OpenCV—python 角点特征检测之二(SIFT、SURF、ORB)
角点检测
- 一、SIFT(Scale-Invariant Feature Trans-form)
- 1.1 尺度空间极值检测
- 1.2关键点(极值点)定位
- 1.3 为关键点(极值点)指定方向参数
- 1.4 关键点描述符
- 1.5 关键点匹配
- 二、 SURF(Speeded-Up Robust Features)
- 三、ORB算法
- BFMatcher()函数
- 3.1 ORB直接使用暴力匹配
- 3.2 SURF和SIFT算法+暴力匹配BFMatcher
- 3.3 K-近邻匹配(KNN)
一、SIFT(Scale-Invariant Feature Trans-form)
D.Lowe 于2004 年提出了一个新的算法:尺度不变特征变换(SIFT),这个算法可以帮助我们提取图像中的关键点并计算它们的描述符。Sift特征匹配算法可以处理两幅图像之间发生平移、旋转、尺度缩放、亮度变化、仿射变换情况下的匹配问题,具有很强的匹配能力。在Mikolajczyk对包括Sift算子在内的十种局部描述子所做的不变性对比实验中,Sift及其扩展算法已被证实在同类描述子中具有最强的健壮性。
其应用范围包含物体辨识、机器人地图感知与导航、影像缝合、3D模型建立、手势辨识、影像追踪和动作比对。局部影像特征的描述与侦测可以帮助辨识物体,SIFT 特征是基于物体上的一些局部外观的兴趣点而与影像的大小和旋转无关。对于光线、噪声、些微视角改变的容忍度也相当高。
SIFT算法的实质是:“不同的尺度空间上查找关键点(特征点),并计算出关键点的方向” 。
- 独特性好 信息量丰富,适用于在海量特征数据库中进行快速、准确的匹配。
- 多量性 即使少数的几个物体也可以产生大量Sift特征向量。
- 速度相对较快 经优化的Sift匹配算法甚至可以达到实时的要求。
- 可扩展性强 可以很方便的与其他形式的特征向量进行联合。
SIFT 算法主要由四步构成:
1.1 尺度空间极值检测
尺度空间滤波器可以使用一些列具有不同方差 σ 的高斯卷积核构成。
使用具有不同方差值 σ 的高斯拉普拉斯算子LoG( Laplacion of Gaussian)对图像进行卷积,LoG 由于具有不同的方差值 σ 所以可以用来检测不同大小的斑点(当 LoG 的方差 σ 与斑点直径相等时能够使斑点完全平滑)。
简单来说方差 σ 就是一个尺度变换因子:
高斯方差的大小与窗口的大小存在一个倍数关系:窗口大小等于 6 倍方差加 1,所以方差的大小也决定了窗口大小。由于 LoG 的计算量非常大,所以 SIFT 算法使用高斯差分算子(Difference of Gaussians)近似LoG算子来进行极值检测:
D ( x , y , σ ) = ( G ( x , y , k σ ) − G ( x , y , σ ) ) ⨂ I ( x , y ) = L ( x , y , k σ ) − L ( x , y , σ ) D(x,y,σ)=(G(x,y,kσ)− G (x,y,σ))\bigotimes I(x,y)=L(x,y,kσ)−L(x,y,σ) D(x,y,σ)=(G(x,y,kσ)−G(x,y,σ))⨂I(x,y)=L(x,y,kσ)−L(x,y,σ)
由上式可以看出,高斯差分算子(Difference of Gaussians)是使用两个不同的 σ , k σ σ ,kσ σ,kσ来做高斯模糊差异而得到的。这里, ⨂ \bigotimes ⨂ 表示卷积操作, G ( x , y , σ ) G(x,y,σ) G(x,y,σ)为一个变化尺度的高斯(Gaussian )函数, I ( x , y ) I(x,y) I(x,y)表示原图像。
关于以上公式的推导过程或者算子的原理: 详情请点击。
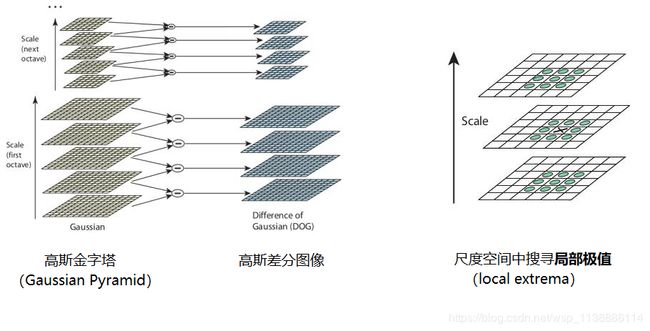
这里需要再解释一下图像金字塔,我们可以通过减少采样(如只取奇数行或奇数列)来构成一组图像尺寸(1,0.5,0.25 等)不同的金字塔,然后对这一组图像中的每一张图像使用具有不同方差 σ 的高斯卷积核构建出具有不同分辨率的图像金字塔(不同的尺度空间)。DoG 就是这组具有不同分辨率的图像金字塔中相邻的两层之间的差值。如下左图所示:
G ( x , y , σ ) = 1 2 π σ 2 e − ( x − m / 2 ) 2 + ( y − n / 2 ) 2 2 σ 2 G(x,y,σ)= \frac{1}{2πσ^2} e − \frac{(x−m/2)^2 +(y−n/2)^2}{2σ^2 } G(x,y,σ)=2πσ21e−2σ2(x−m/2)2+(y−n/2)2
m , n m,n m,n 表示高斯模板的维度(由 ( 6 σ + 1 ) ( 6 σ + 1 ) (6σ+1)(6σ+1) (6σ+1)(6σ+1)确定。 x , y x,y x,y 代表图像的像素位置。 σ σ σ是尺度空间因子,值越小表示图像被平滑的越少,相应的尺度也就越小。大尺度对应于图像的结构,小尺度对应于图像的细节纹理特征。
图像在尺度空间中搜寻局部极值(local extrema)。以下图为例,在图像中的某个像素点不但与其附近的8个像素点比较,而且与其前一层(previous scale)的9个像素点和下一层(next scale)的9个像素点进行比较(需为同一Octave)。如果该像素点是局部极值点,那么我们就认为它是一个潜在的KeyPoint(关键点)——最能代表这个scale的点
论文中给出了一些经验的值:octave(组)为4,scale layer(层)为5, σ = 1.6 , k = 2 σ=1.6,k=\sqrt{2} σ=1.6,k=2
1.2关键点(极值点)定位
一旦找到关键点,我们就要对它们进行修正从而得到更准确的结果。
作者使用尺度空间的泰勒级数展开来获得极值的准确位置,如果极值点的灰度值小于阈值(0.03)就会被忽略掉。在 OpenCV 中这种阈值被称为contrastThreshold。
DoG 算法对边界非常敏感,所以我们必须要把边界去除。前面我们讲的Harris 算法除了可以用于角点检测之外还可以用于检测边界。作者就是使用了同样的思路。作者使用 2x2 的 Hessian 矩阵计算主曲率(principal curvature)H如下:
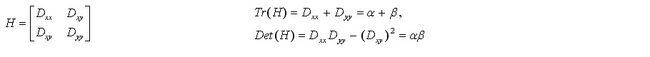 H的特征值 α α α 和 β β β 分别代表 x 和 y 方向的梯度。
H的特征值 α α α 和 β β β 分别代表 x 和 y 方向的梯度。
从 Harris 角点检测的算法中,我们知道当一个特征值远远大于另外一个特征值时检测到的是边界。所以他们使用了一个简单的函数,如果比例高于阈值(OpenCV 中称为边界阈值),这个关键点就会被忽略。文章中给出的边界阈值为 10。
所以低对比度的关键点和边界关键点都会被去除掉,剩下的就是我们感兴趣的关键点了。
1.3 为关键点(极值点)指定方向参数
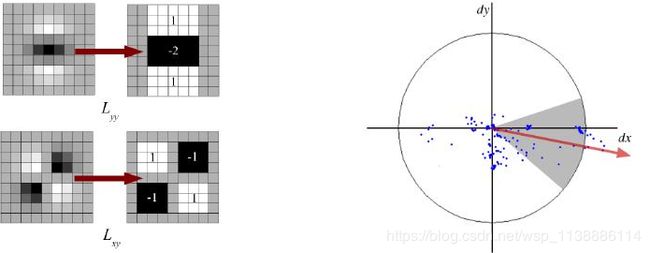
现在我们要为每一个关键点赋予一个反向参数,这样它才会具有旋转不变性。获取关键点(所在尺度空间)的邻域,然后计算这个区域的梯度级和方向。根据计算得到的结果创建一个含有 36 个 bins(每 10 度一个 bin)的方向直方图。(使用当前尺度空间 σ 值的 1.5 倍为方差的圆形高斯窗口和梯度级做权重)。
直方图中的峰值为主方向参数,如果其他的任何柱子的高度高于峰值的80% 被认为是辅方向。这就会在相同的尺度空间相同的位置构建除具有不同方向的关键点。这对于匹配的稳定性会有所帮助。
1.4 关键点描述符
新的关键点描述符被创建了。选取与关键点周围一个 16x16 的邻域,把它分成 16 个 4x4 的小方块,为每个小方块创建一个具有 8 个 bin 的方向直方图。总共加起来有 128 个 bin。由此组成长为 128 的向量就构成了关键点描述符。除此之外还要进行几个测量以达到对光照变化,旋转等的稳定性。
1.5 关键点匹配
下一步就可以采用关键点特征向量的 欧式距离 来作为两幅图像中关键点的相似性判定度量。取第一个图的某个关键点,通过遍历找到第二幅图像中的距离最近的那个关键点。
但有些情况下,第二个距离最近的关键点与第一个距离最近的关键点靠的太近。这可能是由于噪声等引起的。此时要计算最近距离与第二近距离的比值。如果比值大于 0.8,就忽略掉。这会去除 90% 的错误匹配,同时只去除 5% 的正确匹配。
SIFT算法在 opencv-contrib-python=3.4.3之后专利收费。执行以下命令:
pip uninstall opencv-python #卸载之前用的
pip install opencv-contrib-python==3.4.2.16
两个小案例:
import cv2
imgpath = './jianzhu_01.jpg'
img = cv2.imread(imgpath)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 创建SIFT对象
sift = cv2.xfeatures2d.SIFT_create()
keypoints, descriptor = sift.detectAndCompute(gray, None)
img = cv2.drawKeypoints(image=img,
outImage=img,
keypoints = keypoints,
flags=cv2.DRAW_MATCHES_FLAGS_DEFAULT,
color = (51, 163, 236))
cv2.imshow('sift_jianzhu_01', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
import cv2
import numpy as np
def sift_func(img_path1,img_path2):
img_1 = cv2.imread(img_path1)
img_2 = cv2.imread(img_path2)
gray_1 = cv2.cvtColor(img_1, cv2.COLOR_BGR2GRAY)
gray_2 = cv2.cvtColor(img_2, cv2.COLOR_BGR2GRAY)
# SIFT特征计算
sift = cv2.xfeatures2d.SIFT_create()
psd_kp1, psd_des1 = sift.detectAndCompute(gray_1, None)
psd_kp2, psd_des2 = sift.detectAndCompute(gray_2, None)
# Flann特征匹配
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
matches = flann.knnMatch(psd_des1, psd_des2, k=2)
goodMatch = []
for m, n in matches:
# goodMatch是经过筛选的优质配对,如果2个配对中第一匹配的距离小于第二匹配的距离的1/2,
# 基本可以说明这个第一配对是两幅图像中独特的,不重复的特征点,可以保留。
if m.distance < 0.50*n.distance:
goodMatch.append(m)
# 增加一个维度
goodMatch = np.expand_dims(goodMatch, 1)
print(goodMatch[:20])
img_out = cv2.drawMatchesKnn(img_1, psd_kp1,
img_2, psd_kp2,
goodMatch[:20], None, flags=2)
return img_out
if __name__ == '__main__':
img_path1 = 'shanghai_01.png'
img_path2 = 'shanghai_02.png'
img_out = sift_func(img_path1, img_path2)
cv2.imshow('image', img_out)
cv2.waitKey(0)
cv2.destroyAllWindows()

二、 SURF(Speeded-Up Robust Features)
在 2006 年Bay,H.,Tuytelaars,T. 和 Van Gool,L 共同提出了 SURF(加速稳健特征)算法。跟它的名字一样,这是个算法是加速版的 SIFT。
在 SIFT 中,Lowe 在构建尺度空间时使用 DoG 对 LoG 进行近似。SURF使用盒子滤波器(box_filter)对 LoG 进行近似。下图显示了这种近似。在进行卷积计算时可以利用积分图像(积分图像的一大特点是:计算图像中某个窗口内所有像素和时,计算量的大小与窗口大小无关),是盒子滤波器的一大优点。而且这种计算可以在不同尺度空间同时进行。同样 SURF 算法计算关键点的尺度和位置是也是依赖与 Hessian 矩阵行列式的。
为了保证特征矢量具有选装不变形,需要对于每一个特征点分配一个主要方向。需要以特征点为中心,以 6s(s 为特征点的尺度)为半径的圆形区域内,对图像进行 Harr 小波相应运算。这样做实际就是对图像进行梯度运算,但是利用积分图像,可以提高计算图像梯度的效率,为了求取主方向值,需哟啊设计一个以方向为中心,张角为 60 度的扇形滑动窗口,以步长为 0.2 弧度左右旋转这个滑动窗口,并对窗口内的图像 Haar 小波的响应值进行累加。主方向为最大的 Haar 响应累加值对应的方向。在很多应用中根本就不需要旋转不变性,所以没有必要确定它们的方向,如果不计算方向的话,又可以使算法提速。SURF 提供了成为 U-SURF 的功能,它具有更快的速度,同时保持了对 +/-15 度旋转的稳定性。OpenCV 对这两种模式同样支持,只需要对参数upright 进行设置,当 upright 为 0 时计算方向,为 1 时不计算方向,同时速度更快。
import cv2
imgpath = 'varese.jpg'
img = cv2.imread(imgpath)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 创建SIFT对象
sift = cv2.xfeatures2d.SURF_create(float(4000))
keypoints, descriptor = sift.detectAndCompute(gray, None)
img = cv2.drawKeypoints(image=img,
outImage=img,
keypoints = keypoints,
flags=cv2.DRAW_MATCHES_FLAGS_DEFAULT,
color = (51, 163, 236))
cv2.imshow('sift_keypoints', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
三、ORB算法
对比SURF和SIFT算法,ORB算法更处于起步阶段,在2011年才首次发布。但比前两者的速度更快。ORB基于FAST关键点检测和BRIEF的描述符技术相结合。
- FAST:特征检测算法。
- BRIEF:只是一个描述符,这是图像一种表示方式,可以比较两个图像的关键点描述符,可作为特征匹配的一种方法。
通过以下一些函数实现,我们可以使用for循环来匹配图库中我们需要的图片(分类),检测图像相似度等一系列的操作。
BFMatcher()函数
函数参数及详情如下:
"""
BFMatcher()
normType:NORM_L1, NORM_L2, NORM_HAMMING, NORM_HAMMING2。
NORM_L1 和 NORM_L2是 SIFT和SURF描述符的优先选择,
NORM_HAMMING 和 NORM_HAMMING2 是用于ORB算法
matches 是DMatch对象,具有以下属性:
DMatch.distance - 描述符之间的距离。 越低越好。
DMatch.trainIdx - 训练描述符中描述符的索引
DMatch.queryIdx - 查询描述符中描述符的索引
DMatch.imgIdx - 训练图像的索引。
"""
3.1 ORB直接使用暴力匹配
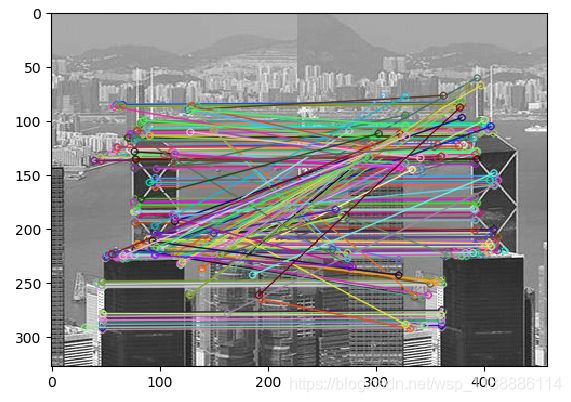
暴力匹配:比较两个描述符并产生匹配结果。使用ORB检测关键点之外,还将两图进行匹配,匹配的图像如下
实现方法:首先分别对两图进行ORB处理,然后将两图的关键点进行暴力匹配。具体代码如下:
import cv2
from matplotlib import pyplot as plt
def match_ORB():
img1 = cv2.imread('./gggg/001.png',0)
img2 = cv2.imread('./gggg/002.png',0)
# 使用ORB特征检测器和描述符,计算关键点和描述符
orb = cv2.ORB_create()
kp1, des1 = orb.detectAndCompute(img1,None)
kp2, des2 = orb.detectAndCompute(img2,None)
bf = cv2.BFMatcher(normType=cv2.NORM_HAMMING, crossCheck=True)
matches = bf.match(des1,des2)
matches = sorted(matches, key = lambda x:x.distance)
img3 = cv2.drawMatches(img1=img1,keypoints1=kp1,
img2=img2,keypoints2=kp2,
matches1to2=matches,
outImg=img2, flags=2)
return img3
if __name__ == '__main__':
img3 = match_ORB()
plt.imshow(img3)
plt.show()
3.2 SURF和SIFT算法+暴力匹配BFMatcher
暴力匹配BFMatcher是一种匹配方法,只要提供两个关键点即可实现匹配。下例中使用SURF和SIFT算法:
import time
import cv2
from matplotlib import pyplot as plt
def match_ORB():
img1 = cv2.imread('./gggg/001.png', 0)
img2 = cv2.imread('./gggg/002.png', 0)
# 使用SURF_create特征检测器 和 BFMatcher描述符
orb = cv2.xfeatures2d.SURF_create(float(3000))
kp1, des1 = orb.detectAndCompute(img1, None)
kp2, des2 = orb.detectAndCompute(img2, None)
bf = cv2.BFMatcher(normType=cv2.NORM_L1, crossCheck=True)
matches = bf.match(des1, des2)
matches = sorted(matches, key=lambda x: x.distance)
img3 = cv2.drawMatches(img1=img1, keypoints1=kp1,
img2=img2, keypoints2=kp2,
matches1to2=matches, outImg=img2,
flags=2)
return img3
if __name__ == '__main__':
start_time = time.time()
img3 = match_ORB()
plt.imshow(img3)
plt.show()
end_time = time.time()
print("Total Spend time:", str((end_time - start_time) / 60)[0:6] + "分钟")
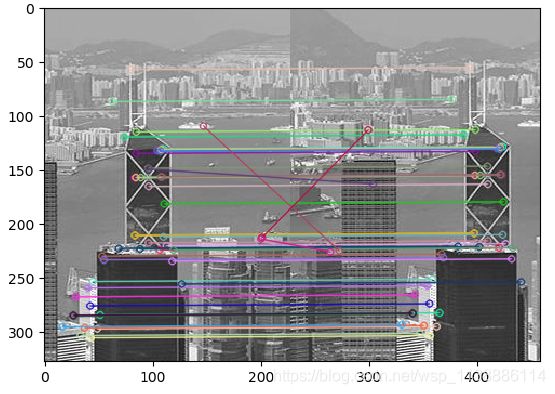
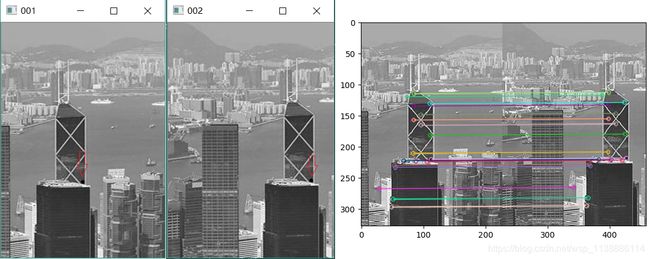
输出匹配点。关于cv2.rectangle()函数请查看 https://blog.csdn.net/wsp_1138886114/article/details/82945328
import time
import cv2
from matplotlib import pyplot as plt
def match_ORB():
img1 = cv2.imread('./gggg/001.png', 0)
img2 = cv2.imread('./gggg/002.png', 0)
# 使用SURF_create特征检测器 和 BFMatcher描述符
orb = cv2.xfeatures2d.SURF_create(float(3000))
kp1, des1 = orb.detectAndCompute(img1, None)
kp2, des2 = orb.detectAndCompute(img2, None)
# matches是DMatch对象,DMatch是以列表的形式表示,每个元素代表两图能匹配得上的点。
bf = cv2.BFMatcher(normType=cv2.NORM_L1, crossCheck=True)
matches = bf.match(des1, des2)
matches = sorted(matches, key=lambda x: x.distance)
# =========================== 输出匹配的坐标 ===================================
# kp1的索引由DMatch对象属性为queryIdx决定,kp2的索引由DMatch对象属性为trainIdx决定
# 获取001.png的关键点位置。可以遍历matches[:20]前20个最佳的匹配点
x, y = kp1[matches[0].queryIdx].pt
