车险往年保单关联计算的性能优化
问题的提出
保险行业中,往往需要根据往年保单来快速计算和生成当年新的保单。以车险为例,在提醒老客户续保时就需要计算指定时间段的往年保单,例如某省级公司需要定期计算特定月份内可续保保单对应的历史保单。而目前在大多数保险营运系统中,这类批量数据处理任务都是由存储过程实现的,其中存在的典型问题就是存储过程性能差,运行时间长。如果只是计算一天的历史保单,运行时间尚可接受;如果时间跨度较大,运行时间就会长的无法忍受,基本就变成不可能完成的任务了。
解决思路与过程
案例场景说明
下面我们将针对这种基于历史保单信息的计算任务的性能优化。实际业务中遇到的真实的存储过程很长,有2000多行。我们这里对问题进行了简化,只分析主体的部分,进而讨论集算器SPL语言优化类似计算的方法和思路。
这个场景中计算用到的数据表包括:保单表和保单-车辆明细表。对于较大的省份,保单表和保单-车辆明细表都有几千万数据存量,每天新增保单的增量数据有一到两万条。
经过简化的两个表结构如下:
保单表
policyid char(22) not null ,-- 保单编码(主键)
policyno char(22),-- 保单号
startdate datetime year to second,-- 开始日期
enddate datetime year to second-- 结束日期
保单 - 车辆明细表
policyid char(22) not null , -- 保单编码(主键)
itemid decimal(8,0) not null ,-- 明细编码(主键)
licensenoid varchar(20),-- 牌照编码
licensetype char(3),-- 牌照种类
vinid varchar(18),--vin 编码
frameid varchar(30),-- 车架编码
新旧保单的对照表:
policyid char(22) not null , -- 保单编码
oldpolicyid char(22)—上年保单编码
往年保单的计算输入参数是起始日期(istart)和结束日期(iend),计算目标是新旧保单的对照表,找不到旧保单的将被舍弃。
计算过程简化描述如下:
1、 从保单表中,找出开始日期在指定时间段(istart和iend之间)内的新增保单。
2、 用新增保单关联上一年的历史保单。关联的条件是:vin编码相同;或者车架编码相同;或者牌照种类、牌照编码同时相同。同时,要去掉旧的保险单号为null或者空字符串的数据,去掉新旧保险单相同的数据。
3、 在所有旧保险单中找到和新保单结束日期在90天之内的,就是上年保单。
优化思路
1、 理解业务,采用更好的算法,而不是照搬存储过程。
存储过程如果遇到了很难优化的性能问题,根本原因可能是采用的计算方法出了问题。这往往是因为SQL原理和模型造成的,要靠新的工具通过支持更好的计算方法来解决。如果用SPL简单翻译存储过程的语句,计算方法没有改变,性能也很难提升。
推荐的做法是通过存储过程理解业务的需求,然后从原理层面思考更快的算法,在工具层面采用集算器SPL提供的更优化的算法重新实现。
乾学院提供了很多性能优化的案例,可以帮助SPL程序员快速找到更好的计算方法。
2、 数据外置,利用集算器获得更好性能。
集算器提供了私有数据文件格式,具备压缩、列存、有序等有利于性能的特点。因此可以将数据库中的数据预先缓存到集算器数据文件中,利用数据外置优化整体性能。
3、 针对对关联计算,区别分类加以优化。
和SQL的关联计算不同,集算器中能够对不同类型的join采用不同的算法,包括主键相同的同维表、外键表、主子表、大表关联小表等等细分情况。而如果出现了两个大表cross join的情况,则有必要重新分析业务需求。
数据准备
1、 从数据库中导出保单表和保单车辆明细表。按照policyid排序之后,存放到组表文件POLICY.ctx和POLICY_CAR.ctx中。这里的排序很重要,是后续实现有序归并的前提条件。因为数据库JDBC性能较差,所以第一次导出全部历史数据的时候速度会比较慢。但是以后每天导出新增数据,增量更新组表文件就很快了。
2、 针对POLICY.ctx的enddate字段新建索引index_enddate。
3、 数据准备的具体代码可以参考教程的组表部分。
解决办法和过程
