Bag-of-Features——图像检索与识别
图像检索中要将查询图像与数据库中所有的图像进行完全比较往往是不可行的。在数据库很大的情况下,这样的查询方式会耗费过多时间。本篇要讲到的方法可以将任意图片的所有特征向量用一个固定维数的向量表出,且这个维数并不因图片特征点数不同而变化。这使在数百万图像中搜索具有相似内容的图像成为可能。
Bag - of - Features
在介绍BoF之前,首先得简单介绍一下Bag-of-Words。
Bag-of-Words(BoW)模型源于文本分类技术,在信息检索中,它假定对于一个文本,忽略其词序和语法、句法。将其仅仅看作是一个词集合,或者说是词的一个组合,文本中每个词的出现都是独立的,不依赖于其他词是否出现,或者说这篇文章的作者在任意一个位置选择词汇都不受前面句子的影响而独立选择的。

图像可以视为一种文档对象,图像中不同的局部区域或其特征可看做构成图像的词汇,其中相近的区域或其特征可以视作为一个词。这样,就能够把文本检索及分类的方法用到图像分类及检索中去。

Bag-of-Features 模型仿照文本检索领域的Bag-of-Words方法,把每幅图像描述为一个局部区域/关键点(Patches/Key Points)特征的无序集合。使用某种聚类算法(如K-means)将局部特征进行聚类,每个聚类中心被看作是词典中的一个视觉词汇(Visual Word),相当于文本检索中的词,视觉词汇由聚类中心对应特征形成的码字(code word)来表示(可看当为一种特征量化过程)。所有视觉词汇形成一个视觉词典(Visual Vocabulary),对应一个码书(code book),即码字的集合,词典中所含词的个数反映了词典的大小。图像中的每个特征都将被映射到视觉词典的某个词上,这种映射可以通过计算特征间的距离去实现,然后统计每个视觉词的出现与否或次数,图像可描述为一个维数相同的直方图向量,即Bag-of-Features。
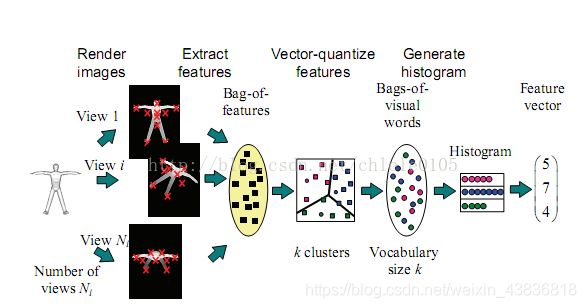
1. SIFT特征提取
关于SIFT的原理,这里有传送门→SIFT特征匹配算法及代码(python)
相关代码块:
# -*- coding: utf-8 -*-
import pickle
from PCV.imagesearch import imagesearch
from PCV.localdescriptors import sift
from PCV.imagesearch import vocabulary
from sqlite3 import dbapi2 as sqlite
from PCV.tools.imtools import get_imlist
#获取图像列表
imlist = get_imlist('first1000/')
nbr_images = len(imlist)
#获取特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
# load vocabulary
#载入词汇
with open('first1000/vocabulary.pkl', 'rb') as f:
voc = pickle.load(f)
#创建索引
indx = imagesearch.Indexer('testImaAdd.db',voc)
indx.create_tables()
# go through all images, project features on vocabulary and insert
#遍历所有的图像,并将它们的特征投影到词汇上
for i in range(nbr_images)[:1000]:
locs,descr = sift.read_features_from_file(featlist[i])
indx.add_to_index(imlist[i],descr)
# commit to database
#提交到数据库
indx.db_commit()
con = sqlite.connect('testImaAdd.db')
print (con.execute('select count (filename) from imlist').fetchone())
print (con.execute('select * from imlist').fetchone())
#获取图像列表
imlist = get_imlist('first1000/')
nbr_images = len(imlist)
#获取特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
#提取文件夹下图像的sift特征
for i in range(nbr_images):
sift.process_image(imlist[i], featlist[i])
#生成词汇
voc = vocabulary.Vocabulary('ukbenchtest')
voc.train(featlist, 1000, 10)
#保存词汇
# saving vocabulary
with open('first1000/vocabulary.pkl', 'wb') as f:
pickle.dump(voc, f)
print ('vocabulary is:', voc.name, voc.nbr_words)
在这里,将给定的图像数据集用sift特征提取得出特征词汇,并保存到词汇表。
2. 学习“视觉词典”
由于第一步得到的特征很多,也可能有很多特征是相似的。所以第二步需要将第一步得到的特征进行聚类。
用K-Means聚类的方法,将特征进行分类。并将聚类中心点记录到视觉词典,方便后期图像的检索。
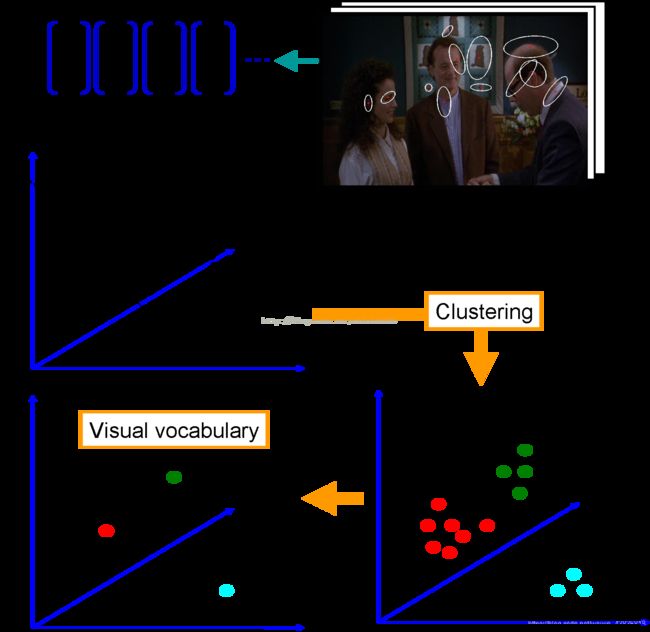
3. 针对输入的特征集,根据词典量化
利用最短距离原则。
4. 把输入图像转化成视觉单词的频率直方图
通过tf-idf对频数表加上权重,生成最终的bof。
这里的单词权重的定义,还有需要注意的地方:将不同图像都具有的特征对应的权重调 小,即
弱化共性特征,排除干扰

