ANTLR 超详细教程
解析器是功能强大的工具,使用ANTLR,您可以编写可用于多种不同语言的各种解析器。
在本完整的教程中,我们将要:
- 解释基础 :解析器是什么,解析器可以用于什么
- 了解如何设置要从Javascript,Python,Java和C#中使用的ANTLR
- 讨论如何测试解析器
- 展示ANTLR中最先进,最有用的功能 :您将学到解析所有可能的语言所需的一切
- 显示大量示例
也许您已经阅读了一些过于复杂或过于局部的教程,似乎以为您已经知道如何使用解析器。 这不是那种教程。 我们只希望您知道如何编码以及如何使用文本编辑器或IDE。 而已。
在本教程的最后:
- 您将能够编写一个解析器以识别不同的格式和语言
- 您将能够创建构建词法分析器和解析器所需的所有规则
- 您将知道如何处理遇到的常见问题
- 您将了解错误,并且将知道如何通过测试语法来避免错误。
换句话说,我们将从头开始,到结束时,您将学到所有可能需要了解ANTLR的知识。

ANTLR Mega Tutorial Giant目录列表
什么是ANTLR?
ANTLR是解析器生成器,可帮助您创建解析器的工具。 解析器获取一段文本并将其转换为一个组织化的结构 ,例如抽象语法树(AST)。 您可以将AST看作是描述代码内容的故事,也可以看作是通过将各个部分放在一起而创建的逻辑表示。
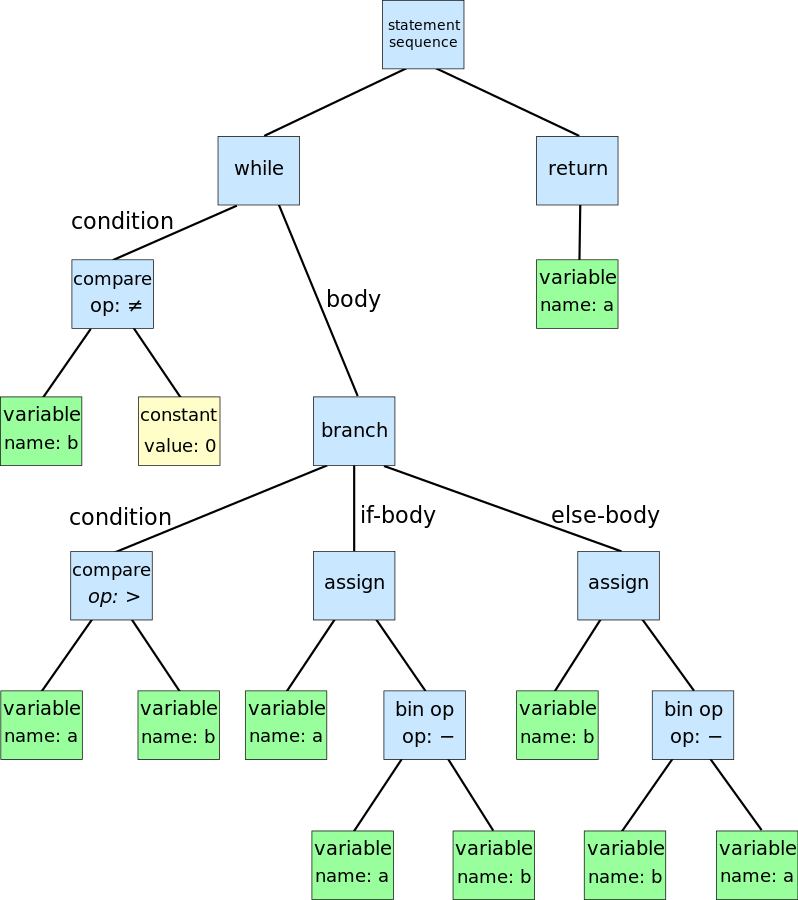
欧氏算法的AST的图形表示
获得AST所需要做的事情:
- 定义词法分析器和语法分析器
- 调用ANTLR:它将以您的目标语言(例如Java,Python,C#,Javascript)生成一个词法分析器和解析器
- 使用生成的词法分析器和解析器:调用它们并传递代码以进行识别,然后它们会返回给您AST
因此,您需要首先为要分析的事物定义一个词法分析器和解析器语法。 通常,“事物”是一种语言,但它也可以是数据格式,图表或任何以文本表示的结构。
正则表达式不够吗?
如果您是典型的程序员,您可能会问自己: 为什么我不能使用正则表达式 ? 正则表达式非常有用,例如当您想在文本字符串中查找数字时,它也有很多限制。
最明显的是缺乏递归:除非您为每个级别手动编码,否则您无法在另一个表达式中找到一个(正则)表达式。 很快就无法维持的事情。 但是更大的问题是它并不是真正可扩展的:如果您只将几个正则表达式放在一起,就将创建一个脆弱的混乱,将很难维护。
使用正则表达式不是那么容易
您是否尝试过使用正则表达式解析HTML? 这是一个可怕的想法,因为您冒着召唤克苏鲁的危险,但更重要的是, 它实际上并没有奏效 。 你不相信我吗 让我们看一下,您想要查找表的元素,因此尝试像这样的常规扩展: (.*?)
style或id类的属性。 没关系,您执行tr和td ,但是它们已满标签。
因此,您也需要消除这种情况。 而且甚至有人甚至敢使用<!—我的评论&gtl->之类的评论。 注释可以在任何地方使用,并且使用正则表达式不容易处理。 是吗?
因此,您禁止Internet使用HTML中的注释:已解决问题。
或者,您也可以使用ANTLR,对您而言似乎更简单。
ANTLR与手动编写自己的解析器
好的,您确信需要一个解析器,但是为什么要使用像ANTLR这样的解析器生成器而不是构建自己的解析器呢?
ANTLR的主要优势是生产率
如果您实际上一直在使用解析器,因为您的语言或格式在不断发展,则您需要能够保持步伐,而如果您必须处理实现a的细节,则无法做到这一点。解析器。 由于您不是为了解析而解析,因此您必须有机会专注于实现目标。 而ANTLR使得快速,整洁地执行此操作变得更加容易。
其次,定义语法后,您可以要求ANTLR生成不同语言的多个解析器。 例如,您可以使用C#获得一个解析器,而使用Javascript获得一个解析器,以在桌面应用程序和Web应用程序中解析相同的语言。
有人认为,手动编写解析器可以使其更快,并且可以产生更好的错误消息。 这有些道理,但以我的经验,ANTLR生成的解析器总是足够快。 如果确实需要,您可以调整语法并通过处理语法来提高性能和错误处理。 只要对语法感到满意,就可以这样做。
目录还是可以的
两个小注意事项:
- 在本教程的配套存储库中,您将找到所有带有测试的代码,即使我们在本文中没有看到它们
- 示例将使用不同的语言,但是知识通常适用于任何语言
设定
- 设定ANTLR
- Javascript设置
- Python设置
- Java设置
- C#设定
初学者
- 词法分析器
- 创建语法
- 设计数据格式
- Lexer规则
- 解析器规则
- 错误与调整
中级
- 用Javascript设置聊天项目
- Antlr.js
- HtmlChatListener.js
- 与听众合作
- 用语义谓词解决歧义
- 用Python继续聊天
- 与侦听器配合使用的Python方法
- 用Python测试
- 解析标记
- 词汇模式
- 解析器文法
高级
- Java中的标记项目
- 主App.java
- 使用ANTLR转换代码
- 转换代码的喜悦与痛苦
- 高级测试
- 处理表情
- 解析电子表格
- C#中的电子表格项目
- Excel注定了
- 测试一切
结束语
- 技巧和窍门
- 结论
设定
在本节中,我们准备使用ANTLR的开发环境:解析器生成器工具,每种语言的支持工具和运行时。
1.设置ANTLR
ANTLR实际上由两个主要部分组成:用于生成词法分析器和解析器的工具,以及运行它们所需的运行时。
语言工程师将只需要您使用该工具,而运行时将包含在使用您的语言的最终软件中。
无论您使用哪种语言,该工具始终是相同的:这是开发计算机上所需的Java程序。 尽管每种语言的运行时都不同,但是开发人员和用户都必须可以使用它。
该工具的唯一要求是您已经安装了至少Java 1.7 。 要安装Java程序,您需要从官方站点下载最新版本,当前版本为:
http://www.antlr.org/download/antlr-4.6-complete.jar使用说明
- 将下载的工具复制到通常放置第三方Java库的位置(例如
/usr/local/lib或C:\Program Files\Java\lib) - 将工具添加到您的
CLASSPATH。 将其添加到您的启动脚本中(例如.bash_profile) - (可选)还在您的启动脚本中添加别名,以简化ANTLR的使用
在Linux / Mac OS上执行说明
// 1.
sudo cp antlr-4.6-complete.jar /usr/local/lib/
// 2. and 3.
// add this to your .bash_profile
export CLASSPATH=".:/usr/local/lib/antlr-4.6-complete.jar:$CLASSPATH"
// simplify the use of the tool to generate lexer and parser
alias antlr4='java -Xmx500M -cp "/usr/local/lib/antlr-4.6-complete.jar:$CLASSPATH" org.antlr.v4.Tool'
// simplify the use of the tool to test the generated code
alias grun='java org.antlr.v4.gui.TestRig'在Windows上执行说明
// 1.
