Netty篇:ByteBuf之内存池源码分析
Netty的内存池的实现有些复杂,使用了大量的位运算,晦涩难懂,不过万能的博客上好多大神已经介绍的非常详细,推荐四篇很详细很棒的源码分析的文章链接,本文根据自己的理解顺一下思路,内容主要也是出自以下四篇:
Netty内存池之PoolThreadCache详解
Netty内存池之PoolArena详解
Netty内存池之PoolSubpage详解
Netty内存池之PoolChunk原理详解
Netty的内存池整体上参照jemalloc实现,组成部分主要包括PoolArena、PoolChunkList、PoolChunk、PoolPage、PoolSubpage这5个层级,基本关系盗张图展示下:(图出自Netty内存池实现)
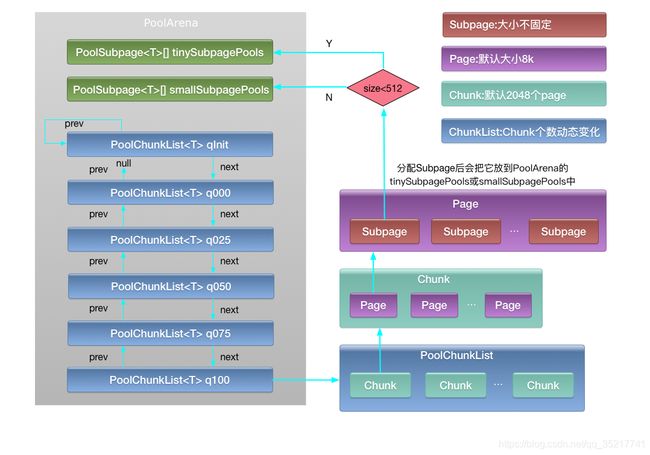
ByteBuf申请的入口在PooledByteBufAllocator,PooledByteBufAllocator创建的时候,会创建两个Arean(一个heap和一个direct)数组,这个数组里的arena会分配给每个线程(意思就是每个线程有两个arena)。
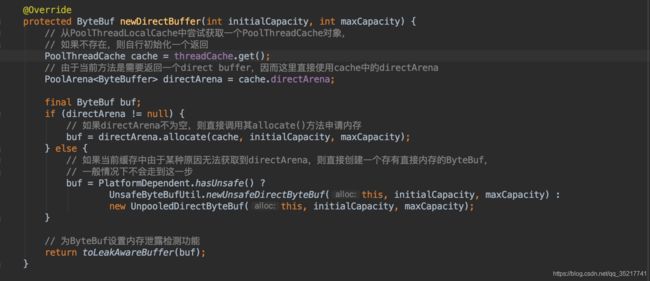
Netty会为每一个线程都维护一个PoolThreadCache对象,这个PoolThreadLocalCache,调用get的时候,会得到当前线程的PoolThreadCache,如果不存在则初始化一个,初始化时首先会查找PoolArena数组中被最少线程占用的那个arena,然后将其封装到一个新建的PoolThreadCache中返回,通过当前线程的这个PoolThreadCache 就能读取到directArena(直接内存),然后就在这个directArena这里开始分配内存了。但是最终的内存分配工作被委托给PoolArena。
