Python+MongoDB 爬取百度词条
本文是根据慕课网的内容的学习与总结:http://www.imooc.com/learn/563
程序采用的开发环境如下:
MongoDB版本:mongodb-3.4.1
Python版本:2.7
集成IDE:Pycharm
思维导图:ImindMap 9
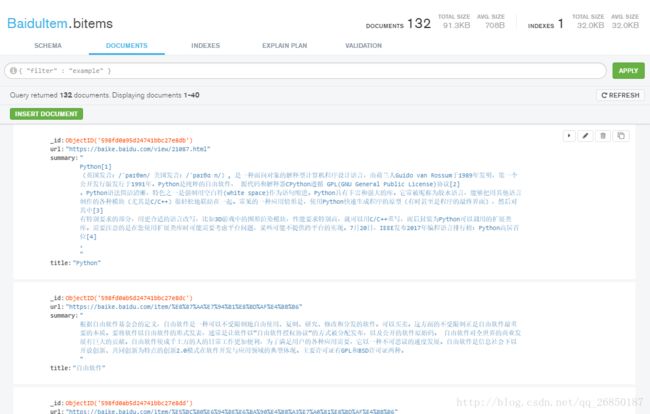
先看一下数据库中的已经爬取(132条)的内容(词条链接,简介,标题):
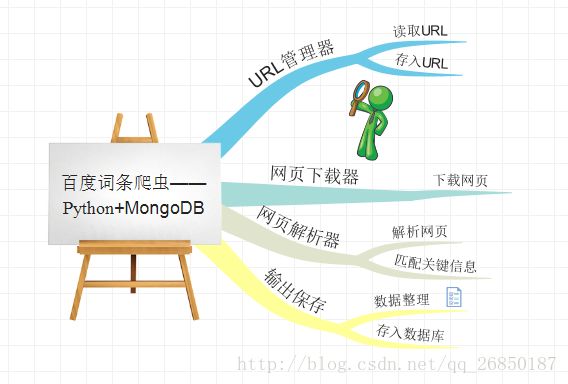
1、设计思路:
爬虫的一般步骤:确定要爬取的内容,分析网页结构,下载网页,解析网页,保存数据
本程序:主要分为以下几个模块
(1)URL管理器、(2)网页下载器、(3)网页解析器、(4)保存数据
2、编码:
(1)URL管理器:有两个set集合,set1保存尚未被下载解析的url,set2保存已被下载解析的url。每次从set1中取出url,进行下载解析,同时将新解析出来的url存入set1。
注:用set是避免爬虫的重复爬取
url_manager.py
#coding:utf-8
'''
date: 2017-8-12
description:Url管理类
'''
class UrlManager(object):
def __init__(self):
self.new_urls = set()
self.old_urls = set()
# 添加新的URL
def add_new_url(self, new_url):
if new_url is None:
return
if new_url not in self.new_urls and new_url not in self.old_urls:
self.new_urls.add(new_url)
# 添加多个Url
def add_new_urls(self, new_urls):
if new_urls is None or len(new_urls) == 0:
return
for url in new_urls:
self.add_new_url(url)
# 判断新Url集合是否为空
def has_new_url(self):
return len(self.new_urls) != 0
# 获取URL
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url(2).网页下载器:
这个比较简单,从URL管理器读取新的URL,进行下载即可,采用python2.7的内置库:urllib2
html_downloader.py
#coding:utf-8
'''
date:2017-8-12
description: 网页下载器
'''
import urllib2
class HtmlDownLoader(object):
def download(self, new_url):
if new_url is None:
return None
response = urllib2.urlopen(new_url)
if response.getcode() != 200:
return None
return response.read()(3)Url解析器:采用第三方库beautifulsoup4,
html_parser.py
#coding:utf-8
'''
date:2017-8-12
description: 网页解析类。采用BeautifulSoup进行解析
'''
import urlparse
from bs4 import BeautifulSoup
import re
class HtmlParser(object):
# 爬取本词条网页的所有相关连接URL
def get_new_urls(self, page_url, soup):
new_urls = set()
links = soup.find_all('a',href=re.compile(r'/item/.+[0-9]'))
for link in links:
new_url = link['href']
new_full_url = urlparse.urljoin(page_url,new_url)
new_urls.add(new_full_url)
# print link
return new_urls
# 根据标签获取要爬取的数据
def get_new_data(self, page_url, soup):
res_data = {}
#url
res_data['url'] = page_url
# class ="lemmaWgt-lemmaTitle-title" >
title_node = soup.find('dd',class_="lemmaWgt-lemmaTitle-title").find('h1')
res_data['title'] = title_node.get_text()
# class ="lemma-summary" label-module="lemmaSummary" >
summary_node = soup.find('div',class_="lemma-summary")
res_data['summary'] = summary_node.get_text()
return res_data
# 解析网页
def parse(self, page_url, html_cont):
if page_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont,'html.parser', from_encoding='utf-8')
new_urls = self.get_new_urls(page_url,soup)
new_data = self.get_new_data(page_url,soup)
return new_urls,new_data(4)存入数据库:数据库采用MongoDB,编码时需要安装pymongo
html_outputer.py
#coding:utf-8
'''
date: 2017-8-12
description:Url管理类
'''
import pymongo
class HtmlOutputer(object):
# 获取MongoDB的数据库连接
def getConnect(self):
connection = pymongo.MongoClient()
BaiduItem = connection.BaiduItem
BaiduItemConnection = BaiduItem.bitems
return BaiduItemConnection
def collect_data(self, data):
if data is None:
return
self.getConnect().insert_one(data)(5)程序入口:spider_main.py
#coding:utf-8
'''
date: 2017-8-12
description:Url管理类
'''
import html_downloader,html_parser,html_outputer,url_manager
class SpiderMain(object):
#初始化构造器
def __init__(self):
self.urls = url_manager.UrlManager()
self.downloader = html_downloader.HtmlDownLoader()
self.parser = html_parser.HtmlParser()
self.outputer = html_outputer.HtmlOutputer()
def craw(self, root_url):
count = 1
self.urls.add_new_url(root_url)
while self.urls.has_new_url():
try:
new_url = self.urls.get_new_url()
print 'craw %d : %s' % (count, new_url)
html_cont = self.downloader.download(new_url)
new_urls, new_data = self.parser.parse(new_url, html_cont)
self.urls.add_new_urls(new_urls)
self.outputer.collect_data(new_data)
if count == 100:
break
count += 1
except:
print 'crawed failed'
# self.outputer.saveInfo()
if __name__ == '__main__':
root_url = "https://baike.baidu.com/view/21087.html"
obj_spider = SpiderMain()
obj_spider.craw(root_url)