Go to System Properties dialog > Environment variables
-> Create or append to the CLASSPATH variable
// 2. and 3. Option A: use doskey
doskey antlr4=java org.antlr.v4.Tool $*
doskey grun =java org.antlr.v4.gui.TestRig $*
// 2. and 3. Option B: use batch files
// create antlr4.bat
java org.antlr.v4.Tool %*
// create grun.bat
java org.antlr.v4.gui.TestRig %*
// put them in the system path or any of the directories included in %path%典型工作流程
使用ANTLR时,首先要编写语法 ,即扩展名为.g4的文件,其中包含要分析的语言规则。 然后,您可以使用antlr4程序来生成程序将实际使用的文件,例如词法分析器和解析器。
antlr4 运行antlr4时可以指定几个重要选项。
首先,您可以指定目标语言,以Python或JavaScript或任何其他不同于Java的目标(默认语言)生成解析器。 其他的用于生成访问者和侦听器(不要担心,如果您不知道这些是什么,我们将在后面进行解释)。
缺省情况下,仅生成侦听器,因此要创建访问者,请使用-visitor命令行选项,如果不想生成-no-listener则使用-no-listener listener。 也有相反的选项-no-visitor和-listener ,但它们是默认值。
antlr4 -visitor 您可以使用一个名为TestRig (的小实用工具来优化语法测试TestRig (尽管,如我们所见,它通常是grun的别名)。
grun 文件名是可选的,您可以代替分析在控制台上键入的输入。
如果要使用测试工具,则即使您的程序是用另一种语言编写的,也需要生成Java解析器。 这可以通过选择与antlr4不同的选项来antlr4 。
手动测试语法初稿时,Grun非常有用。 随着它变得更加稳定,您可能希望继续进行自动化测试(我们将看到如何编写它们)。
Grun还有一些有用的选项: -tokens ,显示检测到的令牌, -gui生成AST的图像。
2. Javascript设置
您可以将语法与Javascript文件放在同一文件夹中。 包含语法的文件必须具有与语法相同的名称,该名称必须在文件顶部声明。
在下面的示例中,名称为Chat ,文件为Chat.g4 。
通过使用ANTLR4 Java程序指定正确的选项,我们可以创建相应的Javascript解析器。
antlr4 -Dlanguage=JavaScript Chat.g4请注意,该选项区分大小写,因此请注意大写的“ S”。 如果您输入有误,则会收到类似以下的消息。
error(31): ANTLR cannot generate Javascript code as of version 4.6ANTLR可以与node.js一起使用,也可以在浏览器中使用。 对于浏览器,您需要使用webpack或require.js 。 如果您不知道如何使用两者之一,可以查阅官方文档寻求帮助或阅读网络上的antlr教程。 我们将使用node.js ,只需使用以下标准命令即可为之安装ANTLR运行时。
npm install antlr43. Python设置
有了语法后,请将其放在与Python文件相同的文件夹中。 该文件必须具有与语法相同的名称,该名称必须在文件顶部声明。 在下面的示例中,名称为Chat ,文件为Chat.g4 。
通过使用ANTLR4 Java程序指定正确的选项,我们可以简单地创建相应的Python解析器。 对于Python,您还需要注意Python的版本2或3。
antlr4 -Dlanguage=Python3 Chat.g4PyPi提供了运行时,因此您可以使用pio进行安装。
pip install antlr4-python3-runtime同样,您只需要记住指定正确的python版本。
4. Java设定
要使用ANTLR设置我们的Java项目,您可以手动执行操作。 或者您可以成为文明的人并使用Gradle或Maven。
另外,您可以在IDE中查看ANTLR插件。
4.1使用Gradle进行Java设置
这就是我通常设置Gradle项目的方式。
我使用Gradle插件调用ANTLR,也使用IDEA插件生成IntelliJ IDEA的配置。
dependencies {
antlr "org.antlr:antlr4:4.5.1"
compile "org.antlr:antlr4-runtime:4.5.1"
testCompile 'junit:junit:4.12'
}
generateGrammarSource {
maxHeapSize = "64m"
arguments += ['-package', 'me.tomassetti.mylanguage']
outputDirectory = new File("generated-src/antlr/main/me/tomassetti/mylanguage".toString())
}
compileJava.dependsOn generateGrammarSource
sourceSets {
generated {
java.srcDir 'generated-src/antlr/main/'
}
}
compileJava.source sourceSets.generated.java, sourceSets.main.java
clean{
delete "generated-src"
}
idea {
module {
sourceDirs += file("generated-src/antlr/main")
}
}我将语法放在src / main / antlr /下 ,并且gradle配置确保它们在与程序包相对应的目录中生成。 例如,如果我希望解析器位于包me.tomassetti.mylanguage中,则必须将其生成到generate-src / antlr / main / me / tomassetti / mylanguage中 。
此时,我可以简单地运行:
# Linux/Mac
./gradlew generateGrammarSource
# Windows
gradlew generateGrammarSource然后我从语法中生成了词法分析器和解析器。
然后我也可以运行:
# Linux/Mac
./gradlew idea
# Windows
gradlew idea我已经准备好要打开一个IDEA项目。
4.2使用Maven进行Java设置
首先,我们将在POM中指定需要antlr4-runtime作为依赖项。 我们还将使用Maven插件通过Maven运行ANTLR。
我们还可以指定是否使用ANTLR来生成访问者或侦听器。 为此,我们定义了几个相应的属性。
4.0.0
[..]
UTF-8
true
true
org.antlr
antlr4-runtime
4.6
[..]
[..]
org.antlr
antlr4-maven-plugin
4.6
antlr4
[..]
现在,您必须将语法的* .g4文件放在src/main/antlr4/me/tomassetti/examples/MarkupParser.
编写完语法后,您只需运行mvn package ,所有奇妙的事情就会发生:ANTLR被调用,它会生成词法分析器和解析器,并将它们与其余代码一起编译。
// use mwn to generate the package
mvn package如果您从未使用过Maven,则可以查看Java目标的官方ANTLR文档或Maven网站来入门。
使用Java开发ANTLR语法有一个明显的优势:有多个IDE的插件,这是该工具的主要开发人员实际使用的语言。 因此,它们是org.antlr.v4.gui.TestRig类的工具,可以轻松地集成到您的工作流中,如果您想轻松地可视化输入的AST,这些工具将非常有用。
5. C#设置
支持.NET Framework和Mono 3.5,但不支持.NET Core。 我们将使用Visual Studio创建我们的ANTLR项目,因为由C#目标的同一作者为Visual Studio创建了一个不错的扩展,称为ANTLR语言支持 。 您可以通过进入工具->扩展和更新来安装它。 当您构建项目时,此扩展将自动生成解析器,词法分析器和访问者/侦听器。
此外,该扩展名将允许您使用众所周知的菜单添加新项目来创建新的语法文件。 最后但并非最不重要的一点是,您可以在每个语法文件的属性中设置用于生成侦听器/访问者的选项。
另外,如果您更喜欢使用编辑器,则需要使用常规的Java工具生成所有内容。 您可以通过指示正确的语言来做到这一点。 在此示例中,语法称为“电子表格”。
antlr4 -Dlanguage=CSharp Spreadsheet.g4请注意,CSharp中的“ S”为大写。
您仍然需要项目的ANTLR4运行时,并且可以使用良好的nu'nuget安装它。
初学者
在本节中,我们为使用ANTLR奠定了基础:什么是词法分析器和解析器,在语法中定义它们的语法以及可用于创建它们的策略。 我们还将看到第一个示例,以展示如何使用所学知识。 如果您不记得ANTLR的工作原理,可以回到本节。
6.词法分析器
在研究解析器之前,我们需要首先研究词法分析器,也称为令牌化器。 它们基本上是解析器的第一个垫脚石,当然ANTLR也允许您构建它们。 词法分析器将各个字符转换为令牌 (解析器用来创建逻辑结构的原子)。
想象一下,此过程适用于自然语言,例如英语。 您正在阅读单个字符,将它们放在一起直到形成一个单词,然后将不同的单词组合成一个句子。
让我们看下面的示例,并想象我们正在尝试解析数学运算。
437 + 734词法分析器扫描文本,然后找到“ 4”,“ 3”,“ 7”,然后找到空格“”。 因此,它知道第一个字符实际上代表一个数字。 然后,它找到一个“ +”符号,因此知道它代表一个运算符,最后找到另一个数字。

它怎么知道的? 因为我们告诉它。
/*
* Parser Rules
*/
operation : NUMBER '+' NUMBER ;
/*
* Lexer Rules
*/
NUMBER : [0-9]+ ;
WHITESPACE : ' ' -> skip ;这不是一个完整的语法,但是我们已经可以看到词法分析器规则全部为大写,而解析器规则全部为小写。 从技术上讲,关于大小写的规则仅适用于其名称的第一个字符,但通常为了清楚起见,它们全为大写或小写。
规则通常按以下顺序编写:首先是解析器规则,然后是词法分析器规则,尽管在逻辑上它们是按相反的顺序应用的。 同样重要的是要记住, 词法分析器规则是按照它们出现的顺序进行分析的 ,它们可能是不明确的。
典型的例子是标识符:在许多编程语言中,它可以是任何字母字符串,但是某些组合(例如“ class”或“ function”)被禁止,因为它们表示一个class或function 。 因此,规则的顺序通过使用第一个匹配项来解决歧义,这就是为什么首先定义标识关键字(例如类或函数)的令牌,而最后一个用于标识符的令牌的原因。
规则的基本语法很容易: 有一个名称,一个冒号,该规则的定义和一个终止分号
NUMBER的定义包含一个典型的数字范围和一个“ +”符号,表示允许一个或多个匹配项。 这些都是我认为您熟悉的非常典型的指示,否则,您可以阅读有关正则表达式的语法的更多信息。
最后,最有趣的部分是定义WHITESPACE令牌的词法分析器规则。 这很有趣,因为它显示了如何指示ANTLR忽略某些内容。 考虑一下忽略空白如何简化解析器规则:如果我们不能说忽略WHITESPACE,则必须将其包括在解析器的每个子规则之间,以便用户在所需的地方放置空格。 像这样:
operation : WHITESPACE* NUMBER WHITESPACE* '+' WHITESPACE* NUMBER;注释通常也是如此:它们可以出现在任何地方,并且我们不想在语法的每个部分中都专门处理它们,因此我们只是忽略它们(至少在解析时)。
7.创建语法
现在,我们已经了解了规则的基本语法,下面我们来看看定义语法的两种不同方法:自顶向下和自底向上。
自上而下的方法
这种方法包括从以您的语言编写的文件的一般组织开始。
文件的主要部分是什么? 他们的顺序是什么? 每个部分中包含什么?
