沪深300配对交易
目录
- 获取数据
- 相关系数三级目录
- 协整检验
- 聚类算法进一步筛选
- 回测
获取数据
通过pandas_datareader来获取沪深300的股票数据,为此,先从网上爬虫得到沪深300的股票名单
import os
import pandas as pd
import pandas_datareader as web
import pickle
import requests
import bs4 as bs
import matplotlib.pyplot as plt
import numpy as np
# import tushare
def save_hs300_tickers():
# resp = requests.get('https://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
resp = requests.get(
'https://zh.wikipedia.org/wiki/%E6%B2%AA%E6%B7%B1300#%E6%88%90%E4%BB%BD%E8%82%A1%E5%88%97%E8%A1%A8')
soup =bs.BeautifulSoup(resp.text, "lxml")
table = soup.find('table', {'class':"wikitable collapsible sortable"})
tickers = []
for row in table.find_all('tr')[1:]:
ticker = row.find('td').text
if ticker[0] == "6" :
ticker = ticker + ".SS"
else :
ticker = ticker + ".SZ"
tickers.append(ticker)
with open("hs300tickers.pickle","wb") as f:
pickle.dump(tickers,f)
print(tickers)
return tickers之后下载数据
def get_data_from_yahoo(reload_hs300=False):
if reload_hs300:
tickers = save_hs300_tickers()
else:
with open("hs300tickers.pickle", "rb") as f:
tickers = pickle.load(f)
if not os.path.exists('stock_dfs'):
os.makedirs('stock_dfs')
start_date = dt.datetime(2010, 1, 1)
end_date = dt.datetime(2020, 6, 1)
for ticker in tickers[:]:
print(ticker)
if not os.path.exists('stock_dfs/{}.csv'.format(ticker)):
df = web.DataReader(ticker,'yahoo',start_date, end_date )
df.to_csv('stock_dfs/{}.csv'.format(ticker))
else:
print('Already have {}'.format(ticker))这些步骤也可以用tushare完成,现在电脑里已经有了300个CSV文件,为了之后读取文件更方便,先写一个整合数据的程序
def compile_data():
with open("hs300tickers.pickle", "rb") as f:
tickers = pickle.load(f)
main_df = pd.DataFrame()
for count,ticker in enumerate(tickers):
df = pd.read_csv('stock_dfs/{}.csv'.format(ticker))
df.set_index('Date',inplace=True)
df.rename(columns={'Adj Close': ticker}, inplace=True)
df.drop(['Open', 'High', 'Low', 'Close', 'Volume'], 1, inplace=True)
df.fillna(method = 'ffill')
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df,how='outer')
if count % 10 ==0:
print(count)
print(main_df.head())
main_df.to_csv('hs300_closes.csv')
把300只股票的收盘价统一放进hs300_closes.csv中
相关系数三级目录
计算相关系数非常简单
df = pd.read_csv('hs300_closes.csv')
df = df[-700:-400]
df_corr = df.corr()df_corr就是相关系数矩阵,可以通过下面的程序画出相关系数热力图
data = df_corr.values
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
heatmap = ax.pcolor(data,cmap=plt.cm.RdYlGn)
fig.colorbar(heatmap)
ax.set_xticks(np.arange(data.shape[0])+0.5, minor=False)
ax.set_yticks(np.arange(data.shape[1])+0.5, minor=False)
ax.invert_yaxis()
ax.xaxis.tick_top()
column_labels = df_corr.columns
row_labels = df_corr.index
