Pandas进阶
文章目录
- 1 文件读取与储存
- CSV
- HTML
- 2.缺失值处理
- 2.1 如何处理nan
- 缺失值处理
- 2.2 不是缺失值nan,有默认标记的如一些特殊符号
- 3. 数据的离散化
- 3.1 如何实现数据的离散化
- 3.2 案例:股票的涨跌幅离散化
- 4. 高级处理-合并
- Pandas综合案例
- 1.准备数据
- 2. **需求1**
- 3. **需求2**
- 4.**需求3**
1 文件读取与储存
- csv(Comma-Separated values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号)是纯文本形式存储表格数据,既可以用记事本打开,也可以用EXCEL打开。CSV文件由任意数目的记录组成,记录间以换行符分隔;每条记录由字段组成,字段间的分隔符一般是逗号或制表符
- json是轻量级的数据交换格式,完全独立于编程语言的文本格式来存储和表示数据,特点是简洁和清晰的层次结构.json是轻量级的?这是因为json不管是编写,还是解析都很高效,而且在传输过程中采用了压缩技术,更加的节省带宽·
- 我们对HTML并不陌生,它是超文本标记语言(Hyper Text Markup Language)
- EXCEL就不介绍了,大家都很熟悉
- pickle相对就没那么眼熟了,pickle其实是个模块,模块中的序列化过程将文本信息转变为二进制数据流。这样就信息就容易存储在硬盘之中,而不是像将数据放入内存中那样关机断电就会丢失数据。 相反的,其反序列化便可以得到原始的数据
- CSV
pd.read_csv(path)
usecols=
names=
dataframe.to_csv(path)
columns=[]
index=False
header=False
- HDF5
hdf5 存储 3维数据的文件
key1 dataframe1二维数据
key2 dataframe2二维数据
pd.read_hdf(path, key=)
df.to_hdf(path, key=)
- JSON
pd.read_json(path)
orient="records"
lines=True
df.to_json(patn)
orient="records"
lines=True
在表格的Reader和Writer两列包含了对各种数据形式的读写函数
对于读,统一都是以read加下划线加需要读取的数据形式
对于写,统一都是以to加下划线加需要写入的数据形式

CSV
注:需要人为手动设置列索引
data = pd.read_csv("stock_day2.csv", names=["open", "high", "close", "low", "volume", "price_change", "p_change", "ma5", "ma10", "ma20", "v_ma5", "v_ma10", "v_ma20", "turnover"])
data[:10]
| open | high | close | low | volume | price_change | p_change | ma5 | ma10 | ma20 | v_ma5 | v_ma10 | v_ma20 | turnover | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2018-02-27 | 23.53 | 25.88 | 24.16 | 23.53 | 95578.03 | 0.63 | 2.68 | 22.942 | 22.142 | 22.875 | 53782.64 | 46738.65 | 55576.11 | 2.39 |
| 2018-02-26 | 22.80 | 23.78 | 23.53 | 22.80 | 60985.11 | 0.69 | 3.02 | 22.406 | 21.955 | 22.942 | 40827.52 | 42736.34 | 56007.50 | 1.53 |
| 2018-02-23 | 22.88 | 23.37 | 22.82 | 22.71 | 52914.01 | 0.54 | 2.42 | 21.938 | 21.929 | 23.022 | 35119.58 | 41871.97 | 56372.85 | 1.32 |
| 2018-02-22 | 22.25 | 22.76 | 22.28 | 22.02 | 36105.01 | 0.36 | 1.64 | 21.446 | 21.909 | 23.137 | 35397.58 | 39904.78 | 60149.60 | 0.90 |
| 2018-02-14 | 21.49 | 21.99 | 21.92 | 21.48 | 23331.04 | 0.44 | 2.05 | 21.366 | 21.923 | 23.253 | 33590.21 | 42935.74 | 61716.11 | 0.58 |
| 2018-02-13 | 21.40 | 21.90 | 21.48 | 21.31 | 30802.45 | 0.28 | 1.32 | 21.342 | 22.103 | 23.387 | 39694.65 | 45518.14 | 65161.68 | 0.77 |
| 2018-02-12 | 20.70 | 21.40 | 21.19 | 20.63 | 32445.39 | 0.82 | 4.03 | 21.504 | 22.338 | 23.533 | 44645.16 | 45679.94 | 68686.33 | 0.81 |
| 2018-02-09 | 21.20 | 21.46 | 20.36 | 20.19 | 54304.01 | -1.50 | -6.86 | 21.920 | 22.596 | 23.645 | 48624.36 | 48982.38 | 70552.47 | 1.36 |
