爬虫实战系列(六):网抑云音乐评论获取就是这样简单
声明:本博客只是简单的爬虫示范,并不涉及任何商业用途。
一.前言
网易云可以说是国内一个较流行的音乐平台了,作为一名云村老用户,今天还是忍不住向它下手了。由于QQ音乐评论爬虫的经验,我很快就在开发者工具界面的xhr文件中找到了评论数据。但是一个问题摆在面前,网易云对评论数据做了混淆加密处理,如果使用requests来爬的话还需要搞懂它的加密原理,这样过于麻烦,于是我便想到了Selenium,即通过模拟用户操作浏览器的方式来进行页面跳转和评论获取,这样一来就容易多了。
二.爬虫过程
2.1 如何进行翻页操作
这次爬取我选取的林俊杰的《无滤镜》,进入页面并滑到界面底部,我们即可获取需要进行的翻页次数和需要操作的元素,即622次和下一页“按钮”:

选中按钮并右键点击检查,即可找到下一页“按钮”的源码,这里需要注意到一个问题,这些“按钮”都在一个id=g_iframe的iframe中,因此在定位元素时需要先切换到对应的iframe中去,我开始没注意这个,结果元素定位一直出问题。

在解决上述问题后,还有一个问题是"下一页"按钮进行click操作却无法点击成功,在上网查询资料后发现跳转操作需要通过js方式来完成,即:
next_button = WAIT.until(EC.element_to_be_clickable((By.XPATH,'//a[starts-with(@class,"zbtn znxt js-n-")]')))
driver.execute_script('arguments[0].click();', next_button)
2.2 获取评论数据
对于评论的获取其实属于常规操作了,首先选中一条评论->右键->检查,可以发现所有的评论都在class='cnt f-brk'的div块中:
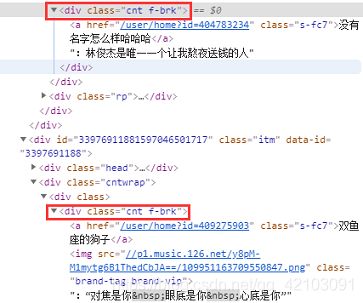
因此,我看可以通过selenium的方法find_elements_by_xpath()来获取到所有的div块,然后通过每个元素的text属性来获取到元素的文本,需要注意的直接获取的text文本中包含了用户名,我们只需要截取文本中的评论内容。
2.3 爬虫流程
综合上述的2.1,2.2两节可得爬虫的详细流程,需要注意的是第一页需要单独通过url来获取,而其他的就都可以按照点击按钮->获取评论来进行循环:

2.4 词频直方图的绘制
对于爬取的评论数据,我准备采用词频直方图来进行可视化展示,首先进行jieba分词,再删除停用词,然后再调用sklearn的CountVectorizer类来获取词频,最后将词频进行排序后选取前10热词利用Matplotlib进行词频直方图绘制:
三.爬虫代码及结果展示
3.1 爬虫部分代码
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
import pandas as pd
#开启万花筒模式
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--disable-gpu')
driver = webdriver.Chrome(options=options)
WAIT = WebDriverWait(driver,10)
def ParseComment(element_list):
"""
功能:提取网页中的评论
element_list:包含评论的div元素块集合
"""
clist = []
for c in element_list:
text = c.text
idx = text.find(':')
print(text[idx + 1:])
clist.append(text[idx + 1:])
return clist
def NextPage():
"""
功能:获取下一页评论
page_num:当前评论页
"""
try:
next_button = WAIT.until(EC.element_to_be_clickable((By.XPATH,'//a[starts-with(@class,"zbtn znxt js-n-")]')))
driver.execute_script('arguments[0].click();', next_button)
element_list = WAIT.until(EC.presence_of_all_elements_located((By.XPATH,'//div[@class="cnt f-brk"]')))
return element_list
except TimeoutException:
traceback.print_exc()
driver.refresh()
NextPage()
def Spider(page_nums = 623,url="https://music.163.com/#/song?id=1466053895"):
"""
功能:爬虫主程序
page_nums:评论总页数
url:爬取歌曲链接
"""
i,comments = 2,[]
driver.get(url)
driver.switch_to.frame('g_iframe')
element_list = driver.find_elements_by_xpath('//div[@class="cnt f-brk"]')
comments += ParseComment(element_list )
try:
while i <= page_nums:
print('-------------Crawing page {}---------------'.format(i))
element_list = NextPage()
comments += ParseComment(element_list)
i += 1
finally:
driver.close()
return comments
def Saver(comments,file_path = '无滤镜评论.csv'):
"""
功能:保存评论为csv文件
comments:评论列表
"""
datas = pd.DataFrame(comments,columns=['评论内容'])
datas.to_csv(file_path,index=False)
if __name__ == "__main__":
comments = Spider()
Saver(comments)
3.2 评论处理代码
import pandas as pd
import matplotlib.pyplot as plt
import jieba
import re
from sklearn.feature_extraction.text import CountVectorizer
chinese = '[\u4e00-\u9fa5]+' #提取中文汉字的pattern
def LoadComments(file_path="无滤镜评论.csv"):
"""
功能:加载csv文件中的评论为评论列表
file_path:csv文件路径
"""
datas = pd.read_csv(file_path)
comment_list = datas['评论内容'].values.tolist()
return comment_list
def LoadStopWords(file_path = '中文停用词词表.txt'):
"""
功能:加载中文停用词列表
file_path:停用词表所在路径
"""
stopwords = []
with open(file_path,'r') as f:
text = f.readlines()
for line in text:
stopwords.append(line[:-2])#去换行符
return stopwords
def DeleteStopWrods(g_list,stop_words):
"""
功能:删除中文停词
g_lst:分词结果
stop_words:分词结果
"""
outcome = []
for term in g_list:
if term not in stop_words:
outcome.append(term)
return outcome
def Cutter(comment_list,stop_words):
"""
功能:中文分词主函数
comment_list:评论列表
stop_words:中文停用词表
"""
cut_string = "" #分词结果字符串
for comment in comment_list:
comment = "".join(re.findall(chinese,comment))
if comment != "":
seg_list = jieba.cut(comment)
comment = " ".join(DeleteStopWrods(seg_list,stop_words))
cut_string += comment + ' '
return cut_string
def WordFrequence(cut_string):
"""
功能:获取词频
cut_string:分词后的字符串
"""
vc = CountVectorizer()
X = vc.fit_transform([cut_string])
word = vc.get_feature_names()
freq = X.toarray().tolist()
word_freq = [item for item in zip(word,freq[0])] #获取单词对应的词频
word_freq.sort(reverse=True,key=lambda x:x[1]) #按词频降序排序
return word_freq
def WordFrequenceBar(word_freq):
"""
功能:生成词频直方图
word_freq:词及频率
"""
top = word_freq[:10]
data = pd.DataFrame(top,columns=['word','freq'])
x,y = data['word'].values.tolist(),data['freq'].values.tolist()
plt.rcParams['font.sans-serif']=['SimHei']#正确显示中文l
color = [(1 - 0.03 * l, 0, 0) for l in range(10)] #设置不同柱形不同颜色
plt.barh(x[::-1],y[::-1],color=color[::-1])
plt.title('无滤镜热词top10')
plt.xlabel('freq')
plt.ylabel('word')
plt.savefig('热词直方图.png')
plt.show()
def main():
"""
功能:完成中文分词,词频直方图的绘制
"""
#加载评论数据
comment_list = LoadComments()
#加载停用词表
stop_words = LoadStopWords()
#分词
cut_string = Cutter(comment_list,stop_words)
#获取词频
word_freq = WordFrequence(cut_string)
#生成词频直方图
WordFrequenceBar(word_freq)
if __name__ == "__main__":
main()
3.3 爬虫结果展示
在爬取到所有的评论后,我将评论先保存到csv文件中,最后一共获取到一万三千多条评论数据,部分评论展示如下:

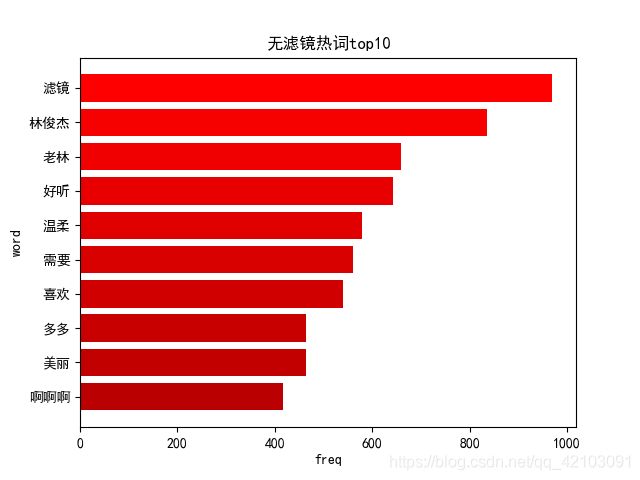
对获取的评论进行分词后,进行词频获取,然后筛选出top10热词绘制的词频直方图如下图所示:
以上便是本文的全部内容,要是觉得不错支持一下吧!!!