ECCV2020——Self-Prediction for Joint Instance and Semantic Segmentation of Point Clouds
Self-Prediction for Joint Instance and Semantic Segmentation of Point Clouds
- Abstract
- (一) Introduction
- (二) Related Work
- (三) Methodology
- 3.1 Self-Prediction
- 3.2 Associated Learning Framework
- 3.3 Optimization Objectives
- (四)Experiments
- 4.1 Experiment Settings
- 4.2 Segmentation Results on S3DIS
- 4.3 Segmentation Results on ShapeNet
- 4.4 Ablation Study
- (五)Conclusion
Abstract
- 针对3D实例和点云的语义分割开发了一种名为“Self-Prediction”的新颖学习方案。
- 与大多数现有的专注于设计卷积操作符的方法不同,该论文设计了一种新的学习方案来增强点关系的探索,以便更好地分割。
- 更具体地说,将一个点云样本划分为两个子集,并根据它们的表示构造一个完整图。在给定一个子集的标签时,利用标签传播算法对另一个子集的标签进行预测。
- 通过训练这个Self-Prediction,骨干网络可以充分探索关系上下文/几何/形状信息和学习更多的可区分特征。
- 而且,在此基础上,设计了一种基于Self-Prediction方案的通用关联框架,用于同时增强实例和语义分割,结合实例和语义表示进行Self-Prediction。
- 通过这种方式,实例分割和语义分割相互配合,相互加强。
- 与基线相比,S3DIS和ShapeNet在实例分割和语义分割上取得了显著的性能改进。在S3DIS上取得了state-of-the-arts的实例分割结果。
- 在仅以pointnet++为骨干网络的情况下,与S3DIS和ShapeNet上最先进的语义分割结果相比,也取得了比较好的结果。
(一) Introduction

网络框架:
- 包含一个骨干网和instance-head,semantic-head和Self-Prediction head。
- instance-head学习实例嵌入以进行实例聚类。
- semantic-head则输出语义嵌入以进行语义预测。
- 在Self-Prediction head中,每个点的实例和语义嵌入被组合在一起。
- 然后,将语义和实例标签连接起来,为每个点形成一个多标签。
- 之后,将点云分为两组,其中一组标签被丢弃。
- 给定整个点云和一组标签的组合嵌入,构造了一个完整的图,然后使用标签传播算法为另一组同时预测语义和实例标签。
- 在两组之间执行双向传播。通过多标签自预测的此过程,实例和语义嵌入得到了关联的增强。
- 自我预测的过程结合了点的嵌入相似性,这使网络探索点之间的有效关系并学习更多区分性表示。
- 这三个heads在训练时进行了联合优化。在推理过程中,Self-Prediction head被丢弃,没有引入计算负担和网络参数。
- 论文框架在不同的骨干网络(如PointNet,PointNet ++等)上是通用且有效的。
(二) Related Work
~~
(三) Methodology
3.1 Self-Prediction
定义:
- Self-Prediction是与实例和分割任务并行的辅助任务,旨在增强骨干网络以学习更强大和更具区分性的表示形式。
idea:
- 为了获得更好的分割性能,许多现有工作设计了卷积算子以捕获点云中包含的关系,几何和形状信息。共同目标是学习更多区分性表示。但是,论文采取了新的观点。如果给定点云中rest points的标签,学到的表示形式可用于预测点云的一部分的实例/语义标签,则可以认为它充分利用了关系信息并具有足够的代表性。
- 因此,论文制定了一个Self-Prediction任务,即将点云平均分为两组,然后根据给定的表示在两组之间执行双向预测。
结果:
- 网络在Self-Prediction任务上表现良好,可以获得更 strong features ,并在特定任务(即实例和语义分割)上表现更好。
网络框架详解:
-
给定一个包含N个点 X = { x 1 , x 2 , . . . , x N } X= \left \{x_{1},x_{2},...,x_{N}\right \} X={x1,x2,...,xN}的点云示例,每个点 x i ∈ R h x_i∈R^h xi∈Rh可以用坐标,颜色,法线等表示。 h h h是输入点特征的维数。
-
对于每个点 x i x_i xi,其类别标签均由一个one-hot vector表示。制定一个标签矩阵 Y ∈ y Y∈y Y∈y,其中矩阵 Y Y Y的每一行表示点 x i x_i xi的one-hot label,而 y y y表示具有非负元素的 N × C N×C N×C矩阵的集合(C是类别数)。
-
将点云平均分为两组,即 X S = { x 1 , x 2 , . . . , x N } X_{S}= \left \{x_{1},x_{2},...,x_{N}\right \} XS={x1,x2,...,xN},及其标签矩阵 X 1 : M ; X_{1:M}; X1:M; X U = { x M + 1 , x M + 2 , . . . , x N } X_{U}= \left \{x_{M+1},x_{M+2},...,x_{N}\right \} XU={xM+1,xM+2,...,xN},及其标签矩阵 Y M + 1 : N Y_{M+1:N} YM+1:N。
-
使用标签传播算法在点子集 X S X_S XS和 X U X_U XU之间执行双向Self-Prediction,即从 X S X_S XS到 X U X_U XU以及从 X U X_U XU到 X S X_S XS反向传播标签。.