| 2018-02-08 | 21.79 | 22.09 | 21.88 | 21.75 | 27068.16 | 0.09 | 0.41 | 22.372 | 23.009 | 23.839 | 44411.98 | 48612.16 | 73852.45 | 0.68 |
| 2018-02-07 | 22.69 | 23.11 | 21.80 | 21.29 | 53853.25 | -0.50 | -2.24 | 22.480 | 23.258 | 23.929 | 52281.28 | 56315.11 | 74925.33 | 1.35 |
# 保存'open'列的数据
data[:10].to_csv("test.csv", columns=["open"])
#不保存行索引
data[:10].to_csv("test.csv", columns=["open"],index = False)
path =r' D:\course \bike hour.csv'
res =pd.read_csv(path)
res
记得在Python转义符’’\”,在windows下的目录字符串中通常有斜杠,而斜杠在 Python的字符串中有转义的作用。如果我们不告诉Python这个斜杠不是转义符,它就会把\b”理解是退格(ASCII码值为008x为十六进制),所以我们需要在路径前加上”r”告诉Python保持字符串原始值
HTML
read_html 作用快速获取在html中页面table格式数据
url ='https://www.fdic.gov/bank/individual/failed/banklist.html'
res2=pd.read_html(url)
res2
我们可以看到read_html把网页上的表格型数据解析为一个列表。其中表示列标签换行用to_html可以看到table类型的表格网页结构
df = pd.DataFrame(np.random.rand(2,2))
df
| 0 | 1 | |
|---|---|---|
| 0 | 0.099625 | 0.445910 |
| 1 | 0.500740 | 0.461739 |
print(df.to_html())
0
1
0
0.099625
0.445910
1
0.500740
0.461739
2.缺失值处理
处理类型一般有两种:
- 删除含有缺失值的样本(多)
- 替换/插补(少)
2.1 如何处理nan
一般分为两步
-
判断数据中是否存在NaN
pd.isnull(df) 有缺失返回True pd.notnull(df) -
删除含有缺失值的样本
df.dropna(inplace=False) 替换/插补 df.fillna(value, inplace=False)
import pandas as pd
import numpy as np
movie = pd.read_csv("./IMDB-Movie-Data.csv")
movie
| Rank | Title | Genre | Description | Director | Actors | Year | Runtime (Minutes) | Rating | Votes | Revenue (Millions) | Metascore | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | Guardians of the Galaxy | Action,Adventure,Sci-Fi | A group of intergalactic criminals are forced … | James Gunn | Chris Pratt, Vin Diesel, Bradley Cooper, Zoe S… | 2014 | 121 | 8.1 | 757074 | 333.13 | 76.0 |
| 1 | 2 | Prometheus | Adventure,Mystery,Sci-Fi | Following clues to the origin of mankind, a te… | Ridley Scott | Noomi Rapace, Logan Marshall-Green, Michael Fa… | 2012 | 124 | 7.0 | 485820 | 126.46 | 65.0 |
| 2 | 3 | Split | Horror,Thriller | Three girls are kidnapped by a man with a diag… | M. Night Shyamalan | James McAvoy, Anya Taylor-Joy, Haley Lu Richar… | 2016 | 117 | 7.3 | 157606 | 138.12 | 62.0 |
| 3 | 4 | Sing | Animation,Comedy,Family | In a city of humanoid animals, a hustling thea… | Christophe Lourdelet | Matthew McConaughey,Reese Witherspoon, Seth Ma… | 2016 | 108 | 7.2 | 60545 | 270.32 | 59.0 |
pd.isnull(movie)
| Rank | Title | Genre | Description | Director | Actors | Year | Runtime (Minutes) | Rating | Votes | Revenue (Millions) | Metascore | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | False | False | False | False | False | False | False | False | False | False | False |
| 1 | False | False | False | False | False | False | False | False | False | False | False | False |
