沪深300成分股分析
import pandas as pd
import numpy as np
import glob
import os
import seaborn as sns
import matplotlib.pyplot as plt
import statsmodels.api as sm
import statsmodels.formula.api as smf
from statsmodels.formula.api import ols, glm
做这个分析的时候,我丢失了沪深300的数据,但是并不影响分析模型,所以在以工作日为数据集的分析上,我计算沪深300成分股和sz000001的相关性以及回归。
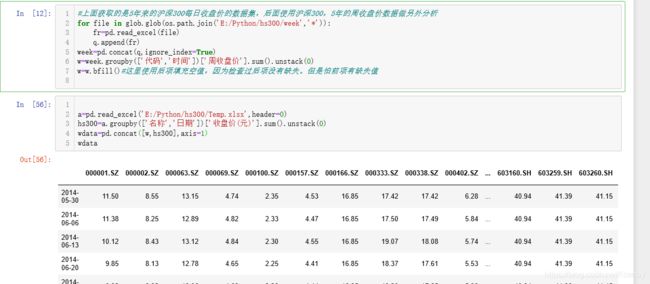
引入需要用到的库,使用循环语句以及glob、os库批量读入文件。

对读取的数据进行清洗,填充,同时简单的选取前四列绘制价格走势图。

将股价数据作为自变量标准化为涨幅百分比表示的数据
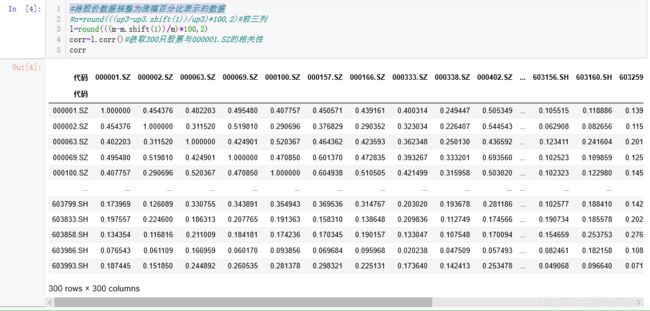
选取与00001.SZ相关性最高的10只股票
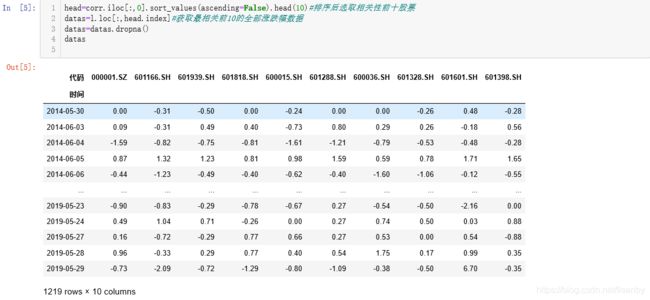
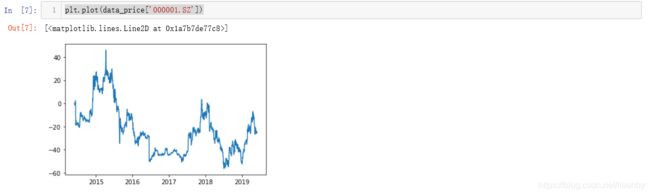
获得最相关10只股票的涨幅波动累加值,简单的绘制10只股票的图形,单独绘制000001.SZ的图形,以便观测在累计涨幅波动上两者的走势差异。

