【AI实战】手把手教你文字识别(识别篇:LSTM+CTC, CRNN, chineseocr方法)

文字识别是AI的一个重要应用场景,文字识别过程一般由图像输入、预处理、文本检测、文本识别、结果输出等环节组成。
其中,文本检测、文本识别是最核心的环节。文本检测方面,在前面的文章中已介绍过了多种基于深度学习的方法,可针对各种场景实现对文字的检测,详见以下文章:
【AI实战】手把手教你文字识别(检测篇:MSER、CTPN、SegLink、EAST等方法)
【AI实战】手把手教你文字识别(检测篇:AdvancedEAST、PixelLink方法)

而本文主要就是介绍在“文本识别”方面的实战方法,只要掌握了这些方法,那么跟前面介绍的文本检测方法结合起来,就可以轻松应对各种文字识别的任务了。话不多说,马上来学习“文本识别”的方法。
文字识别可根据待识别的文字特点采用不同的识别方法,一般分为定长文字、不定长文字两大类别。
- 定长文字(例如验证码),由于字符数量固定,采用的网络结构相对简单,识别也比较容易;
- 不定长文字(例如印刷文字、广告牌文字等),由于字符数量是不固定的,因此需要采用比较复杂的网络结构和后处理环节,识别也具有一定的难度。
下面按照定长文字、不定长文字分别介绍识别方法。
一、定长文字识别
定长文字的识别相对简单,应用场景也比较局限,最典型的场景就是验证码的识别了。由于字符数量是已知的、固定的,因此,网络结构比较简单,一般构建3层卷积层,2层全连接层便能满足“定长文字”的识别。
具体方法在之前介绍验证码识别的文章中已详细介绍,在此不再赘述。详见文章:
【AI实战】文字识别(验证码识别)

二、不定长文字识别
不定长文字在现实中大量存在,例如印刷文字、广告牌文字等,由于字符数量不固定、不可预知,因此,识别的难度也较大,这也是目前研究文字识别的主要方向。下面介绍不定长文字识别的常用方法:LSTM+CTC、CRNN、chinsesocr。
1、LSTM+CTC 方法
(1)什么是LSTM
为了实现对不定长文字的识别,就需要有一种能力更强的模型,该模型具有一定的记忆能力,能够按时序依次处理任意长度的信息,这种模型就是“循环神经网络”(Recurrent Neural Networks,简称RNN)。
LSTM(Long Short Term Memory,长短期记忆网络)是一种特殊结构的RNN(循环神经网络),用于解决RNN的长期依赖问题,也即随着输入RNN网络的信息的时间间隔不断增大,普通RNN就会出现“梯度消失”或“梯度爆炸”的现象,这就是RNN的长期依赖问题,而引入LSTM即可以解决这个问题。LSTM单元由输入门(Input Gate)、遗忘门(Forget Gate)和输出门(Output Gate)组成,具体的技术原理的工作过程详见之前的文章(文章:白话循环神经网络(RNN)),LSTM的结构如下图所示。

(2)什么是CTC
CTC(Connectionist Temporal Classifier,联接时间分类器),主要用于解决输入特征与输出标签的对齐问题。例如下图,由于文字的不同间隔或变形等问题,导致同个文字有不同的表现形式,但实际上都是同一个文字。在识别时会将输入图像分块后再去识别,得出每块属于某个字符的概率(无法识别的标记为特殊字符”-”),如下图:
由于字符变形等原因,导致对输入图像分块识别时,相邻块可能会识别为同个结果,字符重复出现。因此,通过CTC来解决对齐问题,模型训练后,对结果中去掉间隔字符、去掉重复字符(如果同个字符连续出现,则表示只有1个字符,如果中间有间隔字符,则表示该字符出现多次),如下图所示
(3)LSTM+CTC实现:常量定义
定义一些常量,在模型训练和预测中使用,定义如下:
# 数据集,可根据需要增加英文或其它字符
DIGITS = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
# 分类数量
num_classes = len(DIGITS) + 1 # 数据集字符数+特殊标识符
# 图片大小,32 x 256
OUTPUT_SHAPE = (32, 256)
# 学习率
INITIAL_LEARNING_RATE = 1e-3
DECAY_STEPS = 5000
REPORT_STEPS = 100
LEARNING_RATE_DECAY_FACTOR = 0.9
MOMENTUM = 0.9
# LSTM网络层次
num_hidden = 128
num_layers = 2
# 训练轮次、批量大小
num_epochs = 50000
BATCHES = 10
BATCH_SIZE = 32
TRAIN_SIZE = BATCHES * BATCH_SIZE
# 数据集目录、模型目录
data_dir = '/tmp/lstm_ctc_data/'
model_dir = '/tmp/lstm_ctc_model/'(4)LSTM+CTC实现:随机生成不定长图片数据
为了训练和测试LSTM+CTC识别模型,先要准备好基础数据,可根据需要准备好已标注的文本图片集。在这里,为了方便训练和测试模型,随机生成10000张不定长的图片数据集。通过使用Pillow生成图片和绘上文字,并对图片随机叠加椒盐噪声,以更加贴近现实场景。核心代码如下:
# 生成椒盐噪声
def img_salt_pepper_noise(src,percetage):
NoiseImg=src
NoiseNum=int(percetage*src.shape[0]*src.shape[1])
for i in range(NoiseNum):
randX=random.randint(0,src.shape[0]-1)
randY=random.randint(0,src.shape[1]-1)
if random.randint(0,1)==0:
NoiseImg[randX,randY]=0
else:
NoiseImg[randX,randY]=255
return NoiseImg
# 随机生成不定长图片集
def gen_text(cnt):
# 设置文字字体和大小
font_path = '/data/work/tensorflow/fonts/arial.ttf'
font_size = 30
font=ImageFont.truetype(font_path,font_size)
for i in range(cnt):
# 随机生成1到10位的不定长数字
rnd = random.randint(1, 10)
text = ''
for j in range(rnd):
text = text + DIGITS[random.randint(0, len(DIGITS) - 1)]