-
首先,构造一个完整的图 W ∈ R N × N W∈R^{N×N} W∈RN×N,其每个元素都由高斯相似度函数定义:
W i j = e x p ( − d ( φ ( x i ) , φ ( x j ) ) 2 σ 2 ) − − − − − − − − − − − − − − − − − − − − ( 1 ) W_{ij}=exp(-\frac{d\left ( \varphi \left ( x_{i}\right ),\varphi \left ( x_j\right )\right )}{2\sigma ^{2}})--------------------(1) Wij=exp(−2σ2d(φ(xi),φ(xj)))−−−−−−−−−−−−−−−−−−−−(1)
φ \varphi φ是骨干网
φ ( x i ) \varphi \left ( x_{i}\right ) φ(xi)表示点 x i x_i xi的提取特征,
d d d是欧几里得距离度量函数,
σ σ σ是用于调整strength neighbors的长度比例参数。
在所有实验中,将σ设置为1。 -
然后通过计算拉普拉斯矩阵对构造的图进行归一化:
L = D − 1 / 2 W D − 1 / 2 − − − − − − − − − − − − − − − − ( 2 ) L=D^{-1/2}WD^{-1/2}----------------(2) L=D−1/2WD−1/2−−−−−−−−−−−−−−−−(2)
D D D是对角矩阵, D i i D_{ii} Dii是 W W W的第i行之和。即 D i i = ∑ j = 1 N W i j D_{ii}=\sum_{j=1}^{N}W_{ij} Dii=∑j=1NWij。
- 为了分别在给定 X S X_S XS标签预测 X U X_U XU标签和给定 X U X_U XU标签时预测 X S X_S XS标签,必须通过将Y1:M和YM + 1:N分别填充零向量来准备两个初始标签矩阵 S 0 S^{0} S0和 U 0 U^0 U0。 具体来说, S 0 S^{0} S0和 U 0 U^0 U0表示为:
S 0 = [ Y 1 T , . . . , Y M T , 0 T , . . . , 0 T ] T − − − − − − ( 3 ) S^{0}=\left [ Y_{1}^{T},...,Y_{M}^{T},0^{T},...,0^{T}\right ]^{T}------(3) S0=[Y1T,...,YMT,0T,...,0T]T−−−−−−(3)
U 0 = [ 0 T , . . . , 0 T , Y M + 1 T , . . . , 0 N T ] T − − − − − ( 3 ) U^{0}=\left [ 0_{}^{T},...,0_{}^{T},Y_{M+1}^{T},...,0_{N}^{T}\right ]^{T}-----(3) U0=[0T,...,0T,YM+1T,...,0NT]T−−−−−(3)
Y i Y_i Yi表示标签矩阵 Y Y Y的第 i i i行。 - Self-Prediction过程是通过标签传播算法执行的,其迭代版本如下:
S ( t + 1 ) = α L S ( t ) + ( 1 − α ) S 0 − − − − − − ( 4 ) S^{(t+1)}=\alpha LS^{\left ( t\right )}+\left ( 1-\alpha\right )S^{0}------(4) S(t+1)=αLS(t)+(1−α)S0−−−−−−(4)
U ( t + 1 ) = α L U ( t ) + ( 1 − α ) U 0 − − − − − − ( 4 ) U^{(t+1)}=\alpha LU^{\left ( t\right )}+\left ( 1-\alpha\right )U^{0}------(4) U(t+1)=αLU(t)+(1−α)U0−−−−−−(4)
α α α是用于控制传播比例的参数,即初始标记矩阵对传播结果的影响程度。将α设置为0.99。 - S ( t ) ∈ y S^{(t)}\in y S(t)∈y和 U ( t ) ∈ y U^{(t)}\in y U(t)∈y是第 t t t次迭代结果。通过迭代方程4直到收敛,我们将得到最终结果 S ∗ S^∗ S∗和 U ∗ U^ ∗ U∗。论文直接使用<
>提出的上述迭代版本的封闭形式来获得传播/预测的结果。封闭形式的表达式,如下所示:
S ( ∗ ) = ( 1 − α L ) − 1 S 0 − − − − − − ( 5 ) S^{(\ast)}=\left ( 1-\alpha L\right )^{-1}S^{0}------(5) S(∗)=(1−αL)−1S0−−−−−−(5)
U ( ∗ ) = ( 1 − α L ) − 1 U 0 − − − − − − ( 5 ) U^{(\ast)}=\left ( 1-\alpha L\right )^{-1}U^{0}------(5) U(∗)=(1−αL)−1U0−−−−−−(5)
I ∈ R N × N I\in R^{N\times N} I∈RN×N是单位矩阵。 S M + 1 : N ∗ S^{\ast}_{M+1:N} SM+1:N∗和 U 1 : M ∗ U^{\ast}_{1:M} U1:M∗是有效的传播结果。 - 预测 x i x_i xi的标签通过arg max U i ∗ U_{i}^{\ast} Ui∗当 1 < i ≤ M 1< i\leq M 1<i≤Mand arg max S i ∗ S_{i}^{\ast} Si∗当 M < i ≤ N M< i\leq N M<i≤N。
- 最终self-predicted结果 Y ∗ ∈ y Y^{\ast}\in y Y∗∈y是:
Y ∗ = [ ∪ 1 : M ∗ T , S M + 1 : N ∗ T ] T − − − − − ( 6 ) Y^{\ast}=\left [\cup^{\ast T}_{1:M},S^{\ast T}_{M+1:N}\right ]^{T}-----(6) Y∗=[∪1:M∗T,SM+1:N∗T]T−−−−−(6) - 最后,使用ground truth label矩阵 Y Y Y作为监督信号来训练这个Self-Prediction任务。
3.2 Associated Learning Framework
- 以点云 X X X为输入,骨干网输出特征矩阵 F ∈ R N × H F∈^{RN×H} F∈RN×H,其中 H H H表示输出特征的维数。Instance head以 F F F为输入,将其转换成point-wise instance embeddings F i n s ∈ R N × H i n s F_{ins}∈R^{N×H_{ins}} Fins∈RN×Hins,其中 H i n s H_{ins} Hins是实例嵌入的维数,在所有的实验中都设置为32。
损失函数:
- 如果一个点云例子包含 K K K个实例,并且第K个(K∈1,2,…K)实例包含 N k N_k Nkpoints,则将 e j ∈ R H i n s e_j∈R^{H_{ins}} ej∈RHins表示为第j个点的实例嵌入,将 μ k ∈ R H i n s \mu_{k}∈R^{H_{ins}} μk∈RHins表示为第 K K K个实例的平均嵌入。实例损失写为:
L v a r . = 1 C ∑ c = 1 C 1 N c ∑ i = 1 N c [ ∥ μ C − ϵ i ∥ − δ v ] + 2 − − − − − − − − − − − − − − − ( 5 ) L_{var.}=\frac{1}{C}\sum_{c=1}^{C}\frac{1}{N_{c}}\sum_{i=1}^{N_{c}}\left [ \left \| \mu_{C}-\epsilon _{i}\right \|-\delta _{v}\right ]_{+}^{2}---------------(5) Lvar.=C1c=1∑CNc1i=1∑Nc[∥μC−ϵi∥−δv]+2−−−−−−−−−−−−−−−(5)
L d i s t . = 1 C ( C − 1 ) ∑ C A = 1 C ∑ C B = 1 C [ 2 δ d − ∥ μ C A − μ C B ∥ ] + 2 . . . . . . . . C A ≠ C B − − − − − − − − − − ( 6 ) L_{dist.}=\frac{1}{C(C-1)}\sum_{C_{A}=1}^{C}\sum_{C_{B}=1}^{C}\left [2\delta _{d}- \left \| \mu_{C_{A}}-\mu_{C_{B}}\right \|\right ]_{+}^{2} ........ C_{A}\neq C_{B}----------(6) Ldist.=C(C−1)1CA=1∑CCB=1∑C[2δd−∥μCA−μCB∥]+2........CA=CB−−−−−−−−−−(6)
L r e g . = 1 C ∑ C = 1 C ∥ μ C ∥ − − − − − − − − − − − − ( 7 ) L_{reg.}=\frac{1}{C}\sum_{C=1}^{C}\left \|\mu _{C} \right \|------------(7) Lreg.=C1C=1∑C∥μC∥−−−−−−−−−−−−(7)
L i n s = L v a r + L d i s t + 0.001 ⋅ L r e g − − − − − − − − ( 10 ) L_{ins}=L_{var}+L_{dist}+0.001\cdot L_{reg}--------(10) Lins=Lvar+Ldist+0.001⋅Lreg−−−−−−−−(10) - [ x ] + = m a x ( 0 , x ) \left [ x\right ]_{+}=max(0,x) [x]+=max(0,x), δ v δ_v δv, δ d δ_d δd分别是 L v a r 和 L d i s t L_{var}和L_{dist} Lvar和Ldist的边界
- L v a r . L_{var.} Lvar.将属于同一实例的特征拉到它们的平均值
- L d i s t . L_{dist.} Ldist.将具有不同实例标签的聚类分开
- L r e g . L_{reg.} Lreg.是一个正则化的术语, pulling the means towards the origin。
实例标签:
- 通过在推理过程中对实例嵌入进行mean-shift聚类得到的。
semantic-head:
- 以特征矩阵 F F F为输入,学习语义嵌入矩阵 F s e m ∈ R N × H s e m F_{sem}∈R^{N×H_{sem}} Fsem∈RN×Hsem,在交叉熵损失的监督下进一步进行点分类。点语义嵌入的维数 H s e m H_{sem} Hsem被设置为128。
Self-Prediction head:
-
结合实例嵌入和语义嵌入,联合self-predict实例和语义标签。
-
具体地说,将 F i n s F_{ins} Fins和 F s e m F_{sem} Fsem沿着axis of features连接起来,并将其转换成一个联合嵌入矩阵 F j o i n t ∈ R H j o i n t F_{joint}∈R^{H_{joint}} Fjoint∈RHjoint,其中 h j o i n t h_{joint} hjoint是联合嵌入的维数,在所有的实验中都设置为160。
-
对于 X X X中的每个点,分别将其语义和实例标签转换为one-hot形式。
-
每个点的实例标签表示它属于哪个实例。这个实例标签是语义不可知的,即不能从一个点的实例标签中推断出它的语义标签。
-
