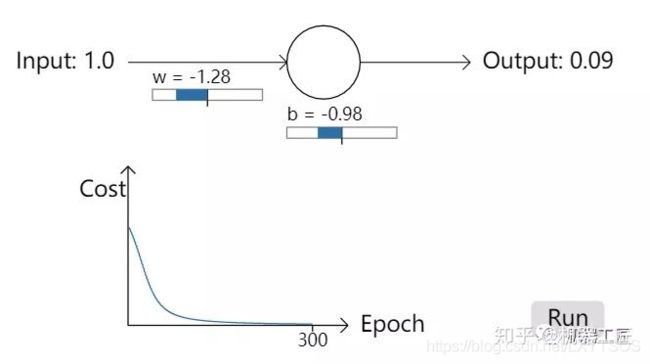
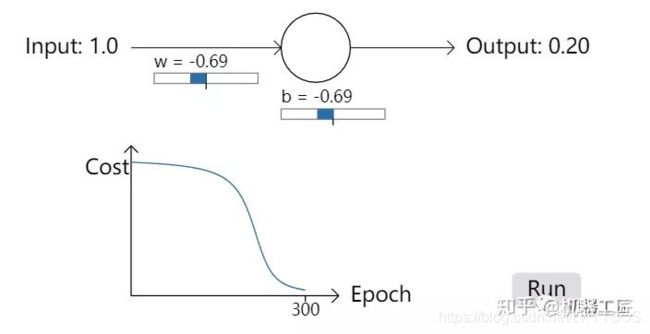
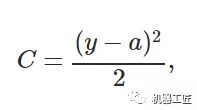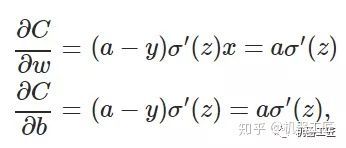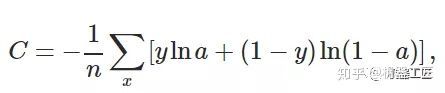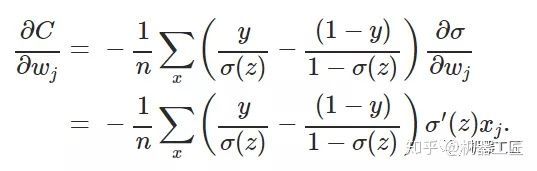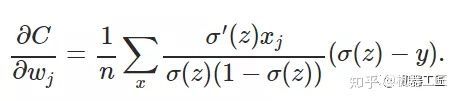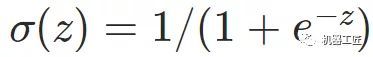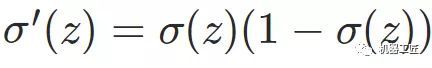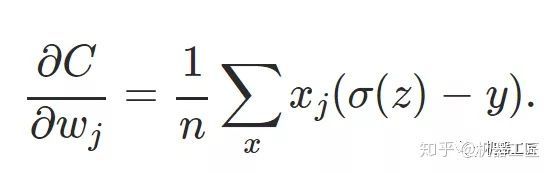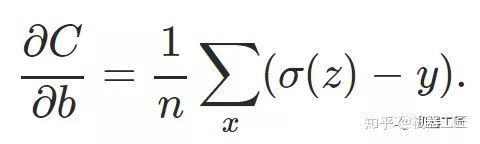- 机器学习与深度学习间关系与区别
ℒℴѵℯ心·动ꦿ໊ོ꫞
人工智能学习深度学习python
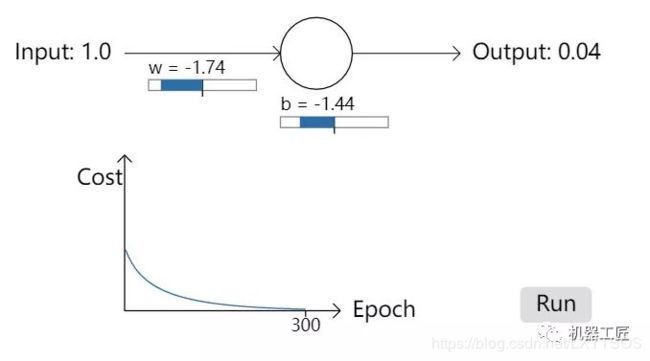
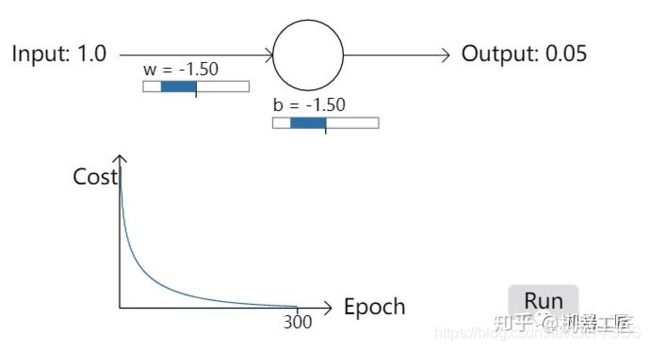
一、机器学习概述定义机器学习(MachineLearning,ML)是一种通过数据驱动的方法,利用统计学和计算算法来训练模型,使计算机能够从数据中学习并自动进行预测或决策。机器学习通过分析大量数据样本,识别其中的模式和规律,从而对新的数据进行判断。其核心在于通过训练过程,让模型不断优化和提升其预测准确性。主要类型1.监督学习(SupervisedLearning)监督学习是指在训练数据集中包含输入
- 将cmd中命令输出保存为txt文本文件
落难Coder
Windowscmdwindow
最近深度学习本地的训练中我们常常要在命令行中运行自己的代码,无可厚非,我们有必要保存我们的炼丹结果,但是复制命令行输出到txt是非常麻烦的,其实Windows下的命令行为我们提供了相应的操作。其基本的调用格式就是:运行指令>输出到的文件名称或者具体保存路径测试下,我打开cmd并且ping一下百度:pingwww.baidu.com>./data.txt看下相同目录下data.txt的输出:如果你再
- 推荐3家毕业AI论文可五分钟一键生成!文末附免费教程!
小猪包333
写论文人工智能AI写作深度学习计算机视觉
在当前的学术研究和写作领域,AI论文生成器已经成为许多研究人员和学生的重要工具。这些工具不仅能够帮助用户快速生成高质量的论文内容,还能进行内容优化、查重和排版等操作。以下是三款值得推荐的AI论文生成器:千笔-AIPassPaper、懒人论文以及AIPaperPass。千笔-AIPassPaper千笔-AIPassPaper是一款基于深度学习和自然语言处理技术的AI写作助手,旨在帮助用户快速生成高质