当进行内存申请时,首先会尝试从PoolThreadCache中申请,如果无法从中申请到,则会尝试从Netty的公共内存池中申请。PoolThreadCache申请内存并不是说其会创建一块内存,或者说其会到PoolArena中申请内存,而是指,其本身已经缓存有内存块,而当前申请的内存块大小正好与其一致,就会将该内存块返回;PoolThreadCache中的内存块都是在当前线程使用完创建的ByteBuf对象后,通过调用其release()方法释放内存时直接缓存到当前PoolThreadCache中的,其并不会直接将内存块返回给PoolArena,PoolThreadCache会对其内存块使用次数进行计数,这么做的目的在于,如果一个ThreadPoolCache所缓存的内存块使用较少,那么就可以将其释放到PoolArena中,以便于其他线程可以申请使用。
PoolArena
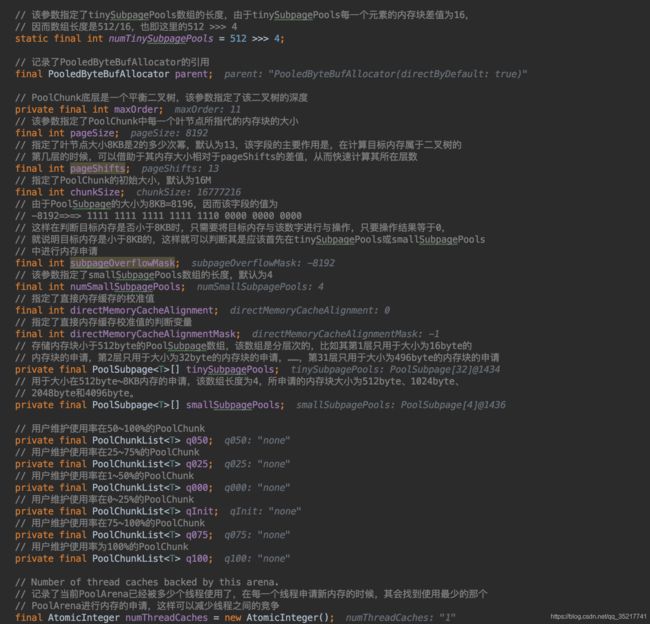
真是的内存分配工作会在PoolArena中进行,PoolArena中主要包含三部分子内存池:tinySubpagePools,smallSubpagePools和一系列按内存使用率划分的的PoolChunkList。初始状态时,tinySubpagePools是一个长度为32的数组,smallSubpagePools是一个长度为4的数组,PoolChunkList为空,几个PoolChunkList会串成一个单向链表,而PoolChunkList中的PoolChunk也是以单向链表存储,PoolChunk会根据内存占用率的不同而在几个PoolChunkList中依次传递。
内部参数如下:
内存分配部分代码如下:
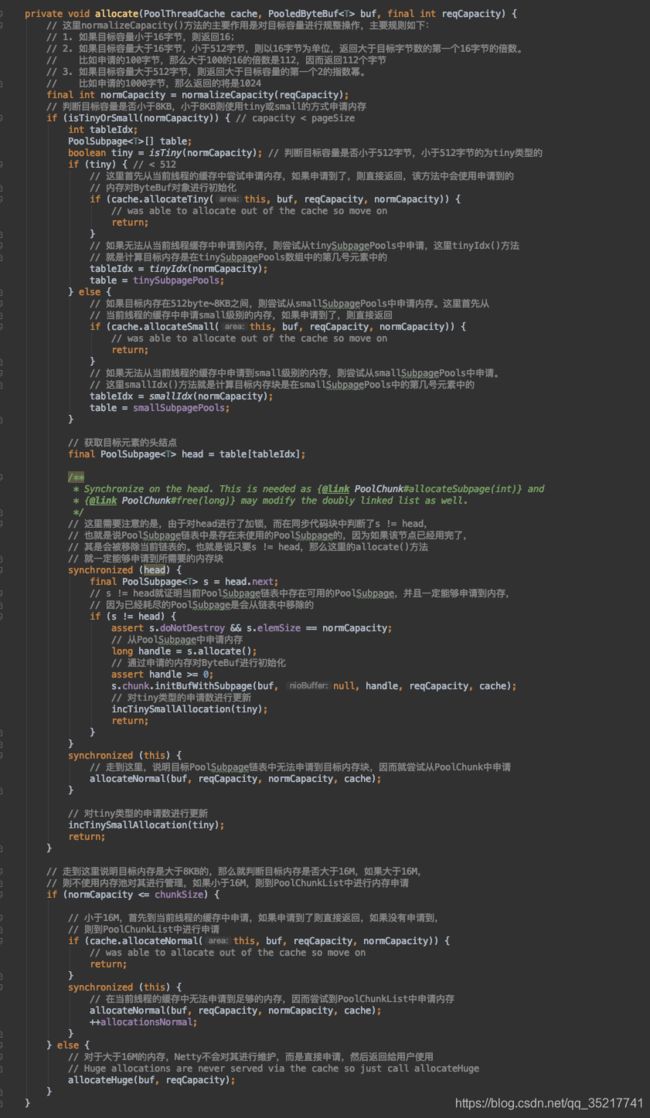
首先判断内存的大小,决定分配tiny,small还是normal内存。然后会尝试从当前线程的缓存PoolThreadCache中申请目标内存,如果能够申请到,则直接返回,如果不能申请到,则在当前层级中申请。对于tiny和small层级的内存申请,如果无法申请到,则会在PoolChunkList中申请,如果还没申请到,就创建一个PoolChunk申请,并执行PoolChunk#allocate方法申请,申请到之后还会判断PoolChunk的使用率决定它在哪个PoolChunkList中。
