caffe源码分析-Blob
本文主要分析caffe源码分析-Blob,主要如下几个方面:
-
overview整体上了解caffe的Blob
-
Blob 成员变量
-
Blob主要函数,核心在于Blob的使用实例以及其与opencvMat的操作的相互转化(附带运行结果基于CLion)
overview
Blob 是Caffe作为数据传输的媒介,无论是网络权重参数,还是输入数据,都是转化为Blob数据结构来存储,网络,求解器等都是直接与此结构打交道的。
其直观的可以把它看成一个有4维的结构体(包含数据和梯度),而实际上,它们只是一维的指针而已,其4维结构通过shape属性得以计算出来(根据C语言的数据顺序)。
Blob在也不一定全是4维的,例如全连接层的参数就没有用四维,后期的版本已经deprecated,而是直接用
vectorshape_
成员变量
Blob中的主要数据成员如下,实际是在SyncedMemory上做了一层包装(SyncedMemory介绍见上一篇blog):
protected:
shared_ptr data_; //存储前向传递数据
shared_ptr diff_; //存储反向传递梯度
shared_ptr shape_data_;// 参数维度old version
vector shape_; //参数维度
int count_; //Blob存储的元素个数(shape_所有元素乘积)
int capacity_;//当前Blob的元素个数(控制动态分配)
主要函数
主要分析如下几类函数:
-
构造函数, 以及Reshape函数()
-
索引、返回N、C、H、W相关函数
-
gpu、cpu同步函数, 以及数据的获取
-
简单的数据处理如scale_data对数据缩放(底层调用了cblas库的运算)
-
Blob的示例,数据赋值以及和opencv Mat的操作
-
Blob对应的protobuf结构体BlobShape、BlobProto、BlobProtoVector
1. 构造函数, 以及Reshape函数()
构造函数分类两种类型:
-
默认的什么参数
-
传入N、C、H、W构造,最终调用Reshape函数
Blob() //构造函数:初始化列表 {空函数体}
: data_(), diff_(), count_(0), capacity_(0) {}
// @brief Deprecated; use Blob(const vector& shape) .
explicit Blob(const int num, const int channels, const int height,
const int width); //可以通过设置数据维度(N,C,H,W)初始化
// 也可以通过传入vector直接传入维数
explicit Blob(const vector& shape);
Blob() //构造函数:初始化列表 {空函数体}
: data_(), diff_(), count_(0), capacity_(0) {}
// @brief Deprecated; use Blob(const vector& shape) .
explicit Blob(const int num, const int channels, const int height,
const int width); //可以通过设置数据维度(N,C,H,W)初始化
// 也可以通过传入vector直接传入维数
explicit Blob(const vector& shape);
下面重点看下Reshape函数
template
void Blob::Reshape(const int num, const int channels, const int height,
const int width) {
vector shape(4);
shape[0] = num;
shape[1] = channels;
shape[2] = height;
shape[3] = width;
Reshape(shape);
}
// 完成blob形状shape_的记录,大小count_的计算,合适大小capacity_存储的申请
template
void Blob::Reshape(const vector& shape) {
CHECK_LE(shape.size(), kMaxBlobAxes);
count_ = 1;
shape_.resize(shape.size());
if (!shape_data_ || shape_data_->size() < shape.size() * sizeof(int)) {
shape_data_.reset(new SyncedMemory(shape.size() * sizeof(int)));
}
int* shape_data = static_cast(shape_data_->mutable_cpu_data());
for (int i = 0; i < shape.size(); ++i) {
CHECK_GE(shape[i], 0);
CHECK_LE(shape[i], INT_MAX / count_) << "blob size exceeds INT_MAX";
count_ *= shape[i];
shape_[i] = shape[i];
shape_data[i] = shape[i];
}
if (count_ > capacity_) {
capacity_ = count_;
// 只是构造了SyncedMemory对象,并未真正分配内存和显存
data_.reset(new SyncedMemory(capacity_ * sizeof(Dtype)));
// 真正分配是在第一次访问数据时
diff_.reset(new SyncedMemory(capacity_ * sizeof(Dtype)));
}
}
上面注意的是:shape_data_是历史版本的shape, new SyncedMemory(shape.size() * sizeof(int))并不分配实际的内存。shape_data_->mutable_cpu_data()获取实际的data,如果没有分配内存则分配。
void* SyncedMemory::mutable_cpu_data() {
to_cpu();
head_ = HEAD_AT_CPU;
return cpu_ptr_;
}
mutable_cpu_data,根据head_的枚举状态判断是否已经分配了内存。
注:Reshape函数除了被构造函数调用外,也常常作为一般的函数调用,例如对网络的输入的改变:
net_24.blobs['data'].reshape(10, 3, 24, 24)
2. 索引、返回N、C、H、W相关函数
/// @brief Deprecated legacy shape accessor num: use shape(0) instead.
