论文笔记之PPDM(Parallel Point Detection and Matching for Real-time Human-Object Interaction Detection)
分为两分支,一个用于点(人、物、交互三个点)检测,一个用于点匹配,达到了实时的效果。
CVPR2020接收
论文地址:https://arxiv.org/pdf/1912.12898v1.pdf
1. 摘要
本文提出了一种一阶段人物交互(HOI)检测方法,该方法在单个Titan XP GPU上以37 fps的速度在HICO-DET数据集上优于现有的所有方法。这是第一种实时检测HOI的方法。
传统的HOI检测方法分为两个阶段,即人体目标proposal生成和proposal分类。它们的有效性和效率受到了体系结构的限制。本文提出了一种并行点检测与点匹配(PPDM)的HOI检测框架。在PPDM中,HOI被定义为一个点三元组<人的点,交互点,物体点>。人与物体点是检测box的中心,交互点是人与物体点的中心点。PPDM包含两个并行分支,即点检测分支和点匹配分支。点检测分支预测三个点。同时,点匹配分支预测从交互点到对应的人和物体点的两个位移。将来自同一交互点的人体点和物体点视为匹配对。在并行体系结构中,交互点隐含地为人体和物体检测提供上下文和正则化,抑制了无意义的HOI三个的孤立的检测框,提高了HOI检测的精度。
此外,人与物体检测框之间的匹配只适用于有限数量的过滤候选交互点,这样节省了大量的计算成本。
另外,作者建立了一个新的面向应用程序的数据库HOI-A,作为对现有数据集的一个很好的补充。
2. 相关工作
常规的HOI检测方法主要包括两个阶段:
- 第一阶段是人和物体proposal的生成。 预训练的检测器用于定位人和物体。然后,通过将过滤后的M个人体box和N个物体box成对地组合,生成M × N个人-物proposal。
- 第二阶段是proposal分类,它可以预测每个人-物proposal的交互类别。
当前的工作更加注重探索如何改善第二阶段。 最近的工作旨在通过捕获上下文信息或人类结构消息来了解HOI。一些方法将第二阶段表述为图推理问题,并使用图卷积网络来预测HOI。
两阶段方法的有效性和效率的局限性主要是因为它们的两个阶段是顺序的和分离的。 proposal生成阶段完全基于目标检测的置信度。人-物proposal是独立生成的, 没有考虑在第二阶段合并两个proposal以形成有意义的HOI三元组的可能性。因此,所生成的人-物proposal可能具有相对较低的质量。
此外,在第二阶段,所有的人-物proposal都需要进行线性扫描,而其中只有少数有效。 额外的计算成本很大。 因此,需要非顺序和高度耦合的框架。
3. 本文方法
3.1 总体结构

首先应用关键点热图预测网络,例如 Hourglass-104或DLA-34,以从图像中提取外观特征。
a)点检测分支:基于提取的视觉特征,利用三个卷积模块来预测交互点,人体中心点和物体中心点的热图。 另外,要生成最终框,所以对二维尺寸和局部偏移量进行回归。
b)点匹配分支:该分支的第一步是将位移从交互点分别回归到人点和物体点。 根据预测的点和位移,第二步是将每个交互点与人点和物体点进行匹配,以生成一组三元组。
3.2 点检测
(1)公式化表示:
点检测分支估计人体box,物体box和交互点。 人体box表示为它的中心点![]() ,相应的大小(宽度和高度)
,相应的大小(宽度和高度)![]() 以及局部点偏移
以及局部点偏移![]() ,以恢复由以下各项引起的离散化误差。 物体框的表示方式与此类似。
,以恢复由以下各项引起的离散化误差。 物体框的表示方式与此类似。
此外,将交互点![]() 定义为配对的人类点和物体点的中点。考虑到交互点的接受场足够大以包含人和物体,因此可以基于
定义为配对的人类点和物体点的中点。考虑到交互点的接受场足够大以包含人和物体,因此可以基于![]() 的特征来估计人的动作a。
的特征来估计人的动作a。
实际上,当数据集中有M个人时,每个人框都表示为![]() 。 为了描述方便,在不引起混淆的情况下,省略下标i。 类似的省略也适用于
。 为了描述方便,在不引起混淆的情况下,省略下标i。 类似的省略也适用于![]() 。
。
在图3中,将输入图像![]() 馈入特征提取器以生成特征
馈入特征提取器以生成特征![]() ,其中W和H是输入图像的宽度和高度,d是输出步幅。 点的热图是低分辨率的,因此还计算了低分辨率的中心点。 给定GT人体的点(xh; yh),相应的低分辨率点为
,其中W和H是输入图像的宽度和高度,d是输出步幅。 点的热图是低分辨率的,因此还计算了低分辨率的中心点。 给定GT人体的点(xh; yh),相应的低分辨率点为![]() 。 可以用相同的方法计算低分辨率的GT物体的点
。 可以用相同的方法计算低分辨率的GT物体的点![]() 。基于低分辨率的人和物体点,可以将地GT相互作用点定义为
。基于低分辨率的人和物体点,可以将地GT相互作用点定义为![]()
 。
。
(2)Point location loss
直接检测点很困难,因此作者采用关键点估计方法将点映射到具有高斯核的热图中。从而将点检测转换为热图估计任务。 将三个GT的低分辨率点(xh; yh),(xo; yo)和(xa; ya)映射到三个高斯热图中,包括人点热图![]()
![]() ,物体点热图
,物体点热图![]() 和相互作用点热图
和相互作用点热图![]() ,其中T是物体类别的数量,K是交互类别的数量。 请注意,在〜Co和〜Ca中,仅对应于特定物体类别和人类动作的通道为非零。 通过在特征图V上添加三个相应的卷积块来生成三个热图,每个卷积块由具有ReLU的3 × 3卷积层,随后的1 × 1卷积层和Sigmoid组成。
,其中T是物体类别的数量,K是交互类别的数量。 请注意,在〜Co和〜Ca中,仅对应于特定物体类别和人类动作的通道为非零。 通过在特征图V上添加三个相应的卷积块来生成三个热图,每个卷积块由具有ReLU的3 × 3卷积层,随后的1 × 1卷积层和Sigmoid组成。
对于这三个热图,都应用了逐元素的focal loss。 例如,给定一个估计的交互点热图^ C a和相应的地热图〜C a,损失函数为:
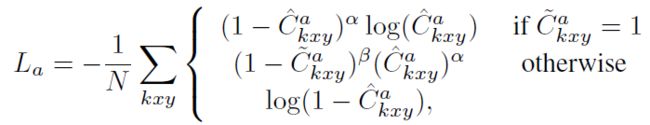
其中N等于图像中的交互点数(HOI三重态),^ Ca kxy是预测的热图中^ Ca中类别k在位置(x; y)的分数。 遵循[Cornernet: Detecting objects as
paired keypoints,Objects as points]中的默认设置,分别设置α为2,β为4。 人体点和物体点的损失Lp和Lo可以类似地计算。
(3)Size and offset loss
除了中心点,还需要box大小和中心点的局部偏移量,以形成人-物box。 将四个卷积块添加到特征图V中,以分别估计2D大小以及人和物体框的局部偏移。 每个块包含具有ReLU的3 × 3卷积层和1 × 1卷积层。
在训练期间,仅计算GT人点(〜xh;〜yh)和物体点(〜xo;〜yo)的每个位置的L1 loss,而忽略所有其他位置。 以局部偏移的损失函数为例,尺寸回归损失Lwh的定义与此类似。 定位于(〜xh;〜yh)的人类点的地面真实局部偏移量定义为 。
。
因此,损失函数Loff是人box loss: Lh off和物体box loss :Looff的总和:

其中〜Sh(〜So)表示训练集中的GT人(物)点集。 M = |〜Sh|和D = |〜So|是人体点和物体点的数量。 M不一定等于D。例如,一个人可能对应于多个动作和物体。 Lo off与 Lh off相似地定义。
3.3 点匹配
(1)公式化
点匹配分支通过使用交互点作为桥梁将人box与其对应的物体box配对。更具体地说,将交互点视为anchor, 估计了两个位移dah =(dah x; dah y)和dao =(dao x; dao y),即,交互点与人/物点之间的位移。 粗略的人类点和物体点分别是(xa; ya)加上dah和dao。
位移分支由两个卷积模块组成。 每个模块由带ReLU的3 × 3卷积层和1 × 1卷积层组成。主体和客体位移图的大小均为![]() 。
。
(2)Displacement loss
为了训练位移分支,对每个相互作用点应用L1 loss。 从位于(〜xa;〜ya)的交互点到相应人类点的GT位移可通过![]() 计算得到。 (〜xa;〜ya)位置的预测位移为
计算得到。 (〜xa;〜ya)位置的预测位移为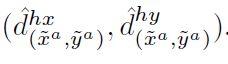 。
。
位移损失定义为:

其中〜Sa表示训练集中的GT交互点集。 N = |〜Sa|是交互点的数量。 从交互点到物体点的位移损失函数具有相同的形式。
(3)Triplet matching
考虑两个方面来判断人/物体点是否可以与交互点匹配。 人/物体需要:
1)接近由交互点加上位移生成的粗略的人/物体点;
2)具有较高的置信度。
在此基础上,对于检测到的交互点(^ xa; ^ ya),通过下面等式对检测到的人类点集^ Sh中的点进行排序,并选择最佳点:
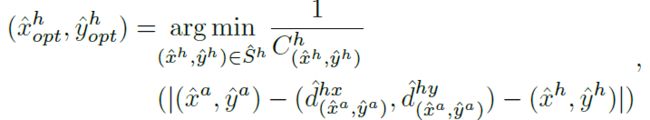
其中Ch(^ xh; ^ yh)表示人类点(^ xh; ^ yh)的置信度得分。 最佳物体框(^ xo opt; ^ yo opt)的计算方法类似。
3.4 损失函数及推理
最终损失可以通过对上述损失进行加权求和而得出:

将λ设为0.1。 La,Lh和Lo是点位置损失,Lah和Loh是位移损失,而Lwh和Loff是尺寸和偏移损失。
在推理过程中:
- 首先对预测的人,物体和交互点热图进行步幅为1的3 × 3 max-pooling操作,其作用与NMS类似。
- 其次,通过所有类别中相应的置信度得分^ Ch,^ Co和^ Ca选择前K个人类点^ Sh,物体中心点^ So和交互点^Sa。
- 然后,通过3.3中(3)中的等式找到每个选定交互点的主体点和客体点。对于每个匹配的人类点(^ xh opt; ^ yh opt),得到最后一个框为:
 ,其中:
,其中:
 是人类中心点的精确位置。
是人类中心点的精确位置。 是相应位置的框的大小。 最终的HOI检测结果是一组三元组,三元组的置信度得分为
是相应位置的框的大小。 最终的HOI检测结果是一组三元组,三元组的置信度得分为 。
。
3.5 HOI-A数据集
现有的数据集,例如HICO-Det和VCOCO,极大地促进了相关研究的发展。 但是,在实际应用中,需要特别注意的有限的频繁HOI类别在以前的数据集中并未强调。因此作者引入了一个新的数据集,称为HOI-A。

 如表1所示,作者选择实际应用中驱动的动词类别。 HOI-A数据集中的每种动词都有其相应的应用场景。
如表1所示,作者选择实际应用中驱动的动词类别。 HOI-A数据集中的每种动词都有其相应的应用场景。
4. 实验
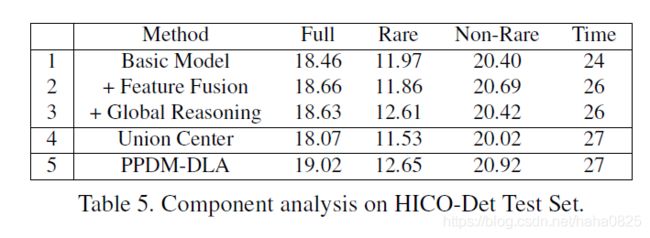
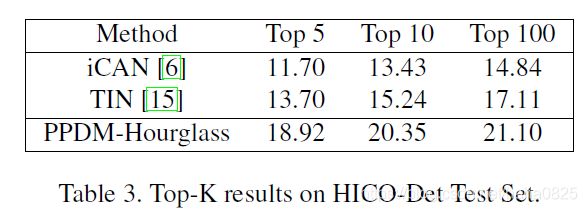
4.1 HICO-DET test set上的结果

“ A”,“ P”,“ S”,“ L”分别代表外观特征,人体姿势信息,空间特征和语言特征。
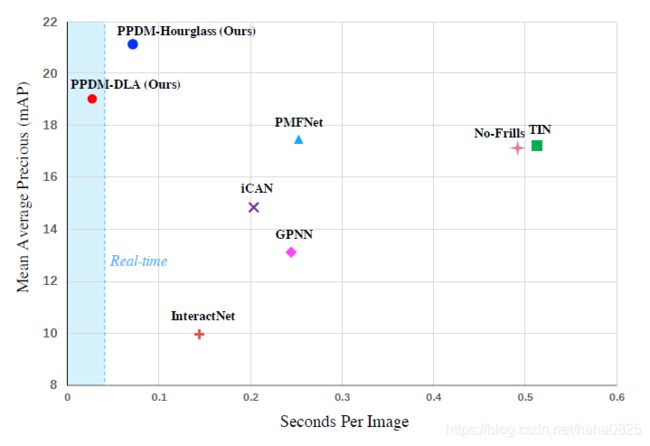
4.2 与SOTA相比
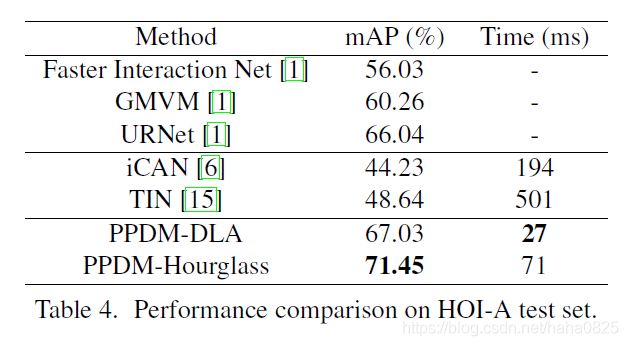
4.3 消融实验