要经过一个过滤链来处理,等过滤链处理完成后,再由statement来执行,等到执行完成了,将执行结果resultSet 包装成一个ResultSetProxyImpl。
过滤器与过滤链
我们曾经都有在web.xml配置过过滤器filter。当我们配置了多个过滤器filter后,每个过滤器filter都有其execute()方法。我们把这些filter组织起来,放在一个叫做filterchain的list之类的容器中,那么就可以循环执行每个过滤器的execute()方法。从这里可以看出,过滤链filterchain是持有所有的filter的。为了让所有的filter执行,filter还需要持有filterchain对象。但是呢,filter并不需要一直持有filterchain,所以filterchain只是作为filter方法的形参传进来。因此,每个filter可以是filterchainA的一环,也可以是filterchainB的一环。
找一个统计连接提交的方法
public class StatFilter extends FilterEventAdapter implements StatFilterMBean
public void connection_commit(FilterChain chain, ConnectionProxy connection) throws SQLException {
chain.connection_commit(connection);
JdbcDataSourceStat dataSourceStat = chain.getDataSource().getDataSourceStat();
dataSourceStat.getConnectionStat().incrementConnectionCommitCount();
}
public void connection_commit(ConnectionProxy connection) throws SQLException {
if (this.pos < this.filterSize) {
//1.让下一个filter干活,
//3.filter继续干活,执行connection_commit,对数据源的commit操作进行统计。
this.nextFilter().connection_commit(this, connection);
} else {
//4.fliter的活干完了,然后开始执行真正的提交。
connection.getRawObject().commit();
}
}
private Filter nextFilter() {
//2.filter的活干完了,返还该filter
Filter filter = (Filter)this.getFilters().get(this.pos++);
return filter;
}
至此,总结下事件、过滤器和过滤链。
过滤器,一个基本单元。它不会引用过滤器链,因为它可以属于不同的过滤器链。它不会引用处理对象,因为它可以处理这个对象也可以处理那个对象。所以在这三者中,过滤器的过滤方法中,会传入另外两个对象,而不会在其它属性和方法中产生。web中的过滤器中的dofilter参数就是chain与req与res三个。
过滤链则是由过滤器装配而来,他是一个组合器。产生过滤器时,必须把基本过滤器传进来,而且是稳定的引用关系,但因为链条上有多个过滤器,所以要有一个容器来放它们。所以过滤链持有一个容器,init的时候,放入一个个过滤器。过滤器是串起来一个个执行的,所以还要有一个定位信息,现在执行到那一个了。
那么又有一个问题了,过滤链是如何定位到过滤器的呢。在前面的代码中可以看到,每次执行过滤器时,都有这么一段this.pos < this.filterSize。同时,在nextFilter()方法中,有Filter filter = (Filter)this.getFilters().get(this.pos++);。说明过滤链是通过pos来定位到执行了哪个过滤器了。同时查看源码发现pos确实是filterchain的一个私有变量。
public class FilterChainImpl implements FilterChain {
protected int pos = 0;
private final DataSourceProxy dataSource;
private final int filterSize;
}
观察源码发现一个有趣的问题,filterchain是不会真正持有filter的。而其中的重要方法,getFilters、nextFilter,都是从构造chain的dataSource中来的。
public List getFilters() {
return this.dataSource.getProxyFilters();
}
这有点像以前有个小品《不差钱》,二丫去小沈阳的店里吃饭,是带着菜让饭店加工的。同时也有点像我们以前做线性表排序的时候,并不真正持有被排序的对象。这就保证每次过滤链都是一次性使用的。如果不这样,事件A调用该过滤链,事件B也调用过滤链。这样的话pos指针就会乱掉。总的来说,就是如下图。
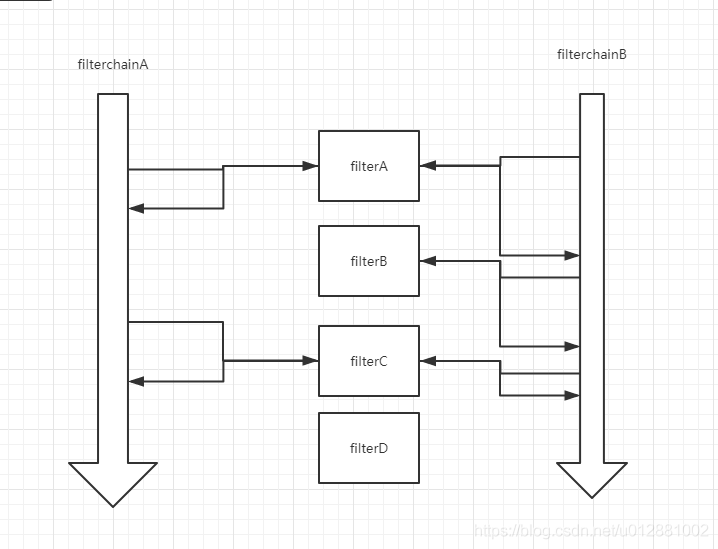
最后,在从宏观上了解下整个的执行过程。