小师妹学JavaIO之:NIO中那些奇怪的Buffer
文章目录
- 简介
- Buffer的分类
- Big Endian 和 Little Endian
- aligned内存对齐
- 总结
简介
妖魔鬼怪快快显形,今天F师兄帮助小师妹来斩妖除魔啦,什么BufferB,BufferL,BufferRB,BufferRL,BufferS,BufferU,BufferRS,BufferRU统统给你剖析个清清楚楚明明白白。
Buffer的分类
小师妹:F师兄不都说JDK源码是最好的java老师吗?为程不识源码,就称牛人也枉然。但是我最近在学习NIO的时候竟然发现有些Buffer类居然没有注释,就那么突兀的写在哪里,让人好生心烦。
更多内容请访问www.flydean.com
居然还有这样的事情?快带F师兄去看看。
小师妹:F师兄你看,以ShortBuffer为例,它的子类怎么后面都带一些奇奇怪怪的字符:
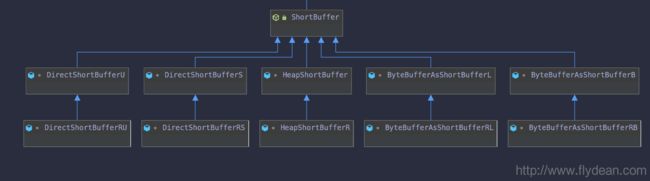
什么什么BufferB,BufferL,BufferRB,BufferRL,BufferS,BufferU,BufferRS,BufferRU都来了,点进去看他们的源码也没有说明这些类到底是做什么的。
还真有这种事情,给我一个小时,让我仔细研究研究。
一个小时后,小师妹,经过我一个小时的辛苦勘察,结果发现,确实没有官方文档介绍这几个类到底是什么含义,但是师兄我掐指一算,好像发现了这些类之间的小秘密,且听为兄娓娓道来。
之前的文章,我们讲到Buffer根据类型可以分为ShortBuffer,LongBuffer,DoubleBuffer等等。
但是根据本质和使用习惯,我们又可以分为三类,分别是:ByteBufferAsXXXBuffer,DirectXXXBuffer和HeapXXXBuffer。
ByteBufferAsXXXBuffer主要将ByteBuffer转换成为特定类型的Buffer,比如CharBuffer,IntBuffer等等。
而DirectXXXBuffer则是和虚拟内存映射打交道的Buffer。
最后HeapXXXBuffer是在堆空间上面创建的Buffer。
Big Endian 和 Little Endian
小师妹,F师兄,你刚刚讲的都不重要,我就想知道类后面的B,L,R,S,U是做什么的。
好吧,在给你讲解这些内容之前,师兄我给你讲一个故事。
话说在明末浙江才女吴绛雪写过一首诗:《春 景 诗》
莺啼岸柳弄春晴,
柳弄春晴夜月明。
明月夜晴春弄柳,
晴春弄柳岸啼莺。
小师妹,可有看出什么特异之处?最好是多读几遍,读出声来。
小师妹:哇,F师兄,这首诗从头到尾和从尾到头读起来是一样的呀,又对称又有意境!
不错,这就是中文的魅力啦,根据读的方式不同,得出的结果也不同,其实在计算机世界也存在这样的问题。
我们知道在java中底层的最小存储单元是Byte,一个Byte是8bits,用16进制表示就是Ox00-OxFF。
java中除了byte,boolean是占一个字节以外,好像其他的类型都会占用多个字节。
如果以int来举例,int占用4个字节,其范围是从Ox00000000-OxFFFFFFFF,假如我们有一个int=Ox12345678,存到内存地址里面就有这样两种方式。
第一种Big Endian将高位的字节存储在起始地址

第二种Little Endian将地位的字节存储在起始地址
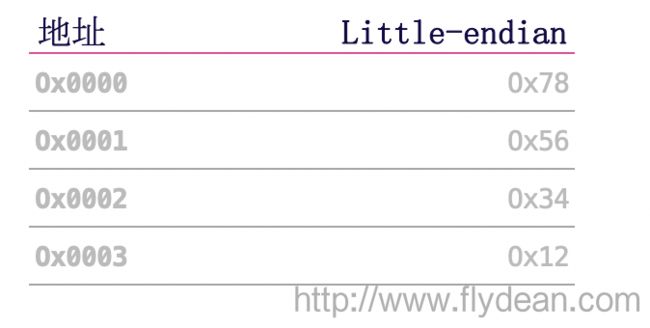
其实Big Endian更加符合人类的读写习惯,而Little Endian更加符合机器的读写习惯。
目前主流的两大CPU阵营中,PowerPC系列采用big endian方式存储数据,而x86系列则采用little endian方式存储数据。
如果不同的CPU架构直接进行通信,就由可能因为读取顺序的不同而产生问题。
java的设计初衷就是一次编写处处运行,所以自然也做了设计。
所以BufferB表示的是Big Endian的buffer,BufferL表示的是Little endian的Buffer。
而BufferRB,BufferRL表示的是两种只读Buffer。
aligned内存对齐
小师妹:F师兄,那这几个又是做什么用的呢? BufferS,BufferU,BufferRS,BufferRU。
在讲解这几个类之前,我们先要回顾一下JVM中对象的存储方式。
还记得我们是怎么使用JOL来分析JVM的信息的吗?代码非常非常简单:
log.info("{}", VM.current().details());
输出结果:
# Running 64-bit HotSpot VM.
# Using compressed oop with 3-bit shift.
# Using compressed klass with 3-bit shift.
# WARNING | Compressed references base/shifts are guessed by the experiment!
# WARNING | Therefore, computed addresses are just guesses, and ARE NOT RELIABLE.
# WARNING | Make sure to attach Serviceability Agent to get the reliable addresses.
# Objects are 8 bytes aligned.
# Field sizes by type: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
# Array element sizes: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
上面的输出中,我们可以看到:Objects are 8 bytes aligned,这意味着所有的对象分配的字节都是8的整数倍。
再注意上面输出的一个关键字aligned,确认过眼神,是对的那个人。
aligned对齐的意思,表示JVM中的对象都是以8字节对齐的,如果对象本身占用的空间不足8字节或者不是8字节的倍数,则补齐。
还是用JOL来分析String对象:
[main] INFO com.flydean.JolUsage - java.lang.String object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 12 (object header) N/A
12 4 byte[] String.value N/A
16 4 int String.hash N/A
20 1 byte String.coder N/A
21 1 boolean String.hashIsZero N/A
22 2 (loss due to the next object alignment)
Instance size: 24 bytes
Space losses: 0 bytes internal + 2 bytes external = 2 bytes total
可以看到一个String对象占用24字节,但是真正有意义的是22字节,有两个2字节是补齐用的。
对齐的好处显而易见,就是CPU在读取数据的时候更加方便和快捷,因为CPU设定是一次读取多少字节来的,如果你存储是没有对齐的,则CPU读取起来效率会比较低。
现在可以回答部分问题:BufferU表示是unaligned,BufferRU表示是只读的unaligned。
小师妹:那BufferS和BufferRS呢?
这个问题其实还是很难回答的,但是经过师兄我的不断研究和探索,终于找到了答案:
先看下DirectShortBufferRU和DirectShortBufferRS的区别,两者的区别在两个地方,先看第一个Order:
DirectShortBufferRU:
public ByteOrder order() {
return ((ByteOrder.nativeOrder() != ByteOrder.BIG_ENDIAN)
? ByteOrder.LITTLE_ENDIAN : ByteOrder.BIG_ENDIAN);
}
DirectShortBufferRS:
public ByteOrder order() {
return ((ByteOrder.nativeOrder() == ByteOrder.BIG_ENDIAN)
? ByteOrder.LITTLE_ENDIAN : ByteOrder.BIG_ENDIAN);
}
可以看到DirectShortBufferRU的Order是跟nativeOrder是一致的。而DirectShortBufferRS的Order跟nativeOrder是相反的。
为什么相反?再看两者get方法的不同:
DirectShortBufferU:
public short get() {
try {
checkSegment();
return ((UNSAFE.getShort(ix(nextGetIndex()))));
} finally {
Reference.reachabilityFence(this);
}
}
DirectShortBufferS:
public short get() {
try {
checkSegment();
return (Bits.swap(UNSAFE.getShort(ix(nextGetIndex()))));
} finally {
Reference.reachabilityFence(this);
}
}
区别出来了,DirectShortBufferS在返回的时候做了一个bits的swap操作。
所以BufferS表示的是swap过后的Buffer,和BufferRS表示的是只读的swap过后的Buffer。
总结
不写注释实在是害死人啊!尤其是JDK自己也不写注释的情况下!
更多精彩内容且看:
- 区块链从入门到放弃系列教程-涵盖密码学,超级账本,以太坊,Libra,比特币等持续更新
- Spring Boot 2.X系列教程:七天从无到有掌握Spring Boot-持续更新
- Spring 5.X系列教程:满足你对Spring5的一切想象-持续更新
- java程序员从小工到专家成神之路(2020版)-持续更新中,附详细文章教程
本文作者:flydean程序那些事
本文链接:http://www.flydean.com/java-io-nio-kinds-of-buffer/
本文来源:flydean的博客
欢迎关注我的公众号:程序那些事,更多精彩等着您!