- AI大模型的架构演进与最新发展
季风泯灭的季节
AI大模型应用技术二人工智能架构
随着深度学习的发展,AI大模型(LargeLanguageModels,LLMs)在自然语言处理、计算机视觉等领域取得了革命性的进展。本文将详细探讨AI大模型的架构演进,包括从Transformer的提出到GPT、BERT、T5等模型的历史演变,并探讨这些模型的技术细节及其在现代人工智能中的核心作用。一、基础模型介绍:Transformer的核心原理Transformer架构的背景在Transfo
- ai绘画工具midjourney怎么下载?附作品管理教程
设计师早上好
Midjourney是一款功能强大的AI绘画工具,它使用机器学习技术和深度神经网络等算法,可以生成各种艺术风格的绘画作品。在创意设计、广告宣传等方面有着广泛的应用前景。那么,ai绘画工具midjourney怎么下载?本文将为您介绍Midjourney的下载以及作品的相关管理。一、Midjourney下载Midjourney的下载非常简单,只需打开Midjourney官网(点击“GetMidjour
- [实践应用] 深度学习之模型性能评估指标
YuanDaima2048
深度学习工具使用深度学习人工智能损失函数性能评估pytorchpython机器学习
文章总览:YuanDaiMa2048博客文章总览深度学习之模型性能评估指标分类任务回归任务排序任务聚类任务生成任务其他介绍在机器学习和深度学习领域,评估模型性能是一项至关重要的任务。不同的学习任务需要不同的性能指标来衡量模型的有效性。以下是对一些常见任务及其相应的性能评估指标的详细解释和总结。分类任务分类任务是指模型需要将输入数据分配到预定义的类别或标签中。以下是分类任务中常用的性能指标:准确率(
- [实践应用] 深度学习之优化器
YuanDaima2048
深度学习工具使用pytorch深度学习人工智能机器学习python优化器
文章总览:YuanDaiMa2048博客文章总览深度学习之优化器1.随机梯度下降(SGD)2.动量优化(Momentum)3.自适应梯度(Adagrad)4.自适应矩估计(Adam)5.RMSprop总结其他介绍在深度学习中,优化器用于更新模型的参数,以最小化损失函数。常见的优化函数有很多种,下面是几种主流的优化器及其特点、原理和PyTorch实现:1.随机梯度下降(SGD)原理:随机梯度下降通过
- 生成式地图制图
Bwywb_3
深度学习机器学习深度学习生成对抗网络
生成式地图制图(GenerativeCartography)是一种利用生成式算法和人工智能技术自动创建地图的技术。它结合了传统的地理信息系统(GIS)技术与现代生成模型(如深度学习、GANs等),能够根据输入的数据自动生成符合需求的地图。这种方法在城市规划、虚拟环境设计、游戏开发等多个领域具有应用前景。主要特点:自动化生成:通过算法和模型,系统能够根据输入的地理或空间数据自动生成地图,而无需人工逐
- 吴恩达深度学习笔记(30)-正则化的解释
极客Array
正则化(Regularization)深度学习可能存在过拟合问题——高方差,有两个解决方法,一个是正则化,另一个是准备更多的数据,这是非常可靠的方法,但你可能无法时时刻刻准备足够多的训练数据或者获取更多数据的成本很高,但正则化通常有助于避免过拟合或减少你的网络误差。如果你怀疑神经网络过度拟合了数据,即存在高方差问题,那么最先想到的方法可能是正则化,另一个解决高方差的方法就是准备更多数据,这也是非常
- 个人学习笔记7-6:动手学深度学习pytorch版-李沐
浪子L
深度学习深度学习笔记计算机视觉python人工智能神经网络pytorch
#人工智能##深度学习##语义分割##计算机视觉##神经网络#计算机视觉13.11全卷积网络全卷积网络(fullyconvolutionalnetwork,FCN)采用卷积神经网络实现了从图像像素到像素类别的变换。引入l转置卷积(transposedconvolution)实现的,输出的类别预测与输入图像在像素级别上具有一一对应关系:通道维的输出即该位置对应像素的类别预测。13.11.1构造模型下
- 深度学习-点击率预估-研究论文2024-09-14速读
sp_fyf_2024
深度学习人工智能
深度学习-点击率预估-研究论文2024-09-14速读1.DeepTargetSessionInterestNetworkforClick-ThroughRatePredictionHZhong,JMa,XDuan,SGu,JYao-2024InternationalJointConferenceonNeuralNetworks,2024深度目标会话兴趣网络用于点击率预测摘要:这篇文章提出了一种新
- 计算机视觉中,Pooling的作用
Wils0nEdwards
计算机视觉人工智能
在计算机视觉中,Pooling(池化)是一种常见的操作,主要用于卷积神经网络(CNN)中。它通过对特征图进行下采样,减少数据的空间维度,同时保留重要的特征信息。Pooling的作用可以归纳为以下几个方面:1.降低计算复杂度与内存需求Pooling操作通过对特征图进行下采样,减少了特征图的空间分辨率(例如,高度和宽度)。这意味着网络需要处理的数据量会减少,从而降低了计算量和内存需求。这对大型神经网络
- 神经网络-损失函数
红米煮粥
神经网络人工智能深度学习
文章目录一、回归问题的损失函数1.均方误差(MeanSquaredError,MSE)2.平均绝对误差(MeanAbsoluteError,MAE)二、分类问题的损失函数1.0-1损失函数(Zero-OneLossFunction)2.交叉熵损失(Cross-EntropyLoss)3.合页损失(HingeLoss)三、总结在神经网络中,损失函数(LossFunction)扮演着至关重要的角色,它
- 损失函数与反向传播
Star_.
PyTorchpytorch深度学习python
损失函数定义与作用损失函数(lossfunction)在深度学习领域是用来计算搭建模型预测的输出值和真实值之间的误差。1.损失函数越小越好2.计算实际输出与目标之间的差距3.为更新输出提供依据(反向传播)常见的损失函数回归常见的损失函数有:均方差(MeanSquaredError,MSE)、平均绝对误差(MeanAbsoluteErrorLoss,MAE)、HuberLoss是一种将MSE与MAE
- BP神经网络的传递函数
大胜归来19
MATLAB
BP网络一般都是用三层的,四层及以上的都比较少用;传输函数的选择,这个怎么说,假设你想预测的结果是几个固定值,如1,0等,满足某个条件输出1,不满足则0的话,首先想到的是hardlim函数,阈值型的,当然也可以考虑其他的;然后,假如网络是用来表达某种线性关系时,用purelin---线性传输函数;若是非线性关系的话,用别的非线性传递函数,多层网络时,每层不一定要用相同的传递函数,可以是三种配合,可
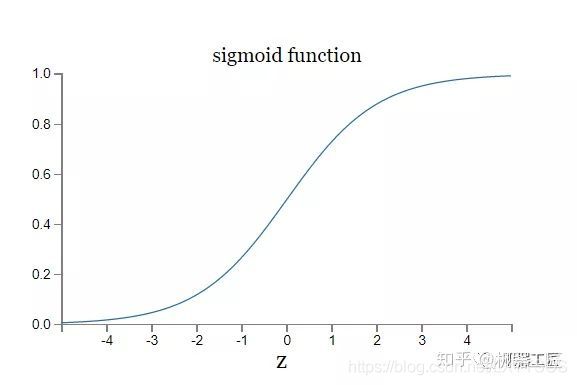
- 神经网络传递函数sigmoid,神经网络传递函数作用
快乐的小荣荣
神经网络机器学习深度学习人工智能
神经网络传递函数选取不同会有特别大差别嘛?只是最后一层,但前面层是非线性,那么可能存在区别不大的情况。线性函数f(a*input)=af(input),一般来说,input为向量,最简化情况下,可以假设input的各个维度,a1=a2=a3。。。意味着你线性层只是简单的对输入做了scale~而神经网络能起作用的原因,在于通过足够复杂的非线性函数,来模拟任何的分布。所以,神经网络必须要用非线性函数。
- Python和R均方根误差平均绝对误差算法模型
亚图跨际
Python交叉知识R回归模型误差指标归一化均方根误差生态状态指标神经网络成本误差气体排放气候模型多项式拟合
要点回归模型误差评估指标归一化均方根误差生态状态指标神经网络成本误差计算气体排放气候算法模型Python误差指标均方根误差和平均绝对误差均方根偏差或均方根误差是两个密切相关且经常使用的度量值之一,用于衡量真实值或预测值与观测值或估计值之间的差异。估计器θ^\hat{\theta}θ^相对于估计参数θ\thetaθ的RMSD定义为均方误差的平方根:RMSD(θ^)=MSE(θ^)=E((θ^−θ
- 【深度学习】训练过程中一个OOM的问题,太难查了
weixin_40293999
深度学习深度学习人工智能
现象:各位大佬又遇到过ubuntu的这个问题么?现象是在训练过程中,ssh上不去了,能ping通,没死机,但是ubunutu的pc侧的显示器,鼠标啥都不好用了。只能重启。问题原因:OOM了95G,尼玛!!!!pytorch爆内存了,然后journald假死了,在journald被watchdog干掉之后,系统就崩溃了。这种规模的爆内存一般,即使被oomkill了,也要卡半天的,确实会这样,能不能配
- 云服务业界动态简报-20180128
Captain7
一、青云青云QingCloud推出深度学习平台DeepLearningonQingCloud,包含了主流的深度学习框架及数据科学工具包,通过QingCloudAppCenter一键部署交付,可以让算法工程师和数据科学家快速构建深度学习开发环境,将更多的精力放在模型和算法调优。二、腾讯云1.腾讯云正式发布腾讯专有云TCE(TencentCloudEnterprise)矩阵,涵盖企业版、大数据版、AI
- 机器学习VS深度学习
nfgo
机器学习
机器学习(MachineLearning,ML)和深度学习(DeepLearning,DL)是人工智能(AI)的两个子领域,它们有许多相似之处,但在技术实现和应用范围上也有显著区别。下面从几个方面对两者进行区分:1.概念层面机器学习:是让计算机通过算法从数据中自动学习和改进的技术。它依赖于手动设计的特征和数学模型来进行学习,常用的模型有决策树、支持向量机、线性回归等。深度学习:是机器学习的一个子领
- 大数据毕业设计hadoop+spark+hive知识图谱租房数据分析可视化大屏 租房推荐系统 58同城租房爬虫 房源推荐系统 房价预测系统 计算机毕业设计 机器学习 深度学习 人工智能
2401_84572577
程序员大数据hadoop人工智能
做了那么多年开发,自学了很多门编程语言,我很明白学习资源对于学一门新语言的重要性,这些年也收藏了不少的Python干货,对我来说这些东西确实已经用不到了,但对于准备自学Python的人来说,或许它就是一个宝藏,可以给你省去很多的时间和精力。别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。我先来介绍一下这些东西怎么用,文末抱走。(1)Python所有方向的学习路线(
- 深度学习-13-小语言模型之SmolLM的使用
皮皮冰燃
深度学习深度学习
文章附录1SmolLM概述1.1SmolLM简介1.2下载模型2运行2.1在CPU/GPU/多GPU上运行模型2.2使用torch.bfloat162.3通过位和字节的量化版本3应用示例4问题及解决4.1attention_mask和pad_token_id报错4.2max_new_tokens=205参考附录1SmolLM概述1.1SmolLM简介SmolLM是一系列尖端小型语言模型,提供三种规
- 【NLP5-RNN模型、LSTM模型和GRU模型】
一蓑烟雨紫洛
nlprnnlstmgrunlp
RNN模型、LSTM模型和GRU模型1、什么是RNN模型RNN(RecurrentNeuralNetwork)中文称为循环神经网络,它一般以序列数据为输入,通过网络内部的结构设计有效捕捉序列之间的关系特征,一般也是以序列形式进行输出RNN的循环机制使模型隐层上一时间步产生的结果,能够作为当下时间步输入的一部分(当下时间步的输入除了正常的输入外还包括上一步的隐层输出)对当下时间步的输出产生影响2、R
- 基于深度学习的农作物病害检测
SEU-WYL
深度学习dnn深度学习人工智能
基于深度学习的农作物病害检测利用卷积神经网络(CNN)、生成对抗网络(GAN)、Transformer等深度学习技术,自动识别和分类农作物的病害,帮助农业工作者提高作物管理效率、减少损失。1.农作物病害检测的挑战病害种类繁多:农作物病害的类型多样,不同病害在同一作物上的表现差异很大,同时同一种病害在不同生长阶段的症状也可能不同。环境影响:天气、光照、湿度等外部环境因素会影响农作物的表现,使得病害检
- 基于深度学习的文本引导的图像编辑
SEU-WYL
深度学习dnn深度学习人工智能
基于深度学习的文本引导的图像编辑(Text-GuidedImageEditing)是一种通过自然语言文本指令对图像进行编辑或修改的技术。它结合了图像生成和自然语言处理(NLP)的最新进展,使用户能够通过描述性文本对图像内容进行精确的调整和操控。1.文本引导的图像编辑的挑战文本和图像之间的对齐:如何将文本中的语义信息准确地映射到图像中的特定区域或元素是一个关键挑战。这涉及到多模态数据的对齐和理解。编
- 深度学习--对抗生成网络(GAN, Generative Adversarial Network)
Ambition_LAO
深度学习生成对抗网络
对抗生成网络(GAN,GenerativeAdversarialNetwork)是一种深度学习模型,由IanGoodfellow等人在2014年提出。GAN主要用于生成数据,通过两个神经网络相互对抗,来生成以假乱真的新数据。以下是对GAN的详细阐述,包括其概念、作用、核心要点、实现过程、代码实现和适用场景。1.概念GAN由两个神经网络组成:生成器(Generator)和判别器(Discrimina
- 深度学习:怎么看pth文件的参数
奥利给少年
深度学习人工智能
.pth文件是PyTorch模型的权重文件,它通常包含了训练好的模型的参数。要查看或使用这个文件,你可以按照以下步骤操作:1.确保你有模型的定义你需要有创建这个.pth文件时所用的模型的代码。这意味着你需要有模型的类定义和架构。2.加载模型权重使用PyTorch的load_state_dict方法来加载权重。这里是如何操作的:importtorchimporttorch.nnasnn#定义模型结构
- chatgpt赋能python:如何在Python中安装Keras库?