一个数据集包含 C s e m C_{sem} Csem semantic类,而输入点云样本 X X X包含 C i n s C_{ins} Cinsinstances。然后将语义标签矩阵和实例标签矩阵分别表示为 Y s e m ∈ y s e m Y_{sem}∈y_{sem} Ysem∈ysem and Y i n s ∈ y i n s Y_{ins}∈y_{ins} Yins∈yins,其中 Y s e m Y_{sem} Ysem是具有非负元素的 N × C s e m N×C_{sem} N×Csem矩阵的集合, Y i n s Y_{ins} Yins是具有非负元素的 N × C i n s N×C_{ins} N×Cins矩阵的集合。
-
在给定这两个标签矩阵的基础上,通过连接每个点的语义标签和实例标签,构造了一个多标签矩阵 Y j o i n t ∈ y j o i n t Y_{joint}∈y_{joint} Yjoint∈yjoint,其中 Y j o i n t Y_{joint} Yjoint是 N × ( C s e m + C i n s ) N×(C_{sem}+C_{ins}) N×(Csem+Cins)矩阵的非负元素集。可以从 Y j o i n t Y_{joint} Yjoint推断每个点属于哪个语义类和实例。
-
将self-predicted 切片为 Y j o i n t ∗ ∈ y j o i n t Y_{joint}^*∈y_{joint} Yjoint∗∈yjoint切片为语义结果 Y s e m ∗ ∈ y s e m Y_{sem}^*∈y_{sem} Ysem∗∈ysem和 Y i n s ∗ ∈ y i n s Y_{ins}^*∈y_{ins} Yins∗∈yins,然后分别由semantic ground truth Y s e m Y_{sem} Ysem和instance ground truth Y i n s Y_{ins} Yins进行监督。应该注意的是,Self-Prediction每次都是在一个点云样本之间进行的,因此实例标签的含义随样本的不同而变化也没关系。
Instance-head, semantic-head and Self-Prediction head 联合优化:
- Instance-head and semantic-head旨在获得分割结果。
- Self-Prediction head 融合了点之间的相似性关系,并加强了backbone以学习更多区分性表示。
- 这三个heads相互配合,可获得更好的分割效果。
- Self-Prediction head被丢弃,during inference仅使用实例头和语义头,因此不会引入额外的计算负担和空间使用量。
3.3 Optimization Objectives
- 用等式10中的实例损失 L i n s L_{ins} Lins训练instance-head。
- semantic-head由经典的交叉熵损失训练,并由语义标签 Y s e m Y_{sem} Ysem监督,写为:
L s e m = − 1 N ∑ i = 1 N [ Y s e m ] i l o g p i − − − − ( 11 ) L_{sem}=-\frac{1}{N}\sum_{i=1}^{N}\left [ Y_{sem}\right ]_{i}logp_{i}----(11) Lsem=−N1i=1∑N[Ysem]ilogpi−−−−(11)
-
p i p_i pi表示由softmax函数计算的输出概率分布。
-
给定共同的self-predicted 结果 Y i n s ∗ Y_{ins}^{\ast} Yins∗和 Y i s e m ∗ Y_{isem}^{\ast} Yisem∗,我们还通过交叉熵损失训练了Self-Prediction head,公式为:
L s p = − 1 N ∑ i = 1 N ( [ Y i n s ] i ∗ l o g q i + [ Y s e m ] i ∗ l o g r i ) − − − − − − − − ( 12 ) L_{sp}=-\frac{1}{N}\sum_{i=1}^{N}\left ( \left [ Y_{ins}\right ]_{i}\ast logq_{i}+\left [ Y_{sem}\right ]_{i}\ast logr_{i}\right )--------(12) Lsp=−N1i=1∑N([Yins]i∗logqi+[Ysem]i∗logri)−−−−−−−−(12) -