| 2 | False | False | False | False | False | False | False | False | False | False | False | False |
| 3 | False | False | False | False | False | False | False | False | False | False | False | False |
| 4 | False | False | False | False | False | False | False | False | False | False | False | False |
| 5 | False | False | False | False | False | False | False | False | False | False | False | False |
| 6 | False | False | False | False | False | False | False | False | False | False | False | False |
| 7 | False | False | False | False | False | False | False | False | False | False | True | False |
缺失值处理
#说明存在一个以上缺失值
np.any( pd.isnull(movie) )
True
pd.isnull(movie).any() # 检查每个字段是否存在缺失值
Rank False
Title False
Genre False
Description False
Director False
Actors False
Year False
Runtime (Minutes) False
Rating False
Votes False
Revenue (Millions) True
Metascore True
dtype: bool
方法1:删除含有缺失值的样本 返回一个新的
data1 = movie.dropna()
pd.isnull(data1).any() # 结果表明不存在缺失值
Rank False
Title False
Genre False
Description False
Director False
Actors False
Year False
Runtime (Minutes) False
Rating False
Votes False
Revenue (Millions) False
Metascore False
dtype: bool
方法2:含有缺失值的字段——填补均值 在原始表中修改
# Revenue (Millions)
# Metascore
movie["Revenue (Millions)"].fillna(movie["Revenue (Millions)"].mean(), inplace=True)
movie["Metascore"].fillna(movie["Metascore"].mean(), inplace=True)
pd.isnull(movie).any()
Rank False
Title False
Genre False
Description False
Director False
Actors False
Year False
Runtime (Minutes) False
Rating False
Votes False
Revenue (Millions) False
Metascore False
dtype: bool
2.2 不是缺失值nan,有默认标记的如一些特殊符号
-
现将需要处理的符号替换 -> np.nan
df.replace(to_replace="?", value=np.nan) -
处理np.nan缺失值的步骤
# 现将符号转换成nan
data_new =data.replace(to_replace="?",value=np.nan)
# 再将nan删除
data_new.dropna(inplace=True)
data_new.isnull().any()
Sample code number False
Clump Thickness False
Uniformity of Cell Size False
Uniformity of Cell Shape False
Marginal Adhesion False
Single Epithelial Cell Size False
Bare Nuclei False
Bland Chromatin False
Normal Nucleoli False
Mitoses False
Class False
dtype: bool
3. 数据的离散化
3.1 如何实现数据的离散化
-
分组
自动分组sr=pd.qcut(data, bins) 自定义分组sr=pd.cut(data, []) -
将分组好的结果转换成one-hot编码
pd.get_dummies(sr, prefix=)
1)准备数据
data = pd.Series([165,174,160,180,159,163,192,184], index=['No1:165', 'No2:174','No3:160', 'No4:180', 'No5:159', 'No6:163', 'No7:192', 'No8:184'])
2)分组
自动分组 使用qcut分为3组
sr = pd.qcut(data, 3)
type(sr)
pandas.core.series.Series
查看每组数量
sr.value_counts()
(178.0, 192.0] 3
(158.999, 163.667] 3
(163.667, 178.0] 2
dtype: int64
3)转换成one-hot编码
pd.get_dummies(sr,prefix="height")#前缀