例如,Java文件可以分为三个部分:
- 包装声明
- 进口
- 类型定义
当您已经知道要为其设计语法的语言或格式时,此方法最有效。 具有良好理论背景的人或喜欢从“大计划”入手的人可能会首选该策略。
使用这种方法时,首先要定义代表整个文件的规则。 它可能会包括其他规则,以代表主要部分。 然后,您定义这些规则,然后从最一般的抽象规则过渡到底层的实用规则。
自下而上的方法
自下而上的方法包括首先关注小元素:定义如何捕获令牌,如何定义基本表达式等等。 然后,我们移至更高级别的构造,直到定义代表整个文件的规则。
我个人更喜欢从底层开始,这些基本项目是使用词法分析器进行分析的。 然后您自然地从那里成长到结构,该结构由解析器处理。 这种方法允许只关注语法的一小部分,为此建立语法,确保其按预期工作,然后继续进行下一个工作。
这种方法模仿了我们的学习方式。 此外,从实际代码开始的好处是,在许多语言中,实际代码实际上是相当普遍的。 实际上,大多数语言都具有标识符,注释,空格等内容。显然,您可能需要进行一些调整,例如HTML中的注释在功能上与C#中的注释相同,但是具有不同的定界符。
自底向上方法的缺点在于解析器是您真正关心的东西。 不要求您构建一个词法分析器,而是要求您构建一个可以提供特定功能的解析器。 因此,如果您不了解程序的其余部分如何工作,那么从最后一部分词法分析器开始,您可能最终会进行一些重构。
8.设计数据格式
为新语言设计语法是困难的。 您必须创建一种对用户来说简单而直观的语言,同时又要明确地使语法易于管理。 它必须简洁,清晰,自然,并且不会妨碍用户。
因此,我们从有限的内容开始:一个简单的聊天程序的语法。
让我们从对目标的更好描述开始:
- 不会有段落,因此我们可以使用换行符作为消息之间的分隔符
- 我们要允许表情符号,提及和链接。 我们将不支持HTML标签
- 由于我们的聊天将针对讨厌的青少年,因此我们希望为用户提供一种简单的方法来喊叫和设置文本颜色的格式。
最终,少年们可能会大喊大叫,全是粉红色。 多么活着的时间。
9. Lexer规则
我们首先为聊天语言定义词法分析器规则。 请记住,词法分析器规则实际上位于文件的末尾。
/*
* Lexer Rules
*/
fragment A : ('A'|'a') ;
fragment S : ('S'|'s') ;
fragment Y : ('Y'|'y') ;
fragment H : ('H'|'h') ;
fragment O : ('O'|'o') ;
fragment U : ('U'|'u') ;
fragment T : ('T'|'t') ;
fragment LOWERCASE : [a-z] ;
fragment UPPERCASE : [A-Z] ;
SAYS : S A Y S ;
SHOUTS : S H O U T S;
WORD : (LOWERCASE | UPPERCASE | '_')+ ;
WHITESPACE : (' ' | '\t') ;
NEWLINE : ('\r'? '\n' | '\r')+ ;
TEXT : ~[\])]+ ;在此示例中,我们使用规则片段 :它们是词法分析器规则的可重用构建块。 您定义它们,然后在词法分析器规则中引用它们。 如果定义它们但不将它们包括在词法分析器规则中,则它们根本无效。
我们为要在关键字中使用的字母定义一个片段。 这是为什么? 因为我们要支持不区分大小写的关键字。 除了避免重复字符的情况以外,在处理浮点数时也使用它们。 为了避免重复数字,请在点/逗号之前和之后。 如下面的例子。
fragment DIGIT : [0-9] ;
NUMBER : DIGIT+ ([.,] DIGIT+)? ;TEXT令牌显示如何捕获所有内容,除了波浪号('〜')之后的字符以外。 我们不包括右方括号']',但是由于它是用于标识一组字符结尾的字符,因此必须在其前面加上反斜杠'\'来对其进行转义。
换行规则是用这种方式制定的,因为操作系统实际上指示换行的方式不同,有些包括carriage return ('\r') ,有些包括newline ('\n') ,或者二者结合。
10.解析器规则
我们继续解析器规则,这些规则是我们的程序将与之最直接交互的规则。
/*
* Parser Rules
*/
chat : line+ EOF ;
line : name command message NEWLINE;
message : (emoticon | link | color | mention | WORD | WHITESPACE)+ ;
name : WORD ;
command : (SAYS | SHOUTS) ':' WHITESPACE ;
emoticon : ':' '-'? ')'
| ':' '-'? '('
;
link : '[' TEXT ']' '(' TEXT ')' ;
color : '/' WORD '/' message '/';
mention : '@' WORD ;第一个有趣的部分是message ,与其包含的内容有关,不如说是它所代表的结构。 我们说的是message可以是任何列出的规则中的任何顺序。 这是解决空白时无需每次重复的简单方法。 由于作为用户,我们发现空白不相关,因此我们看到类似WORD WORD mention ,但解析器实际上看到WORD WHITESPACE WORD WHITESPACE mention WHITESPACE 。
当您无法摆脱空白时,处理空白的另一种方法是更高级的:词法模式。 基本上,它允许您指定两个词法分析器部分:一个用于结构化部分,另一个用于简单文本。 这对于解析XML或HTML之类的内容很有用。 我们将在稍后展示。
很明显, 命令规则很明显,您只需要注意命令和冒号这两个选项之间不能有空格,但是之后需要一个WHITESPACE 。 表情符号规则显示了另一种表示多种选择的符号,您可以使用竖线字符“ |” 没有括号。 我们仅支持带有或不带有中间线的两个表情符号,快乐和悲伤。
就像我们已经说过的那样, 链接规则可能被认为是错误或执行不佳,实际上, TEXT捕获了除某些特殊字符之外的所有内容。 您可能只想在括号内使用WORD和WHITESPACE,或者在方括号内强制使用正确的链接格式。 另一方面,这允许用户在编写链接时犯错误,而不会使解析器抱怨。
您必须记住,解析器无法检查语义
例如,它不知道指示颜色的WORD是否实际代表有效颜色。 也就是说,它不知道使用“ dog”是错误的,但是使用“ red”是正确的。 必须通过程序的逻辑进行检查,该逻辑可以访问可用的颜色。 您必须找到在语法和您自己的代码之间划分执行力的正确平衡。
解析器应仅检查语法。 因此,经验法则是,如果有疑问,则让解析器将内容传递给程序。 然后,在程序中,检查语义并确保规则实际上具有正确的含义。
让我们看一下规则颜色:它可以包含一条消息 ,它本身也可以是消息的一部分; 这种歧义将通过使用的上下文来解决。
11.错误与调整
在尝试新语法之前,我们必须在文件开头添加一个名称。 名称必须与文件名相同,文件扩展名应为.g4 。
grammar Chat;您可以在官方文档中找到如何为您的平台安装所有内容 。 安装完所有内容后,我们创建语法,编译生成的Java代码,然后运行测试工具。
// lines preceded by $ are commands
// > are input to the tool
// - are output from the tool
$ antlr4 Chat.g4
$ javac Chat*.java
// grun is the testing tool, Chat is the name of the grammar, chat the rule that we want to parse
$ grun Chat chat
> john SAYS: hello @michael this will not work
// CTRL+D on Linux, CTRL+Z on Windows
> CTRL+D/CTRL+Z
- line 1:0 mismatched input 'john SAYS: hello @michael this will not work\n' expecting WORD好的,它不起作用。 为什么要期待WORD ? 就在那! 让我们尝试使用选项-tokens它可以识别的令牌,以找出-tokens 。
$ grun Chat chat -tokens
> john SAYS: hello @michael this will not work
- [@0,0:44='john SAYS: hello @michael this will not work\n',,1:0]
- [@1,45:44='',,2:0] 因此,它只能看到TEXT令牌。 但是我们把它放在语法的末尾,会发生什么? 问题在于它总是尝试匹配最大可能的令牌。 所有这些文本都是有效的TEXT令牌。 我们如何解决这个问题? 有很多方法,第一种当然是摆脱该令牌。 但是目前,我们将看到第二个最简单的方法。
[..]
link : TEXT TEXT ;
[..]
TEXT : ('['|'(') ~[\])]+ (']'|')');我们更改了有问题的令牌,使其包含前面的括号或方括号。 请注意,这并不完全相同,因为它允许两个系列的括号或方括号。 但这是第一步,毕竟我们正在这里学习。
让我们检查一下是否可行:
$ grun Chat chat -tokens
> john SAYS: hello @michael this will not work
- [@0,0:3='john',,1:0]
- [@1,4:4=' ',,1:4]
- [@2,5:8='SAYS',,1:5]
- [@3,9:9=':',<':'>,1:9]
- [@4,10:10=' ',,1:10]
- [@5,11:15='hello',,1:11]
- [@6,16:16=' ',,1:16]
- [@7,17:17='@',<'@'>,1:17]
- [@8,18:24='michael',,1:18]
- [@9,25:25=' ',,1:25]
- [@10,26:29='this',,1:26]
- [@11,30:30=' ',,1:30]
- [@12,31:34='will',,1:31]
- [@13,35:35=' ',,1:35]
- [@14,36:38='not',,1:36]
- [@15,39:39=' ',,1:39]
- [@16,40:43='work',,1:40]
- [@17,44:44='\n',,1:44]
- [@18,45:44='',,2:0] 使用-gui选项,我们还可以拥有一个很好的,更易于理解的图形表示。
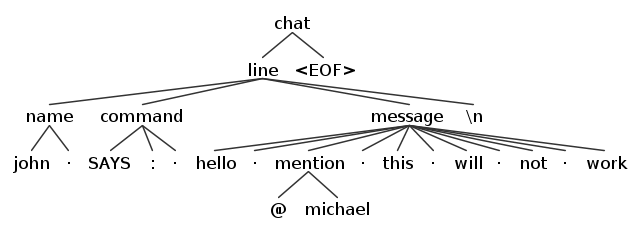
空中的点表示空白。
这行得通,但不是很聪明,不错或没有组织。 但是不用担心,稍后我们将看到更好的方法。 该解决方案的一个积极方面是,它可以显示另一个技巧。
TEXT : ('['|'(') .*? (']'|')');这是令牌TEXT的等效表示形式:“。” 匹配任何字符,“ *”表示可以随时重复前面的匹配,“?” 表示先前的比赛是非贪婪的。 也就是说,前一个子规则匹配除其后的所有内容,从而允许匹配右括号或方括号。
中级
在本节中,我们将了解如何在程序中使用ANTLR,需要使用的库和函数,如何测试解析器等。 我们了解什么是监听器以及如何使用监听器。 通过查看更高级的概念(例如语义谓词),我们还基于对基础知识的了解。 尽管我们的项目主要使用Javascript和Python,但该概念通常适用于每种语言。 当您需要记住如何组织项目时,可以回到本节。
12.使用Java脚本设置聊天项目
在前面的部分中,我们逐段地介绍了如何为聊天程序构建语法。 现在,让我们复制刚在Javascript文件的同一文件夹中创建的语法。
grammar Chat;
/*
* Parser Rules
*/
chat : line+ EOF ;
line : name command message NEWLINE ;
message : (emoticon | link | color | mention | WORD | WHITESPACE)+ ;
name : WORD WHITESPACE;
command : (SAYS | SHOUTS) ':' WHITESPACE ;
emoticon : ':' '-'? ')'
| ':' '-'? '('
;
link : TEXT TEXT ;
color : '/' WORD '/' message '/';
mention : '@' WORD ;
/*
* Lexer Rules
*/
fragment A : ('A'|'a') ;
fragment S : ('S'|'s') ;
fragment Y : ('Y'|'y') ;
fragment H : ('H'|'h') ;
fragment O : ('O'|'o') ;
fragment U : ('U'|'u') ;
fragment T : ('T'|'t') ;
fragment LOWERCASE : [a-z] ;
fragment UPPERCASE : [A-Z] ;
SAYS : S A Y S ;
SHOUTS : S H O U T S ;
WORD : (LOWERCASE | UPPERCASE | '_')+ ;
WHITESPACE : (' ' | '\t')+ ;
NEWLINE : ('\r'? '\n' | '\r')+ ;
TEXT : ('['|'(') ~[\])]+ (']'|')');通过使用ANTLR4 Java程序指定正确的选项,我们可以创建相应的Javascript解析器。
antlr4 -Dlanguage=JavaScript Chat.g4现在,您将在文件夹中找到一些新文件,它们的名称如ChatLexer.js, ChatParser.js并且还有* .tokens文件,其中没有一个对我们来说不重要,除非您想了解ANTLR的内部工作原理。
您要查看的文件是ChatListener.js ,您不会对其进行任何修改,但是它包含我们将使用自己的侦听器覆盖的方法和函数。 我们不会对其进行修改,因为每次重新生成语法时,更改都会被覆盖。
查看它,您可以看到几个输入/退出函数,每个解析器规则都有一对。 当遇到与规则匹配的一段代码时,将调用这些函数。 这是侦听器的默认实现,它使您可以在派生的侦听器上仅覆盖所需的功能,而其余部分保持不变。
var antlr4 = require('antlr4/index');
// This class defines a complete listener for a parse tree produced by ChatParser.
function ChatListener() {
antlr4.tree.ParseTreeListener.call(this);
return this;
}
ChatListener.prototype = Object.create(antlr4.tree.ParseTreeListener.prototype);
ChatListener.prototype.constructor = ChatListener;
// Enter a parse tree produced by ChatParser#chat.
ChatListener.prototype.enterChat = function(ctx) {
};
// Exit a parse tree produced by ChatParser#chat.
ChatListener.prototype.exitChat = function(ctx) {
};
[..]创建Listener的替代方法是创建一个Visitor 。 主要区别在于,您既无法控制侦听器的流程,也无法从其功能返回任何内容,而您既可以使用访问者来完成这两个操作。 因此,如果您需要控制AST节点的输入方式或从其中几个节点收集信息,则可能需要使用访客。 例如,这对于代码生成很有用,在代码生成中,创建新源代码所需的一些信息散布在许多部分。 听者和访客都使用深度优先搜索。
深度优先搜索意味着在访问某个节点时将访问其子节点,并且如果一个子节点具有其自己的子节点,则在继续第一个节点的其他子节点之前将对其进行访问。 下图将使您更容易理解该概念。

因此,对于侦听器,在与该节点的第一次相遇时将触发enter事件,并且在退出所有子节点之后将触发出口。 在下图中,您可以看到在侦听器遇到线路节点时将触发哪些功能的示例(为简单起见,仅显示与线路相关的功能)。

对于标准的访问者,其行为将是相似的,当然,对于每个单个节点都只会触发单个访问事件。 在下图中,您可以看到访问者遇到线路节点时将触发哪些功能的示例(为简单起见,仅显示与线路相关的功能)。
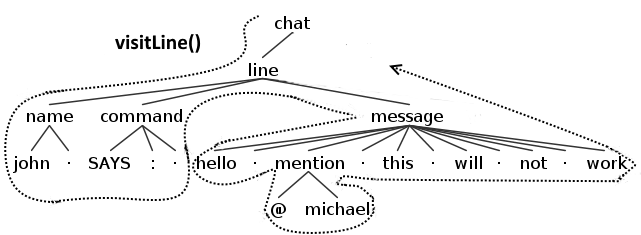
请记住, 这对于访问者的默认实现是正确的 , 这是通过返回每个函数中每个节点的子代来完成的 。 如果您忽略了访问者的方法,则有责任使访问者继续旅行或在此停留。
13. Antlr.js
终于到了看典型的ANTLR程序外观的时候了。
const http = require('http');
const antlr4 = require('antlr4/index');
const ChatLexer = require('./ChatLexer');
const ChatParser = require('./ChatParser');
const HtmlChatListener = require('./HtmlChatListener').HtmlChatListener;
http.createServer((req, res) => {
res.writeHead(200, {
'Content-Type': 'text/html',
});
res.write('');
var input = "john SHOUTS: hello @michael /pink/this will work/ :-) \n";
var chars = new antlr4.InputStream(input);
var lexer = new ChatLexer.ChatLexer(chars);
var tokens = new antlr4.CommonTokenStream(lexer);
var parser = new ChatParser.ChatParser(tokens);
parser.buildParseTrees = true;
var tree = parser.chat();
var htmlChat = new HtmlChatListener(res);
antlr4.tree.ParseTreeWalker.DEFAULT.walk(htmlChat, tree);
res.write('');
res.end();
}).listen(1337);在主文件的开头,我们导入(使用require )必要的库和文件, antlr4 (运行时)和生成的解析器,以及稍后将要看到的侦听器。
为简单起见,我们从字符串中获取输入,而在实际情况下,它将来自编辑器。
第16-19行显示了每个ANTLR程序的基础:您从输入创建字符流,将其提供给词法分析器,然后将其转换为令牌,然后由解析器对其进行解释。
花一点时间思考一下是很有用的:词法分析器处理输入的字符,准确地说是输入的副本,而解析器处理解析器生成的标记。 词法分析器无法直接处理输入,解析器甚至看不到字符 。
记住这一点很重要,以防您需要执行一些高级操作(如操纵输入)。 在这种情况下,输入是字符串,但当然可以是任何内容流。
第20行是多余的,因为该选项已经默认为true,但是在以后的运行时版本中可能会更改,因此最好指定它。
然后,在第21行,将树的根节点设置为聊天规则。 您要调用解析器,指定一个通常是第一条规则的规则。 但是,实际上您可以直接调用任何规则,例如color 。
通常,一旦从解析器中获取AST,我们就想使用侦听器或访问者来处理它。 在这种情况下,我们指定一个侦听器。 我们特定的侦听器采用一个参数:响应对象。 我们希望使用它在响应中放入一些文本以发送给用户。 设置好听众之后,我们最终与听众一起走到树上。
14. HtmlChatListener.js
我们继续看聊天项目的听众。
const antlr4 = require('antlr4/index');
const ChatLexer = require('./ChatLexer');
const ChatParser = require('./ChatParser');
var ChatListener = require('./ChatListener').ChatListener;
HtmlChatListener = function(res) {
this.Res = res;
ChatListener.call(this); // inherit default listener
return this;
};
// inherit default listener
HtmlChatListener.prototype = Object.create(ChatListener.prototype);
HtmlChatListener.prototype.constructor = HtmlChatListener;
// override default listener behavior
HtmlChatListener.prototype.enterName = function(ctx) {
this.Res.write("");
};
HtmlChatListener.prototype.exitName = function(ctx) {
this.Res.write(ctx.WORD().getText());
this.Res.write(" ");
};
HtmlChatListener.prototype.exitEmoticon = function(ctx) {
var emoticon = ctx.getText();
if(emoticon == ':-)' || emoticon == ':)')
{
this.Res.write("??");
}
if(emoticon == ':-(' || emoticon == ':(')
{
this.Res.write("??");
}
};
HtmlChatListener.prototype.enterCommand = function(ctx) {
if(ctx.SAYS() != null)
this.Res.write(ctx.SAYS().getText() + ':' + '');
if(ctx.SHOUTS() != null)
this.Res.write(ctx.SHOUTS().getText() + ':' + '
');
};
HtmlChatListener.prototype.exitLine = function(ctx) {
this.Res.write("
");
};
exports.HtmlChatListener = HtmlChatListener;在require函数调用之后,我们使HtmlChatListener扩展了ChatListener。 有趣的东西从第17行开始。
ctx参数是我们要进入/退出的节点的特定类上下文的实例。
所以for enterNameis NameContext,for exitEmoticonis EmoticonContext等。此特定上下文将具有规则的适当元素,从而可以轻松访问相应的标记和子规则。例如,NameContext将包含WORD()和WHITESPACE()之 类的字段;CommandContext 将包含类似领域的空白() ,如是说()和呼喊()。
这些功能,
enter*并且exit*,在遍历代表程序换行符的AST时,每次进入或退出相应的节点时,walker都会调用它们。侦听器允许您执行一些代码,但请务必记住,您不能停止Walker的执行和函数的执行。
在第18行,我们开始打印strong标签,因为我们希望名称为粗体,然后在exitName上,从标记WORD中获取文本并关闭标签。请注意,我们忽略了WHITESPACE令牌,没有任何东西表明我们必须显示所有内容。在这种情况下,我们可以完成输入或退出功能的所有操作。
在函数exitEmoticon上,我们仅将表情符号文本转换为表情符号字符。我们得到整个规则的文本,因为没有为该解析器规则定义令牌。在enterCommand,反而有可能是任何两个令牌如是说或喊叫,让我们检查哪一个定义。然后,如果是SHOUT,则通过大写转换来更改以下文本。请注意,由于行命令从语义上来说会更改消息的所有文本,因此我们在行规则p 的出口处关闭了标签。
现在,我们要做的就是使用来启动节点,nodejs antlr.js然后将浏览器指向其地址(通常位于)http://localhost:1337/,我们将看到下图。
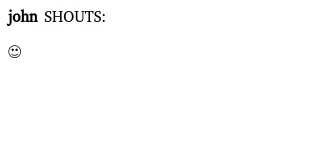
一切都很好,我们只需要添加所有不同的侦听器即可处理其余的语言。让我们从color和message开始。
15.与听众一起工作
我们已经看到了如何开始定义侦听器。现在,让我们认真研究如何在一个完整的,健壮的侦听器中发展。让我们首先添加对颜色的支持并检查我们的努力成果。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
HtmlChatListener.prototype.enterColor = function(ctx) {
var color = ctx.WORD().getText();
this.Res.write('');
};
HtmlChatListener.prototype.exitColor = function(ctx) {
this.Res.write("");
};
HtmlChatListener.prototype.exitMessage = function(ctx) {
this.Res.write(ctx.getText());
};
exports.HtmlChatListener = HtmlChatListener;
|
除非它不起作用。也许它工作太多:我们在两次编写消息的某些部分(“这将工作”):首先,当我们检查特定的节点,消息的子节点时,然后是最后。
幸运的是,使用Javascript,我们可以动态更改对象,因此我们可以利用这一事实来更改* Context对象本身。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
HtmlChatListener.prototype.exitColor = function(ctx) {
ctx.text += ctx.message().text;
ctx.text += '';
};
HtmlChatListener.prototype.exitEmoticon = function(ctx) {
var emoticon = ctx.getText();
if(emoticon == ':-)' || emoticon == ':)')
{
ctx.text = "??";
}
if(emoticon == ':-(' || emoticon == ':(')
{
ctx.text = "??";
}
};
HtmlChatListener.prototype.exitMessage = function(ctx) {
var text = '';
for (var index = 0; index < ctx.children.length; index++ ) {
if(ctx.children[index].text != null)
text += ctx.children[index].text;
else text += ctx.children[index].getText();
}
if(ctx.parentCtx instanceof ChatParser.ChatParser.LineContext == false)
{
ctx.text = text;
}
else {
this.Res.write(text);
this.Res.write("");
}
};
|
上面的片段中仅显示了修改的零件。我们在每个转换其文本的节点上添加一个文本字段,然后在每条消息的出口处打印文本(如果它是主要消息),它是行规则的直接子元素。如果这是一条消息,那也是彩色的孩子,我们将文本字段添加到我们要退出的节点上,然后进行彩色打印。我们在第30行进行检查,我们在其中查看父节点以查看它是否是object的实例LineContext。这也进一步证明了每个ctx参数如何对应于正确的类型。
在第23和27行之间,我们可以看到生成的树的每个节点的另一个字段:children,显然其中包含子节点。您可以观察到,如果存在字段文本,则将其添加到适当的变量中,否则我们将使用常规函数来获取节点的文本。
16.用语义谓词解决歧义
到目前为止,我们已经看到了如何为Java中的聊天语言构建解析器。让我们继续研究此语法,但切换到python。请记住,所有代码都在存储库中可用。在此之前,我们必须解决一个烦人的问题:TEXT令牌。我们拥有的解决方案很糟糕,此外,如果我们尝试获取令牌的文本,则必须修剪边缘,括号或方括号。所以,我们能做些什么?
我们可以使用ANTLR的一个特殊功能,即语义谓词。顾名思义,它们是产生布尔值的表达式。它们有选择地启用或禁用以下规则,因此可以解决歧义。可以使用它们的另一个原因是支持同一语言的不同版本,例如具有新结构的版本或没有该结构的旧版本。
从技术上讲,它们是较大动作组的一部分,该动作允许将任意代码嵌入语法中。缺点是语法不再与语言无关,因为操作中的代码必须对目标语言有效。因此,通常建议在无法避免的情况下只使用语义谓词,然后将大部分代码留给访问者/听众。
|
1
2
3
|
link : '[' TEXT ']' '(' TEXT ')';</font>
</font>
TEXT : {self._input.LA(-1) == ord('[') or self._input.LA(-1) == ord('(')}? ~[\])]+ ;
|
我们恢复了到其原始表述的链接,但向TEXT令牌添加了一个语义谓词,写在大括号内,后跟一个问号。我们self._input.LA(-1)用来检查当前字符之前的字符,如果此字符是方括号或圆括号,我们将激活TEXT标记。重复这一点很重要,在我们的目标语言中,这必须是有效的代码,最终将在生成的Lexer或Parser中使用,在本例中为ChatLexer.py.
这不仅对语法本身很重要,而且因为不同的目标可能具有不同的字段或方法,例如在python中LA返回intin,所以我们必须将转换char为a int。
让我们看看其他语言中的等效形式。
|
1
2
3
4
5
6
|
// C#. Notice that is .La and not .LA
TEXT : {_input.La(-1) == '[' || _input.La(-1) == '('}? ~[\])]+ ;</font>
// Java</font>
TEXT : {_input.LA(-1) == '[' || _input.LA(-1) == '('}? ~[\])]+ ;</font>
// Javascript</font>
TEXT : {this._input.LA(-1) == '[' || this._input.LA(-1) == '('}? ~[\])]+ ;
|
如果要测试前面的令牌,可以使用,_input.LT(-1,)但只能对解析器规则进行此操作。例如,如果您只想在WHITESPACE令牌之前启用提及规则。
// C#
mention: {_input.Lt(-1).Type == WHITESPACE}? '@' WORD ;
// Java
mention: {_input.LT(1).getType() == WHITESPACE}? '@' WORD ;
// Python
mention: {self._input.LT(-1).text == ' '}? '@' WORD ;
// Javascript
mention: {this._input.LT(1).text == ' '}? '@' WORD ;17.用Python继续聊天
在查看Python示例之前,我们必须修改语法并将TEXT标记放在WORD标记之前。否则,如果括号或方括号之间的字符对WORD均有效,例如,其中,则ANTLR可能会分配错误的令牌[this](link)。
在python中使用ANTLR并不比在任何其他平台上困难,您只需要注意Python的版本2或3。
|
1
|
antlr4 -Dlanguage=Python3 Chat.g4
|
就是这样。因此,运行命令后,在python项目的目录内,将有一个新生成的解析器和一个词法分析器。您可能会发现有趣的看ChatLexer.py,特别是函数TEXT_sempred (sempred代表SEM滑稽PRED icate)。
|
1
2
3
|
def TEXT_sempred(self, localctx:RuleContext, predIndex:int):
if predIndex == 0:
return self._input.LA(-1) == ord('[') or self._input.LA(-1) == ord('(')
|
您可以在代码中看到我们的谓词。这也意味着您必须检查谓词中使用的函数的正确库是否可供词法分析器使用。
18.与侦听器配合使用的Python方法
Python项目的主文件与Javascript非常相似,当然在细节上做了必要的修改。也就是说,我们必须使库和函数适应于不同语言的正确版本。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
import sys
from antlr4 import *
from ChatLexer import ChatLexer
from ChatParser import ChatParser
from HtmlChatListener import HtmlChatListener
def main(argv):
input = FileStream(argv[1])
lexer = ChatLexer(input)
stream = CommonTokenStream(lexer)
parser = ChatParser(stream)
tree = parser.chat()
output = open("output.html","w")
htmlChat = HtmlChatListener(output)
walker = ParseTreeWalker()
walker.walk(htmlChat, tree)
output.close()
if __name__ == '__main__':
main(sys.argv)
|
我们还将输入和输出更改为文件,从而避免了需要使用Python启动服务器或避免使用终端不支持的字符的问题。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
import sys
from antlr4 import *
from ChatParser import ChatParser
from ChatListener import ChatListener
class HtmlChatListener(ChatListener) :
def __init__(self, output):
self.output = output
self.output.write('')
def enterName(self, ctx:ChatParser.NameContext) :
self.output.write("")
def exitName(self, ctx:ChatParser.NameContext) :
self.output.write(ctx.WORD().getText())
self.output.write(" ")
def enterColor(self, ctx:ChatParser.ColorContext) :
color = ctx.WORD().getText()
ctx.text = '' def exitColor(self, ctx:ChatParser.ColorContext):
ctx.text += ctx.message().text
ctx.text += '' def exitEmoticon(self, ctx:ChatParser.EmoticonContext) :
emoticon = ctx.getText()
if emoticon == ':-)' or emoticon == ':)' :
ctx.text = "??" if emoticon == ':-(' or emoticon == ':(' :
ctx.text = "??" def enterLink(self, ctx:ChatParser.LinkContext):
ctx.text = '%s' % (ctx.TEXT()[1], (ctx.TEXT()[0]))
def exitMessage(self, ctx:ChatParser.MessageContext):
text = '' for child in ctx.children:
if hasattr(child, 'text'):
text += child.text
else:
text += child.getText()
if isinstance(ctx.parentCtx, ChatParser.LineContext) is False:
ctx.text = text
else:
self.output.write(text)
self.output.write("")
def enterCommand(self, ctx:ChatParser.CommandContext):
if ctx.SAYS() is not None :
self.output.write(ctx.SAYS().getText() + ':' + ')
if ctx.SHOUTS() is not None :
self.output.write(ctx.SHOUTS().getText() + ':' + ')
def exitChat(self, ctx:ChatParser.ChatContext):
self.output.write("")
|
除了35-36行(我们引入了对链接的支持)之外,没有其他新内容了。尽管您可能会注意到Python语法更简洁,并且在具有动态类型的同时,也不能将其宽松地键入Javascript。不同类型的* Context对象被明确地写出。如果只有Python工具像语言本身一样易于使用。但是当然我们不能只像这样飞过python,因此我们还介绍了测试。
19.用Python测试
尽管Visual Studio Code有一个非常好的Python扩展,它也支持单元测试,但是为了兼容性,我们将使用命令行。
|
1
|
python3 -m unittest discover -s . -p ChatTests.py
|
这就是运行测试的方式,但是在此之前我们必须编写它们。实际上,即使在此之前,我们也必须编写代码ErrorListener来管理可能发现的错误。尽管我们可以简单地读取默认错误侦听器输出的文本,但是使用我们自己的实现有一个优势,即我们可以更轻松地控制发生的情况。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
|
import sys
from antlr4 import *
from ChatParser import ChatParser
from ChatListener import ChatListener
from antlr4.error.ErrorListener import *
import io
class ChatErrorListener(ErrorListener):
def __init__(self, output):
self.output = output
self._symbol = '' def syntaxError(self, recognizer, offendingSymbol, line, column, msg, e):
self.output.write(msg)
self._symbol = offendingSymbol.text
@property def symbol(self):
return self._symbol
|
我们的课程源于此ErrorListener,我们只需要实现即可syntaxError。尽管我们还添加了一个属性符号来轻松检查哪个符号可能导致了错误。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
from antlr4 import *
from ChatLexer import ChatLexer
from ChatParser import ChatParser
from HtmlChatListener import HtmlChatListener
from ChatErrorListener import ChatErrorListener
import unittest
import io
class TestChatParser(unittest.TestCase):
def setup(self, text):
lexer = ChatLexer(InputStream(text))
stream = CommonTokenStream(lexer)
parser = ChatParser(stream)
self.output = io.StringIO()
self.error = io.StringIO()
parser.removeErrorListeners()
errorListener = ChatErrorListener(self.error)
parser.addErrorListener(errorListener)
self.errorListener = errorListener
return parser
def test_valid_name(self):
parser = self.setup("John ")
tree = parser.name()
htmlChat = HtmlChatListener(self.output)
walker = ParseTreeWalker()
walker.walk(htmlChat, tree)
# let's check that there aren't any symbols in errorListener
self.assertEqual(len(self.errorListener.symbol), 0)
def test_invalid_name(self):
parser = self.setup("Joh-")
tree = parser.name()
htmlChat = HtmlChatListener(self.output)
walker = ParseTreeWalker()
walker.walk(htmlChat, tree)
# let's check the symbol in errorListener
self.assertEqual(self.errorListener.symbol, '-')
if __name__ == '__main__':
unittest.main()
|
该setup方法用于确保正确设置所有内容。在第19-21行,我们还设置了ChatErrorListener,但是首先我们删除了默认值,否则它仍然会在标准输出上输出错误。我们正在侦听解析器中的错误,但是我们也可以捕获词法分析器生成的错误。这取决于您要测试的内容。您可能要同时检查两者。
两种正确的测试方法将检查有效名称和无效名称。这些检查链接到我们先前定义的属性symbol,如果为空,一切都很好,否则它包含导致错误的符号。请注意,在第28行,字符串的末尾有一个空格,因为我们已定义了规则名称,以WHITESPACE令牌结尾。
20.解析标记
ANTLR可以解析许多内容,包括二进制数据,在这种情况下,令牌由不可打印的字符组成。但是更常见的问题是解析标记语言,例如XML或HTML。标记也是一种用于您自己的创作的有用格式,因为它允许将非结构化文本内容与结构化注释混合在一起。它们从根本上表示一种智能文档的形式,包含文本和结构化数据。描述它们的技术术语是岛屿语言。这种类型不限于仅包含标记,有时是透视问题。