# 生成图片并绘上文字
img=Image.new("RGB",(256,32))
draw=ImageDraw.Draw(img)
draw.text((1,1),text,font=font,fill='white')
img=np.array(img)
# 随机叠加椒盐噪声并保存图像
img = img_salt_pepper_noise(img, float(random.randint(1,10)/100.0))
cv2.imwrite(data_dir + text + '_' + str(i+1) + '.jpg',img)随机生成的不定长数据效果如下:
执行 gen_text(10000) 后生成的图片集如下,文件名由序号和文字标签组成:

(5)LSTM+CTC实现:标签向量化(稀疏矩阵)
由于文字是不定长的,因此,如果读取图片并获取标签,然后将标签存放在一个紧密矩阵中进行向量化,那将会出现大量的零元素,很浪费空间。因此,使用稀疏矩阵对标签进行向量化。所谓“稀疏矩阵”就是矩阵中的零元素远远多于非零元素,采用这种方式存储可有效节约空间。
稀疏矩阵有3个属性,分别是:
- indices:二维矩阵,代表非零的坐标点
- values:二维tensor,代表indice位置的数据值
- dense_shape:一维,代表稀疏矩阵的大小(取行数和列的最大长度)
例如读取了以下图片和相应的标签,那么存储为稀疏矩阵的结果如下:
将标签转为稀疏矩阵,对标签进行向量化,核心代码如下:
# 序列转为稀疏矩阵
# 输入:序列
# 输出:indices非零坐标点,values数据值,shape稀疏矩阵大小
def sparse_tuple_from(sequences, dtype=np.int32):
indices = []
values = []
for n, seq in enumerate(sequences):
indices.extend(zip([n] * len(seq), range(len(seq))))
values.extend(seq)
indices = np.asarray(indices, dtype=np.int64)
values = np.asarray(values, dtype=dtype)
shape = np.asarray([len(sequences), np.asarray(indices).max(0)[1] + 1], dtype=np.int64)
return indices, values, shape将稀疏矩阵转为标签,用于输出结果,核心代码如下:
# 稀疏矩阵转为序列
# 输入:稀疏矩阵
# 输出:序列
def decode_sparse_tensor(sparse_tensor):
decoded_indexes = list()
current_i = 0
current_seq = []
for offset, i_and_index in enumerate(sparse_tensor[0]):
i = i_and_index[0]
if i != current_i:
decoded_indexes.append(current_seq)
current_i = i
current_seq = list()
current_seq.append(offset)
decoded_indexes.append(current_seq)
result = []
for index in decoded_indexes:
result.append(decode_a_seq(index, sparse_tensor))
return result
# 序列编码转换
def decode_a_seq(indexes, spars_tensor):
decoded = []
for m in indexes:
str = DIGITS[spars_tensor[1][m]]
decoded.append(str)
return decoded(6)LSTM+CTC实现:读取数据
读取图像数据以及进行标签向量化,以便于输入到模型进行训练,核心代码如下:
# 将文件和标签读到内存,减少磁盘IO
def get_file_text_array():
file_name_array=[]
text_array=[]
for parent, dirnames, filenames in os.walk(data_dir):
file_name_array=filenames
for f in file_name_array:
text = f.split('_')[0]
text_array.append(text)
return file_name_array,text_array
# 获取训练的批量数据
def get_next_batch(file_name_array,text_array,batch_size=64):
inputs = np.zeros([batch_size, OUTPUT_SHAPE[1], OUTPUT_SHAPE[0]])
codes = []
# 获取训练样本
for i in range(batch_size):
index = random.randint(0, len(file_name_array) - 1)
image = cv2.imread(data_dir + file_name_array[index])
image = cv2.resize(image, (OUTPUT_SHAPE[1], OUTPUT_SHAPE[0]), 3)
image = cv2.cvtColor(image,cv2.COLOR_RGB2GRAY)
text = text_array[index]
# 矩阵转置
inputs[i, :] = np.transpose(image.reshape((OUTPUT_SHAPE[0], OUTPUT_SHAPE[1])))
# 标签转成列表
codes.append(list(text))
# 标签转成稀疏矩阵
targets = [np.asarray(i) for i in codes]
sparse_targets = sparse_tuple_from(targets)
seq_len = np.ones(inputs.shape[0]) * OUTPUT_SHAPE[1]
return inputs, sparse_targets, seq_len(7)LSTM+CTC实现:构建网络
利用tensorflow内置的LSTM单元构建网络,核心代码如下:
def get_train_model():
# 输入
inputs = tf.placeholder(tf.float32, [None, None, OUTPUT_SHAPE[0]])
# 稀疏矩阵
targets = tf.sparse_placeholder(tf.int32)
# 序列长度 [batch_size,]
seq_len = tf.placeholder(tf.int32, [None])
# 定义LSTM网络
cell = tf.contrib.rnn.LSTMCell(num_hidden, state_is_tuple=True)
stack = tf.contrib.rnn.MultiRNNCell([cell] * num_layers, state_is_tuple=True) # old
outputs, _ = tf.nn.dynamic_rnn(cell, inputs, seq_len, dtype=tf.float32)
shape = tf.shape(inputs)
batch_s, max_timesteps = shape[0], shape[1]
outputs = tf.reshape(outputs, [-1, num_hidden])
W = tf.Variable(tf.truncated_normal([num_hidden,
num_classes],
stddev=0.1), name="W")
b = tf.Variable(tf.constant(0., shape=[num_classes]), name="b")
logits = tf.matmul(outputs, W) + b
logits = tf.reshape(logits, [batch_s, -1, num_classes])
# 转置矩阵
logits = tf.transpose(logits, (1, 0, 2))
return logits, inputs, targets, seq_len, W, b (8)LSTM+CTC实现:模型训练
在训练之前,先定义好准确率评估方法,以便于在训练过程中不断评估模型的准确性,核心代码如下:
# 准确性评估
# 输入:预测结果序列 decoded_list ,目标序列 test_targets
# 返回:准确率
def report_accuracy(decoded_list, test_targets):
original_list = decode_sparse_tensor(test_targets)
detected_list = decode_sparse_tensor(decoded_list)
# 正确数量
true_numer = 0
# 预测序列与目标序列的维度不一致,说明有些预测失败,直接返回
if len(original_list) != len(detected_list):
print("len(original_list)", len(original_list), "len(detected_list)", len(detected_list),
" test and detect length desn't match")
return
# 比较预测序列与结果序列是否一致,并统计准确率
print("T/F: original(length) <-------> detectcted(length)")
for idx, number in enumerate(original_list):
detect_number = detected_list[idx]
hit = (number == detect_number)
print(hit, number, "(", len(number), ") <-------> ", detect_number, "(", len(detect_number), ")")
if hit:
true_numer = true_numer + 1
accuracy = true_numer * 1.0 / len(original_list)
print("Test Accuracy:", accuracy)
return accuracy接着开始对模型进行训练,核心代码如下:
def train():
# 获取训练样本数据
file_name_array, text_array = get_file_text_array()
# 定义学习率
global_step = tf.Variable(0, trainable=False)
learning_rate = tf.train.exponential_decay(INITIAL_LEARNING_RATE,
global_step,
DECAY_STEPS,
LEARNING_RATE_DECAY_FACTOR,
staircase=True)
# 获取网络结构
logits, inputs, targets, seq_len, W, b = get_train_model()
# 设置损失函数
loss = tf.nn.ctc_loss(labels=targets, inputs=logits, sequence_length=seq_len)
cost = tf.reduce_mean(loss)
# 设置优化器
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss, global_step=global_step)
decoded, log_prob = tf.nn.ctc_beam_search_decoder(logits, seq_len, merge_repeated=False)
acc = tf.reduce_mean(tf.edit_distance(tf.cast(decoded[0], tf.int32), targets))
init = tf.global_variables_initializer()
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
with tf.Session() as session:
session.run(init)
saver = tf.train.Saver(tf.global_variables(), max_to_keep=10)
for curr_epoch in range(num_epochs):
train_cost = 0
train_ler = 0
for batch in range(BATCHES):
# 训练模型
train_inputs, train_targets, train_seq_len = get_next_batch(file_name_array, text_array, BATCH_SIZE)
feed = {inputs: train_inputs, targets: train_targets, seq_len: train_seq_len}
b_loss, b_targets, b_logits, b_seq_len, b_cost, steps, _ = session.run(
[loss, targets, logits, seq_len, cost, global_step, optimizer], feed)
# 评估模型
if steps > 0 and steps % REPORT_STEPS == 0:
test_inputs, test_targets, test_seq_len = get_next_batch(file_name_array, text_array, BATCH_SIZE)
test_feed = {inputs: test_inputs,targets: test_targets,seq_len: test_seq_len}
dd, log_probs, accuracy = session.run([decoded[0], log_prob, acc], test_feed)
report_accuracy(dd, test_targets)
# 保存识别模型
save_path = saver.save(session, model_dir + "lstm_ctc_model.ctpk",global_step=steps)
c = b_cost
train_cost += c * BATCH_SIZE
train_cost /= TRAIN_SIZE
# 计算 loss
train_inputs, train_targets, train_seq_len = get_next_batch(file_name_array, text_array, BATCH_SIZE)
val_feed = {inputs: train_inputs,targets: train_targets,seq_len: train_seq_len}
val_cost, val_ler, lr, steps = session.run([cost, acc, learning_rate, global_step], feed_dict=val_feed)
log = "{} Epoch {}/{}, steps = {}, train_cost = {:.3f}, val_cost = {:.3f}"
print(log.format(curr_epoch + 1, num_epochs, steps, train_cost, val_cost))经过一段时间的训练,执行了600多步后,评估的准确性已全部预测正确,如下图:
(8)LSTM+CTC实现:能力封装
为了方便其它程序调用LSTM+CTC的识别能力,对识别能力进行封装,只需要输入一张图片,即可识别后返回结果。核心代码如下:
# LSTM+CTC 文字识别能力封装
# 输入:图片
# 输出:识别结果文字
def predict(image):
# 获取网络结构
logits, inputs, targets, seq_len, W, b = get_train_model()
decoded, log_prob = tf.nn.ctc_beam_search_decoder(logits, seq_len, merge_repeated=False)
saver = tf.train.Saver()
with tf.Session() as sess:
# 加载模型
saver.restore(sess, tf.train.latest_checkpoint(model_dir))
# 图像预处理
image = cv2.resize(image, (OUTPUT_SHAPE[1], OUTPUT_SHAPE[0]), 3)
image = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
pred_inputs = np.zeros([1, OUTPUT_SHAPE[1], OUTPUT_SHAPE[0]])
pred_inputs[0, :] = np.transpose(image.reshape((OUTPUT_SHAPE[0], OUTPUT_SHAPE[1])))
pred_seq_len = np.ones(1) * OUTPUT_SHAPE[1]
# 模型预测
pred_feed = {inputs: pred_inputs,seq_len: pred_seq_len}
dd, log_probs = sess.run([decoded[0], log_prob], pred_feed)
# 识别结果转换
detected_list = decode_sparse_tensor(dd)[0]
detected_text = ''
for d in detected_list:
detected_text = detected_text + d
return detected_text
2、CRNN 方法
CRNN(Convolutional Recurrent Neural Network,卷积循环神经网络)是目前比较流行的文字识别模型,不需要对样本数据进行字符分割,可识别任意长度的文本序列,模型速度快、性能好。网络结构如下图所示,主要由卷积层、循环层、转录层3部分组成,具体技术原理请详见之前的文章(文章:大话文本识别经典模型 CRNN)
那么该如何使用CRNN训练和识别呢?
github上实现CRNN的代码有很多,这里面选择一个相对简单的CRNN源代码进行研究。
(1)下载源代码
首先,在github上下载CRNN源代码(https://github.com/Belval/CRNN),可直接下载成zip压缩包或者git克隆
git clone https://github.com/Belval/CRNN.git(2)准备基础数据
使用第1节LSTM+CTC介绍的方法随机生成10000张不定长图片+椒盐噪声作为基础数据集,具体详见第1节的生成基础数据代码,在此不再重复。注意,由于该CRNN源代码在读取图片时默认文件名第1位为标签(以下划线 ”_” 隔开),于是注意按照文件命名规则生成图片。
(3)训练模型
参考CRNN/run.py里面的代码,编写模型训练的调用代码如下:
# 模型训练
def train():
# 设置基本属性
batch_size=32 # 批量大小
max_image_width=400 # 最大图片宽度
train_test_ratio=0.75 # 训练集、测试集划分比例
restore=True # 是否恢复加载模型,可用于多次加载训练
iteration_count=1000 # 迭代次数
# 初始化调用CRNN
crnn = CRNN(
batch_size,
model_dir,
data_dir,
max_image_width,
train_test_ratio,
restore
)
# 模型训练
crnn.train(iteration_count)经过了5个小时左右,迭代训练了263次,使得loss(损失值)已降低至接近1,模型也已基本上可用。
CRNN的训练过程很长,本案例随机生成的文字还是比较简单的,但每步的迭代就已耗时很长。如果是实际应用中,需要使用背景更加复杂、文字形态更加多样的数据集,对训练loss的要求也更高,这时会使得整个训练过程更长。因此,一般会采用“迁移学习”的方式来提升训练效率和模型效果(详见文章:了解什么是“迁移学习”),“迁移学习”的实现方式后面会再单独进行介绍。
(4)模型测试
参考CRNN/run.py里面的代码,编写模型测试的代码,可输出测试结果,代码如下:
# 模型测试
def test():
# 设置基本属性
batch_size=32
max_image_width=400
restore=True
# 初始化CRNN
crnn = CRNN(
batch_size,
model_dir,
data_dir,
max_image_width,
0,
restore
)
# 测试模型
crnn.test()测试的结果如下,程序会批量读入数据后,输入原始结果(第一行)和预测结果(第二行),便于比较两者是否一致。
作者提供的这种测试方式太考验人眼了,我们可将CRNN里面的test函数进行个小修改,自动计算准确率,将会方便很多。修改的代码如下:
def test(self):
with self.__session.as_default():
print('Testing')
for batch_y, _, batch_x in self.__data_manager.test_batches:
decoded = self.__session.run(
self.__decoded,
feed_dict={
self.__inputs: batch_x,
self.__seq_len: [self.__max_char_count] * self.__data_manager.batch_size
}
)
# 修改,统计准确率
true_cnt = 0
for i, y in enumerate(batch_y):
if batch_y[i] == ground_truth_to_word(decoded[i]):
true_cnt = true_cnt + 1
else:
# 预测结果不一致的,才显示出来
print('target:',batch_y[i])
print('predict:',ground_truth_to_word(decoded[i]))
print('acc:',float(true_cnt)/float(len(batch_y)))
return None(5)能力封装
为了方便将CRNN识别能力提供给其它程序调用,在CRNN/crnn.py代码的基础上进行修改,对CRNN识别能力进行封装,即只需输入指定的图片,即可返回识别结果。
首先是重写crnn.py里面加载CRNN网络结构的方式,由于原先的代码在初始化时只支持批量的图片进行训练和测试,为了实现对指定的某张图片进行识别,对网络模型的初始化和调用方式进行修改,核心代码如下:
# CRNN 网络结构
def crnn_network(max_width, batch_size):
# 双向RNN
def BidirectionnalRNN(inputs, seq_len):
# rnn-1
with tf.variable_scope(None, default_name="bidirectional-rnn-1"):
# Forward
lstm_fw_cell_1 = rnn.BasicLSTMCell(256)
# Backward
lstm_bw_cell_1 = rnn.BasicLSTMCell(256)
inter_output, _ = tf.nn.bidirectional_dynamic_rnn(lstm_fw_cell_1, lstm_bw_cell_1, inputs, seq_len, dtype=tf.float32)
inter_output = tf.concat(inter_output, 2)
# rnn-2
with tf.variable_scope(None, default_name="bidirectional-rnn-2"):
# Forward
lstm_fw_cell_2 = rnn.BasicLSTMCell(256)
# Backward
lstm_bw_cell_2 = rnn.BasicLSTMCell(256)
outputs, _ = tf.nn.bidirectional_dynamic_rnn(lstm_fw_cell_2, lstm_bw_cell_2, inter_output, seq_len, dtype=tf.float32)
outputs = tf.concat(outputs, 2)
return outputs
# CNN,用于提取特征
def CNN(inputs):
# 64 / 3 x 3 / 1 / 1
conv1 = tf.layers.conv2d(inputs=inputs, filters = 64, kernel_size = (3, 3), padding = "same", activation=tf.nn.relu)
# 2 x 2 / 1
pool1 = tf.layers.max_pooling2d(inputs=conv1, pool_size=[2, 2], strides=2)
# 128 / 3 x 3 / 1 / 1
conv2 = tf.layers.conv2d(inputs=pool1, filters = 128, kernel_size = (3, 3), padding = "same", activation=tf.nn.relu)