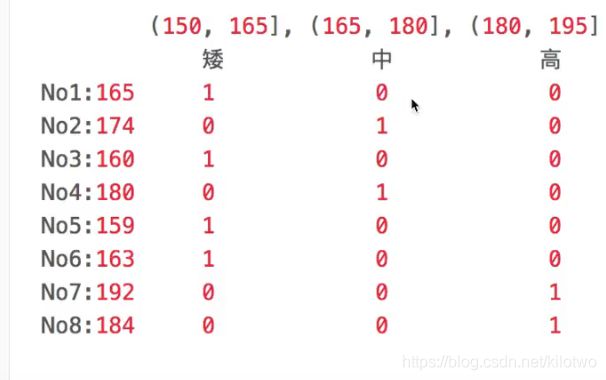
自定义分组
除了自动分组外,也可以人为设置区间来分组
bins = [150, 165, 180, 195]
sr = pd.cut(data, bins)
pd.get_dummies(sr,prefix="height")
sr.value_counts()
(150, 165] 4
(180, 195] 2
(165, 180] 2
dtype: int64
3.2 案例:股票的涨跌幅离散化
stock = pd.read_csv("stock_day.csv")
change = stock["p_change"]
2018-02-27 2.68
2018-02-26 3.02
2018-02-23 2.42
2018-02-22 1.64
2018-02-14 2.05
2018-02-13 1.32
2018-02-12 4.03
2018-02-09 -6.86
2018-02-08 0.41
2018-02-07 -2.24
2018-02-06 -4.17
2018-02-05 2.87
2018-02-02 0.89
2018-02-01 -5.48
2018-01-31 -0.46
2018-01-30 0.21
change_ = pd.qcut(change,10)
pd.get_dummies(change_,prefix="change")
| change_(-10.030999999999999, -4.836] | change_(-4.836, -2.444] | change_(-2.444, -1.352] | change_(-1.352, -0.462] | change_(-0.462, 0.26] | change_(0.26, 0.94] | change_(0.94, 1.738] | change_(1.738, 2.938] | change_(2.938, 5.27] | change_(5.27, 10.03] | |
|---|---|---|---|---|---|---|---|---|---|---|
| 2018-02-27 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 2018-02-26 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 2018-02-23 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 2018-02-22 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
可以看出自动分组效果并不理想
change_.value_counts()
(5.27, 10.03] 65
(0.26, 0.94] 65
(-0.462, 0.26] 65
(-10.030999999999999, -4.836] 65
(2.938, 5.27] 64
(1.738, 2.938] 64
(-1.352, -0.462] 64
(-2.444, -1.352] 64
(-4.836, -2.444] 64
(0.94, 1.738] 63
Name: p_change, dtype: int64
手动分组离散化
bins = [-100, -7, -5, -3, 0, 3, 5, 7, 100]
change2 = pd.cut(change,bins)
change2.value_counts()
(0, 3] 215
(-3, 0] 188
(3, 5] 57
(-5, -3] 51
(7, 100] 35
(5, 7] 35
(-100, -7] 34
(-7, -5] 28
Name: p_change, dtype: int64
lisan = pd.get_dummies(change2,prefix="涨跌幅").head()
| 涨跌幅_(-100, -7] | 涨跌幅_(-7, -5] | 涨跌幅_(-5, -3] | 涨跌幅_(-3, 0] | 涨跌幅_(0, 3] | 涨跌幅_(3, 5] | 涨跌幅_(5, 7] | 涨跌幅_(7, 100] | |
|---|---|---|---|---|---|---|---|---|
| 2018-02-27 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 2018-02-26 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 2018-02-23 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 2018-02-22 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 2018-02-14 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
4. 高级处理-合并
-
np.concatnate((a, b), axis=)
-
水平拼接 np.hstack()
-
竖直拼接 np.vstack()
-
按方向拼接 pd.concat([data1, data2], axis=1)
-
按索引拼接
pd.merge实现合并 pd.merge(left, right, how="inner", on=[索引])
stock.head()
| open | high | close | low | volume | price_change | p_change | ma5 | ma10 | ma20 | v_ma5 | v_ma10 | v_ma20 | turnover | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2018-02-27 | 23.53 | 25.88 | 24.16 | 23.53 | 95578.03 | 0.63 | 2.68 | 22.942 | 22.142 | 22.875 | 53782.64 | 46738.65 | 55576.11 | 2.39 |