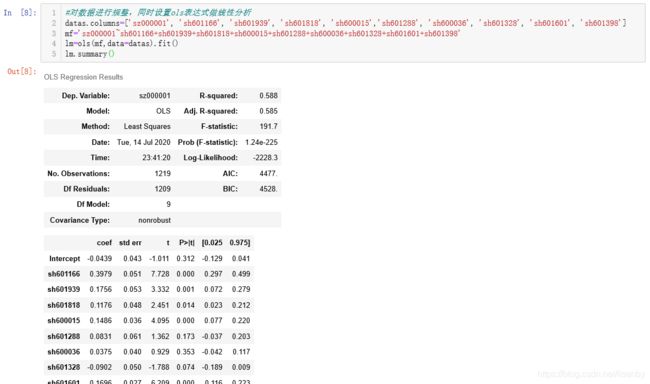
重命名列名,编写ols线性分析表达式mf,获得摘要信息,R方大于0.4模型显著。但是p>t值中sh601288、sh600036偏大。
这个例子中的模型是用的SZ.000001与同他五年来涨幅最相关的9支股票做的分析,该模型无法用来预测未来走势,因为不管是SZ.000001的价格还是其余九只股票的价格都无法提前预知,所以我选取在模型摘要中对SZ.000001影响因子最大的股票601166.SH与之做分析。
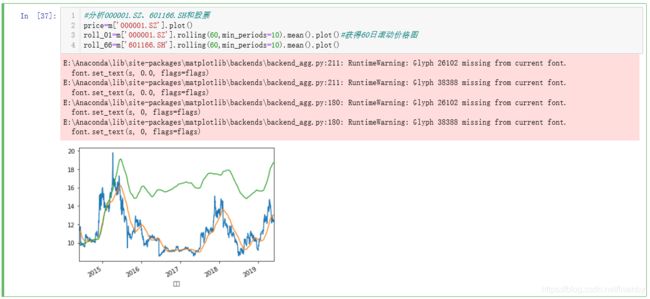
图中蓝色是股价走势图,而绿色和橙色是60日滚动均值的曲线,我们可以看出,在股价走势上,两只股票具有极高的相似性。
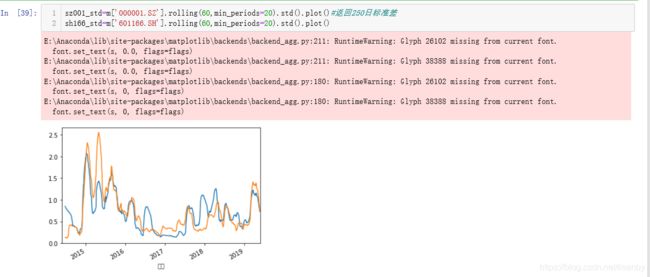
获得两只股票的60日均值标准差,发现两者具有相似的离散程度。与上方的股价走势图类似。因此我对000001.SZ切箱分析,查看涨幅分布规律。
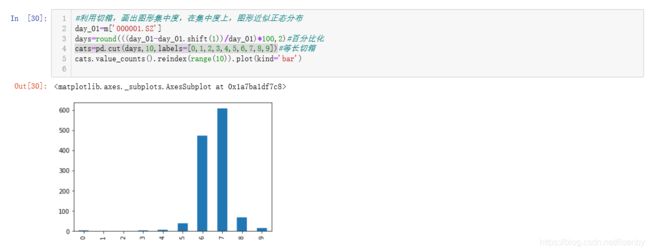
将股价涨跌幅十等分,近五年的股价涨跌幅基本符合正态分布。且涨多跌少,且有大跌幅而小涨幅。
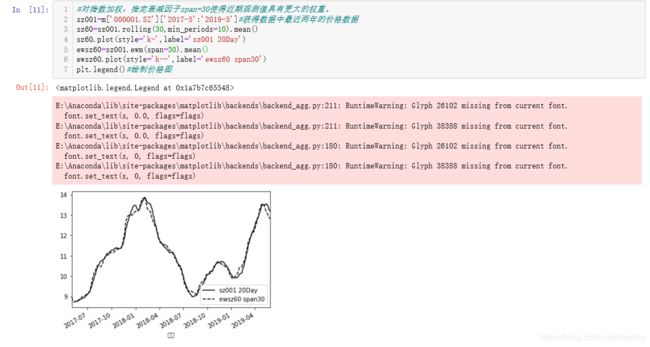
对指数加权计算,赋予近期的观测值更大的权重,衰减因子span=30,当然这么看过于干燥,我把之前分析的股价图一并放入。
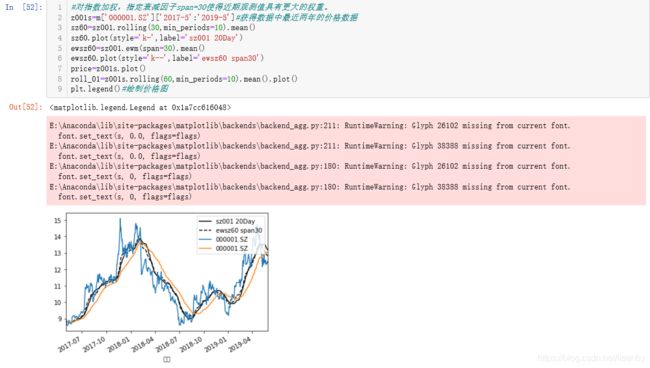