例如,您可能必须构建一个忽略预处理器指令的解析器。在这种情况下,您必须找到一种方法来区分正确的代码与遵循不同规则的指令。
无论如何,解析此类语言的问题是实际上我们不必解析很多文本,但是我们不能忽略或丢弃,因为这些文本包含了对用户有用的信息,并且是结构化的一部分文件。解决方案是词法模式,这是一种在大量自由文本中解析结构化内容的方法。
21.词汇模式
我们将从新的语法开始,看看如何使用词汇模式。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
lexer grammar MarkupLexer;
OPEN : '[' -> pushMode(BBCODE) ;
TEXT : ~('[')+ ;
// Parsing content inside tags
mode BBCODE;
CLOSE : ']' -> popMode ;
SLASH : '/' ;
EQUALS : '=' ;
STRING : '"' .*? '"' ;
ID : LETTERS+ ;
WS : [ \t\r\n] -> skip ;
fragment LETTERS : [a-zA-Z] ;
|
查看第一行,您可能会注意到一个不同:我们正在定义a lexer grammar,而不是通常的(combined) grammar。您根本无法与解析器语法一起定义词法模式。您只能在词法分析器语法中使用词法模式,而不能在组合语法中使用词法模式。正如您所看到的,其余的都不令人惊讶,我们正在定义一种BBCode标记,其标签由方括号分隔。
在第3、7和9行,您将发现关于词法模式的所有基本知识。您定义一个或多个令牌,这些令牌可以定界不同的模式并激活它们。
默认模式已经隐式定义,如果您需要定义默认模式,只需使用mode名称后跟即可。除标记语言外,词汇模式通常用于处理字符串插值。当字符串文字可以包含多个简单文本时,但可以包含任意表达式。
当我们使用组合语法时,我们可以隐式定义标记:在解析器规则中,我们使用了像'='这样的字符串。现在,我们正在使用单独的词法分析器和解析器语法,我们无法这样做。这意味着必须明确定义每个标记。因此,我们有SLASH或EQUALS之类的定义,它们通常可以直接在解析器规则中使用。这个概念很简单: 在词法分析器语法中,我们需要定义所有标记,因为稍后无法在解析器语法中定义它们。
22.解析器文法
可以这么说,我们看看词法分析器语法的另一面。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
parser grammar MarkupParser;</font>
</font>
options { tokenVocab=MarkupLexer; }</font>
</font>
file : element* ;</font>
</font>
attribute : ID '=' STRING ;</font>
</font>
content : TEXT ;</font>
</font>
element : (content | tag) ;</font>
</font>
tag : '[' ID attribute? ']' element* '[' '/' ID ']' ;
|
在第一行,我们定义一个parser grammar。由于我们需要的标记是在词法分析器语法中定义的,因此我们需要使用一个选项来对ANTLR说一下,以便在其中找到它们。在组合语法中这不是必需的,因为标记是在同一文件中定义的。
文档中还有许多其他选项可用。
除了我们定义了内容规则之外,几乎没有其他要添加的内容,以便我们可以更轻松地管理稍后在程序中找到的文本。
正如您所看到的,我只想说,我们不需要每次都显式使用令牌(例如SLASH),而是可以使用相应的文本(例如“ /”)。
ANTLR将自动转换相应标记中的文本,但是只有在已经定义它们的情况下,这种情况才会发生。简而言之,好像我们已经写过:
|
1
|
tag : OPEN ID attribute? CLOSE element* OPEN SLASH ID CLOSE ;
|
但是,如果我们还没有在词法分析器语法中明确定义它们,就不能使用隐式方法。另一种看待这种情况的方式是:当我们定义组合语法时,ANTLR定义要使用所有标记,而我们自己并未明确定义。当我们需要使用单独的词法分析器和解析器语法时,我们必须自己明确定义每个标记。完成此操作后,我们可以按需要使用它们。
在转向实际的Java代码之前,让我们看一下AST作为示例输入。

您可以轻松地注意到元素规则是透明的:在期望找到它的地方总会有一个tag或content。那么为什么要定义它呢?有两个优点:避免我们的语法重复,并简化对解析结果的管理。我们避免重复,因为如果没有元素规则,我们应该在使用它的所有地方重复 (content | tag)。如果有一天我们添加一种新型元素怎么办?除此之外,它还简化了AST的处理,因为它使节点既表示标签,又使内容扩展了注释祖先。
高级
在本节中,我们加深对ANTLR的理解。我们将研究在解析冒险中可能需要处理的更复杂的示例和情况。我们将学习如何执行更多的高级测试,捕获更多的错误并确保代码质量更高。我们将看到访客是什么以及如何使用它。最后,我们将看到如何处理表达式及其带来的复杂性。
当您需要处理复杂的解析问题时,可以回到本节。
23. Java中的标记项目
您可以按照Java安装程序中的说明进行操作,也可以仅复制 antlr-java配套存储库的文件夹。pom.xml正确配置文件后,便可以构建和执行应用程序。
|
1个
2
3
4
|
// use mwn to generate the package
mvn package// every time you need to execute the application
java -cp target/markup-example-1.0-jar-with-dependencies.jar me.tomassetti.examples.MarkupParser.App
|
如您所见,它与任何典型的Maven项目没有什么不同,尽管它确实比典型的Javascript或Python项目更为复杂。当然,如果您使用的是IDE,则无需执行与典型工作流程不同的任何操作。
24.主App.java
我们将看到如何用Java编写典型的ANTLR应用程序。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
|
package me.tomassetti.examples.MarkupParser;
import org.antlr.v4.runtime.*;
import org.antlr.v4.runtime.tree.*;
public class App
{
public static void main( String[] args )
{
ANTLRInputStream inputStream = new ANTLRInputStream(
"I would like to [b][i]emphasize[/i][/b] this and [u]underline [b]that[/b][/u] ." +
"Let's not forget to quote: [quote author=\"John\"]You're wrong![/quote]");
MarkupLexer markupLexer = new MarkupLexer(inputStream);
CommonTokenStream commonTokenStream = new CommonTokenStream(markupLexer);
MarkupParser markupParser = new MarkupParser(commonTokenStream);
MarkupParser.FileContext fileContext = markupParser.file();
MarkupVisitor visitor = new MarkupVisitor();
visitor.visit(fileContext);
}
}
|
在这一点上,主要的Java文件不足为奇,唯一的新发展是visitor。当然,ANTLR类的名称与此类之间几乎没有什么区别。这次我们正在建立一个访客,其主要优点是可以控制程序流程。虽然我们仍在处理文本,但我们不想显示它,而是希望将其从伪BBCode转换为伪Markdown。
25.使用ANTLR转换代码
处理我们从伪BBCode到伪Markdown转换的第一个问题是设计决策。我们的两种语言是不同的,坦率地说,两种原始语言都设计得不好。
BBCode的创建是为了安全起见,目的是为了禁止使用HTML,但会给用户带来一些影响。Markdown的创建是一种易于读写的格式,可以将其转换为HTML。因此它们都模仿HTML,您实际上可以在Markdown文档中使用HTML。让我们开始研究真正的转换有多混乱。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
package me.tomassetti.examples.MarkupParser;
import org.antlr.v4.runtime.*;
import org.antlr.v4.runtime.misc.*;
import org.antlr.v4.runtime.tree.*;
public class MarkupVisitor extends MarkupParserBaseVisitor
{
@Override public String visitFile(MarkupParser.FileContext context)
{
visitChildren(context);
System.out.println("");
return null;
}
@Override public String visitContent(MarkupParser.ContentContext context)
{
System.out.print(context.TEXT().getText());
return visitChildren(context);
}
}
|
我们访客的第一个版本将打印所有文本,并忽略所有标签。
您可以通过调用visitChildren或任何其他visit *函数并确定返回什么来查看如何控制流程。我们只需要覆盖我们要更改的方法。否则,默认实现只是visitContent在第23行上执行,它将访问子节点并允许访问者继续。就像对于侦听器一样,参数是正确的上下文类型。如果要停止访问者,只需在第15行返回null即可。
26.转换代码的喜悦与痛苦
即使是非常简单的代码转换,也带来一些复杂性。让我们从一些基本的访问者方法开始轻松。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
@Overridepublic String visitContent(MarkupParser.ContentContext context)
{
return context.getText();
}
@Overridepublic String visitElement(MarkupParser.ElementContext context)
{
if(context.parent instanceof MarkupParser.FileContext)
{
if(context.content() != null)
System.out.print(visitContent(context.content()));
if(context.tag() != null)
System.out.print(visitTag(context.tag()));
}
return null;
}
|
在查看主要方法之前,让我们先看看支持的方法。最重要的是,我们visitContent通过使其返回文本而不是打印文本来进行了更改。其次,我们重写了,visitElement以便它打印其子项的文本,但前提是它是top元素,而不是在tag内部。在这两种情况下,它都可以通过调用适当的visit *方法来实现。它知道要调用哪个,因为它会检查它实际上是否具有标签或内容节点。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
@Overridepublic String visitTag(MarkupParser.TagContext context)
{
String text = "";
String startDelimiter = "", endDelimiter = "";
String id = context.ID(0).getText();
switch(id)
{
case "b":
startDelimiter = endDelimiter = "**";
break;
case "u":
startDelimiter = endDelimiter = "*";
break;
case "quote":
String attribute = context.attribute().STRING().getText();
attribute = attribute.substring(1,attribute.length()-1);
startDelimiter = System.lineSeparator() + "> ";
endDelimiter = System.lineSeparator() + "> " + System.lineSeparator() + "> – " + attribute + System.lineSeparator();
break;
}
text += startDelimiter;
for (MarkupParser.ElementContext node: context.element())
{
if(node.tag() != null)
text += visitTag(node.tag());
if(node.content() != null)
text += visitContent(node.content());
}
text += endDelimiter;
return text;
}
|
VisitTag比其他方法包含更多的代码,因为它还可以包含其他元素,包括必须自己管理的其他标签,因此不能简单地打印它们。我们将ID的内容保存在第5行,当然,我们不需要检查相应的结束标记是否匹配,因为只要输入格式正确,解析器就会确保该匹配。
第一种复杂性始于第14-15行:正如在另一种语言中进行语言转换时经常发生的那样,两者之间没有完美的对应关系。虽然BBCode试图成为HTML的更智能,更安全的替代品,但Markdown希望实现HTML的相同目标,以创建结构化文档。因此,BBCode具有下划线标签,而Markdown没有。
所以我们必须做一个决定
我们要放弃信息,还是直接打印HTML或其他内容?我们选择其他内容,而是将下划线转换为斜体。这似乎完全是武断的,并且此决定中确实存在选择的要素。但是这种转换迫使我们丢失了一些信息,并且两者都用于强调,因此我们选择了新语言中的更接近的事物。
第18-22行的以下情况迫使我们做出另一种选择。我们无法以结构化的方式维护有关报价作者的信息,因此我们选择以对人类读者有意义的方式来打印信息。
在第28-34行,我们做了“魔术”:访问孩子并收集他们的文本,然后使用endDelimiter结束。最后,我们返回创建的文本。
那就是访客的工作方式
