常见CNN网络创新点
这篇文章主要介绍卷积神经网络1998年到2019年的20多种经典的网络,体会每种网络的前世今身以及包含的深邃思想。算是一个总结性的博客吧。。。
目录
一、1998年:LeNet
二、2012年:AlexNet
三、2013年:ZFNet
四、2014年:亚军——VGGNet
冠军——GoogLeNet
五、2015年:ResNet
六、2016年:DenseNet
七、2017年:SENet
一、1998年:LeNet
1988年,Yann LeCun(深度学习三巨头之一,2019年获得图灵奖)提出了用于手写字符识别的卷积网络模型LeNet5。其原理结构比较清晰,如图所示。当年,美国很多企业都采用了该模型用于识别现实场景中的数字,例如邮政编码、手写数字等,能够达到商用的程度,可见其在AI领域的开创性地位。
在论文中,LeNet5被用于识别MNIST数据集提供的10个数字。MNIST数据集在人工智能领域的作用是非常重要的,是当时Google实验室的Corinna Cortes和纽约大学的Yann LeCun共同建立的手写数字数据库,由60000张训练图片和10000张测试图片组成。该数据集提供的图片像素统一为28×28,图片中字符像素最大为20×20。

创新点:提出卷积神经网络
二、2012年:AlexNet
AlexNet是2012年提出的,当时AlexNet直接将ImageNet数据集的识别错误率从之前的非深度学习方法的28.2%降低到16.4%。AlexNet算是这波AI热潮的引爆点。

创新点:
- 更深的网络,增强了模型的表示能力。
- 成功添加了ReLU激活函数作为CNN的激活层,缓解了sigmoid激活函数的梯度消失问题,收敛也更快。
- 提出了局部响应归一化(Local Response Normalization,LRN),对局部神经元创建竞争机制,抑制反馈较少的神经元,增强模型的泛化能力。
- 设计并使用了Dropout以随机忽略部分神经元,从而避免出现模型过拟合的问题。
- 添加了裁剪、旋转等方式增强数据。
三、2013年:ZFNet
ZFNet是ImageNet分类任务2013年的冠军,其在AlexNet的结构上没有做多大改进。首先作者Matthew D Zeiler提出了一种新的可视化技术,该技术可以深入了解中间特征图的功能和分类器的操作。最终基于特征图的可视化结果发现以下两点:
-
AlexNet第一层中有大量的高频(边缘)和低频(非边缘)信息的混合,却几乎没有覆盖到中间的频率信息。
-
由于第一层卷积用的步长为4,太大,导致了有非常多的混叠情况,学到的特征不是特别好看,不像是后面的特征能看到一些纹理、颜色等。
可以看到ZFNet并没有特别出彩的地方,因此这一年的ImageNet分类竞赛算是比较平静的一届。

创新点:
- 将AlexNet的第一层的卷积核大小从11x11改成7x7。同时针对第二个问题将第一个卷积层的卷积核滑动步长从4改成2
- ZFNet将AlexNet的第3\4\5卷积层变为384\384\256
四、2014年:亚军——VGGNet
VGGNet是由Oxford的Visual Geometry Group提出的,在2014年的ImageNet比赛中,分别在定位和分类任务中取得了第一和第二的成绩。VGGNet相比于前面的AlexNet,仍然沿用了卷积加全连接的结构,但深度更深。VGGNet的论文全名为:Very Deep Convolutional Networks for Large-Scale Visual Recognition》。
VGG至今依然有很多人在使用,是非常经典和实用的网络。其证明了增加网络的深度能够在一定程度上提升网络的最终性能。VGG有两种结构,分别是VGG16和VGG19,二者之间没有本质的区别,只是网络深度不同。
我们来看一下VGGNet的具体网络结构:

创新点:
- 所有隐藏层都使用了ReLU激活函数,而不是LRN(Local Response Normalization),因为LRN浪费了更多了内存和时间并且性能没有太大提升。
- 使用更小的卷积核和更小的滑动步长。和AlexNet相比,VGG的卷积核大小只有和两种。卷积核的感受野很小,因此可以把网络加深,同时使用多个小卷积核使得网络总参数量也减少了。
冠军——GoogLeNet
稍加注意,我们可以发现,VGG、AlexNet的绝大部分参数集中在最后几个全连接(FC)层,然而FC组件不仅参数多,而且容易过拟合,之后便有了NIN。NIN使用1×1卷积核创造性地解决了这个问题,极大地降低了参数量,同时还提升了效果。
受到NIN的启发,Google的研究小组提出了Inception模块——一种高效表达特征的稀疏性结构,主要是增加对尺度的适应性,达到提升特征表达能力的效果。Inception的结构如图所示。
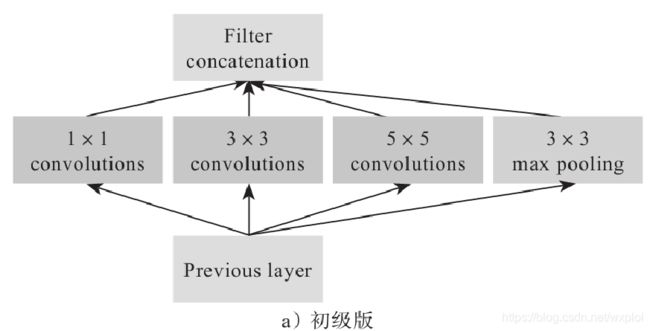
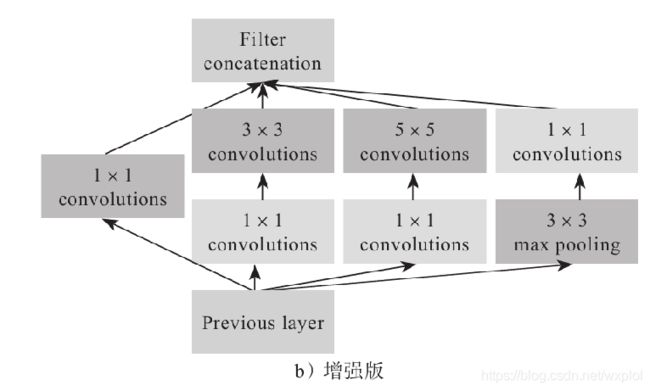
创新点:
- 提出Inception模块
- 使用辅助Loss
- 全连接层用简单的平均池化代替
五、2015年:ResNet
从前面介绍的网络中我们可以发现,随着网络深度的增加,模型的准确度也在同步提高。但是,网络加深的同时也一直无法摆脱一个问题:梯度消失现象越发明显。在梯度回传的过程中,比较靠前的梯度会很小,这意味着某些层基本上得不到更新,因此增加深度也就变得没有意义,反而徒增计算量。而且随着网络深度的增加,参数量更大,优化也变得更加困难。凭借增加网络深度来提升性能有时反而会出现更大的误差。这时,残差网络(Residual Network)的出现极大地缓解了这个问题。
2015年,微软亚洲研究院的何凯明等人提出了深度残差网络(Deep Residual Network[8]),它在当年的ImageNet竞赛中获得冠军。该网络简称为ResNet(由算法Residual命名),层数达到了152层,top-5的错误率降到了3.57%,而2014年的冠军GoogLeNet的错误率是6.7%。ResNet的结构如图所示。

ResNet通过逐层保留的方式,保持了模型各层级的特征信息,一定程度上解决了梯度消失的问题,而且快捷连接的方式也很少产生额外的参数。这些优点促使ResNet逐渐成为各大检测、分割等算法的基础框架。
残差为什么有效?
引入残差网络(跳跃连接),这个残差结构实际上就是一个差分方放大器,使得映射F(x)对输出的变化更加敏感。这个结构不仅改善了网络越深越难训练的缺点还加快了模型的收敛速度。
六、2016年:DenseNet
受到ResNet的启发,DenseNet于2016年被提出来。DenseNet将每个卷积层网络的输入变为前面所有网络输出的拼接。这种稠密的方式使得每层都可以利用之前学习到的所有特征,无须重复学习。同时,仿照ResNet的结构,梯度可以更好地传播,训练深层网络也变得更加方便。下面简单看一下DenseNet结构,如图所示。
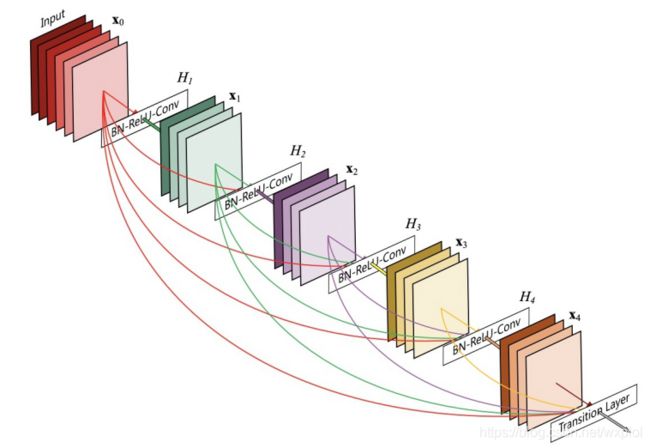
先前的网络因为使用了shortcut连接,网络已经变得越来越深了。接着引入了要介绍的DenseNet,正是利用了shortcut连接的思想,每一层都将前面所有层的特征图作为输入,最后使用concatenate来聚合信息。实验显示,DenseNet减轻了梯度消失问题,增大了特征重用,大大减少了参数量。DenseNet使用了concatenate来聚合不同的特征图,类似于ResNet残差的思想,提高了网络的信息和梯度流动,使得网络更加容易训练。
七、2017年:SENet
受到近几年Attention思想的启发,其主要思想是对每个输出通道(Channel)都预测一个权重,然后对每个通道进行加权,且是在2D空间做卷积。从本质上来说,其只对图像的空间信息进行建模,并没有对通道之间的信息建模,所以下面尝试对通道之间的信息进行建模。

对于每个输出通道,先执行系列的卷积Pooling操作Ftr之后,得到C×H×W大小的特征图。接下来,执行Squeeze和Excitation操作。
1)Squeeze:对C×H×W特征图执行Global Average Pooling操作,得到1×1×C大小的特征图,这个特征图可以理解为具有全局的感受野。
2)Excitation:使用一个全连接神经网络,对Squeeze之后的结果做非线性变换。
3)特征的重新标定:将Excitation得到的结果作为权重,使其与输入特征相乘。