从图中可以看到,60日的平滑均线对于股价的反应是滞后的,而加入衰减因子后,图形可以更快的适应股价的变化情况,因此可以看出有衰减因子的图形具有更强的适应性。
上面得出的结论是我们获得了两个强相关的股票,他们的涨跌幅走势在统计学上具有一致性,因此在股票投资组合上无法形成互补。但是如果000001.SZ股票是沪深300指数,那么601166.SH可以作为对股指进行追踪的组合股票之一。
另外有一份14-19五年的每周沪深300及成分股的股指涨跌幅。所以下面我又用每周的做了一份分析。

一样的数据读入pd,拼接数据。

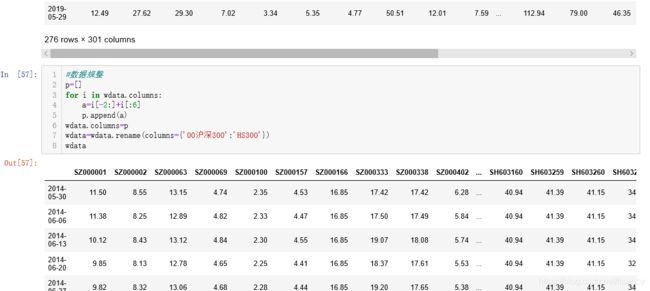
数据规整。
列名太丑了,清洗一下。
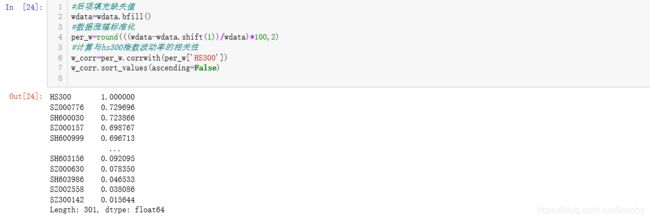
还是一样,将数据价格标准化为涨幅。同时获取成分股与HS300指数周涨幅的相关性。
取周波动最相关股票SZ000776做一元一次回归分析。
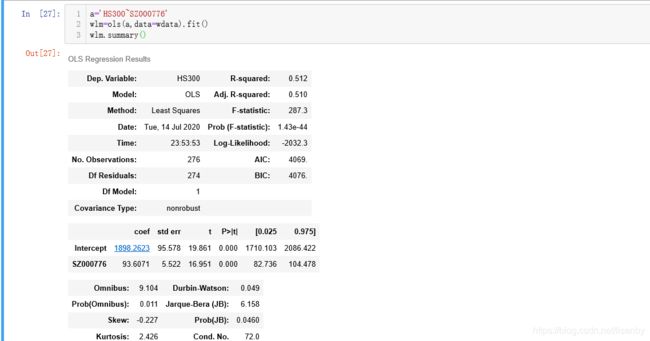
R大于0.4,显著。P>t等于0显著。
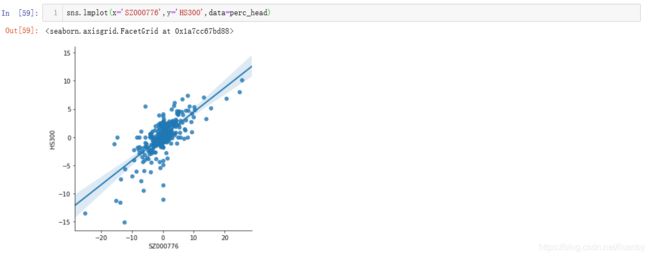
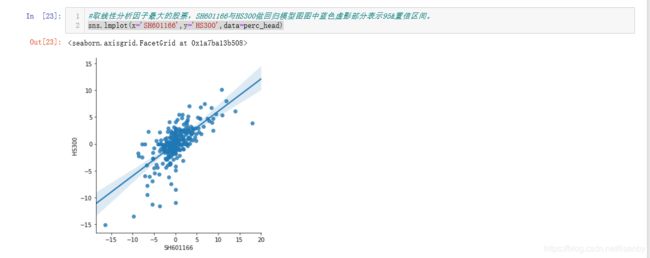
画出两者之间涨跌幅线性关系图(注意这里不是股价的),上面的回归分析是用的股价来的线性回归关系,浅蓝色部分为95%置信区间下的取值范围。