PoolChunk
一个Page的默认大小是8K,一个Chunk中默认包含了2048个Page,共16M,以2048个page为叶子节点,构成了一个一颗深度为11的满二叉树,共4095个节点,每个节点的代表的内存空间是其两个儿子节点代表内存空间的和,PoolChunk中维护了的memoryMap和depthMap两个数组,每个数组长度为4096,第一个位置存了0,后续4095个位置按层序顺遍历顺序存了所有节点的所在的层数,depthMap一样,每次数字代表了可分配的内存,比如0就是16M,11就是8k等。如果某个子节点被分配完了,那么该节点就会被标记为12(最大深度+1),表示已分配,同时递归更新其父节点,同步减少其父节点可供分配内存的值。PoolChunk只负责小于16M的内存分配,对于大于16M的内存分配不走池化。
PoolChunk对象属性如下:
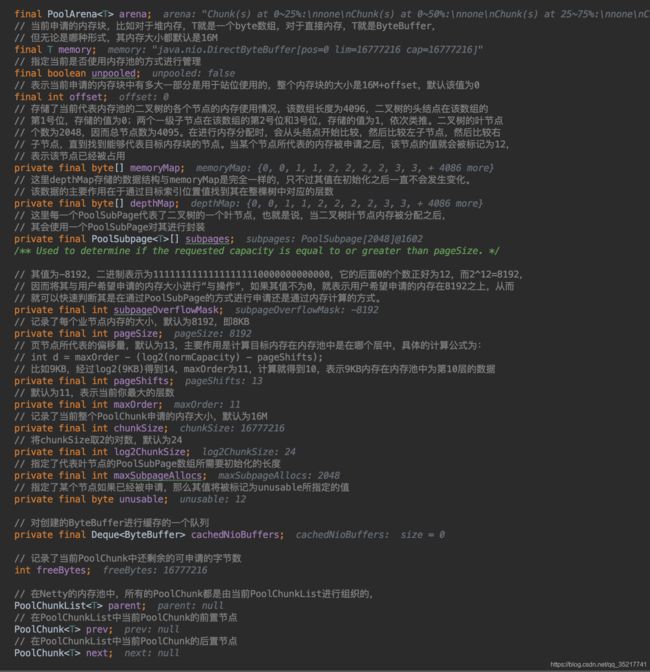
上述PoolArena如果申请不到内存会新建PoolChunk,新建并初始化PoolChunk会正式申请一块内存(此处通过PlatformDependent根据指定回收策略申请一块堆外内存),然后执行PoolChunk#allocate方法做memoryMap调整以及ByteBuffer初始化等工作。
PoolChunk#allocate中对目标容量做了判断,小于8KB的走allocateSubpage方法,大于8KB走allocateRun方法,两个方法会返回一个handle,里边存储的高32位是PoolSubpage内存块的位图索引(下文介绍),低32位是PoolChunk的内存占用索引(下文介绍),代码如下。
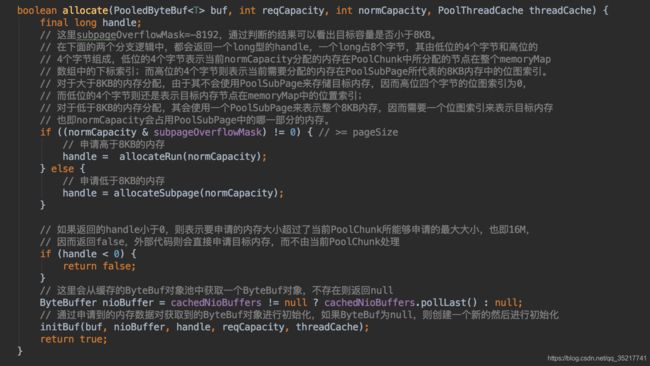
在allocateRun中调用了allocateNode方法,主要实现了上文中描述的对memoryMap的维护,因为不需要使用PoolSubpage,所以返回的handler中高32位为0,只把memoryMap返回即可。