ax.set_xticklabels(column_labels)
ax.set_yticklabels(row_labels)
heatmap.set_clim(-1,1)
plt.tight_layout()
plt.show()
绿色代表正相关,红色代表负相关,颜色越深值越大。可以通过图有一个大致上的判断。

协整检验
两只股票价格的相关系数不能直接做为选择股票对的标准,一般要求配对的股票能够通过协整检验。协整检验是为了检验两个或多个非平稳时间序列有无因果关系。协整检验要先检验两只股票的价格时间序列是否同阶单整,本次就简化为先看两只股票的价格的一阶差分是否平稳,都单整后进行协整检验。整检验有两种方法,一种是先做回归,看残差是否平稳,这种方法叫Engel-Granger 两步协整检验法;另一种为Johansen Test 协整检验法。
import statsmodels.api as sm
from statsmodels.tsa.stattools import coint,adfuller
def cointrgration(priceX,priceY):
if priceX is None or priceY is None:
print('数据缺失')
priceX = np.log(priceX)
priceY = np.log(priceY)
ret_x = np.diff(priceX)
ret_y = np.diff(priceY)
ret_x = ret_x[1:]
ret_y = ret_y[1:]
adf_x = adfuller(ret_x)
adf_y = adfuller(ret_y)
results = sm.OLS(priceY,sm.add_constant(priceX)).fit()
spread = results.resid
adfSpread = adfuller(spread)
if adfSpread[0]<adfSpread[4]['1%'] and adf_x[0]<adf_x[4]['1%'] and adf_y[0]<adf_y[4]['1%']:
return True
else:
return False
上面是python实现协整检验的方法,也可以用arch包进行以上操作。
聚类算法进一步筛选
一般同行业内的股票才可以进行配对交易。目前筛选股票的过程中并没有考虑到这一点,因此筛选出来的股票对中,会有一些统计意义上可以配对,但实际没有什么逻辑的股票对。所以用聚类算法对股票进行分类,筛选出适合实际操作的股票对。可以直接用sklearn库进行聚类,本次用的AP算法进行聚类,好处是不用事先给出聚类数目。
from sklearn.cluster import affinity_propagation
from sklearn.covariance import GraphicalLassoCV
def Clusters():
df = pd.read_csv('hs300_diff.csv')
df = df[-700:-400]
df.drop(['Date'],axis=1,inplace=True)
stock_dataset = np.array(df)
stock_dataset = stock_dataset.copy().T
stock_dataset = stock_dataset/np.std(stock_dataset,axis=0)
np.nan_to_num(stock_dataset)
stock_model = GraphicalLassoCV()
stock_model.fit(stock_dataset)
_,labels = affinity_propagation(stock_model.covariance_)
n_labels = max(labels)
print('Stock Clusters: {}'.format(n_labels + 1)) # 10,即得到10个类别
print(len(labels))
return labels完整的筛选股票对程序如下
def filter_data():
df = pd.read_csv('hs300_closes.csv')
df = df[-700:-400]
df_corr = df.corr()
pair_list=[]
pair_SSD=[]
pair_corr=[]
tickers = df_corr.columns
labels = Clusters()
for i in range(0,300):
for j in range(i,300):
corr = df_corr.iloc[i,j]
if corr > 0.95:
if labels[i] ==labels[j]:
priceX = df[str(tickers[i])].values
priceY = df[str(tickers[j])].values
if cointrgration(priceX ,priceY ):
pair_list.append((tickers[i],tickers[j]))
pair_SSD.append(SSD(priceX,priceY))
pair_corr.append(corr)
data = pd.DataFrame([pair_list,pair_corr,pair_SSD],index=['pair','corr','SSd'])
return data回测
对筛选出来的股票,在聚宽进行回测,采用标准的布林带策略,回测结果如下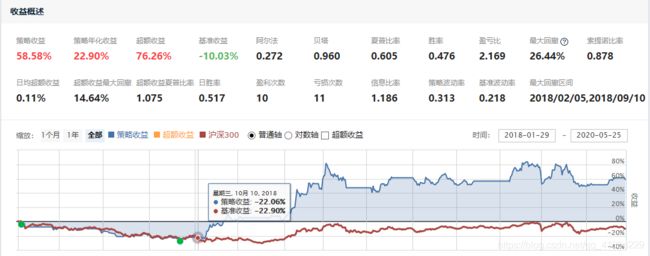
参考资料
https://blog.csdn.net/FrankieHello/article/details/86770852
https://www.youtube.com/watch?v=eAtcIoVGb-4&list=PLQVvvaa0QuDcR-u9O8LyLR7URiKuW-XZq&index=8