小小的看一下五年来最相关10只股票的累计涨跌幅情况。其实这幅图可以无视了。
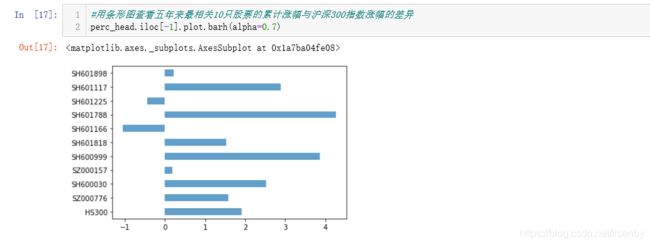
用数据周后一天的累计涨跌幅做了柱状图,清晰的看到各股票五年的涨跌幅。
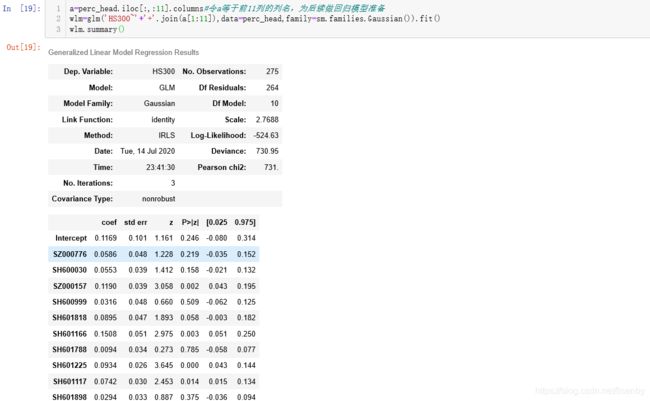
在这里使用广义线性模型glm进行线性回归。同时我又做了一份ols的线性回归模型。
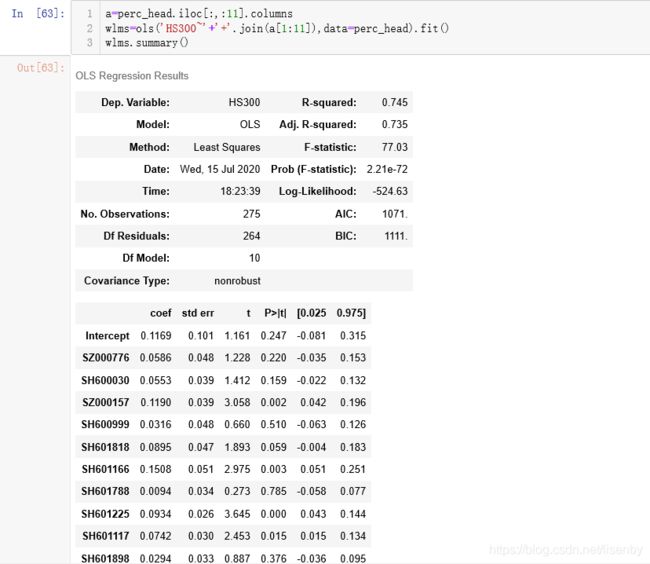
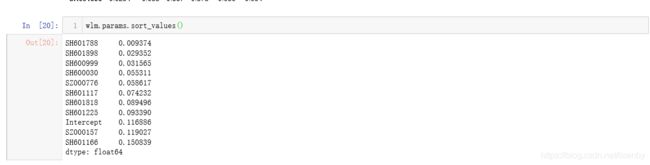
上面两幅图是我用两种方法得出的回归因子系数,两者是相同的,取最大值的SZ601166,画出95置信区间的图片。
到这里其实回归分析已经差不多了,最后就是要做一些模型的预测以及精度检验。于是我拿了sz000076对沪深300的涨跌幅做预测。至于为什么不用10因子模型,因为手头无法拿到全部的后续数据,仅有部分。
![]()
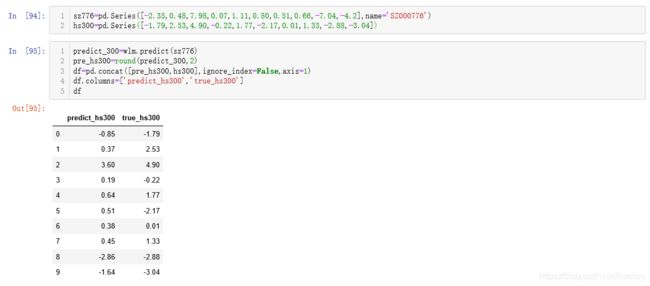
插入ss列为误差值,表示预测值与真实值之间的差。
predict_hs300为预测涨跌幅数据,true_hs300为真实涨跌幅数据
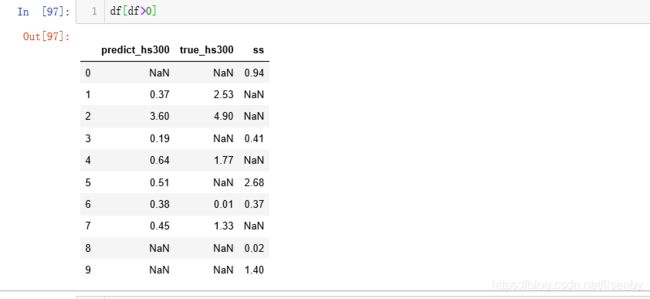
如果仅仅看10个预测值,该模型对于同向涨跌的预测准确率为80%。

而十周整体涨跌幅差值为0.35。说明SZ601166与沪深300指数具有极强的追踪效应。二则互为有效关联。