# 2 x 2 / 1
pool2 = tf.layers.max_pooling2d(inputs=conv2, pool_size=[2, 2], strides=2)
# 256 / 3 x 3 / 1 / 1
conv3 = tf.layers.conv2d(inputs=pool2, filters = 256, kernel_size = (3, 3), padding = "same", activation=tf.nn.relu)
# Batch normalization layer
bnorm1 = tf.layers.batch_normalization(conv3)
# 256 / 3 x 3 / 1 / 1
conv4 = tf.layers.conv2d(inputs=bnorm1, filters = 256, kernel_size = (3, 3), padding = "same", activation=tf.nn.relu)
# 1 x 2 / 1
pool3 = tf.layers.max_pooling2d(inputs=conv4, pool_size=[2, 2], strides=[1, 2], padding="same")
# 512 / 3 x 3 / 1 / 1
conv5 = tf.layers.conv2d(inputs=pool3, filters = 512, kernel_size = (3, 3), padding = "same", activation=tf.nn.relu)
# Batch normalization layer
bnorm2 = tf.layers.batch_normalization(conv5)
# 512 / 3 x 3 / 1 / 1
conv6 = tf.layers.conv2d(inputs=bnorm2, filters = 512, kernel_size = (3, 3), padding = "same", activation=tf.nn.relu)
# 1 x 2 / 2
pool4 = tf.layers.max_pooling2d(inputs=conv6, pool_size=[2, 2], strides=[1, 2], padding="same")
# 512 / 2 x 2 / 1 / 0
conv7 = tf.layers.conv2d(inputs=pool4, filters = 512, kernel_size = (2, 2), padding = "valid", activation=tf.nn.relu)
return conv7
# 定义输入、输出、序列长度
inputs = tf.placeholder(tf.float32, [batch_size, max_width, 32, 1])
targets = tf.sparse_placeholder(tf.int32, name='targets')
seq_len = tf.placeholder(tf.int32, [None], name='seq_len')
# 卷积层提取特征
cnn_output = CNN(inputs)
reshaped_cnn_output = tf.reshape(cnn_output, [batch_size, -1, 512])
max_char_count = reshaped_cnn_output.get_shape().as_list()[1]
# 循环层处理序列
crnn_model = BidirectionnalRNN(reshaped_cnn_output, seq_len)
logits = tf.reshape(crnn_model, [-1, 512])
# 转录层预测结果
W = tf.Variable(tf.truncated_normal([512, config.NUM_CLASSES], stddev=0.1), name="W")
b = tf.Variable(tf.constant(0., shape=[config.NUM_CLASSES]), name="b")
logits = tf.matmul(logits, W) + b
logits = tf.reshape(logits, [batch_size, -1, config.NUM_CLASSES])
logits = tf.transpose(logits, (1, 0, 2))
# 定义损失函数、优化器
loss = tf.nn.ctc_loss(targets, logits, seq_len)
cost = tf.reduce_mean(loss)
optimizer = tf.train.AdamOptimizer(learning_rate=0.0001).minimize(cost)
decoded, log_prob = tf.nn.ctc_beam_search_decoder(logits, seq_len, merge_repeated=False)
dense_decoded = tf.sparse_tensor_to_dense(decoded[0], default_value=-1)
acc = tf.reduce_mean(tf.edit_distance(tf.cast(decoded[0], tf.int32), targets))
# 初始化
init = tf.global_variables_initializer()
return inputs, targets, seq_len, logits, dense_decoded, optimizer, acc, cost, max_char_count, init
# CRNN 识别文字
# 输入:图片路径
# 输出:识别文字结果
def predict(img_path):
# 定义模型路径、最长图片宽度
batch_size = 1
model_path = '/tmp/crnn_model/'
max_image_width = 400
# 创建会话
__session = tf.Session()
with __session.as_default():
(
__inputs,
__targets,
__seq_len,
__logits,
__decoded,
__optimizer,
__acc,
__cost,
__max_char_count,
__init
) = crnn_network(max_image_width, batch_size)
__init.run()
# 加载模型
with __session.as_default():