| 2018-02-26 | 22.80 | 23.78 | 23.53 | 22.80 | 60985.11 | 0.69 | 3.02 | 22.406 | 21.955 | 22.942 | 40827.52 | 42736.34 | 56007.50 | 1.53 |
| 2018-02-23 | 22.88 | 23.37 | 22.82 | 22.71 | 52914.01 | 0.54 | 2.42 | 21.938 | 21.929 | 23.022 | 35119.58 | 41871.97 | 56372.85 | 1.32 |
| 2018-02-22 | 22.25 | 22.76 | 22.28 | 22.02 | 36105.01 | 0.36 | 1.64 | 21.446 | 21.909 | 23.137 | 35397.58 | 39904.78 | 60149.60 | 0.90 |
| 2018-02-14 | 21.49 | 21.99 | 21.92 | 21.48 | 23331.04 | 0.44 | 2.05 | 21.366 | 21.923 | 23.253 | 33590.21 | 42935.74 | 61716.11 | 0.58 |
lisan
| 涨跌幅_(-100, -7] | 涨跌幅_(-7, -5] | 涨跌幅_(-5, -3] | 涨跌幅_(-3, 0] | 涨跌幅_(0, 3] | 涨跌幅_(3, 5] | 涨跌幅_(5, 7] | 涨跌幅_(7, 100] | |
|---|---|---|---|---|---|---|---|---|
| 2018-02-27 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 2018-02-26 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 2018-02-23 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 2018-02-22 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 2018-02-14 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
#水平拼接
pd.concat([stock,change],axis=1)
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
#水平拼接
pd.concat([left,right],axis=1)
| key1 | key2 | A | B | key1 | key2 | C | D | |
|---|---|---|---|---|---|---|---|---|
| 0 | K0 | K0 | A0 | B0 | K0 | K0 | C0 | D0 |
| 1 | K0 | K1 | A1 | B1 | K1 | K0 | C1 | D1 |
| 2 | K1 | K0 | A2 | B2 | K1 | K0 | C2 | D2 |
| 3 | K2 | K1 | A3 | B3 | K2 | K0 | C3 | D3 |
Pandas综合案例
1.准备数据
movie = pd.read_csv("IMDB-Movie-Data.csv")
movie
| Rank | Title | Genre | Description | Director | Actors | Year | Runtime (Minutes) | Rating | Votes | Revenue (Millions) | Metascore | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | Guardians of the Galaxy | Action,Adventure,Sci-Fi | A group of intergalactic criminals are forced … | James Gunn | Chris Pratt, Vin Diesel, Bradley Cooper, Zoe S… | 2014 | 121 | 8.1 | 757074 | 333.13 | 76.0 |
| 1 | 2 | Prometheus | Adventure,Mystery,Sci-Fi | Following clues to the origin of mankind, a te… | Ridley Scott | Noomi Rapace, Logan Marshall-Green, Michael Fa… | 2012 | 124 | 7.0 | 485820 | 126.46 | 65.0 |
| 2 | 3 | Split | Horror,Thriller | Three girls are kidnapped by a man with a diag… | M. Night Shyamalan | James McAvoy, Anya Taylor-Joy, Haley Lu Richar… | 2016 | 117 | 7.3 | 157606 | 138.12 | 62.0 |
| 3 | 4 | Sing | Animation,Comedy,Family | In a city of humanoid animals, a hustling thea… | Christophe Lourdelet | Matthew McConaughey,Reese Witherspoon, Seth Ma… | 2016 | 108 | 7.2 | 60545 | 270.32 | 59.0 |
2. 需求1
想知道这些电影数据中评分的平均分,导演的人数等信息,应该怎么获取?