turensu
ChatGptpythonchatgptkeras计算机
如何在Python中安装Keras库?Keras是一个简单易用的神经网络库,由FrançoisChollet编写。它在Python编程语言中实现了深度学习的功能,可以使您更轻松地构建和试验不同类型的神经网络。如果您是一名Python开发人员,肯定会想知道如何在您的Python项目中安装Keras库。在本文中,我们将向您展示如何安装和配置Keras库。步骤1:安装Python要使用Keras库,您需
- 如何理解深度学习的训练过程
奋斗的草莓熊
深度学习人工智能pythonscikit-learnvirtualenvnumpypandas
文章目录1.训练是干什么?2.预训练模型进行训练,主要更改的是预训练模型的什么东西?1.训练是干什么?以yolov5为例子,训练的目的是把一组输入猫狗图像放到神经网络中,得到一个输出模型,这个模型下次可以直接用来识别哪个是猫,哪个是狗2.预训练模型进行训练,主要更改的是预训练模型的什么东西?超参数(Hyperparameters):这是模型结构中定义的参数,比如:卷积核大小(kernel_size
- Keras深度学习框架入门及实战指南
司莹嫣Maude
Keras深度学习框架入门及实战指南keraskeras-team/keras:是一个基于Python的深度学习库,它没有使用数据库。适合用于深度学习任务的开发和实现,特别是对于需要使用Python深度学习库的场景。特点是深度学习库、Python、无数据库。项目地址:https://gitcode.com/gh_mirrors/ke/keras一、项目介绍Keras简介Keras是一款高级神经网络
- Java常用排序算法/程序员必须掌握的8大排序算法
cugfy
java
分类:
1)插入排序(直接插入排序、希尔排序)
2)交换排序(冒泡排序、快速排序)
3)选择排序(直接选择排序、堆排序)
4)归并排序
5)分配排序(基数排序)
所需辅助空间最多:归并排序
所需辅助空间最少:堆排序
平均速度最快:快速排序
不稳定:快速排序,希尔排序,堆排序。
先来看看8种排序之间的关系:
1.直接插入排序
(1
- 【Spark102】Spark存储模块BlockManager剖析
bit1129
manager
Spark围绕着BlockManager构建了存储模块,包括RDD,Shuffle,Broadcast的存储都使用了BlockManager。而BlockManager在实现上是一个针对每个应用的Master/Executor结构,即Driver上BlockManager充当了Master角色,而各个Slave上(具体到应用范围,就是Executor)的BlockManager充当了Slave角色
- linux 查看端口被占用情况详解
daizj
linux端口占用netstatlsof
经常在启动一个程序会碰到端口被占用,这里讲一下怎么查看端口是否被占用,及哪个程序占用,怎么Kill掉已占用端口的程序
1、lsof -i:port
port为端口号
[root@slave /data/spark-1.4.0-bin-cdh4]# lsof -i:8080
COMMAND PID USER FD TY
- Hosts文件使用
周凡杨
hostslocahost
一切都要从localhost说起,经常在tomcat容器起动后,访问页面时输入http://localhost:8088/index.jsp,大家都知道localhost代表本机地址,如果本机IP是10.10.134.21,那就相当于http://10.10.134.21:8088/index.jsp,有时候也会看到http: 127.0.0.1:
- java excel工具
g21121
Java excel
直接上代码,一看就懂,利用的是jxl:
import java.io.File;
import java.io.IOException;
import jxl.Cell;
import jxl.Sheet;
import jxl.Workbook;
import jxl.read.biff.BiffException;
import jxl.write.Label;
import
- web报表工具finereport常用函数的用法总结(数组函数)
老A不折腾
finereportweb报表函数总结
ADD2ARRAY
ADDARRAY(array,insertArray, start):在数组第start个位置插入insertArray中的所有元素,再返回该数组。
示例:
ADDARRAY([3,4, 1, 5, 7], [23, 43, 22], 3)返回[3, 4, 23, 43, 22, 1, 5, 7].
ADDARRAY([3,4, 1, 5, 7], "测试&q
- 游戏服务器网络带宽负载计算
墙头上一根草
服务器
家庭所安装的4M,8M宽带。其中M是指,Mbits/S
其中要提前说明的是:
8bits = 1Byte
即8位等于1字节。我们硬盘大小50G。意思是50*1024M字节,约为 50000多字节。但是网宽是以“位”为单位的,所以,8Mbits就是1M字节。是容积体积的单位。
8Mbits/s后面的S是秒。8Mbits/s意思是 每秒8M位,即每秒1M字节。
我是在计算我们网络流量时想到的
- 我的spring学习笔记2-IoC(反向控制 依赖注入)
aijuans
Spring 3 系列
IoC(反向控制 依赖注入)这是Spring提出来了,这也是Spring一大特色。这里我不用多说,我们看Spring教程就可以了解。当然我们不用Spring也可以用IoC,下面我将介绍不用Spring的IoC。
IoC不是框架,她是java的技术,如今大多数轻量级的容器都会用到IoC技术。这里我就用一个例子来说明:
如:程序中有 Mysql.calss 、Oracle.class 、SqlSe
- 高性能mysql 之 选择存储引擎(一)
annan211
mysqlInnoDBMySQL引擎存储引擎
1 没有特殊情况,应尽可能使用InnoDB存储引擎。 原因:InnoDB 和 MYIsAM 是mysql 最常用、使用最普遍的存储引擎。其中InnoDB是最重要、最广泛的存储引擎。她 被设计用来处理大量的短期事务。短期事务大部分情况下是正常提交的,很少有回滚的情况。InnoDB的性能和自动崩溃 恢复特性使得她在非事务型存储的需求中也非常流行,除非有非常
- UDP网络编程
百合不是茶
UDP编程局域网组播
UDP是基于无连接的,不可靠的传输 与TCP/IP相反
UDP实现私聊,发送方式客户端,接受方式服务器
package netUDP_sc;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
import java.net.Ine
- JQuery对象的val()方法执行结果分析
bijian1013
JavaScriptjsjquery
JavaScript中,如果id对应的标签不存在(同理JAVA中,如果对象不存在),则调用它的方法会报错或抛异常。在实际开发中,发现JQuery在id对应的标签不存在时,调其val()方法不会报错,结果是undefined。
- http请求测试实例(采用json-lib解析)
bijian1013
jsonhttp
由于fastjson只支持JDK1.5版本,因些对于JDK1.4的项目,可以采用json-lib来解析JSON数据。如下是http请求的另外一种写法,仅供参考。
package com;
import java.util.HashMap;
import java.util.Map;
import
- 【RPC框架Hessian四】Hessian与Spring集成
bit1129
hessian
在【RPC框架Hessian二】Hessian 对象序列化和反序列化一文中介绍了基于Hessian的RPC服务的实现步骤,在那里使用Hessian提供的API完成基于Hessian的RPC服务开发和客户端调用,本文使用Spring对Hessian的集成来实现Hessian的RPC调用。
定义模型、接口和服务器端代码
|---Model
&nb
- 【Mahout三】基于Mahout CBayes算法的20newsgroup流程分析
bit1129
Mahout
1.Mahout环境搭建
1.下载Mahout
http://mirror.bit.edu.cn/apache/mahout/0.10.0/mahout-distribution-0.10.0.tar.gz
2.解压Mahout
3. 配置环境变量
vim /etc/profile
export HADOOP_HOME=/home
- nginx负载tomcat遇非80时的转发问题
ronin47
nginx负载后端容器是tomcat(其它容器如WAS,JBOSS暂没发现这个问题)非80端口,遇到跳转异常问题。解决的思路是:$host:port
详细如下:
该问题是最先发现的,由于之前对nginx不是特别的熟悉所以该问题是个入门级别的:
? 1 2 3 4 5
- java-17-在一个字符串中找到第一个只出现一次的字符
bylijinnan
java
public class FirstShowOnlyOnceElement {
/**Q17.在一个字符串中找到第一个只出现一次的字符。如输入abaccdeff,则输出b
* 1.int[] count:count[i]表示i对应字符出现的次数
* 2.将26个英文字母映射:a-z <--> 0-25
* 3.假设全部字母都是小写
*/
pu
- mongoDB 复制集
开窍的石头
mongodb
mongo的复制集就像mysql的主从数据库,当你往其中的主复制集(primary)写数据的时候,副复制集(secondary)会自动同步主复制集(Primary)的数据,当主复制集挂掉以后其中的一个副复制集会自动成为主复制集。提供服务器的可用性。和防止当机问题
mo
- [宇宙与天文]宇宙时代的经济学
comsci
经济
宇宙尺度的交通工具一般都体型巨大,造价高昂。。。。。
在宇宙中进行航行,近程采用反作用力类型的发动机,需要消耗少量矿石燃料,中远程航行要采用量子或者聚变反应堆发动机,进行超空间跳跃,要消耗大量高纯度水晶体能源
以目前地球上国家的经济发展水平来讲,
- Git忽略文件
Cwind
git