经过分析、测试发现,原存储过程性能优化的关键在于四个关联计算。首先是新增保单和保单-车辆明细表通过policyid关联来获得车辆信息,之后再与保单-车辆明细表分别通过vinid、frameid、licenseid以及licensetype关联三次,来获取历史保单。一天的新增保单有1万多条,这四次关联的时间尚可忍受。而一个月的新增保单有四十多万条,这四次关联的时间就会达到1到2个小时。
对此,我们优化这个存储过程的思路就是利用SPL的计算能力,在对两个主表一次遍历的过程中,完成上述四个关联计算。这样,无论是一天还是一个月的新增保单,计算时间都不会明显延长。
具体的SPL代码分为两大部分:
一、过滤出指定时间段(istart和iend之间)的新增保单数据。
一天的新增保单1到2万条,三十天的新增保单30到60万条,这个量级的数据可以直接存放在内存中。具体代码如下:
| A |
B |
C |
|
| 1 |
=file("data/ctx/POLICY.ctx") |
=A1.create() |
|
| 2 |
=B1.icursor(policyid,startdate,enddate;enddate>=istart && enddate<=iend,index_enddate) |
||
| 3 |
=A2.fetch() |
||
| 4 |
=file("data/ctx/POLICY_CAR.ctx") |
=A4.create() |
|
| 5 |
=A3.(policyid) |
=B4.find@k(A5) |
|
| 6 |
=join@m(B5:t3,policyid;A3:t1,policyid) |
||
| 7 |
=A6.new(t1.policyid:policyid ,t1.startdate:startdate ,t1.enddate:enddate ,ifn(t3.licenseid,""): licenseid,ifn(t3.frameid,""): frameid,ifn(t3.vinid,""):vinid,t3.licensetype:licensetype,t3.licenseid/"|"/t3.licensetype:newlicense) |
||
A1、B1:打开组表文件“保单表”。
A2、A3:从保单表中过滤出指定时间段(istart和iend之间)的新增保单,过滤时使用了预先生成的索引index_enddate。
A4、B4:打开组表文件“保单车辆明细表”。
A5、B5:用新增保单号,关联保单车辆表,找出车辆信息。
A6、A7:关联新增保单信息和车辆信息,生成新增保单和车辆信息表。
二、对历史保单完成三种方式的关联计算,得到新旧保单对照表。
| A |
B |
C |
|
| 8 |
=A1.create().curso r(policyid,policyno, startdate,enddate) |
=A4.create().cursor(policyid,licenseid,licensetype,vini d,frameid) |
|
| 9 |
=joinx(A8:t1,policyid;B8:t2,policyid) |
||
| 10 |
for A9,100000 |
=A10.new(t1.policyid:policyid,t1.policyno:policyno,t1. enddate:enddate,t1.startdate:startdate,t2.vinid:vinid, t2.frameid:frameid,t2.licenseid:licenseid,t2.licensetyp e:licensetype,t2.licenseid/"|"/t2.licensetype:newlicen se) |
|
| 11 |
=join(A7:new,vinid;B10:old,vinid) |
=join(A7:new,frameid; B10:old,frameid) |
|
| 12 |
=join(A7:new,newlicense;B10:old,newlicense) |
=[B11,B12,C11].conj() |
|
| 13 |
=C12.select(new.policyid!=old.policyid && old.policyno!=null && len(trim(old.policyno))>0) |
=B13.new( new.policy id:policyid,new.startd ate:startdate,new.end date:enddate,old.poli cyid:oldpolicyid,old.e nddate:oldenddate) |
|
| 14 |
=@|C13 |
||
| 15 |
=B14.select(enddate>oldenddate && interval@d(oldenddate,startdate)<=90) |
||
| 16 |
=A15.groups(policyid,oldpolicyid) |
||
| 17 |
=file("data/ctx/PO LICY_OLD.btx") |
=A17.export@z(A16) |
|
A8、B8:打开两个组表文件,保单表和保单车辆明细表,用需要的字段建立游标。
A9:用policyid关联两个游标。如前所述,两个表都已经按照policyid排序了,所以这里的joinx是采用有序归并的方式,两个表都只需要遍历一次,复杂度较低。而SQL的HASH计算性能则只能靠运气了。关于有序归并的介绍参见【数据蒋堂】第 35 期:JOIN 提速 – 有序归并。
A10:循环取出两个组表文件关联的结果,每次取出10万条形成序表。
B10:关联结果生成新序表。其中,牌照和牌照种类用“|”合并成一个字段。
B11、C11、B12分别按照三种方式做内连接,计算历史保单。
C12:纵向合并三个内连接的结果。
B13、C13:找出新保单id不等于旧保单id并且旧保单号不为空的数据,生成新序表。
B14:结果合并到B14中。
A15:过滤出结束日期大于旧保单结束日期,“旧保单结束日期”和“新保单开始日期”的间隔不超过90天的数据。
A16、17、B17:对新保单、旧保单去掉重复,存入结果文件。
性能优化效果
在实际项目中,存储过程和集算器对比测试数据如下:
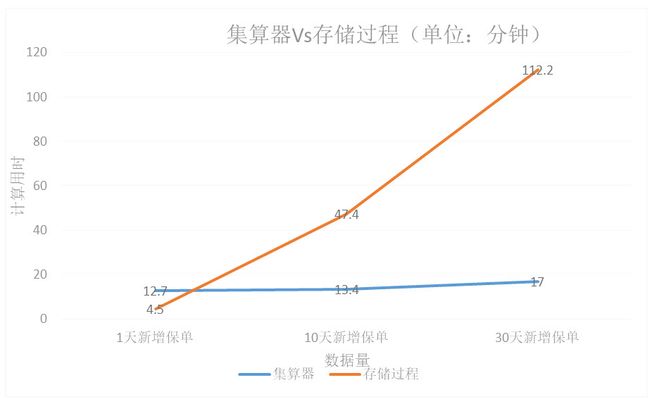
从结果可以看出,同样的条件下:
1、新增保单数据量越大,集算器性能提升越明显。30天新增保单计算时,性能提升6.6倍。
2、存储过程计算时间随着数据量线性增加。集算器计算时间并不会随着数据量线性增加。
3、数据量较小的时候,集算器和存储过程的计算性能都在可接受范围内;数据量较大时,存储过程需要计算几个小时,集算器的计算时间仍在十几分钟。
4、在这次测试中,没有对保单表和保单车辆明细表建索引,计算过程中集算器需要对两个表做遍历查找。因此,数据量较小时,集算器也需要一个基本的遍历计算时间。而数据库建有索引,在小数据量时会有优势。如果集算器也建有索引,这个场景也可以再优化。但由于目前的指标已经可以达到实用,而用户方更关心的是大数据量场景,所以没有再做进一步的优化测试。
优势总结
采用压缩列存
集算器采用压缩列存的方式保存数据。保险单表有70个字段,参与计算的只有十几个字段;保险单明细表有56个字段,参与计算字段不到十个。因此,采用列存方式对性能的提高效果较好。
保险单表和保险单明细表存成集算器组表文件,压缩后只有3G多,也可以有效提高计算速度。
数据有序存放
集算器数据文件中的数据按照保险单号有序存放。保险单表和保险单明细表按照保险单号关联的时候,可以有序分段关联,速度提升明显。
计算中间结果也是有序的,无需再重新建索引,有效节约了原来存储过程中建索引的时间。
采用更快的计算方法
用新保单去找上年、上上年和上三年的保单,需要按照vin码、车架号或者牌照加牌照种类三种方式来判断是否同一辆车。
原存储过程是用新保单表去和保单表、保单明细表多次关联,计算的时间会随着新保单表的数据量而线性增长。
而在集算器中采取的方式是:保单表和保单明细表有序关联之后,循环分批取出(比如:每次取10万条)。在内存中,每一批数据都和新保单通过三种方式关联。循环结束,三种方式的关联也都完成了。这样就实现了大表遍历一遍,同时完成三种方式的关联计算。
对于存储过程来说,无法实现这种算法的根本原因是:1、无法有序关联两个大表;2、用临时表不能保证全内存计算。
提高开发效率
SPL语言代码更短,调试更简单,可以有效提高开发效率。
原存储过程的完整代码约1800多行,用SPL改写后,仅约500格SPL语句即可实现。
作者:terminator
链接:http://c.raqsoft.com.cn/article/1541400226267
来源:乾学院
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。