5. 构造特征到图像的倒排表,通过倒排表快速索引相关图像
构造倒排表的目的—— 避免图像特征与词典一一比对,使之快速锁定检索范围。
相关代码块:
# -*- coding: utf-8 -*-
import pickle
from PCV.imagesearch import imagesearch
from PCV.localdescriptors import sift
from sqlite3 import dbapi2 as sqlite
from PCV.tools.imtools import get_imlist
#获取图像列表
imlist = get_imlist('first1000/')
nbr_images = len(imlist)
#获取特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
#载入词汇
f = open('first1000/vocabulary.pkl', 'rb')
voc = pickle.load(f)
f.close()
src = imagesearch.Searcher('testImaAdd.db',voc)
locs,descr = sift.read_features_from_file(featlist[0])
iw = voc.project(descr)
print ('ask using a histogram...')
print (src.candidates_from_histogram(iw)[:10])
src = imagesearch.Searcher('testImaAdd.db',voc)
print ('try a query...')
nbr_results = 12
res = [w[1] for w in src.query(imlist[0])[:nbr_results]]
imagesearch.plot_results(src,res)
6. 根据索引结果进行直方图匹配
相关代码块:
# -*- coding: utf-8 -*-
import pickle
from PCV.localdescriptors import sift
from PCV.imagesearch import imagesearch
from PCV.geometry import homography
from PCV.tools.imtools import get_imlist
# load image list and vocabulary
#载入图像列表
imlist = get_imlist('first1000/')
nbr_images = len(imlist)
#载入特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
#载入词汇
with open('first1000/vocabulary.pkl', 'rb') as f:
voc = pickle.load(f)
src = imagesearch.Searcher('testImaAdd.db',voc)
# index of query image and number of results to return
#查询图像索引和查询返回的图像数
q_ind = 0
nbr_results = 20
# regular query
# 常规查询(按欧式距离对结果排序)
res_reg = [w[1] for w in src.query(imlist[q_ind])[:nbr_results]]
print ('top matches (regular):', res_reg)
# load image features for query image
#载入查询图像特征
q_locs,q_descr = sift.read_features_from_file(featlist[q_ind])
fp = homography.make_homog(q_locs[:,:2].T)
# RANSAC model for homography fitting
#用单应性进行拟合建立RANSAC模型
model = homography.RansacModel()
rank = {}
# load image features for result
#载入候选图像的特征
for ndx in res_reg[1:]:
locs,descr = sift.read_features_from_file(featlist[ndx]) # because 'ndx' is a rowid of the DB that starts at 1
# get matches
matches = sift.match(q_descr,descr)
ind = matches.nonzero()[0]
ind2 = matches[ind]
tp = homography.make_homog(locs[:,:2].T)
# compute homography, count inliers. if not enough matches return empty list
try:
H,inliers = homography.H_from_ransac(fp[:,ind],tp[:,ind2],model,match_theshold=4)
except:
inliers = []
# store inlier count
rank[ndx] = len(inliers)
# sort dictionary to get the most inliers first
sorted_rank = sorted(rank.items(), key=lambda t: t[1], reverse=True)
res_geom = [res_reg[0]]+[s[0] for s in sorted_rank]
print ('top matches (homography):', res_geom)
# 显示查询结果
imagesearch.plot_results(src,res_reg[:8]) #常规查询
imagesearch.plot_results(src,res_geom[:8]) #重排后的结果
用一张图像进行查询的结果:
常规查询的结果:
对常规查询重新排序后的结果: