目录
- 入门级:基于单特征的Beta分布贝叶斯分类器
- 进阶:以Beta分布作为先验分布的二项分布贝叶斯分类器
入门级:基于单特征的Beta分布贝叶斯分类器
该实例中的机器学习方法本质上使用的是基于单特征的(朴素)贝叶斯判别模型
首先,鉴定出那些在CMV感染状态表现为阳性的(phenotype-positive)患者中出现明显克隆扩张的TCRβs,称为阳性表型相关性TCRβs克隆
一个样本的表型负荷(phenotype burden)被定义为:
该样本的所有unique TCRβs中与阳性表型相关的克隆的数量所占的比例
由于表型负荷的取值范围为 (0,1),其符合β二项分布(简称为β分布)
然后分别对表型阳性和表型阴性两组样本,利用Beta分布(见后文补充知识部分))估计出各组的表型负荷的概率密度分布,分别记作 Beta+(α+ , β+) 和 Beta-(α- , β-)
对于一个新的样本可以计算出它来自表型阳性组和表型阴性组的后验概率:
若,则判断为阳性组,否则为阴性组
进阶:以Beta分布作为先验分布的二项分布贝叶斯分类器
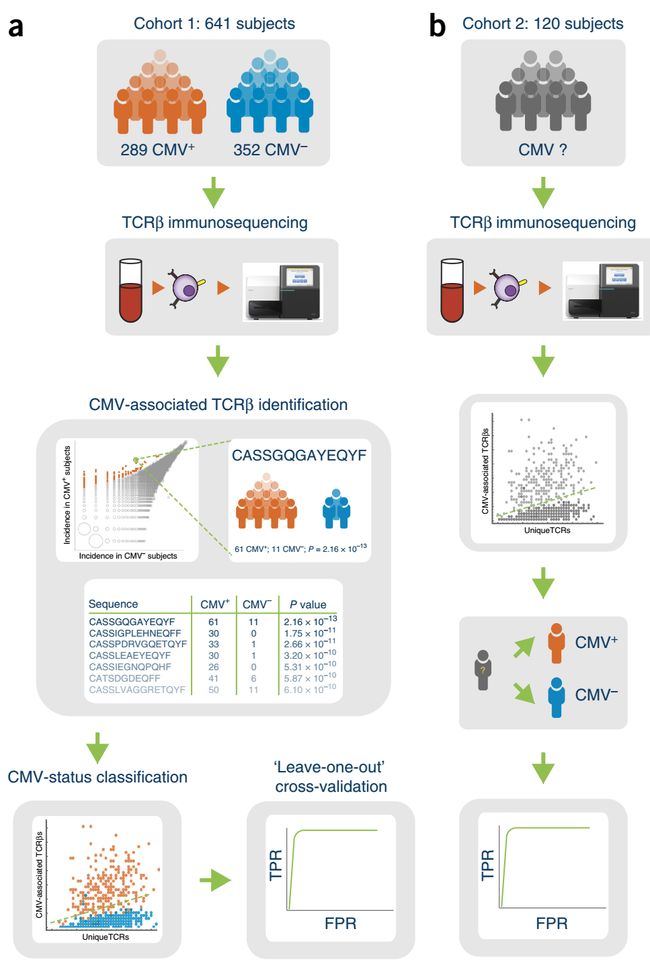
这个项目用到了641个样本(cohort 1),包括352 例CMV阴性(CMV-)和289例CMV阳性(CMV+)
外部验证用到了120个样本(cohort 2)
该机器学习的任务为:
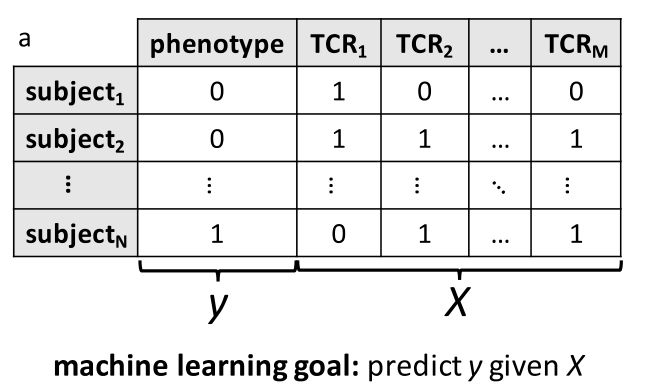
讨论 TCRβ 免疫组的数据特点:
- 可能出现的TCRβ的集合非常大,而单个样本只能从中检测到稀疏的少数几个;
- 一个新样本中很可能会出现训练样本集合中未出现的TCRβ克隆类型;
- 对于一个给定的TCR,它对给定抗原肽的结合亲和力会受到HLA类型的调控,因此原始的用于判别分析的特征集合还受到隐变量——HLA类型的影响;
-
特征选择:鉴定表型相关的TCRβs
使用Fisher精确检验(单尾检验,具体实现过程请查看文末 *2.1. Fisher检验筛选CMV阳性(CMV+)相关克隆):

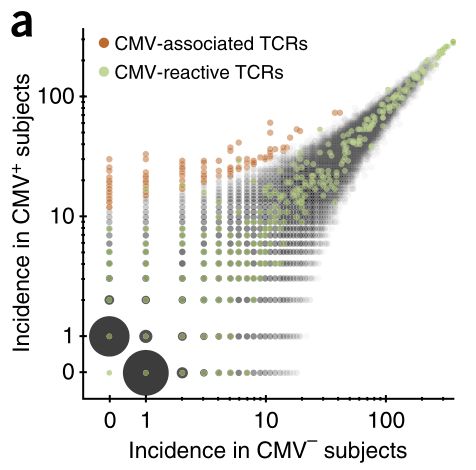
Fisher检验的阈值设为:,FDR<0.14(该FDR的计算方法见文末 *3. FDR的计算方法,且阈值的选择问题本质上是一个模型选择问题 (model selection) ,该问题会在这部分靠后的位置进行讨论),且富集在CMV+样本中,从而得到与CMV+相关的CDR3克隆集合,共有164个
