视觉进阶|计算机视觉及其后的图神经网络教程(第一部分)
概述
我在本文将回答那些不熟悉图或图神经网络的AI/ML/CV的用户通常会问的问题。我提供了Pytorch的例子来澄清这种相对新颖和令人兴奋的模型背后的思路。

问题
我在本部分教程中提出的问题是:
为什么图这种数据结构有用?
为什么在图上定义卷积是困难的?
什么使神经网络成为图神经网络?
为了回答这些问题,我将提供激励性的示例、论文和python代码,使其成为图神经网络(GNNs)的教程。读者需要一些基本的机器学习和计算机视觉知识,但是,我随着我的讲述我也会提供一些背景和直观的解释。
首先,让我们简单回顾一下什么是图?图是由有向/无向边连接的一组节点(顶点)。节点和边通常来自于关于问题的一些专家知识或直觉。因此,它可以是分子中的原子、社交网络中的用户、交通系统中的城市、团队运动中的运动员、大脑中的神经元、动态物理系统中的相互作用对象、图像中的像素、边界框或分割遮罩。换言之,在许多实际情况下,实际上是您决定了什么是图中的节点和边。
在许多实际情况下,实际上是你来决定图中的节点和边是什么。
这是一个非常灵活的数据结构,它概括了许多其他的数据结构。例如,如果没有边,那么它就成为一个集合;如果只有“垂直”边,并且任何两个节点正好由一条路径连接,那么我们就有一棵树。这种灵活性是好的和坏的,我将在本教程中讨论。
1. 为什么图这种数据结构有用?
在计算机视觉(cv)和机器学习(ml)的背景下,研究图形和从中学习的模型至少可以给我们带来四个好处:
1.1 我们可以更接近解决以前太具挑战性的重要问题,例如:癌症的药物发现(Veselkov等人,Nature,2019);更好地理解人脑连接体(Diez&Sepulcre,Nature Communications,2019);能源和环境挑战的材料发现(Xie等人,自然通讯,2019)。
1.2 在大多数cv/ml应用程序中,数据实际上可以看作是图,即使您曾经将它们表示为另一个数据结构。将你的数据表示为图形可以给你带来很多灵活性,并且可以给你一个非常不同和有趣的视角来看待你的问题。例如,您可以从“超级像素”学习,而不是从图像像素学习,如(Liang等人,ECCV2016)和我们即将发表的BMVC论文中所述。图还允许您在数据中施加一种关系归纳偏差-一些关于该问题的先验知识。例如,如果你想对人体姿势进行推理,你的关系偏差可以是人体骨骼关节的图(Yan等人,AAAI,2018);或者如果你想对视频进行推理,你的关系偏差可以是移动边界框的图(Wang&Gupta,ECCV2018)。另一个例子是将面部地标表示为图(Antonakos等人,CVPR,2015),以对面部属性和身份进行推理。
1.3 您最喜欢的神经网络本身可以看作是一个图,其中节点是神经元,边是权重,或者节点是层,边表示向前/向后传递的流(在这种情况下,我们讨论的是在tensorflow、pytorch和其他dl框架中使用的计算图)。应用程序可以是计算图的优化、神经结构搜索、分析训练行为等。
1.4 最后,您可以更有效地解决许多问题,其中数据可以更自然地表示为图形。这包括但不限于分子和社会网络分类(Knyazev et al.,Neurips-W,2018)和生成(Simonovsky&Komodakis,ICANN,2018)、三维网格分类和对应(Fey et al.,CVPR,2018)和生成(Wang et al.,ECCVV,2018)、动态交互对象的建模行为(Kipf et al.,ICML,2018),视觉场景图建模(见即将召开的ICcv研讨会)和问答(Narasimhan,Neurips,2018),程序合成(Allamanis等人,ICLR,2018),不同的强化学习任务(Bapst等人,ICML,2019)和许多其他令人兴奋的问题。
由于我之前的研究是关于识别和分析面部和情绪的,所以我特别喜欢下面这个图。

2. 为什么在图上定义卷积是困难的?
为了回答这个问题,我首先给出了一般使用卷积的一些动机,然后用图的术语来描述“图像上的卷积”,这应该使向“图上的卷积”的过渡更加平滑。
2.1 为什么卷积有用?
让我们理解为什么我们如此关心卷积,为什么我们想用它来绘制图形。与完全连接的神经网络(a.k.a.nns或mlps)相比,卷积网络(a.k.a.cnns或convnets)具有以下根据一辆漂亮的老雪佛兰的图像解释的某些优点。

首先,ConvNets利用图像中的自然先验,在(Bronstein等人,2016)中对此进行了更正式的描述,例如
1.平移不变性-如果我们将上图中的汽车向左/向右/向上/向下平移,我们仍然应该能够将其识别为汽车。通过在所有位置共享过滤器,即应用卷积,可以利用这一点。
2.位置-附近的像素紧密相关,通常代表某种语义概念,例如滚轮或窗户。通过使用相对较大的滤波器可以利用这一点,该滤波器可以捕获局部空间邻域中的图像特征。
3.组成性(或层次结构)-图像中较大的区域通常是其包含的较小区域的语义父级。例如,汽车是车门、车窗、车轮、驾驶员等的父对象,而驾驶员是头部、手臂等的父对象。这是通过叠加卷积层和应用池隐式利用的。
其次,卷积层中可训练参数(即滤波器)的数量不取决于输入维数,因此从技术上讲,我们可以在28×28和512×512图像上训练完全相同的模型。换句话说,模型是参数化的。
理想情况下,我们的目标是开发一种与Graph Neural Nets一样灵活的模型,可以从任何数据中进行摘要和学习,但是与此同时,我们希望通过打开/关闭某些先验条件来控制(调节)这种灵活性的因素。
所有这些出色的属性使ConvNets不太容易过度拟合(训练集的准确性较高,而验证/测试集的准确性较低),在不同的视觉任务中更为准确,并且可以轻松地扩展到大型图像和数据集。 因此,当我们要解决输入数据采用图结构的重要任务时,将所有这些属性转移到图神经网络GNN以规范其灵活性并使其具有可扩展性就很有吸引力。 理想情况下,我们的目标是开发一种与GNN一样灵活的模型,并且可以从任何数据中进行摘要和学习,但是与此同时,我们希望通过打开/关闭某些先验条件来控制(调节)这种灵活性的因素。 这可以打开许多有趣方向的研究。 然而,控制这种折衷是具有挑战性的。
2.2 用图对图像进行卷积
让我们考虑一个具有N个节点的无向图G。 边E表示节点之间的无向连接。 节点和边通常来自您对问题的直觉。 对于图像,我们的直觉是节点是像素或超像素(一组怪异形状的像素),边缘是它们之间的空间距离。 例如,左下方的MNIST图像通常表示为28×28尺寸的矩阵。 我们也可以将其表示为一组N = 28 * 28 = 784像素。 因此,我们的图形G将具有N = 784个节点,并且边缘位置较近的像素的边缘将具有较大的值(下图中的较厚边缘),而远程像素的边缘将具有较小的值(较薄的边缘)。

当我们在图像上训练神经网络或ConvNets时,我们在图上隐式定义了图像-下图是一个规则的二维网格。 由于此网格对于所有训练和测试图像都是相同的,并且是规则的,即,网格的所有像素在所有图像上都以完全相同的方式彼此连接(即,具有相同的邻居数,边长等)。 则此规则网格图没有任何信息可帮助我们将一个图像与另一个图像区分开。 下面,我可视化一些2D和3D规则网格,其中节点的顺序用颜色编码。 顺便说一句,我正在Python中使用NetworkX来做到这一点,e.g. G = networkx.grid_graph([4, 4])。

有了这个4×4的规则网格,让我们简要地看一下2D卷积的工作原理,以了解为什么很难将此运算符转换为图形。 规则网格上的过滤器具有相同的节点顺序,但是现代卷积网络通常具有较小的滤波器,例如下面的示例中的3×3。 该滤波器具有9个值:W 1,W 2,…,W 3,这是我们在使用反向传播器进行训练期间正在更新的值,以最大程度地减少损耗并解决下游任务。 在下面的示例中,我们试探性地将此过滤器初始化为边缘检测器。

当我们进行卷积时,我们会在两个方向上滑动该滤波器:向右和向底部滑动,但是没有什么可以阻止我们从底角开始—重要的是要在所有可能的位置滑动。 在每个位置,我们计算网格上的值(用X表示)与滤镜值W之间的点积:W:X₁W₁+ X₂W₂ +…+X₉W₉,并将结果存储在输出图像中。 在我们的可视化中,我们在滑动过程中更改节点的颜色以匹配网格中节点的颜色。 在常规网格中,我们总是可以将X₂W₂的节点与网格的节点进行匹配。 不幸的是,对于图而言,情况并非如此,我将在下面进行解释。