q i q_i qi和 r i r_i ri是 Y i n s ∗ Y_{ins}^{\ast} Yins∗和 Y i s e m ∗ Y_{isem}^{\ast} Yisem∗第 i i i行的输出概率分布(由softmax计算)。
-
输出概率分布也由softmax函数计算
-
三个head共同优化,总体优化目标是上述三个损失的加权总和:
L = L i n s + L s e m + β L s p − − − − − − − − ( 13 ) L=L_{ins}+L_{sem}+\beta L_{sp}--------(13) L=Lins+Lsem+βLsp−−−−−−−−(13)
其中,β用于平衡上述三个项的贡献,以使它们对总损失的贡献相等。在所有的实验中,β均设置为0.8。
(四)Experiments
4.1 Experiment Settings
Datasets:
- S3DIS
- ShapeNet
S3DIS:
- 对于在S3DIS上进行的实验,采用与PointNet 相同的设置,其中每个房间被分成面积为1m×1m的块。
- 每个3D点均由9维矢量表示(XYZ,RGB和房间的归一化位置)。
- 在训练期间为每个块采样4096个点,所有点都用于测试。
- 上面提到,先构造一个图,然后将点云分为两组以在Self-Prediction head中执行Self-Prediction。在实践中,将点云分为more than两组以进行加速。
- 具体来说,根据实例标签将每个块平均分为8组,即保证每个实例的点平均分布在每个组中。
- 结果,每个语义的点也平均地分布在每个组中。
- 然后随机配对4对,进行Self-Prediction。
- 使用SGD优化器,batch size 8。在S3DIS上训练了100个时期的所有模型。基本学习率设置为0.01,然后每20个时期除以2。
- 按照与JSIS3D: joint semanticinstance segmentation of 3d point clouds with multi-task pointwise networks and multi-value conditional random fields. In: CVPR (2019)和Associatively segmenting instances
and semantics in point clouds. In: CVPR (2019)相同的设置将 δ v δ_v δv设置为0.5,将 δ d δ_d δd设置为1.5。 L s p L_{sp} Lsp的损失权重系数β设置为0.8. - BlockMerging算法用于在推理过程中合并来自不同块的实例,对于mean-shift clusterin,bandwidth设置为0.8。
ShapeNet:
- 输入点云只有coordinat表示
- 在Self-Prediction head,输入点云分成4组。
- Adam optimizer
- train all models for 200 epochs
- batch size 16
- 学习率设置为0.001,每20个epochs.除以2。
- 其他设置与在S3DIS上进行的实验相同。
4.2 Segmentation Results on S3DIS
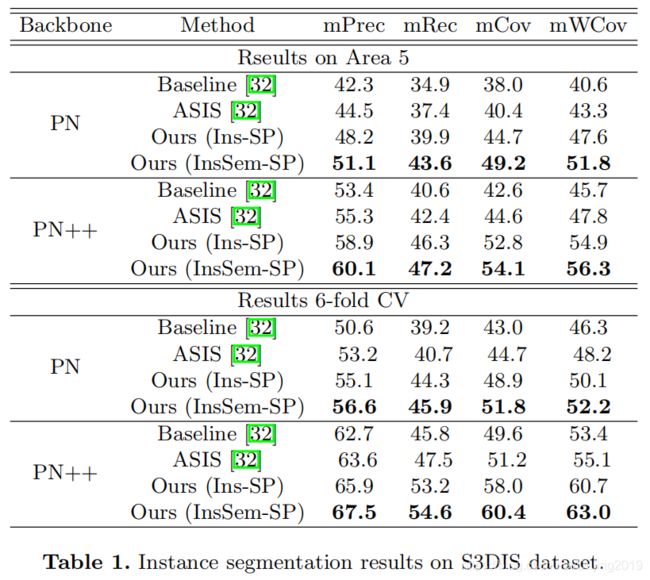

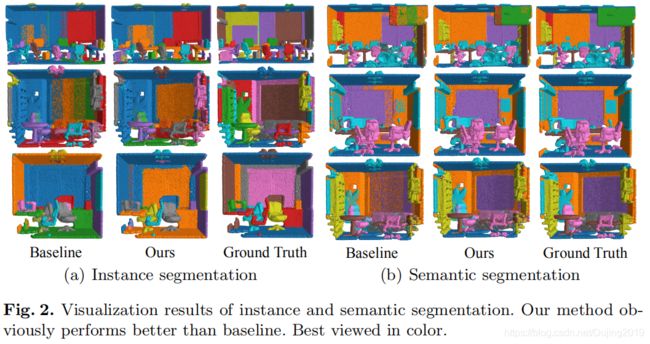
注释:
- Baseline表示仅使用instance-head和semantic-head来训练backbone network。
- InsSem-SP表示方法的完整版本,即联合执行instance and semantic Self-Prediction.