通过下面的TCRβ克隆在两组中的发生率的散点图可以明显地看到,筛出的表型相关的TCRβ克隆的确显著地表达在CMV+组中
-
计算表型负荷(phenotype burden)
一个样本的表型负荷(phenotype burden)被定义为:
该样本的所有unique TCRβs中与阳性表型相关的克隆的数量所占的比例
若阳性表型相关的克隆的集合记为CDR,样本i的unique克隆集合记为CDRi,则它的表型负荷为:
其中表示集合
·中元素的数量下图是将上面的表型负荷计算公式中的分子与分母分别作为纵轴和横轴,画成二维的散点图
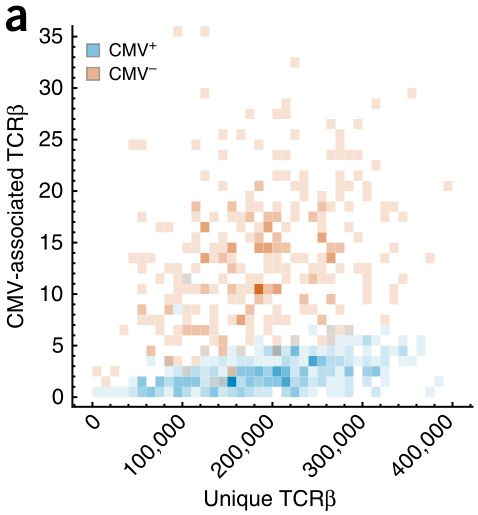
可以明显地看出两类样本在这个层面上来看,有很好的区分度
-
基于二项分布的贝叶斯判别模型
基本思想:
对于相关TCR数为,total unique TCR数为的样本,认为它一个概率为它的表型负荷(服从Beta分布),, 的二项分布(伯努利分布),根据贝叶斯思想,构造最优贝叶斯分类器,即
其中
而是一个常数,对分类器的结果没有影响,可以省略
那么就需要根据训练集估计:
- 类先验概率
- 类条件概率(似然)
(1)首先根据概率图模型推出单个样本的概率表示公式
概率图模型如下:
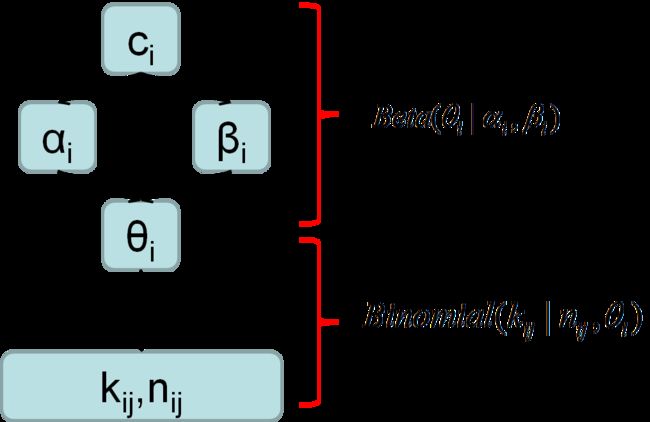
则对于j样本,我们可以算出它的 的后验分布:
其中,
- :表示事件发生的概率,即
- :表示
- :表示的先验分布
对上面的公式进一步推导
根据Beta分布的先验分布的,已知
因此
这样我们就得到单个样本的概率表示公式,其中是Beta函数,从上面的表达式中,我们可以看出是和的函数
(2)优化每个组的表型负荷 的先验分布的两个参数 和 ——最大似然法
我们要最大化组的样本集合它们的联合概率:
其中,是常数,可以省略,则
对它取对数,得到
其中,是属于组的样本数
因此优化目标为:
分别对和求偏导
其中,是伽马函数
使用梯度上升(gradient ascent)法来求解优化目标,其中梯度的公式为:
最终得到的解记为和,其中
(3)根据训练好的分类器对新样本进行分类
分类器为
(4)选择合适的的阈值:model selection
使用交叉验证法中的留一法 (leave-one-out)来进行模型选择
定义该问题的优化目标为最小化cross-entropy loss:
其中,表示样本的所属类别,表示样本被判为的概率,N为训练样本数(N个训练样本数的训练集它总共有N种留一法组合形式)
分析优化目标为什么选择最小化cross-entropy loss:
我们的目的是选择合适的阈值,那么什么叫合适的阈值?就是在该阈值下,能筛选出合适的features,基于这些features训练出的模型能有足够高的泛化性能,即模型的variance足够的小,也就是对于测试数据(这里就是留一法中的那一个样本)有足够高的预测准确性,定量化描述就是N次留一法的准确预测的概率的均值(几何平均数)最大化,即
由于取对数不影响优化方向,所以
从而得到上面的优化目标
补充知识
*1. beta分布
*1.1. 什么是beta分布
对于硬币或者骰子这样的简单实验,我们事先能很准确地掌握系统成功的概率。
然而通常情况下,系统成功的概率是未知的,但是根据频率学派的观点,我们可以通过频率来估计概率。为了测试系统的成功概率,我们做n次试验,统计成功的次数k,于是很直观地就可以计算出。然而由于系统成功的概率是未知的,这个公式计算出的只是系统成功概率的最佳估计。也就是说实际上也可能为其它的值,只是为其它的值的概率较小。因此我们并不能完全确定硬币出现正面的概率就是该值,所以也是一个随机变量,它符合Beta分布,其取值范围为0到1
用一句话来说,beta分布可以看作一个概率的概率密度分布,当你不知道一个东西的具体概率是多少时,它可以给出了所有概率出现的可能性大小。
Beta分布有和两个参数α和β,其中α为成功次数加1,β为失败次数加1。
*1.2. 理解beta分布
举一个简单的例子,熟悉棒球运动的都知道有一个指标就是棒球击球率(batting average),就是用一个运动员击中的球数除以击球的总数,我们一般认为0.266是正常水平的击球率,而如果击球率高达0.3就被认为是非常优秀的。
现在有一个棒球运动员,我们希望能够预测他在这一赛季中的棒球击球率是多少。你可能就会直接计算棒球击球率,用击中的数除以击球数,但是如果这个棒球运动员只打了一次,而且还命中了,那么他就击球率就是100%了,这显然是不合理的,因为根据棒球的历史信息,我们知道这个击球率应该是0.215到0.36之间才对啊。
对于这个问题,一个最好的方法来表示这些经验(在统计中称为先验信息)就是用beta分布,这表示在我们没有看到这个运动员打球之前,我们就有了一个大概的范围。beta分布的定义域是(0,1)这就跟概率的范围是一样的。
s
接下来我们将这些先验信息转换为beta分布的参数,我们知道一个击球率应该是平均0.27左右,而他的范围是0.21到0.35,那么根据这个信息,我们可以取α=81,β=219
之所以取这两个参数是因为:
beta分布的均值