print(x,y)
cv2.rectangle(img1, (int(x), int(y)), (int(x) + 2, int(y) + 2), (0, 0, 255), 2)
cv2.imshow('001', img1)
cv2.waitKey(0)
# 获取002.png的关键点位置
x2, y2 = kp2[matches[0].trainIdx].pt
print(x2,y2)
cv2.rectangle(img2, (int(x2), int(y2)), (int(x2) + 2, int(y2) + 2), (0, 0, 255), 2)
cv2.imshow('002', img2)
cv2.waitKey(0)
cv2.destroyAllWindows()
# ==============================================================================
# 使用plt将两个图像的第一个匹配结果显示出来
img3 = cv2.drawMatches(img1=img1, keypoints1=kp1,
img2=img2, keypoints2=kp2,
matches1to2=matches[:20], outImg=img2,
flags=2)
return img3
if __name__ == '__main__':
start_time = time.time()
img3 = match_ORB()
plt.imshow(img3)
plt.show()
end_time = time.time()
print("Total Spend time:", str((end_time - start_time) / 60)[0:6] + "分钟")
3.3 K-近邻匹配(KNN)
KNN是机器学习中算法中最为简单的算法。使用KNN匹配,实现代码如下:
import cv2
from matplotlib import pyplot as plt
img1 = cv2.imread('./gggg/001.png', 0)
img2 = cv2.imread('./gggg/002.png', 0)
# 使用ORB特征检测器和描述符,计算关键点和描述符
orb = cv2.ORB_create()
kp1, des1 = orb.detectAndCompute(img1,None)
kp2, des2 = orb.detectAndCompute(img2,None)
bf = cv2.BFMatcher(normType=cv2.NORM_HAMMING, crossCheck=True)
# knnMatch 函数参数k是返回符合匹配的个数,暴力匹配match只返回最佳匹配结果。
matches = bf.knnMatch(des1,des2,k=1)
# 使用plt将两个图像的第一个匹配结果显示出来
# 若使用knnMatch进行匹配,则需要使用drawMatchesKnn函数将结果显示
img3 = cv2.drawMatchesKnn(img1=img1,keypoints1=kp1,
img2=img2,keypoints2=kp2,
matches1to2=matches[:40],
outImg=img2, flags=2)
plt.imshow(img3)
plt.show()
# 结果与上图无异,这里不展示了。
参考与鸣谢:
匹配:https://blog.csdn.net/HuangZhang_123/article/details/80660688
高斯算法复现:https://blog.csdn.net/qq_32211827/article/details/72758090
LoG与DOG算子:https://blog.csdn.net/wsp_1138886114/article/details/81368890
https://blog.csdn.net/robinhjwy/article/details/77620924
http://www.bubuko.com/infodetail-2498014.html