__saver = tf.train.Saver()
ckpt = tf.train.latest_checkpoint(model_path)
if ckpt:
__saver.restore(__session, ckpt)
# 读取图片作为输入
arr, initial_len = utils.resize_image(img_path,max_image_width)
batch_x = np.reshape(
np.array(arr),
(-1, max_image_width, 32, 1)
)
# 利用模型识别文字
with __session.as_default():
decoded = __session.run(
__decoded,
feed_dict={
__inputs: batch_x,
__seq_len: [__max_char_count] * batch_size
}
)
pred_result = utils.ground_truth_to_word(decoded[0])
return pred_result将CRNN能力封装后,便能很方便地进行调用识别,如下:
img_path = '/tmp/crnn_data/728591_532.jpg'
pred_result = predict(img_path)
print('predict result:',pred_result)调用结果如下图

3、chineseocr项目
最后再介绍github上一个很不错的文字识别项目chineseocr,这个项目是基于yolo3(用于文字检测)、crnn(用于文字识别)的自然场景文字识别项目。该项目支持darknet / opencv dnn / keras 的文字检测,支持0、90、180、270度的方向检测,支持不定长的英文、中英文识别,同时支持通用OCR、身份证识别、火车票识别等多种场景。
该模型功能完善,使用简单,入手容易,非常适合于新手或者比较通用的场景使用。下面介绍如何使用chineseocr项目。
(1)下载源代码
首先,在github上下载chineseocr源代码(https://github.com/chineseocr/chineseocr),可直接下载成zip压缩包或者git克隆
git clone https://github.com/chineseocr/chineseocr.git(2)下载darknet
chineseocr项目默认使用keras yolo3进行文字检测,该项目同时支持opencv dnn、darknet进行文字检测。
① 下载源代码
如果要使用darknet来进行文字检测,那么就需要再下载darknet源代码(如直接使用项目默认的keras yolo3检测方法,则跳过该步骤),在github上下载chineseocr源代码(https://github.com/pjreddie/darknet),可直接下载成zip压缩包或者git克隆
git clone https://github.com/pjreddie/darknet.git② 放置目录
下载后,将darknet的源代码放到chineseocr项目中的darknet目录中。
mv darknet chineseocr/③ 编译
然后修改Makefile,增加对GPU、cudnn的支持
#GPU=1
#CUDNN=1
#OPENCV=0
#OPENMP=0执行 make 进行编译
④ 指定libdarknet.so路径
修改 darknet/python/darknet.py 的第48行,指定libdarknet.so所在的目录
lib = CDLL(root+"chineseocr/darknet/libdarknet.so", RTLD_GLOBAL)其中root表示chineseocr所在的路径
(3)准备基础环境
在源代码文件中的setup.md中列举了该项目依赖的基础环境,如果是在cpu上运行则查看setup-cpu.md文件。
① 创建虚拟环境
# 创建虚拟环境
conda create -n chineseocr python=3.6 pip scipy numpy jupyter ipython
# 激活虚拟环境
source activate chineseocr
② 安装依赖包
git submodule init && git submodule update
pip install easydict opencv-contrib-python==4.0.0.21 Cython h5py lmdb mahotas pandas requests bs4 matplotlib lxml
pip install -U pillow
pip install keras==2.1.5 tensorflow==1.8 tensorflow-gpu==1.8
pip install web.py==0.40.dev0
conda install pytorch torchvision -c pytorch
pip install torch torchvision(4)下载模型文件
在百度网盘上面下载预训练好的模型文件,并将所有文件复制到models目录中,下载地址为 https://pan.baidu.com/s/1gTW9gwJR6hlwTuyB6nCkzQ
(5)启动web服务
通过执行app.py启动web服务,启动后便能直接上传图片进行文字识别,执行命令为
ipython app.py 8080其中,8080为端口号,可根据实际需要进行修改。
启动后的界面如下,界面中提供了是否进行文字方向检测、是否作单行文字识别,以及通用OCR(默认)、火车票、身份证的识别类型。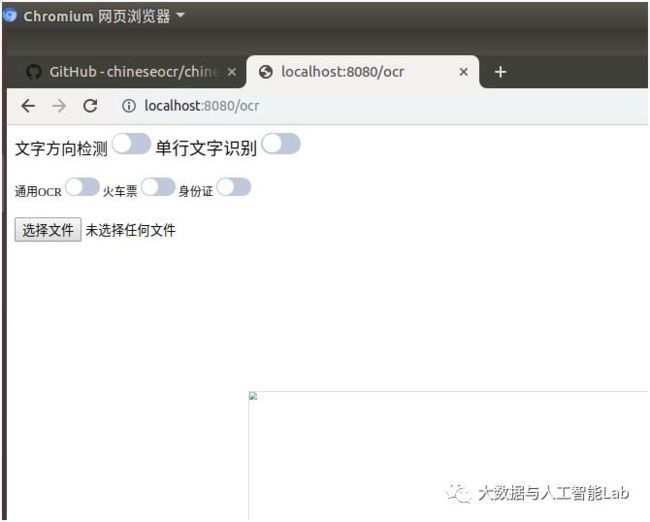
在chineseocr项目中的test目录里面自带了一些测试图片,通过上传一些图片测试识别效果,如下图:
从识别效果上看还不错,接下来试一下火车票、身份证类型的识别
从上图可看出,对火车票的识别结果进行了处理,将出发地点、到达地点、车次、时间、价格、姓名等信息提取了出来。
身份证的识别也是将姓名、性别、民族、出生年月、身份证号、住址这些信息提取了出来。
我们再比较一下,有使用文字方向检测和没有使用文字方向检测时的识别效果区别,如下图:
从识别的结果可以看出,对于一张颠倒的图片(或者具有一定的旋转角度),如果没有加上文字方向检测,则识别出来的结果文字会出现很大的偏差,而加上方向检测后则会正确地识别出来。
(6)识别能力封装
chineseocr项目支持多种方式的文字检测与识别,提供了多种模型可供选择,导致整个项目比较庞大。如果要将该项目的检测与识别能力抽离出来,提供给其它项目使用,则需根据实际业务场景进行简化,将识别能力进行封装。
例如我们选择keras yolo3进行文字检测,选择pytorch进行文字识别,去掉文字方向检测(假定输入的图片绝大多数是方向正确的),那么即可对chineseocr的源代码进行大幅精简。在model.py代码的基础上进行修改,去繁存简,对识别能力进行封装,方便提供给其它应用程序使用。修改后的核心代码如下:
# 文字检测
def text_detect(img,MAX_HORIZONTAL_GAP=30,MIN_V_OVERLAPS=0.6,MIN_SIZE_SIM=0.6,TEXT_PROPOSALS_MIN_SCORE=0.7,TEXT_PROPOSALS_NMS_THRESH=0.3,TEXT_LINE_NMS_THRESH=0.3,):
boxes, scores = detect.text_detect(np.array(img))
boxes = np.array(boxes, dtype=np.float32)
scores = np.array(scores, dtype=np.float32)
textdetector = TextDetector(MAX_HORIZONTAL_GAP, MIN_V_OVERLAPS, MIN_SIZE_SIM)
shape = img.shape[:2]
boxes = textdetector.detect(boxes,scores[:, np.newaxis],shape,TEXT_PROPOSALS_MIN_SCORE,TEXT_PROPOSALS_NMS_THRESH,TEXT_LINE_NMS_THRESH,)
text_recs = get_boxes(boxes)
newBox = []
rx = 1
ry = 1
for box in text_recs:
x1, y1 = (box[0], box[1])
x2, y2 = (box[2], box[3])
x3, y3 = (box[6], box[7])
x4, y4 = (box[4], box[5])
newBox.append([x1 * rx, y1 * ry, x2 * rx, y2 * ry, x3 * rx, y3 * ry, x4 * rx, y4 * ry])
return newBox
# 文字识别
def crnnRec(im, boxes, leftAdjust=False, rightAdjust=False, alph=0.2, f=1.0):
results = []
im = Image.fromarray(im)
for index, box in enumerate(boxes):
degree, w, h, cx, cy = solve(box)
partImg, newW, newH = rotate_cut_img(im, degree, box, w, h, leftAdjust, rightAdjust, alph)
text = crnnOcr(partImg.convert('L'))
if text.strip() != u'':
results.append({'cx': cx * f, 'cy': cy * f, 'text': text, 'w': newW * f, 'h': newH * f,
'degree': degree * 180.0 / np.pi})
return results
# 文字检测、文字识别的能力封装
def ocr_model(img, leftAdjust=True, rightAdjust=True, alph=0.02):
img, f = letterbox_image(Image.fromarray(img), IMGSIZE)
img = np.array(img)
config = dict(MAX_HORIZONTAL_GAP=50, ##字符之间的最大间隔,用于文本行的合并
MIN_V_OVERLAPS=0.6,
MIN_SIZE_SIM=0.6,
TEXT_PROPOSALS_MIN_SCORE=0.1,
TEXT_PROPOSALS_NMS_THRESH=0.3,
TEXT_LINE_NMS_THRESH=0.7, ##文本行之间测iou值
)
config['img'] = img
text_recs = text_detect(**config) ##文字检测
newBox = sort_box(text_recs) ##行文本识别
result = crnnRec(np.array(img), newBox, leftAdjust, rightAdjust, alph, 1.0 / f)
return result经过以上重新改造封装后,只需要调用ocr_model函数,输入图片,即可调用chineseocr项目的检测与识别能力。调用结果如下图:

以上介绍的就是LSTM+CTC、CRNN、chineseocr三种文字识别方法的实战操作,在实际生产中一般会根据业务场景,对识别方法进行改造或增加预处理、后处理环节。如果有兴趣了解的,可私信我再进行交流。
欢迎关注本人的微信公众号“大数据与人工智能Lab”(BigdataAILab),获取 完整源代码


推荐相关阅读
1、AI 实战系列
- 【AI实战】手把手教你文字识别(文字识别篇:LSTM+CTC, CRNN, chineseocr方法)
- 【AI实战】手把手教你文字识别(文字检测篇一:MSER、CTPN、SegLink、EAST 等)
- 【AI实战】手把手教你文字识别(文字检测篇二:AdvancedEAST、PixelLink 方法)
- 【AI实战】手把手教你文字识别(入门篇:验证码识别)
- 【AI实战】快速掌握TensorFlow(一):基本操作
- 【AI实战】快速掌握TensorFlow(二):计算图、会话
- 【AI实战】快速掌握TensorFlow(三):激励函数
- 【AI实战】快速掌握TensorFlow(四):损失函数
- 【AI实战】搭建基础环境
- 【AI实战】训练第一个模型
- 【AI实战】编写人脸识别程序
- 【AI实战】动手训练目标检测模型(SSD篇)
- 【AI实战】动手训练目标检测模型(YOLO篇)
2、大话深度学习系列
- 【精华整理】CNN进化史
- 大话文本识别经典模型(CRNN)
- 大话文本检测经典模型(CTPN)
- 大话文本检测经典模型(SegLink)
- 大话文本检测经典模型(EAST)
- 大话文本检测经典模型(PixelLink)
- 大话文本检测经典模型(Pixel-Anchor)
- 大