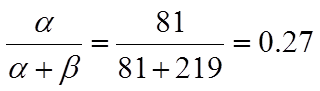
这个分布主要落在了(0.2,0.35)间,这是从经验中得出的合理的范围
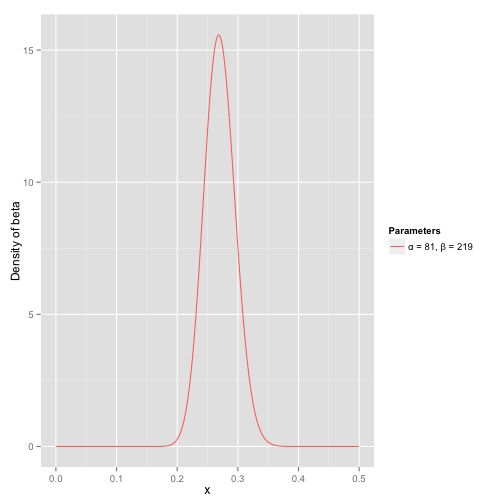
在这个例子里,我们的x轴就表示各个击球率的取值,x对应的y值就是这个击球率所对应的概率密度。也就是说beta分布可以看作一个概率的概率密度分布。
那么有了先验信息后,现在我们考虑一个运动员只打一次球,那么他现在的数据就是“1中;1击”。这时候我们就可以更新我们的分布了,让这个曲线做一些移动去适应我们的新信息,移动的方法很简单
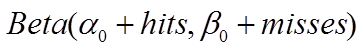
其中α0和β0是一开始的参数,在这里是81和219。所以在这一例子里,α增加了1(击中了一次)。β没有增加(没有漏球)。这就是我们的新的beta分布 Beta(81+1,219),我们跟原来的比较一下:
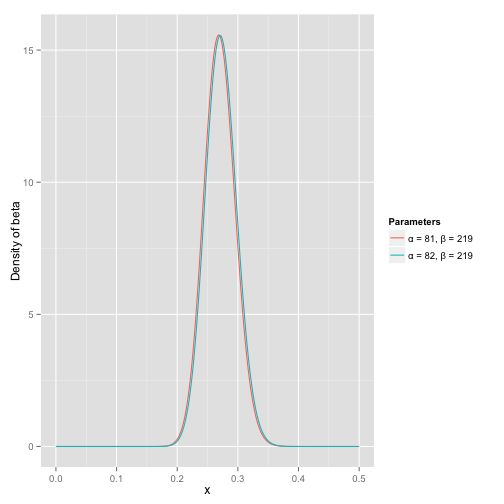
可以看到这个分布其实没多大变化,这是因为只打了1次球并不能说明什么问题。但是如果我们得到了更多的数据,假设一共打了300次,其中击中了100次,200次没击中,那么这一新分布就是 Beta(81+100,219+200) :
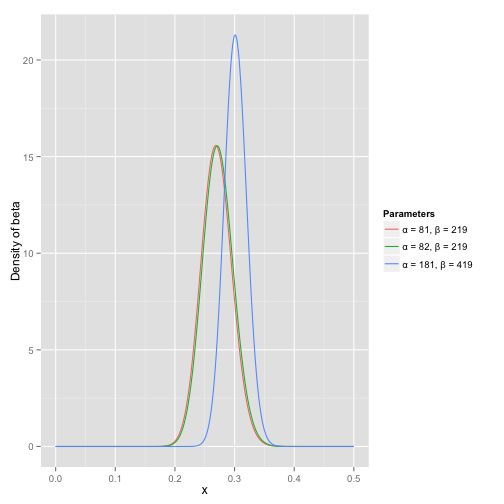
注意到这个曲线变得更加尖,并且平移到了一个右边的位置,表示比平均水平要高
有趣的现象:
根据这个新的beta分布,我们可以得出他的数学期望为:α/(α+β)=82+100/(82+100+219+200)=.303 ,这一结果要比直接的估计要小 100/(100+200)=.333 。你可能已经意识到,我们事实上就是在这个运动员在击球之前可以理解为他已经成功了81次,失败了219次这样一个先验信息。
参考资料:
(1) Emerson R O , Dewitt W S , Vignali M , et al. Immunosequencing identifies signatures of cytomegalovirus exposure history and HLA-mediated effects on the T cell repertoire[J]. Nature Genetics, 2017, 49(5):659-665.
(2) CSDN·chivalry《二项分布和Beta分布》
(3) CSDN·Jie Qiao《带你理解beta分布》