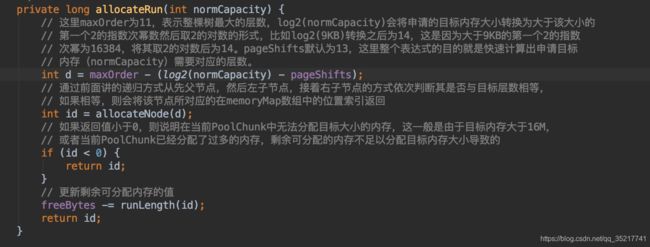
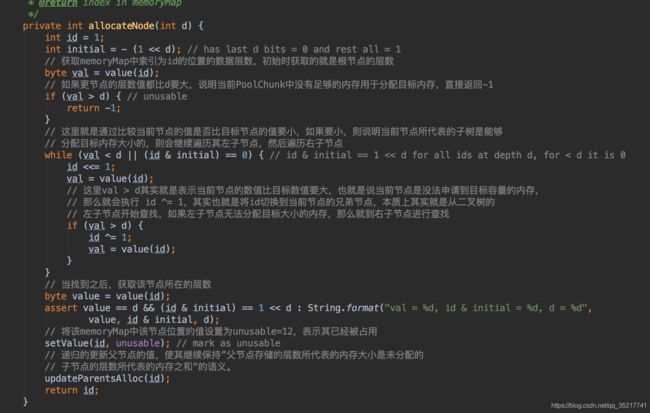
完成后上述操作后,将PoolChunk放入对应的PoolChunkList中,然后以申请到的内存数据为参数完成对应的ByteBuf的初始化操作,各种返回就得到了申请的池化的ByteBuf。
PoolSubpage
上文简单描述了大于8K的内存分配流程,小于8K的内存有PoolSubpage维护(虽说是小于8K,但当申请的内存大于4096B,netty就会将其扩容为8K分配normal内存),分配主要分为两种情况:小于512B的由tinySubpagePools的PoolSubpage的数组维护,tinySubpagePools数组大小为32,以数组加链表的形式存储,每个数组元素从小到大,均未16的倍数,代表其后面链表中的PoolSubpage的内存划分大小,比如按16B划分的内存块链到数组1号元素后边,32B划分的链到2后边,以此类推,最大为196;大于等于512B的则由smallSubpagePools的PoolSubpage数组来维护,结构与tinySubpagePools一样,数组只有四个元素,第一个512B,后边的每个都翻倍。
上文描述一个Page的大小为8K,PoolSubpage操作的节点是在叶子节点上划分内存块,所以PoolSubpage引入了bitmap来表示所划分的内存块是否被占用。由于内存划分最小为16B,8K内存最大可分为512个内存块,所以至少要512位来标记,Netty中使用了8个long组成的数组来表示内存块占用情况,一个long是64为,8个就是512位,即bitmap。但如果按其他内存大小划分,内存块个数要远小于512,所以用bitmapLength标识有几个long标记内存块。
PoolSubpage对象属性如下:

回到PoolChun#allocate方法,当申请的内存小于8K的时候,进入allocateSubpage方法。
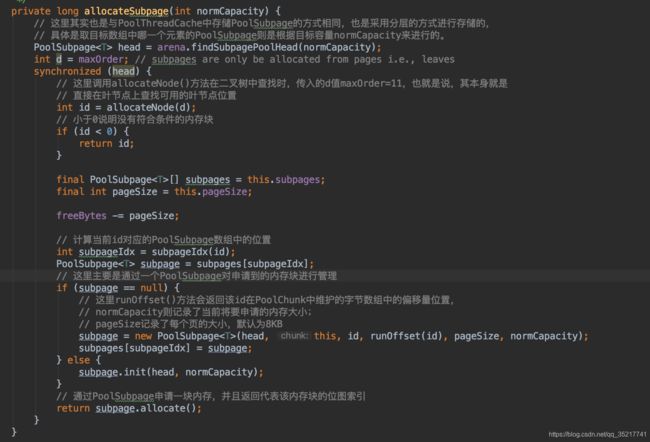