- Ins-SP意味着仅通过使用 F i n s F_{ins} Fins和 Y i n s Y_{ins} Yins输入来执行instance Self-Prediction。
- Sem-SP意味着只能通过接受 F s e m F_{sem} Fsem和 Y s e m Y_{sem} Ysem做为输入来执行semantic Self-Prediction。
- 提出的Self-Prediction head被公式化为损失函数,并且会在推理过程中删除,因此与基线相比,不会引入额外的计算负担和空间使用量。

注释:
- Cov is the average instance-wise IoU between prediction and ground truth.
- WCov means Cov that is weighted by the size of the ground truth instances.
4.3 Segmentation Results on ShapeNet
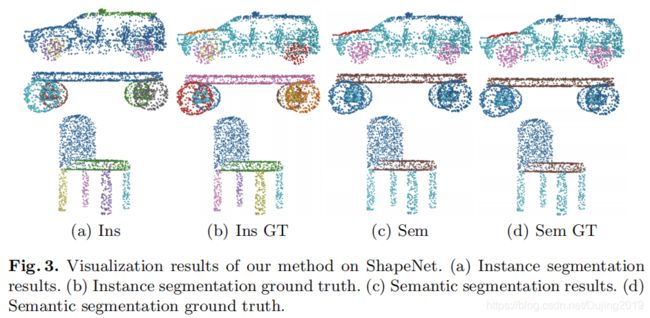
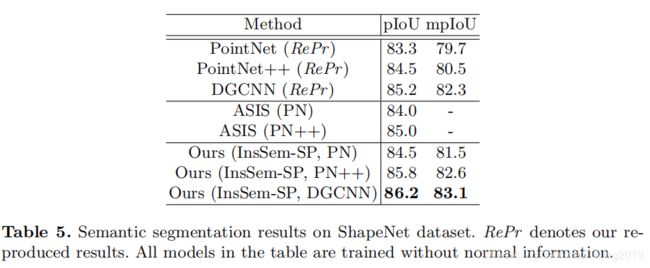
4.4 Ablation Study
任务: 验证bidirectional Self-prediction和 class-averaged group dividing 方式优势。

- 执行 unidirectional Self-Prediction,并且该方向是在两个方向中随机选择的。
- 将点云随机分组,而不是根据Self Prediction head.中的实例标签进行分组。
- 与单向自预测相比,双向自预测带来了明显的改进,随机分组会稍微降低性能。
Parameter Analyses.
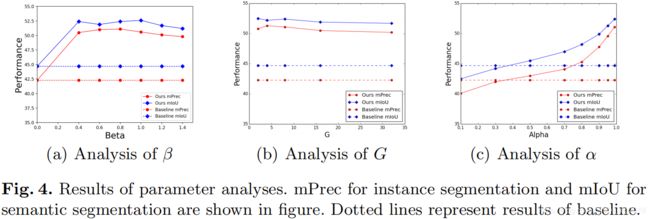
- 方法对参数β(平衡 L s p L_{sp} Lsp权重)不敏感,并且在很大范围内(0.4-1.4)都可以很好地工作。
- 第二个参数是在性能和训练速度之间进行权衡的divided groups G的数量。性能相对稳定,并且在合理范围内对G不敏感。
- 最后一个参数是 α α α,用于控制标签传播过程中的传播部分。论文在所有实验中都遵循通用设置(α= 0.99),并在较大范围内(即,α> 0.5)优于基线。
(五)Conclusion
- 提出了一种名为Self-Prediction的新学习方案以加强关系探索,并提出了一种将点云的实例和语义分段进行关联的联合框架。
- 大量的实验证明,论文方法可以与流行的网络相结合,大大提高其性能。仅以PointNet ++为骨干,方法就可以达到最新水平或可比的结果。
- 论文方法是一个通用的学习框架,易于应用于大多数现有的学习网络。