《使用Python进行自然语言处理》学习笔记一
第一章 语言处理与 Python
一 安装NLTK环境
1.1 windows 7 32的安装
1. 安装Python2.7(稳定版本,http://www.lfd.uci.edu/~gohlke/pythonlibs/#numpy);
2. 安装NumPy:(http://www.lfd.uci.edu/~gohlke/pythonlibs/#numpy)运行numpy‑MKL‑1.8.1rc1.win32‑py2.7.exe;
3. 安装MatPlotLib:(http://www.lfd.uci.edu/~gohlke/pythonlibs/#numpy)运行matplotlib‑1.3.1.win32‑py2.7.exe;
4. 安装NLTK:(http://www.lfd.uci.edu/~gohlke/pythonlibs/#numpy)运行nltk‑2.0.4.win‑amd64‑py2.7.exe;
5 安装NetworkX安装Prover9:(https://www.cs.unm.edu/~mccune/mace4/gui/v05.html)执行Prover9-Mace4-v05-setup.exe程序,或者解压LADR1007B-win.zip,,将解压产生的文件夹LADR1007B-win改名为prover9,并将文件夹prover9移动到C:\nltk_data中;
6. 安装Prover9:(https://www.cs.unm.edu/~mccune/mace4/gui/v05.html)执行Prover9-Mace4-v05-setup.exe程序,或者解压LADR1007B-win.zip,,将解压产生的文件夹LADR1007B-win改名为prover9,并将文件夹prover9移动到C:\nltk_data中;
7. 安装MSVCP71.DLL:(http://cn.dll-files.com/msvcp71.dll.html)如果有必要,将MSVCP71.zip文件解压,将解压得到的MSVCP71.DLL文件复制到C:\Windows\System32下;
8. 安装NLTK数据:在命令行窗口中运行python-m nltk.downloader all,将自动下载并安装所有数据(语料库、词典等),总共约428M。 在window下安装的时候可能没有自带安装easy_install 需要我们手动安装首先下载easy_install的安装包,下载地址:http://pypi.python.org/pypi/setuptools在页面上找到 ez_setup.py下载下来,执行即可,嫌麻烦的直接下载 PyYAML-3.10.win32-py2.7.exe
1.2 Linux安装
等我需要换到Ubuntu下工作的时候补上
二 下载nltk_data数据
1 打开界面程序输入
>>>importnltk
>>>nltk.download()
打开下载窗口
2 下载book数据
选择book执行下载,大概会有100M左右的数据需要下载,需要相当长的时间

3 求助万能的网友
当然,前面的方法是不被建议的方法,好的方法是在网上找网友整理好的包,如http://l3.yunpan.cn/lk/QvLSuskVd6vCU?sid=305
然后直接放在nltk_data文件夹里
三 测试程序
1 词语索引视图
查找显示,单次打印25
>>>text1.concordance("monstrous")
Building index...
Displaying 11 of 11 matches:
………………………………………….
2 相似词查找。
通过上下文找到出现在相似的上下文中的词(相近词查询很像词相关查询)
text1.similar("monstrous")
#Alt-p 获取之前输入的命令
3词的位置信息用离散图表示
>>>text4.dispersion_plot(["citizens", "democracy","freedom", "duties", "America"])
这里容易出现问题
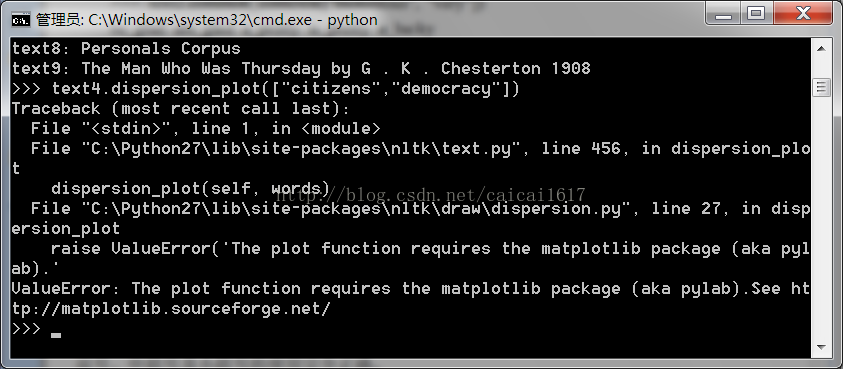
这个可能是Matplotlib 和Numpy的版本导致没有完全安装成功造成的问题
解决办法1:参照http://blog.csdn.net/yang6464158/article/details/18546871进行解决
具体步骤是:把路径如:C:\Python27\Lib\site-packages\scipy\lib中的six.pysix.pyc six.pyo三个文件拷贝到C:\Python27\Lib\site-packages目录下。
再在IDLE(Python GUI)中输入import matplotlib.pyplot as plt便可以解决啦!
这个过程中可能会提示
ValueError:The plot function requires the matplotlib package
ImportError:matplotlib requires dateutil
一般情况下,确实是没装,那么可以去(http://www.lfd.uci.edu/~gohlke/pythonlibs/#numpy)安装python-dateutil-2.2.win32-py2.7.exe和pyparsing-2.0.1.win32-py2.7.exe
完成以后输入
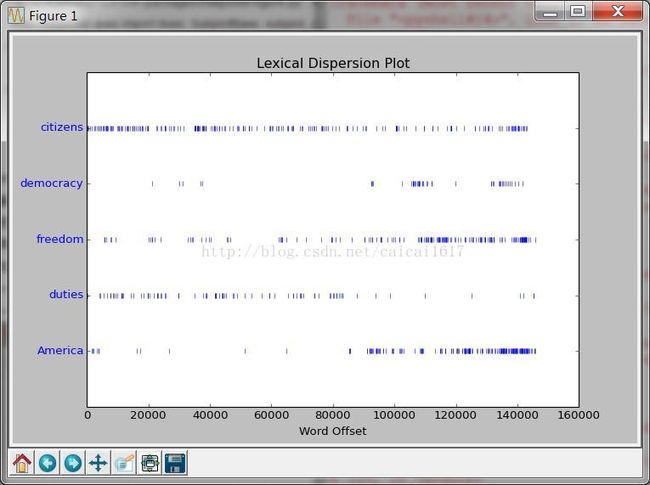
>>>import matplotlib.pyplot as plt
>>>text4.dispersion_plot(["citizens", "democracy","freedom", "duties", "America"])
此时没有问题,那么就会显示
或者:
解决办法2:使用命令行,Win+R+cmd,进入到D:\Python27\Scripts,输入 easy_install NumPy, easy_install matplotlib,重新自动安装相关包,当显示finish时,就可以成功使用matplotlib功能了
指令运行过程中可能会卡在
耐心的等待…. (我没有等它运行完,所以未验证,仅作为备用方法)
备注一个留给自己的作业:当把中文的分词等方法加进去以后,试着分析一下每年的国情咨文讲话,分析一下最近这些年的不同
4 随机生成不同风格的文本
>>>text4.generate()
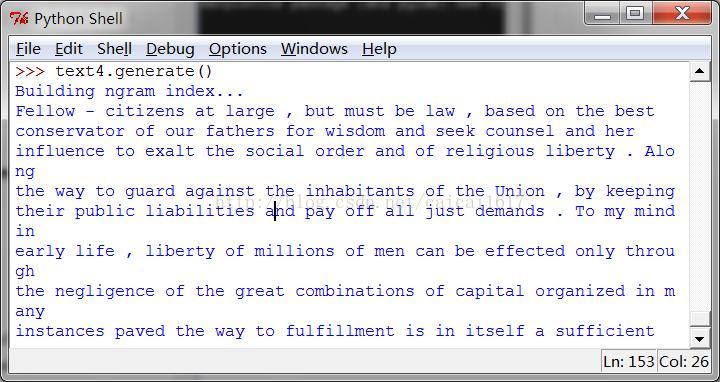
不得不说还是很make sense的,都是套话的堆砌。这个用来写公文应该还可以,反正也没人仔细看,写情书应该也行,就是被发现会比较惨。不知道这能不能看成是一个图灵测试的另一种演示,如果一个人无法分辨机器组织的语言和真正的人组织的语言,那么它的人的属性应该是值得怀疑的,或者说它被机器取代的可能性更大。
5 计数词汇
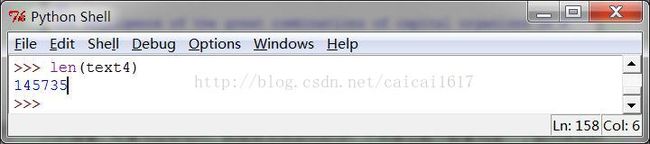
没必要解释。某些情况,如计算TFIDF的时候,会用的上。
6 简单操作
(1)>>> sorted(set(text3)) 得到text3的词表并且按照子母排序,符号也计算了放在最前面
(2) >>>len(set(text3))组合指令,实现随词表的计数
(3) 每个字平均被使用的次数
>>>from __future__ import division
>>>len(text3) / len(set(text3))
计数一个词在文本中出现的次数
>>>text3.count("smote")
计算一个特定的词在文本中占据的百分比
>>>100 * text4.count('a') / len(text4)
7 编写函数
单行的指令绝对不是我想要的,可重用的函数,可继承的类和可以良好运作的系统才是为啥学习的原因。
书中的简单函数,收拾一下写个类试了一试
#!/usr/python/bin
#Filename:nltk_test,计算每个词平均出现次数和某个文本中某个词的出现占该文本的百分比
from__future__ import division
importnltk
fromnltk.book import *
classNltkTest31:
def __init__(self,text):
self.text=text
print self.text
def lexical_diversity(self):
print len(self.text)
print len(set(self.text))
print len(self.text) /len(set(self.text))
return len(self.text) /len(set(self.text))
def percentage(self,str):
print self.text.count(str)
print len(self.text)
print 100 * self.text.count(str) /len(self.text)
return 100 * self.text.count(str) /len(self.text)
nt=NltkTest31(text4)
print'Average appears %f times' %nt.lexical_diversity()
print'\'the\'出现的次数占了%%%f'%nt.percentage('a')
Ctrl+F5果断出错了

这是因为没有指定字符编码集导致的问题,很简单解决(用的还是python自带的IDLE),在Options-Configure IDLE-General-Default Source Encoding 勾选UTF-8(这样用到Linux里面方便一点)。
然后就
这就算成了。
8 链表
>>>sent1 = ['Call', 'me', 'Ishmael', '.']
每句做成一个链表,这样如果需要对单句进行操作那就有福了,不过取数据的时候不能越界,所以还要用好len(sent1)。
>>>sent4 + sent1
Python的’+’实在是很方便,整数,数组,字符串随便加。
>>>text4[173]
根据位置找单词,在text4这个整个文章做成的连表里找到第173位置的单词,不过不预先处理标点符号啥的都算在内。
>>>text4.index('awaken')
根据词找首先出现的位置,也挺方便。
>>>text5[16715:16735]
切片,就是在链表中截取一段。
请注意,索引从零开始:第0 个元素写作 sent[0],其实是第 1 个词“word1”;而句子的第 9 个元素是“word10”。