有很多文件不必使用git管理。例如Eclipse或其他IDE生成的项目文件,编译生成的各种目标或临时文件等。使用git status时,会在Untracked files里面看到这些文件列表,在一次需要添加的文件比较多时(使用git add . / git add -u),会把这些所有的未跟踪文件添加进索引。
==== ==== ==== 一些牢骚
- MySQL连接数据库的必须配置
dashuaifu
mysql连接数据库配置
MySQL连接数据库的必须配置
1.driverClass:com.mysql.jdbc.Driver
2.jdbcUrl:jdbc:mysql://localhost:3306/dbname
3.user:username
4.password:password
其中1是驱动名;2是url,这里的‘dbna
- 一生要养成的60个习惯
dcj3sjt126com
习惯
一生要养成的60个习惯
第1篇 让你更受大家欢迎的习惯
1 守时,不准时赴约,让别人等,会失去很多机会。
如何做到:
①该起床时就起床,
②养成任何事情都提前15分钟的习惯。
③带本可以随时阅读的书,如果早了就拿出来读读。
④有条理,生活没条理最容易耽误时间。
⑤提前计划:将重要和不重要的事情岔开。
⑥今天就准备好明天要穿的衣服。
⑦按时睡觉,这会让按时起床更容易。
2 注重
- [介绍]Yii 是什么
dcj3sjt126com
PHPyii2
Yii 是一个高性能,基于组件的 PHP 框架,用于快速开发现代 Web 应用程序。名字 Yii (读作 易)在中文里有“极致简单与不断演变”两重含义,也可看作 Yes It Is! 的缩写。
Yii 最适合做什么?
Yii 是一个通用的 Web 编程框架,即可以用于开发各种用 PHP 构建的 Web 应用。因为基于组件的框架结构和设计精巧的缓存支持,它特别适合开发大型应
- Linux SSH常用总结
eksliang
linux sshSSHD
转载请出自出处:http://eksliang.iteye.com/blog/2186931 一、连接到远程主机
格式:
ssh name@remoteserver
例如:
ssh
[email protected]
二、连接到远程主机指定的端口
格式:
ssh name@remoteserver -p 22
例如:
ssh i
- 快速上传头像到服务端工具类FaceUtil
gundumw100
android
快速迭代用
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOExceptio
- jQuery入门之怎么使用
ini
JavaScripthtmljqueryWebcss
jQuery的强大我何问起(个人主页:hovertree.com)就不用多说了,那么怎么使用jQuery呢?
首先,下载jquery。下载地址:http://hovertree.com/hvtart/bjae/b8627323101a4994.htm,一个是压缩版本,一个是未压缩版本,如果在开发测试阶段,可以使用未压缩版本,实际应用一般使用压缩版本(min)。然后就在页面上引用。
- 带filter的hbase查询优化
kane_xie
查询优化hbaseRandomRowFilter
问题描述
hbase scan数据缓慢,server端出现LeaseException。hbase写入缓慢。
问题原因
直接原因是: hbase client端每次和regionserver交互的时候,都会在服务器端生成一个Lease,Lease的有效期由参数hbase.regionserver.lease.period确定。如果hbase scan需
- java设计模式-单例模式
men4661273
java单例枚举反射IOC
单例模式1,饿汉模式
//饿汉式单例类.在类初始化时,已经自行实例化
public class Singleton1 {
//私有的默认构造函数
private Singleton1() {}
//已经自行实例化
private static final Singleton1 singl
- mongodb 查询某一天所有信息的3种方法,根据日期查询
qiaolevip
每天进步一点点学习永无止境mongodb纵观千象
// mongodb的查询真让人难以琢磨,就查询单天信息,都需要花费一番功夫才行。
// 第一种方式:
coll.aggregate([
{$project:{sendDate: {$substr: ['$sendTime', 0, 10]}, sendTime: 1, content:1}},
{$match:{sendDate: '2015-
- 二维数组转换成JSON
tangqi609567707
java二维数组json
原文出处:http://blog.csdn.net/springsen/article/details/7833596
public class Demo {
public static void main(String[] args) { String[][] blogL
- erlang supervisor
wudixiaotie
erlang
定义supervisor时,如果是监控celuesimple_one_for_one则删除children的时候就用supervisor:terminate_child (SupModuleName, ChildPid),如果shutdown策略选择的是brutal_kill,那么supervisor会调用exit(ChildPid, kill),这样的话如果Child的behavior是gen_