此时依旧会确定memoryMap中的位置以及标记占用,不过是直接在叶子节点中寻找。然后获取一个PoolSubpage对象,如果没有,就创建一个,对其对象进行初始化操作(初始化位图索引等的初始值,并将对象放入其对应链表中等操作),然后调用其allocate方法,获得其位图索引。
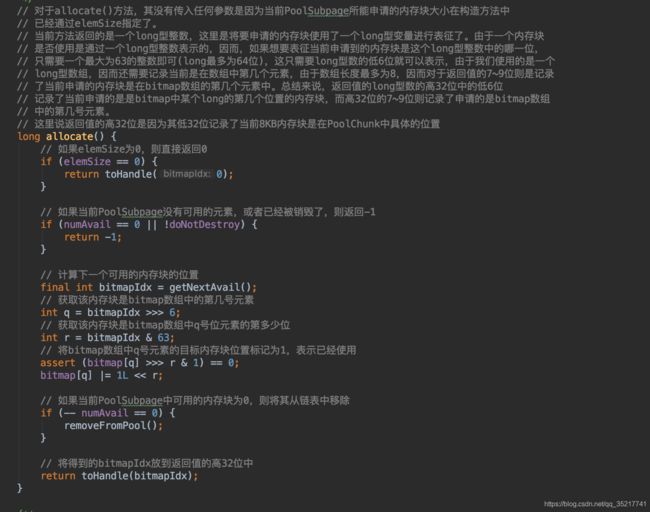
返回的handler中高32位表示bitmap索引,但并不是真正的bitmap,只是低六位记录了在long元素的第几位,7~9位记录了是数组中的几号long元素,然后将得到的int数据移到高32位,将memoryMap放到低32位,组成handler返回,然后就是后续的Bytebuf初始化操作。
内存回收
内存回收依旧是release方法,判断引用计数器是否需要回收内存,最终调用的是PooledByteBuf中实现的deallocate方法。
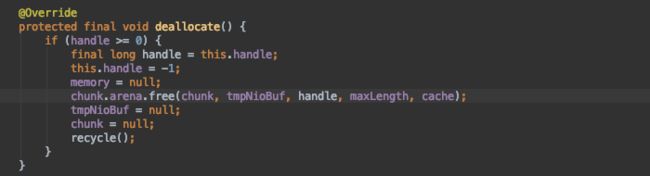
调用PoolArena#free方法
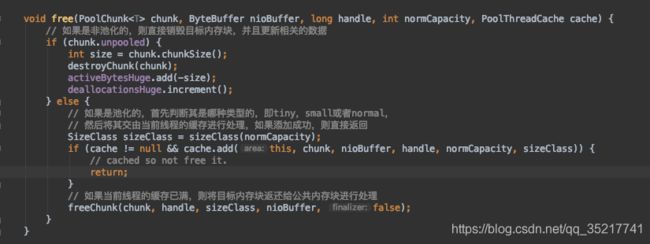
非池化直接销毁内存块,池化判断要回收的类型,尝试将其释放到PoolThreadCache中,上文申请内存的时候,尝试从缓存中获取内存即是此时回收的内存。
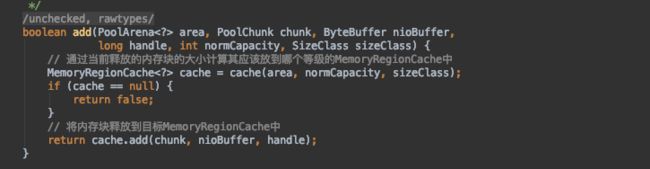
根据内存分配的类型获得对应的MemoryRegionCache,然后将内存块释放到里面。
如果线程缓存已满,则将目标内存返回到公共内存块中,最终会执行PoolChunk#free方法。
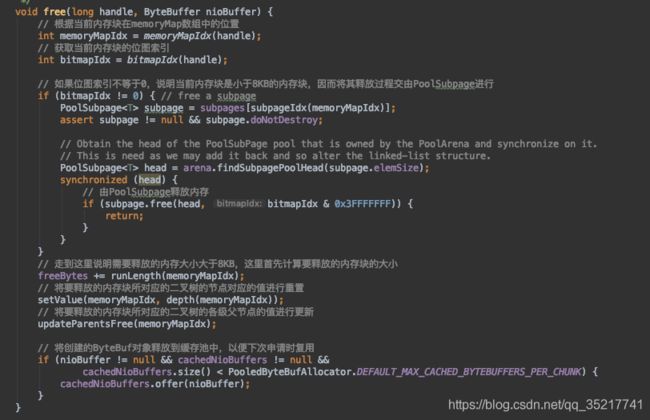
所做工作是重置位图索引,将ByteBuf放入缓存池,如果是PoolSubpage对象,则调用PoolSubpage#free,代码如下:
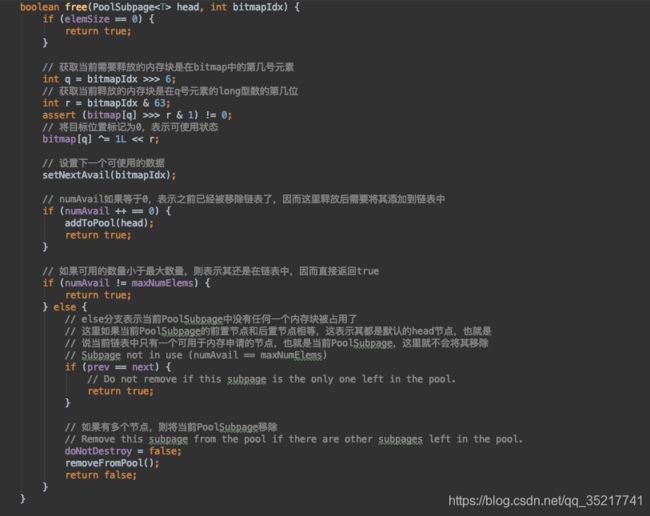
也是重置位图索引,调整链表的操作。
至此,一次池化的内存分配流程就有了简单地介绍。