上面使用的点积是所谓的“聚合运算符”之一。 广义上讲,聚合运算符的目标是将数据汇总为简化形式。 在上面的示例中,点积将3×3矩阵汇总为单个值。 另一个示例是ConvNets中的池化。 请记住,最大池或总池之类的方法是置换不变的,即,即使您随机改组该区域内的所有像素,它们也会从空间区域中合并相同的值。 为了明确起见,点积不是排列不变的,仅仅是因为通常:X₁W₁+X₂W₂ ≠X₂W₁+X₁W₂。
现在,让我们使用我们的MNIST图像并说明常规网格,滤波器和卷积的含义。 请记住我们的图形术语,这个规则的28×28网格将成为我们的图形G,因此该网格中的每个单元都是一个节点,并且节点特征是实际的图像X,即每个节点将只有一个特征-像素 强度从0(黑色)到1(白色)。

接下来,我们定义一个滤波器,并使其成为具有一些(几乎)任意参数的著名Gabor滤波器。 一旦有了图像和滤波器,我们就可以通过在该图像上滑动滤波器(在本例中为7位)并将点积的结果放置到输出矩阵上来执行卷积。
 mark
mark
这一切都很酷,但是正如我之前提到的,当您尝试将卷积推广到图时,这变得很棘手。
节点是一个集合,该集合的任何排列都不会更改它。因此,人们应用的聚合运算符应该是不变排列的
正如我已经提到的,上面用于计算每个步骤的卷积的点积对顺序很敏感。 这种灵敏度使我们能够学习类似于Gabor滤波器的边缘检测器,这对于捕获图像特征很重要。 问题在于,在图中没有明确定义的节点顺序,除非您学会对节点进行排序,或者想出一些启发式方法,否则将导致图与图之间的顺序一致(规范)。 简而言之,节点是一个集合,并且此集合的任何排列都不会更改它。 因此,人们应用的聚合运算符应该是不变排列的。 最受欢迎的选择是所有邻居的平均值(GCN,Kipf&Welling,ICLR,2017)和求和(GIN,Xu et al。,ICLR,2019),即求和或均值合并,然后通过可训练向量W进行投影。 有关其他聚合器,请参见(Hamilton等人,NIPS,2017)。

例如,对于上面左上方的图,节点1的求和聚合器的输出为X₁=(X₁+X₂ +X₃+X₄)W₁,对于节点2:X₂ =(X₁+ X₂ +X₃+X₅) W₁等对于节点3、4和5,即我们需要将此聚合器应用于所有节点。结果,我们将获得具有相同结构的图,但是节点特征现在将包含邻居特征。我们可以使用相同的想法在右边处理图形。
通俗地讲,人们称这种平均或求和为“卷积”,因为我们也从一个节点“滑动”到另一个节点,并在每个步骤中应用一个聚合运算符。 但是,请务必记住,这是一种非常特殊的卷积形式,其中的滤波器没有方向感。 下面,我将展示这些滤波器的外观,并给出如何使它们变得更好的想法。
3. 是什么使神经网络成为图神经网络
您知道经典神经网络是如何工作的,对吗? 我们有一些C维特征X作为网络的输入。 使用我们正在运行的MNIST示例,X将成为我们的C = 784维像素特征(即“展平”的图像)。 这些特征乘以我们在训练期间更新的C×F维度权重W,以使输出更接近我们的期望。 结果可以直接用于解决任务(例如,在回归的情况下),也可以进一步馈入某种非线性(激活),如ReLU或其他可微分(或更精确地,可微分)的函数以形成多层网络。 通常,某些层的输出为:

MNIST中的信号是如此强大,以至于只要使用上面的公式和交叉熵损失,就可以得到91%的准确度,而没有任何非线性和其他技巧(我使用了经过稍微修改的PyTorch示例来做到这一点)。这种模型称为多项式(或多类,因为我们有10类数字)逻辑回归。
现在,我们如何把普通的神经网络转换成图神经网络呢?正如您已经知道的,GNNs背后的核心思想是通过“邻居”进行聚合。在这里,重要的是要理解,在许多情况下,实际上是您指定了“邻居”。
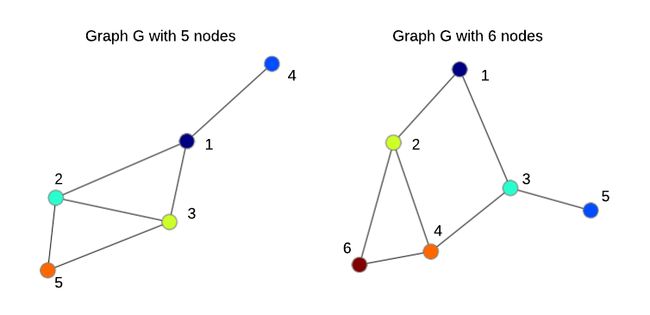
让我们先考虑一个简单的情况,当您得到一些图形时。例如,这可以是一个具有5个人的社交网络的片段(子图),一对节点之间的一条边表示两个人是否是朋友(或者其中至少一个人是这样认为的)。右下图中的邻接矩阵(通常表示为A)是一种以矩阵形式表示这些边的方法,对于我们的深度学习框架而言非常方便。矩阵中的黄色单元格代表边缘,而蓝色表示没有边缘。

现在,让我们基于像素坐标为我们的MNIST示例创建一个邻接矩阵A(文章末尾提供了完整的代码):
import numpy as np
from scipy.spatial.distance import cdist
img_size = 28 # MNIST 图片长宽
col, row = np.meshgrid(np.arange(img_size), np.arange(img_size))
coord = np.stack((col, row), axis=2).reshape(-1, 2) / img_size
dist = cdist(coord, coord) # 见左下图
sigma = 0.2 * np.pi # 高斯分布宽度
A = np.exp(- dist / sigma ** 2) # 见下图中间
这是为视觉任务定义邻接矩阵的一种典型方法,但并非唯一方法(Defferrard等,NIPS,2016;Bronstein等,2016)。该邻接矩阵是我们的先验矩阵,也就是我们的归纳偏差,我们根据直觉将附近的像素连接在一起,而远端像素则不应该或应该具有非常薄的边缘(较小的边缘),以此强加给模型。这是由于观察的结果,即在自然图像中,附近的像素通常对应于同一对象或频繁交互的对象(我们在第2.1节中提到的局部性原理),因此连接此类像素非常有意义。

因此,现在,不仅有特征X,我们还有一些花哨的矩阵A,其值在[0,1]范围内。重要的是要注意,一旦我们知道输入是一个图,我们就假定没有规范的节点顺序在数据集中的所有其他图上都是一致的。就图像而言,这意味着假定像素是随机混洗的。在实践中,找到节点的规范顺序在组合上是无法解决的。即使从技术上来说,对于MNIST,我们可以通过知道此顺序来作弊(因为数据最初来自常规网格),但它不适用于实际的图数据集。
请记住,我们的特征矩阵X具有????行和C列。因此,就图形而言,每一行对应一个节点,C是节点特征的维数。但是现在的问题是我们不知道节点的顺序,所以我们不知道将特定节点的特征放在哪一行。如果我们只是假装忽略此问题并像以前一样直接将X馈送到MLP,则效果将与馈送具有随机混排像素的图像相同,并且每个图像具有独立的(每个时期都相同)混排!令人惊讶的是,神经网络原则上仍可以拟合此类随机数据(Zhang等人,ICLR,2017年),但是测试性能将接近于随机预测。解决方案之一是通过以下方式简单地使用我们之前创建的邻接矩阵A
 mark
mark
我们只需要确保A中的第i行对应于X中第i行中的节点的特征即可。在这里,我使用????而不是普通的A,因为您经常要对A进行归一化。如果????= A,则矩阵乘法 X 相当于对邻居的特征求和,这在许多任务中很有用(Xu et al。,ICLR,2019)。最常见的是对它进行归一化,以便????X????对邻居的特征取平均,即????= A /ΣᵢAᵢ。可以在(Kipf&Welling,ICLR,2017)中找到标准化矩阵A的更好方法。
以下是根据PyTorch代码对NN和GNN进行的比较:
import torch
import torch.nn as nn
C = 2 # 输入要素维数
F = 8 # 输出要素维数
W = nn.Linear(in_features=C, out_features=F) # 可训练的重量
# 全连接层
X = torch.randn(1, C) # 输入特征
Z = W(X) # 输出特征 : torch.Size([1, 8])
#G图神经网络层
N = 6 # Number of nodes in a graph
X = torch.randn(N, C) # 输入特征
A = torch.rand(N, N) # 邻接矩阵 (图中的边)
Z = W(torch.mm(A, X)) # 输出特征: torch.Size([6, 8])
这里是完整的PyTorch代码,可以训练以上两种模型:python mnist_fc.py --model fc 来训练神经网络; python mnist_fc.py --model graph 来训练图神经网络,作为练习,尝试随机调整图神经网络代码中的像素,不要忘记以相同的方式调整矩阵A,并确保它不会影响结果。
运行代码后,您可能会注意到分类精度实际上是相同的。有什么问题?图形网络不是应该更好地工作吗?好吧,在许多情况下都是这样。但不是在这一本书中,因为我们添加的????X⁽ˡ⁾运算符实际上不算什么,而是一个高斯滤波器:
因此,我们的图神经网络等效于带有单个高斯滤波器的卷积神经网络,我们在训练期间从不更新,其次是完全连接的层。该滤镜基本上可以模糊/平滑图像,这并不是一件特别有用的事情(请参见右上方的图像)。但是,这是图神经网络的最简单变体,但它在图结构化数据上的效果很好。为了使GNN在图像之类的规则图上更好地工作,我们需要应用许多技巧。例如,代替使用预定义的高斯滤波器,我们可以学习使用类似这样的微分函数来预测任意一对像素之间的边缘:
import torch.nn as nn # 使用 PyTorch
nn.Sequential(nn.Linear(4, 64), # 将坐标映射到隐藏层
nn.ReLU(), # 非线性
nn.Linear(64, 1), # 将隐藏的表示映射到边缘
nn.Tanh()) # 将边值压缩为[-1,1]
为了使GNN在图像之类的规则图上更好地工作,我们需要应用许多技巧。例如,代替使用预定义的高斯滤波器,我们可以学习预测任何一对像素之间的边缘
这个想法类似于动态过滤器网络(Brabander等,NIPS,2016),边缘条件图网络(ECC,Simonovsky&Komodakis,CVPR,2017)和(Knyazev等,NeurIPS-W,2018)。要使用我的代码进行尝试,您只需要添加--pred_edge标志,因此整个命令是python mnist_fc.py --model graph --pred_edge. 下面,我显示了预定义的高斯和学习滤波器的动画。您可能会注意到,我们刚刚学习的过滤器(在中间)看起来很奇怪。这是因为任务很复杂,因为我们同时优化了两个模型:预测边缘的模型和预测数字类的模型。要学习更好的过滤器(如右边的过滤器),我们需要应用BMVC论文中的其他技巧,而这超出了本教程的范围。
 mark
mark
生成这些GIF的代码非常简单:
import imageio # to save GIFs
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
from scipy.spatial.distance import cdist
import cv2 # 可选 (调整滤波器大小以使其看起来更好)
img_size = 28
# 创建/加载一些邻接矩阵A(例如,基于坐标)
col, row = np.meshgrid(np.arange(img_size), np.arange(img_size))
coord = np.stack((col, row), axis=2).reshape(-1, 2) / img_size
dist = cdist(coord, coord) # 所有像素对之间的距离
sigma = 0.2 * np.pi # 高斯宽度 (训练模型时可以是超参数)
A = np.exp(- dist / sigma ** 2) # 空间相似度邻接矩阵
scale = 4
img_list = []
cmap = mpl.cm.get_cmap('viridis')
for i in np.arange(0, img_size, 4): # 对于第4步的每一行
for j in np.arange(0, img_size, 4): # 对于第4步中的每个col
k = i*img_size + j
img = A[k, :].reshape(img_size, img_size)
img = (img - img.min()) / (img.max() - img.min())
img = cmap(img)
img[i, j] = np.array([1., 0, 0, 0]) # 加红点
img = cv2.resize(img, (img_size*scale, img_size*scale))
img_list.append((img * 255).astype(np.uint8))
imageio.mimsave('filter.gif', img_list, format='GIF', duration=0.2)
我还分享了一个IPython笔记本,该笔记本显示了使用Gabor滤波器对图像进行2D卷积的图表(使用邻接矩阵)与使用循环矩阵的情况(通常用于信号处理)的对比。
在本教程的下一部分中,我将介绍能够在图上生成更好的过滤器的更高级的图层。
结语
Graph Neural Networks是一个非常灵活和有趣的神经网络系列,可以应用于真正的复杂数据。与往常一样,这种灵活性必须付出一定的代价。在GNN的情况下,很难通过将此类算子定义为卷积来规范化模型。朝着这个方向的研究正在迅速发展,因此GNN将在越来越广泛的机器学习和计算机视觉领域中得到应用。