inline int num() const { return LegacyShape(0); }
/// @brief Deprecated legacy shape accessor channels: use shape(1) instead.
inline int channels() const { return LegacyShape(1); }
/// @brief Deprecated legacy shape accessor height: use shape(2) instead.
inline int height() const { return LegacyShape(2); }
/// @brief Deprecated legacy shape accessor width: use shape(3) instead.
inline int width() const { return LegacyShape(3); }
//计算物理偏移量,(n,c,h,w)的偏移量为((n∗C+c)∗H+h)∗W+w
inline int offset(const int n, const int c = 0, const int h = 0,
const int w = 0) const {
CHECK_GE(n, 0);
CHECK_LE(n, num());
CHECK_GE(channels(), 0);
CHECK_LE(c, channels());
CHECK_GE(height(), 0);
CHECK_LE(h, height());
CHECK_GE(width(), 0);
CHECK_LE(w, width());
return ((n * channels() + c) * height() + h) * width() + w;
}
计数 :
//返回Blob维度数,对于维数(N,C,H,W),返回N×C×H×W
inline int count() const { return count_; }
//对于维数(N,C,H,W),count(0, 3)返回N×C×H
inline int count(int start_axis, int end_axis) const {
CHECK_LE(start_axis, end_axis);
CHECK_GE(start_axis, 0);
CHECK_GE(end_axis, 0);
CHECK_LE(start_axis, num_axes());
CHECK_LE(end_axis, num_axes());
int count = 1;
for (int i = start_axis; i < end_axis; ++i) {
count *= shape(i);
}
return count;
}
3. gpu、cpu同步函数, 以及数据的获取
首先给出一个ReLULayer的前馈函数的示例(里面用到了Blob两个函数cpu_data, mutable_cpu_data一个获取可变的数据,一个不可变。)
template
void ReLULayer::Forward_cpu(const vector*>& bottom,
const vector*>& top) {
// bottom_data don’t change
const Dtype* bottom_data = bottom[0]->cpu_data();
// top_data will change
Dtype* top_data = top[0]->mutable_cpu_data();
const int count = bottom[0]->count();
Dtype negative_slope = this->layer_param_.relu_param().negative_slope();
for (int i = 0; i < count; ++i) {
top_data[i] = std::max(bottom_data[i], Dtype(0))
+ negative_slope * std::min(bottom_data[i], Dtype(0));
}
}
// 调用SyncedMemory的数据访问函数cpu_data(),并返回内存指针
template
const Dtype* Blob::cpu_data() const {
CHECK(data_);
return (const Dtype*)data_->cpu_data();
}
template
Dtype* Blob::mutable_cpu_data() {
CHECK(data_);
return static_cast(data_->mutable_cpu_data());
}
下面给出一些简单的示例:
// 假定数据在 CPU 上进行初始化,我们有一个 blob
const Dtype* foo;
Dtype* bar;
foo = blob.gpu_data(); // 数据从 CPU 复制到 GPU
foo = blob.cpu_data(); // 没有数据复制,两者都有最新的内容
bar = blob.mutable_gpu_data(); // 没有数据复制
// ... 一些操作 ...
bar = blob.mutable_gpu_data(); // 仍在 GPU,没有数据复制
foo = blob.cpu_data(); // 由于 GPU 修改了数值,数据从 GPU 复制到 CPU
foo = blob.gpu_data(); //没有数据复制,两者都有最新的内容
bar = blob.mutable_cpu_data(); // 依旧没有数据复制
bar = blob.mutable_gpu_data(); //数据从 CPU 复制到 GPU
bar = blob.mutable_cpu_data(); //数据从 GPU 复制到 CPU
4. 简单的数据处理如scale_data对数据缩放(底层调用了cblas库的运算)
下面简单看下scale_data对data_乘上某个因子(主要是cpu的实现):
data = mutable_cpu_data();//获取可变的CPU数据
caffe_scal(count_, scale_factor, data);//根据个数count_对data scale
template
void Blob::scale_data(Dtype scale_factor) { //对data_乘上某个因子
Dtype* data;
if (!data_) { return; }
switch (data_->head()) {
case SyncedMemory::HEAD_AT_CPU:
data = mutable_cpu_data();
caffe_scal(count_, scale_factor, data);
return;
case SyncedMemory::HEAD_AT_GPU:
case SyncedMemory::SYNCED:
// caffe_gpu_scal(count_, scale_factor, data);
return;
#else
NO_GPU;
#endif
case SyncedMemory::UNINITIALIZED:
return;
default:
LOG(FATAL) << "Unknown SyncedMemory head state: " << data_->head();
}
}
caffe_scal底层调用的是cblas的cblas_sscal函数(此处用了模板的特化):
template <>
void caffe_scal(const int N, const float alpha, float *X) {
cblas_sscal(N, alpha, X, 1);
}
最后注意下Blob的显示模板实例化:int,unsigned int,float,double:
INSTANTIATE_CLASS(Blob);
template class Blob;
template class Blob;
// Instantiate a class with float and double specifications.
#define INSTANTIATE_CLASS(classname) \
char gInstantiationGuard##classname; \
template class classname; \
template class classname
Blob无法被copy以及赋值:
DISABLE_COPY_AND_ASSIGN(Blob);
// Disable the copy and assignment operator for a class.
#define DISABLE_COPY_AND_ASSIGN(classname) \
private:\
classname(const classname&);\
classname& operator=(const classname&)
5. Blob的示例,数据赋值以及和opencv Mat的操作
简单的Blob赋值示例如下:
// create Blob with (N, C, H, W) -> (1, 2, 3, 4)
std::vector vecShape{1, 2, 3, 4};
caffe::Blob b(vecShape);
// fill Blob with sequence
float* pf = b.mutable_cpu_data();
std::iota(pf, pf + 24, 0.0);
// output all the sequence in Blob
for (int i = 0; i < b.count(); ++i) {
std::cout << *(pf + i)<<" ";
} //0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
std::cout< 运行结果输出如下:

接下来给出一个示例:
-
使用opencv Mat创建一个白色的图片,然后将Mat转化为Blob
-
使用Blob操作在图片中间画一条黑线,最后将Blob转化为opencv的Mat
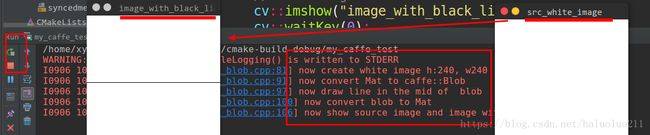
void test_blob_2(){
LOG(INFO) << "now create white image h:240, w240 ";
// create white image and show it
cv::Mat img(240, 240, CV_8UC3, cv::Scalar(255, 255, 255));
cv::imshow("src_white_image", img);
//convert it to float
img.convertTo(img, CV_32FC3);
LOG(INFO) <<"now convert Mat to caffe::Blob";
// create Blob and convert mat to blob
caffe::Blob blob;
mat2Blob(img, blob);
LOG(INFO) <<"now draw line in the mid of blob";
drawMidLine(blob);
LOG(INFO) <<"now convert blob to Mat";
blob2Mat(blob, img);
//convert it to CV_8UC3
img.convertTo(img, CV_8UC3);
LOG(INFO) <<"now show source image and image with white line";
// show image
cv::imshow("image_with_black_line", img);
cv::waitKey(0);
}
运行结果如下:
转换函数如下:
void mat2Blob(const cv::Mat& mat, caffe::Blob& blob){
std::vector vecMat;
blob.Reshape(1, mat.channels(), mat.rows, mat.cols);
int width = blob.width();
int height = blob.height();
float* input_data = blob.mutable_cpu_data();
for (int i = 0; i < blob.channels(); ++i) {
cv::Mat channel(height, width, CV_32FC1, input_data);
vecMat.push_back(channel);
input_data += width * height;
}
cv::split(mat, vecMat);
}
void blob2Mat(const caffe::Blob& blob, cv::Mat& mat){
for (int c = 0; c < blob.channels(); ++c) {
for (int h = 0; h < blob.height(); ++h) {
for (int w = 0; w < blob.width(); ++w) {
mat.at(h, w)[c] = blob.data_at(0, c, h, w);
}
}
}
}
void drawMidLine(caffe::Blob &blob){
float* data = blob.mutable_cpu_data();
// draw black line in the image
for (int c = 0; c < blob.channels(); ++c) {
for (int j = 0; j < blob.width(); ++j) {
*(data + blob.offset(0, c, blob.height() / 2, j)) = 0;
}
}
}
Blob不仅仅限于(N, C, H, W)四维的数据,还可以定义一维的(如在全连接层inner_product_layer中的bias_multiplier_就是一维的),示例如下:
const int N = 8;
vector shape(1, N); // two dimension shape
caffe::Blob blob;
blob.Reshape(shape);
cout< 6. Blob对应的protobuf结构体
shape结构体:
message BlobShape {
repeated int64 dim = 1 [packed = true];
}
Blob结构体BlobProto:
message BlobProto {
optional BlobShape shape = 7;
repeated float data = 5 [packed = true];
repeated float diff = 6 [packed = true];
repeated double double_data = 8 [packed = true];
repeated double double_diff = 9 [packed = true];
// 4D dimensions -- deprecated. Use "shape" instead.
optional int32 num = 1 [default = 0];
optional int32 channels = 2 [default = 0];
optional int32 height = 3 [default = 0];
optional int32 width = 4 [default = 0];
}
注意的是:BlobProto中定义了float,double两种data(data,double_data),这在Blob中的ToProto函数(blob数据序列化保存到proto),定义了两个模板特化:
//blob数据保存到proto中
void ToProto(BlobProto* proto, bool write_diff = false) const;
其中double特化如下:
template<>
void Blob::ToProto(BlobProto *proto, bool write_diff) const {
proto->clear_shape();
for (int i = 0; i < shape_.size(); ++i) {
proto->mutable_shape()->add_dim(shape_[i]);
}
proto->clear_double_data();
proto->clear_double_diff();
const double* data_vec = cpu_data();
for (int i = 0; i < count_; ++i) {
proto->add_double_data(data_vec[i]);
}
if (write_diff) {
const double* diff_vec = cpu_diff();
for (int i = 0; i < count_; ++i) {
proto->add_double_diff(diff_vec[i]);
}
}
}
float类型同理:
// 模板特化float
template<>
void Blob::ToProto(BlobProto* proto, bool write_diff = false) const{
//...
proto->clear_data();
proto->clear_diff();
//......
}
caffe系列源码分析介绍
本系列深度学习框架caffe 源码分析主要内容如下:
1. caffe源码分析-cmake 工程构建:
caffe源码分析-cmake 工程构建主要内容:
自己从头构建一遍工程,这样能让我更好的了解大型的项目的构建。当然原始的caffe的构建感觉还是比较复杂(主要是cmake),我这里仅仅使用cmake构建,而且简化点,当然最重要的是支持CLion直接运行调试(如果需要这个工程可以评论留下你的邮箱,我给你发送过去)。

2. caffe的数据内存分配类SyncedMemory, 以及类Blob数据传输的媒介.
主要内容:
caffe源码分析-SyncedMemory
caffe源码分析-Blob
其中Blob分析给出了其直接与opencv的图片相互转化以及操作,可以使得我们更好的理解Blob.
3. caffe layer的源码分析,包括从整体上说明了layer类别以及其proto定义与核心函数.
内容如下:
caffe源码分析-layer
caffe源码分析-ReLULayer
caffe源码分析-inner_product_layer
caffe源码分析-layer_factory
首先分析了最简单的layer Relu,然后在是inner_product_layer全连接层, 最后是layer_factorycaffe中 以此工厂模式create各种Layer.
4. 数据输入层,主要是多线程+BlockingQueue的方式读取数据训练:
内容如下:
caffe源码分析-BlockingQueue
caffe源码分析-InternalThread
caffe源码分析-DataReader
5. IO处理例如读取proto文件转化为网络,以及网络参数的序列化
内容如下:
caffe源码分析-DataTransformer
caffe源码分析-db, io
6. 最后给出了使用纯C++结合多层感知机网络训练mnist的示例
内容如下:
caffe c++示例(mnist 多层感知机c++训练,测试)
类似与caffe一样按照layer、solver、loss、net等模块构建的神经网络实现可以见下面这篇blog,相信看懂了这个python的代码理解caffe框架会更简单点.
神经网络python实现
最后如果需要cmake + CLion直接运行调试caffe的代码工程,可以评论留下你的邮箱,我给你发送过去.