4.实操(Credit Card Fraud Detection)
目录
- 一、数据挖掘流程
- 二、Data Preview
- 2.1 data. shape
- 2.2 data. head()
- 2.3 data.describe()
- 2.4 check NaN
- 2.5 Class Distribution
- 2.6 correlation heatmap
- 三、问题+方案
- 3.1 发现的问题
- 3.2 方案
- 四、Data Preprocessing
- 4.1 Standardization
- 4.2 Under sample
- 4.3 Data split
- 4.4 SMOTE
- 五、模型构建
- 5.1 Logistic Regression
- 5.2 使用undersample后的测试数据进行评估
- 5.3 对原始数据的测试集进行评估
- 5.4 使用SMOTE训练
- 5.5 结合undersample 和 SMOTE
一、数据挖掘流程
- 加载数据
- 观察数据结构,分布,有哪些问题
- 针对问题提出不同的解决方案
- 数据预处理
- 数据集切分
- 选择评估方法
- 构造模型
- 建模结果记录+分析
- 方案对比
二、Data Preview
2.1 data. shape
(284807, 31)
2.2 data. head()
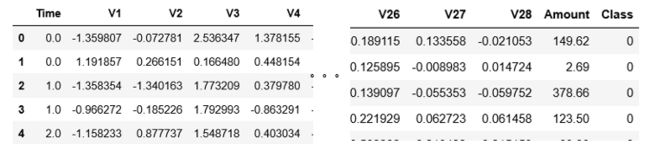
- 可以看出属性有 Time,V1 - V28, Amount组成
- 除了Amount其他的都经过Standardization
- Time属性没用,以后删掉
- Amount 不知道需不需要进行标准化scaling
2.3 data.describe()
data.descirbe(include='all')可以看到Amount的统计量:
- mean:88.34
- std:250
- min:0
- 25%:5.6
- 50%:22
- 75%:77.2
- max:25691
2.4 check NaN
此案例没有缺失值
2.5 Class Distribution
0 : 284315 (99.8%)
1 : 492 (0.2%)
isFraud发生的极其少,数据极不平衡,之后需要SMOTE或者Under sample
2.6 correlation heatmap
import seaborn as sns
corr = data.corr() #传入要看相关性的属性或全部列data.corr()
plt.figure(figsize=(15,15))
sns.heatmap(corr,square=True) ##annot=Ture 显示每个方格的数据 fmt参数控制字符属性
plt.show()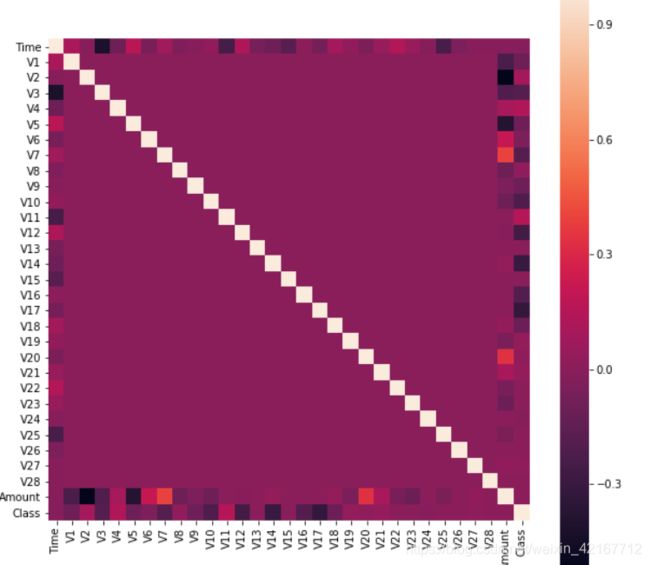
看不出有哪些属性有着很强的相关性,很大程度可能是因为极度imbalance的缘故造成的
三、问题+方案
3.1 发现的问题
- Time 属性没用
- Amount 的数据值范围比别的属性要大很多,要进行standardization变换
- 数据class极度不平衡,需要进行过采样或下采样
3.2 方案
通用的预处理:
- 删除Time属性
- 对Amount进行Standardization
- 平衡数据
3.1 SMOTE
3.2 Under sample
3.3 先将notFraud的样本Undersample到六七百的数量,再进行SMOTE
四、Data Preprocessing
4.1 Standardization
from sklearn.preprocessing import StandardScaler
data['Amount'] = StandardScaler().fit_transform(data['Amount'].values.reshape(-1,1))如果fit_transform传入的数据只有一列需要加values.reshape(-1,1)
4.2 Under sample
# undersample 抽取data中所有的fraud 样本400多个,然后在剩下的class=0的样本中sample相等数量的样本就行
fraud_data = data[data["Class"]==1] # fraud_data dataframe
number_records_fraud = len(fraud_data) # how many fraud samples:492
not_fraud_data = data[data["Class"]==0].sample(n=number_records_fraud)
training_data_1 = pd.concat([fraud_data,not_fraud_data])tips:这里新生成的training_data_1的索引是未经过重排序的,是乱的
进行feature和class的分离
X_under = training_data_1.drop(['Class'],axis=1)
y_under = training_data_1['Class']经过under sample的数据集,看下个属性的相关性热力图
很明显看出V16-V18正相关性很强,V1V2还有一些属性负相关性很强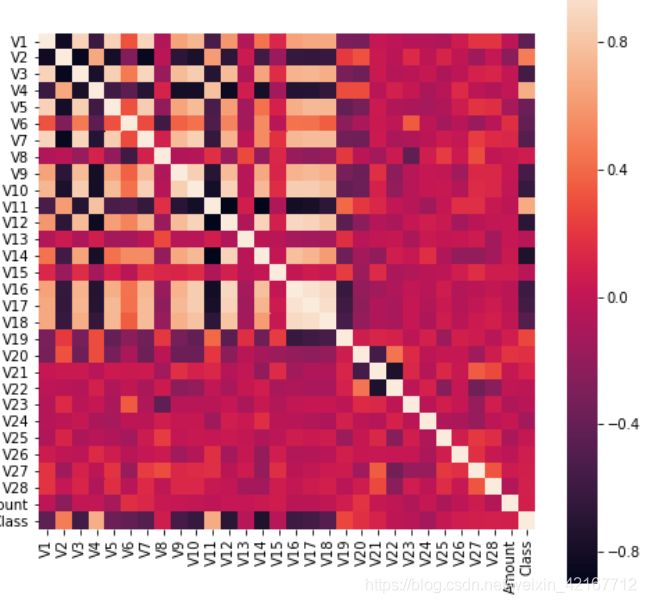
4.3 Data split
对原始数据进行分离
from sklearn.model_selection import train_test_split
train_x, test_x, train_y, test_y = train_test_split(X, y, test_size=0.3, random_state=33)对undersample的数据进行分离
train_x_under, test_x_under, train_y_under, test_y_under = train_test_split(X_under, y_under, test_size=0.3, random_state=33)4.4 SMOTE
from imblearn.over_sampling import SMOTE,ADASYN
features_data,label_data = SMOTE().fit_resample(features_data,np.ravel(label_data))
X_smote,y_smote = SMOTE(random_state=33).fit_resample(X,np.ravel(y))
X_smote = pd.DataFrame(X_smote,columns=features_name)
y_smote = pd.DataFrame({"Class":y_smote})五、模型构建
5.1 Logistic Regression
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
parameters={'penalty':['l1','l2'],'C':[0.01,0.1,1,3,10]}
#C是惩罚力度,与直觉相反,C越小惩罚力度越大
clf = LogisticRegression(n_jobs=-1)
model = GridSearchCV(estimator=clf,param_grid=parameters,cv=8,n_jobs=-1,scoring='recall')
model.fit(train_x_under,train_y_under)
print(model.best_score_)
print(model.best_params_)往GridSearchCV传入不同的评估指标recall 和 Auc
AUC = 0.979185745056816 {‘C’:1, ‘penalty’: ‘l1’} LogisticRegression
Recall = 0.9105691056910569 {‘C’: 0.01, ‘penalty’: ‘l1’} LogisticRegression
5.2 使用undersample后的测试数据进行评估
train_x_under, test_x_under, train_y_under, test_y_under
clf = LogisticRegression(C=1,penalty='l1')
clf.fit(train_x_under,train_y_under)
predict = clf.predict(test_x_under)再使用evaluate方法

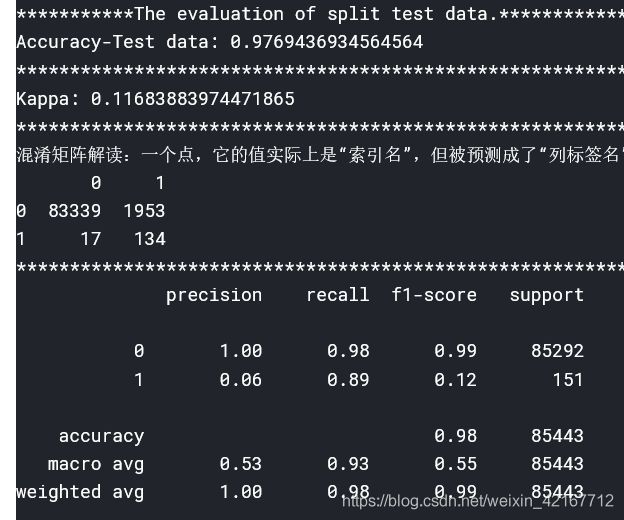
5.3 对原始数据的测试集进行评估
train_x, test_x, train_y, test_yclf = LogisticRegression(C=1,penalty='l1')
clf.fit(train_x,train_y)
predict = clf.predict(test_x)
evaluate(predict,test_y,[0,1])
fraud的recall rate偏低,所有151个fraud样本中只有62%被找出来
5.4 使用SMOTE训练
SMOTE过后的数据 0:1 = 28万:28万
clf = LogisticRegression(C=0.01,penalty='l1')
clf.fit(X_smote,y_smote)
predict = clf.predict(test_x)

误报率提高了好多,正常的被分类成fraud的有2000多个
5.5 结合undersample 和 SMOTE
先将notFraud的undersample到700,这样0:1 = 700:492
再进行SMOTE,就变成700:700,拿这个数据进行训练