- 每个主要元素拜访每个孩子
- 如果是内容节点,则直接返回文本
- 如果是tag,它将设置正确的定界符,然后检查其子级。对每个孩子重复步骤2,然后返回收集的文本
- 它打印返回的文本
显然,这是一个简单的示例,但它显示了启动访问者后如何在管理访问者方面拥有极大的自由。再加上我们在本节开头看到的模式,您可以看到所有选项:返回null以停止访问,返回子项以继续,返回某些内容以执行较高级别的操作树。
27.高级测试
词汇模式的使用允许处理孤岛语言的解析,但使测试复杂化。
我们不会显示,MarkupErrorListener.java因为我们不会更改它。如果需要,可以在存储库中看到它。
您可以使用以下命令运行测试。
|
1
|
mvn test
|
现在我们来看一下测试代码。我们跳过了设置部分,因为这很明显,我们只复制了在主文件上看到的过程,但是我们只是添加了错误侦听器以拦截错误。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
// private variables inside the class AppTest
private MarkupErrorListener errorListener;
private MarkupLexer markupLexer;
public void testText()
{
MarkupParser parser = setup("anything in here");
MarkupParser.ContentContext context = parser.content();
assertEquals("",this.errorListener.getSymbol());
}
public void testInvalidText()
{
MarkupParser parser = setup("[anything in here");
MarkupParser.ContentContext context = parser.content();
assertEquals("[",this.errorListener.getSymbol());
}
public void testWrongMode()
{
MarkupParser parser = setup("author=\"john\"");
MarkupParser.AttributeContext context = parser.attribute();
TokenStream ts = parser.getTokenStream();
assertEquals(MarkupLexer.DEFAULT_MODE, markupLexer._mode);
assertEquals(MarkupLexer.TEXT,ts.get(0).getType());
assertEquals("author=\"john\"",this.errorListener.getSymbol());
}
public void testAttribute()
{
MarkupParser parser = setup("author=\"john\"");
// we have to manually push the correct mode
this.markupLexer.pushMode(MarkupLexer.BBCODE);
MarkupParser.AttributeContext context = parser.attribute();
TokenStream ts = parser.getTokenStream();
assertEquals(MarkupLexer.ID,ts.get(0).getType());
assertEquals(MarkupLexer.EQUALS,ts.get(1).getType());
assertEquals(MarkupLexer.STRING,ts.get(2).getType());
assertEquals("",this.errorListener.getSymbol());
}
public void testInvalidAttribute()
{
MarkupParser parser = setup("author=/\"john\"");
// we have to manually push the correct mode
this.markupLexer.pushMode(MarkupLexer.BBCODE);
MarkupParser.AttributeContext context = parser.attribute();
assertEquals("/",this.errorListener.getSymbol());
}
|
前两种方法与以前完全相同,我们只是检查是否没有错误,或者是否存在正确的方法,因为输入本身是错误的。在第30-32行,事情开始变得有趣:问题在于,通过逐一测试规则,我们没有机会让解析器自动切换到正确的模式。因此它始终保留在DEFAULT_MODE上,在我们的例子中,这使一切看起来都像TEXT。显然,这使得无法正确解析属性。
同样的行还显示了如何检查当前的模式以及解析器找到的令牌的确切类型,我们使用它们来确认在这种情况下确实所有错误。
尽管我们可以使用文本字符串来触发正确的模式,但是每次都会使测试与几段代码交织在一起,这是不行的。因此,在第39行可以看到解决方案:我们手动触发正确的模式。完成此操作后,您可以看到我们的属性已正确识别。
28.处理表情
到目前为止,我们已经编写了简单的解析器规则,现在我们将看到分析一种真实(编程)语言中最具挑战性的部分之一:表达式。尽管语句的规则通常较大,但它们的处理却非常简单:您只需要编写一条规则,将所有不同的可选部分封装在结构中即可。例如,一条for语句可以包含所有其他类型的语句,但是我们可以简单地将它们包含在诸如statement*. “表达式”之类的内容中,而是可以以许多不同的方式进行组合。
一个表达式通常包含其他表达式。例如,典型的二进制表达式由左边的表达式,中间的运算符和右边的另一个表达式组成。这可能导致歧义。例如,5 + 3 * 2对于ANTLR,请考虑该表达式是模棱两可的,因为有两种解析它的方法。它可以将其解析为5 +(3 * 2)或(5 +3)* 2。
到目前为止,我们仅通过标记构造围绕应用了它们的对象就避免了该问题。因此,选择最先应用哪个没有歧义:这是最外部的。想象一下,如果该表达式写成:
|
1
2
3
4
5
6
7
|
<add><font>
<int>5
<mul><font>
<int>3
<int>2
|
这对于ANTLR如何解析它很明显。
这些类型的规则称为左递归规则。您可能会说:只需解析首先出现的内容。这样做的问题是语义:首先是加法,但是我们知道乘法的优先级高于加法。传统上,解决此问题的方法是创建特定表达式的复杂级联,如下所示:
|
1
2
3
4
|
expression : addition;</font>
addition : multiplication ('+' multiplication)* ;</font>
multiplication : atom ('*' atom)* ;</font>
atom : NUMBER ;
|
这样,ANTLR就会知道先搜索一个数字,然后搜索乘法,最后搜索加法。这很麻烦,而且违反直觉,因为最后一个表达式是第一个被实际识别的表达式。幸运的是,ANTLR4可以自动创建类似的结构,因此我们可以使用更自然的语法。
|
1
2
3
4
|
expression : expression '*' expression</font>
| expression '+' expression </font>
| NUMBER</font>
;
|
在实践中,ANTLR考虑我们定义备选方案以决定优先级的顺序。通过以这种方式编写规则,我们告诉ANTLR乘法优先于加法。
29.解析电子表格
现在,我们准备使用C#创建最后一个应用程序。我们将构建类似Excel的应用程序的解析器。实际上,我们要管理您在电子表格的单元格中编写的表达式。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
grammar Spreadsheet;</font>
</font>
expression : '(' expression ')' #parenthesisExp
| expression (ASTERISK|SLASH) expression #mulDivExp
| expression (PLUS|MINUS) expression #addSubExp
| '^' expression #powerExp
| NAME '(' expression ')' #functionExp
| NUMBER #numericAtomExp
| ID #idAtomExp
;</font>
</font>
fragment LETTER : [a-zA-Z] ;</font>
fragment DIGIT : [0-9] ;</font>
</font>
ASTERISK : '*' ;</font>
SLASH : '/' ;</font>
PLUS : '+' ;</font>
MINUS : '-' ;</font>
</font>
ID : LETTER DIGIT ;</font>
</font>
NAME : LETTER+ ;</font>
</font>
NUMBER : DIGIT+ ('.' DIGIT+)? ;</font>
</font>
WHITESPACE : ' ' -> skip;
|
到目前为止,您已经掌握了所有知识,但可能要清除的一切,除了可能的三件事:
- 为什么括号在那里,
- 右边的东西是什么
- 第6行上的那个东西。
括号首先出现是因为它的唯一作用是在需要时给用户一种覆盖运算符优先级的方法。AST的这种图形表示应使其清晰。

右边的东西是标签,它们用于使ANTLR为访问者或侦听器生成特定功能。因此,将会有一个VisitFunctionExp,一个VisitPowerExp等等。这使得避免将巨型访客用作表达式规则成为可能。
与求幂相关的表达式是不同的,因为当遇到两个相同类型的顺序表达式时,有两种可能的操作方式将它们分组。第一个是先执行左边的一个,然后是右边的一个,第二个是相反的:这称为关联性。通常,您要使用的是左关联性, 这是默认选项。但是,幂运算是右相关的,因此我们必须将此信号通知给ANTLR。
另一种看待这种情况的方式是:如果有两个相同类型的表达式,那么哪个优先级高:左一个还是右一个?同样,一张图像值一千个字。
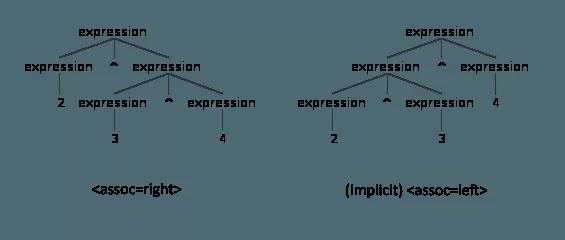
我们还支持函数,代表单元格的字母数字变量和实数。
30. C#中的电子表格项目
您只需要按照C#Setup进行操作即可:为运行时安装nuget软件包,为Visual Studio安装ANTLR4扩展。该扩展将在您构建项目时自动生成所有内容:解析器,侦听器和/或访问者。
完成此操作后,您也可以仅使用常规菜单“添加”->“新建项目”来添加语法文件。恰好执行此操作以创建一个称为的语法Spreadsheet.g4,并将其放入我们刚刚创建的语法中。现在让我们来看一下main Program.cs。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
using System;
using Antlr4.Runtime;
namespace AntlrTutorial
{
class Program
{
static void Main(string[] args)
{
string input = "log(10 + A1 * 35 + (5.4 - 7.4))";
AntlrInputStream inputStream = new AntlrInputStream(input);
SpreadsheetLexer spreadsheetLexer = new SpreadsheetLexer(inputStream);
CommonTokenStream commonTokenStream = new CommonTokenStream(spreadsheetLexer);
SpreadsheetParser spreadsheetParser = new SpreadsheetParser(commonTokenStream);
SpreadsheetParser.ExpressionContext expressionContext = spreadsheetParser.expression();
SpreadsheetVisitor visitor = new SpreadsheetVisitor();
Console.WriteLine(visitor.Visit(expressionContext));
}
}
}
|
除此以外,无话可说,您当然必须注意事物命名的另一种细微变化:注意大小写。例如,AntlrInputStream在C#程序中,是ANTLRInputStream在Java程序中。
您还可以注意到,这次,我们在屏幕上输出访问者的结果,而不是将结果写入文件中。
31. Excel注定了
我们将看看Spreadsheet项目的访客。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
public class SpreadsheetVisitor : SpreadsheetBaseVisitor<double>
{
private static DataRepository data = new DataRepository();
public override double VisitNumericAtomExp(SpreadsheetParser.NumericAtomExpContext context)
{
return double.Parse(context.NUMBER().GetText(), System.Globalization.CultureInfo.InvariantCulture);
}
public override double VisitIdAtomExp(SpreadsheetParser.IdAtomExpContext context)
{
String id = context.ID().GetText();
return data[id];
}
public override double VisitParenthesisExp(SpreadsheetParser.ParenthesisExpContext context)
{
return Visit(context.expression());
}
public override double VisitMulDivExp(SpreadsheetParser.MulDivExpContext context)
{
double left = Visit(context.expression(0));
double right = Visit(context.expression(1));
double result = 0;
if (context.ASTERISK() != null)
result = left * right;
if (context.SLASH() != null)
result = left / right;
return result;
}
[..]