# 评分的平均分
movie["Rating"].mean()
6.723200000000003
# 导演的人数
movie["Director"].size
# np.unique(movie["Director"]).size
1000
# 导演的人数去重后
np.unique(movie["Director"]).size
644
3. 需求2
对于这一组电影数据,如果我们想rating,runtime的分布情况,应该如何呈现数据?
movie["Rating"].plot(kind="hist", figsize=(20, 8))
import matplotlib.pyplot as plt
# 1、创建画布
plt.figure(figsize=(20, 8), dpi=80)
# 2、绘制直方图
plt.hist(movie["Rating"], 20)
# 修改刻度 等差x轴
plt.xticks(np.linspace(movie["Rating"].min(), movie["Rating"].max(), 21))
# 添加网格
plt.grid(linestyle="--", alpha=0.5)
# 3、显示图像
plt.show()

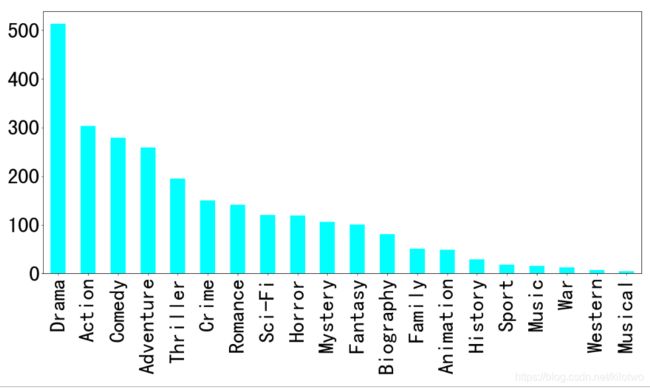
4.需求3
对于这一组电影数据,如果我们希望统计电影分类(genre)的情况,应该如何处理数据?
# 先统计电影类别都有哪些 使用列表解析
movie_genre = [i.split(",") for i in movie["Genre"]]
movie_genre
[['Action', 'Adventure', 'Sci-Fi'],
['Adventure', 'Mystery', 'Sci-Fi'],
['Horror', 'Thriller'],
['Animation', 'Comedy', 'Family'],
['Action', 'Adventure', 'Fantasy'],
['Action', 'Adventure', 'Fantasy'],
['Comedy', 'Drama', 'Music'],
['Comedy'],
['Action', 'Adventure', 'Biography'],
['Adventure', 'Drama', 'Romance'],
['Adventure', 'Family', 'Fantasy'],
['Biography', 'Drama', 'History'],
['Action', 'Adventure', 'Sci-Fi'],
['Animation', 'Adventure', 'Comedy'],
['Action', 'Comedy', 'Drama'],
# 还有这种操作? 嵌套循环
movie_class = np.unique([j for i in movie_genre for j in i])
movie_class
array(['Action', 'Adventure', 'Animation', 'Biography', 'Comedy', 'Crime',
'Drama', 'Family', 'Fantasy', 'History', 'Horror', 'Music',
'Musical', 'Mystery', 'Romance', 'Sci-Fi', 'Sport', 'Thriller',
'War', 'Western'], dtype='len(movie_class)
20
# 统计每个类别有几个电影
count = pd.DataFrame(np.zeros(shape=[1000, 20], dtype="int32"), columns=movie_class)
count.head()
| Action | Adventure | Animation | Biography | Comedy | Crime | Drama | Family | Fantasy | History | Horror | Music | Musical | Mystery | Romance | Sci-Fi | Sport | Thriller | War | Western | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
# 计数填表
for i in range(1000):
count.ix[i, movie_genre[i]] = 1
| Action | Adventure | Animation | Biography | Comedy | Crime | Drama | Family | Fantasy | History | Horror | Music | Musical | Mystery | Romance | Sci-Fi | Sport | Thriller | War | Western | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 3 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 6 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 7 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 8 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 9 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 10 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 11 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 12 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 13 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 14 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
#按列求和
count.sum(axis=0).sort_values(ascending=False).plot(kind="bar", figsize=(20, 9), fontsize=40, colormap="cool")