public override double VisitFunctionExp(SpreadsheetParser.FunctionExpContext context)
{
String name = context.NAME().GetText();
double result = 0;
switch(name)
{
case "sqrt":
result = Math.Sqrt(Visit(context.expression()));
break;
case "log":
result = Math.Log10(Visit(context.expression()));
break;
}
return result;
}
}
|
VisitNumeric并VisitIdAtom返回由数字或变量表示的实际数字。在实际情况下,DataRepository将包含用于访问适当单元格中数据的方法,但在我们的示例中只是一个带有一些键和数字的字典。其他方法实际上以相同的方式工作:它们访问/调用包含的表达式。唯一的区别是他们如何处理结果。
一些对结果执行一个运算,二进制运算以正确的方式组合两个结果,最后VisitParenthesisExp只在链上报告更高的结果。当计算机完成数学运算时,它很简单。
32.测试一切
到目前为止,我们仅测试了解析器规则,也就是说,仅当我们创建了正确的规则来解析输入时才进行测试。现在,我们还将测试访问者功能。这是理想的机会,因为我们的访客返回了可以单独检查的值。在其他情况下,例如,如果您的访问者在屏幕上打印了一些内容,则可能需要重写访问者以在流上进行写入。然后,在测试时,您可以轻松捕获输出。
我们将不显示SpreadsheetErrorListener.cs它,因为它与我们已经看到的上一个相同;如果需要,可以在存储库中看到它。
要在Visual Studio上执行单元测试,您需要在解决方案内部创建一个特定项目。您可以选择不同的格式,我们选择xUnit版本。要运行它们,在菜单栏上有一个恰当命名的“ TEST”部分。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
[Fact]
public void testExpressionPow()
{
setup("5^3^2");
PowerExpContext context = parser.expression() as PowerExpContext;
CommonTokenStream ts = (CommonTokenStream)parser.InputStream;
Assert.Equal(SpreadsheetLexer.NUMBER, ts.Get(0).Type);
Assert.Equal(SpreadsheetLexer.T__2, ts.Get(1).Type);
Assert.Equal(SpreadsheetLexer.NUMBER, ts.Get(2).Type);
Assert.Equal(SpreadsheetLexer.T__2, ts.Get(3).Type);
Assert.Equal(SpreadsheetLexer.NUMBER, ts.Get(4).Type);
}
[Fact]
public void testVisitPowerExp()
{
setup("4^3^2");
PowerExpContext context = parser.expression() as PowerExpContext;
SpreadsheetVisitor visitor = new SpreadsheetVisitor();
double result = visitor.VisitPowerExp(context);
Assert.Equal(double.Parse("262144"), result);
}
[..]
[Fact]
public void testWrongVisitFunctionExp()
{
setup("logga(100)");
FunctionExpContext context = parser.expression() as FunctionExpContext;
SpreadsheetVisitor visitor = new SpreadsheetVisitor();
double result = visitor.VisitFunctionExp(context);
CommonTokenStream ts = (CommonTokenStream)parser.InputStream;
Assert.Equal(SpreadsheetLexer.NAME, ts.Get(0).Type);
Assert.Equal(null, errorListener.Symbol);
Assert.Equal(0, result);
}
[Fact]
public void testCompleteExp()
{
setup("log(5+6*7/8)");
ExpressionContext context = parser.expression();
SpreadsheetVisitor visitor = new SpreadsheetVisitor();
double result = visitor.Visit(context);
Assert.Equal("1.01072386539177", result.ToString(System.Globalization.CultureInfo.GetCultureInfo("en-US").NumberFormat));
}
|
第一个测试功能类似于我们已经看到的功能。它检查是否选择了正确的令牌。在第11和13行上,您可能会惊讶地看到这种奇怪的令牌类型,因为我们没有为'^'符号显式创建一个,所以自动为我们创建了一个。如果需要,可以通过查看ANTLR生成的* .tokens文件来查看所有令牌。
在第25行,我们访问测试节点并获得结果,然后在第27行进行检查。这非常简单,因为我们的访问者很简单,而单元测试应该总是很容易并且由小部分组成,但实际上并不容易比这个。
唯一需要注意的是与数字的格式有关,这在这里不是问题,但请看第59行,我们在其中测试整个表达式的结果。我们需要确保选择了正确的格式,因为不同的国家/地区使用不同的符号作为小数点。
有些事情取决于文化背景
如果您的计算机已经设置为“ 美国英语文化”,则没有必要,但是要保证为每个人提供正确的测试结果,我们必须指定它。如果您要测试与文化相关的事物,请记住这一点:例如,数字分组,温度等。
在第44-46行中,您看到的是,当我们检查错误的功能时,解析器实际上会工作。那是因为确实“ logga”作为函数名称在语法上是有效的,但在语义上却不正确。函数“ logga”不存在,因此我们的程序不知道该如何处理。因此,当我们访问它时,结果为0。您还记得这是我们的选择:因为我们将结果初始化为0,而default在in中VisitFunctionExp. 没有case,所以如果没有函数,结果仍为0。possib替代方案可能是引发异常。
结束语
在本节中,我们将看到示例中从未出现过的提示和技巧,但它们在您的程序中很有用。如果您想进一步了解ANTLR的实践和理论知识,或者需要处理最复杂的问题,我们建议您可能会发现更多有用的资源。
33.技巧和窍门
让我们看一些不时有用的技巧。在我们的示例中从来不需要这些,但是在其他情况下它们非常有用。
卡特尔规则
第一个是 ANY词法分析器规则。这只是以下格式的规则。
|
1
2
|
ANY : . ;
|
这是一条总括的规则,应该放在语法的末尾。它匹配在解析过程中找不到位置的任何字符。因此,创建此规则可以在开发过程中为您提供帮助,这时您的语法仍有很多漏洞,可能会导致分散错误消息。当它在矿山中充当金丝雀时,它甚至在生产过程中很有用。如果它出现在您的程序中,您就知道有问题。
频道
我们还没有谈论过一些东西:channels。他们的用例通常是处理注释。您实际上并不想检查每个语句或表达式中的注释,因此通常使用将它们扔掉-> skip。但是在某些情况下,您可能希望保留它们,例如,如果您正在翻译另一种语言的程序。发生这种情况时,请使用渠道。您已经可以使用一种叫做HIDDEN的东西,但是您可以在词法分析器语法的顶部声明更多的东西。
|
1
2
3
|
channels { UNIQUENAME }</font>
// and you use them this way</font>
COMMENTS : '//' ~[\r\n]+ -> channel(UNIQUENAME) ;
|
规则元素标签
除了区分同一规则的不同情况外,还有其他用途。它们可用于为通常的规则或规则的一部分赋予一个特定名称,通常但并非总是具有语义价值。格式为label=rule,可在其他规则中使用。
|
1
|
expression : left=expression (ASTERISK|SLASH) right=expression ;
|
这样,左和右将成为在田里ExpressionContext节点。而且context.expression(0),可以使用而不是使用来引用同一实体context.left。
有问题的代币
在许多实际语言中,某些符号以不同的方式重复使用,其中某些可能导致歧义。一个常见的有问题的例子是尖括号,它既用于位移表示又用于定界参数化类型。
|
1
2
3
4
|
// bitshift expression, it assigns to x the value of y shifted by three bits</font>
x = y >> 3;</font>
// parameterized types, it define x as a list of dictionaries</font>
List
|
定义位移位运算符标记的自然方法是使用单个双尖括号“ >>”。但这可能会使嵌套的参数化定义与bitshift运算符混淆,例如,在此处显示的第二个示例中。解决问题的一种简单方法是使用语义谓词,但是过多的语义谓词会减慢解析阶段。解决方案是避免定义位移位运算符,而在解析器规则中两次使用尖括号,以便解析器本身可以为每种情况选择最佳候选者。
|
1
2
3
4
5
|
// from this</font>
RIGHT_SHIFT : '>>';</font>
expression : ID RIGHT_SHIFT NUMBER;</font>
// to this</font>
expression : ID SHIFT SHIFT NUMBER;
|
34.结论
今天我们学到了很多:
- 什么是词法分析器和解析器
- 如何创建词法分析器和解析器规则
- 如何使用ANTLR以Java,C#,Python和JavaScript生成解析器
- 您将遇到的基本问题类型以及如何解决
- 如何理解错误
- 如何测试解析器
这就是您自己使用ANTLR所需要知道的一切。我的意思是说,您可能想了解更多,但是现在您有了自己的基础来探索。
如果需要有关ANTLR的更多信息,可以在哪里查看:
- 在这个网站上,有专门用于ANTLR的整个类别。
- 该官方网站ANTLR 是一个很好的起点,以了解该项目的总体状况,专业的开发工具和相关的项目,如StringTemplate的
- GitHub上的ANTLR文档;特别有用的是有关目标的信息 以及如何使用不同的语言进行设置。
- 所述ANTLR 4.6 API ; 它与Java版本有关,因此在其他语言中可能会有一些差异,但这是解决对该工具的内部工作方式的怀疑的最佳位置。
- 对于对ANTLR4背后的科学非常感兴趣的人,有一篇学术论文: 自适应LL(*)解析:动态分析的力量
- 权威的ANTLR 4参考,由人本身,ANTLR的创建者 Terence Parr撰写。如果您想了解有关ANTLR的所有知识以及有关语法分析的大量知识,则需要此资源。
本书也是在这里只能找到并回答以下问题的地方:
ANTLR v4是我在研究生
院修读的一个小弯路(二十五年)的结果。我想我将不得不稍微改变我的座右铭。为什么要用五天的时间手工编程,您将可以花25年的
时间实现自动化?
我们非常努力地在ANTLR上构建了最大的教程:大型教程!帖子长度超过13.000字,或超过30页,以尝试回答有关ANTLR的所有问题。遗漏了什么?联系我们,让我们现在,我们在这里为您提供帮助
翻译自: https://www.javacodegeeks.com/2017/03/antlr-mega-tutorial.html