《OpenCv视觉之眼》Python图像处理十九:Opencv图像处理实战四之通过OpenCV进行人脸口罩模型训练并进行口罩检测
本专栏主要介绍如果通过OpenCv-Python进行图像处理,通过原理理解OpenCv-Python的函数处理原型,在具体情况中,针对不同的图像进行不同等级的、不同方法的处理,以达到对图像进行去噪、锐化等一系列的操作。同时,希望观看本专栏的小伙伴可以理解到OpenCv进行图像处理的强大哦,如有转载,请注明出处(原文链接和作者署名),感谢各位小伙伴啦!
前文参考:
《OpenCv视觉之眼》Python图像处理一 :Opencv-python的简介及Python环境搭建
《OpenCv视觉之眼》Python图像处理二 :Opencv图像读取、显示、保存基本函数原型及使用
《OpenCv视觉之眼》Python图像处理三 :Opencv图像属性、ROI区域获取及通道处理
《OpenCv视觉之眼》Python图像处理四 :Opencv图像灰度处理的四种方法及原理
《OpenCv视觉之眼》Python图像处理五 :Opencv图像去噪处理之均值滤波、方框滤波、中值滤波和高斯滤波
《OpenCv视觉之眼》Python图像处理六 :Opencv图像傅里叶变换和傅里叶逆变换原理及实现
《OpenCv视觉之眼》Python图像处理七 :Opencv图像处理之高通滤波和低通滤波原理及构造
《OpenCv视觉之眼》Python图像处理八 :Opencv图像处理之图像阈值化处理原理及函数
《OpenCv视觉之眼》Python图像处理九 :Opencv图像形态学处理之图像腐蚀与膨胀原理及方法
《OpenCv视觉之眼》Python图像处理十 :Opencv图像形态学处理之开运算、闭运算和梯度运算原理及方法
《OpenCv视觉之眼》Python图像处理十一 :Opencv图像形态学处理之顶帽运算与黑帽运算
《OpenCv视觉之眼》Python图像处理十二 :Opencv图像轮廓提取之基于一阶导数的Roberts算法、Prewitt算法及Sobel算法
《OpenCv视觉之眼》Python图像处理十三 :Opencv图像轮廓提取之基于二阶导数的Laplacian算法和LOG算法
《OpenCv视觉之眼》Python图像处理十四 :Opencv图像轮廓提取之Scharr算法和Canny算法
《OpenCv视觉之眼》Python图像处理十五 :Opencv图像处理之图像缩放、旋转和平移原理及实现
《OpenCv视觉之眼》Python图像处理十六:Opencv项目实战之图像中的硬币检测
《OpenCv视觉之眼》Python图像处理十七:Opencv图像处理实战二之图像中的物体识别并截取
《OpenCv视觉之眼》Python图像处理十八:Opencv图像处理实战三之基于OpenCV训练模型的AI人脸检测
上次博客,了解了OpenCV通过自己训练好的模型进行人脸检测,并且给出了图像中、视频中、摄像头中的人脸检测算法,也知道了OpenCV的训练模型针对正脸的检测准确率是大于百分之95的,而对于侧脸的检测是与侧脸突出的脸部面积的大小,光照强度有关的,因此,该模型如果应用于人脸检测系统只能但方面的用于正脸;既然我们能够使用该模型,那么该模型是怎样进行训练的呢?这是我们需要弄懂的。
本次博客,林君学长将带大家了解OpenCV神经网络模型训练是如何进行训练的,以人脸口罩识别为例
OpenCV图像处理实战四:通过OpenCV进行人脸口罩模型训练并进行口罩检测
[Python图像处理十九]:Opencv图像处理实战四之通过OpenCV进行人脸口罩模型训练并进行口罩检测
- 一、OpenCv的下载及安装
- 1、OpenCv的下载
- 2、OpenCv的安装
- 3、查看是否具有模型训练环境
- 二、人脸口罩数据集的下载及处理
- 1、人脸口罩数据集下载
- 2、数据集重命名为连续序列
- 3、正负样本数据集像素处理
- 4、创建正负样本数据集路径txt文档
- 5、将正负样本txt文档复制到数据集同级目录
- 三、口罩数据集的模型训练
- 1、创建XML文件夹
- 2、复制训练模型的exe文件
- 3、对正负样本txt文档进行预处理
- 4、生成正样本mask.vec文件和负样本mask1.vec文件
- 5、进行模型训练
- 四、戴口罩检测
- 1、通过如下python代码,进行口罩模型训练的监测
新冠疫情的影响下,人民群众被迫戴上口罩,相信各位小伙伴们也不例外,但在戴口罩的情况下,我们会遇到各种不方便的问题,例如在进出校园或者是小区的时候,需要将口罩摘下来,然后进行人脸识别,特别麻烦,本次博客,林君学长主要带大家了解如何对口罩数据集进行模型训练,然后进行戴口罩识别
- 模型训练环境:Opencv-3.4.1(这里并没有使用opencv-python进行训练)
一、OpenCv的下载及安装
在进行OpenCv的安装同时,大家会有几个选择,一个是新版本 的OpenCv-4.xx,另一种选择便是OpenCv-3.xx,在林君学长经过各种测试之后,发现对于模型训练的需要,选择OpenCv-3.4.1版本的进行win下的安装,因为该版本会具有数据集模型训练的exe文件,因此,建议大家选择OpenCv-3.4.1进行下载安装!
1、OpenCv的下载
1)、OpenCv-3.4.1官网下载链接
https://opencv.org/opencv-3-4-1/
2)、选择Win pack进行win10安装包下载

3)、在弹出的页面等待5秒,进行路径选择下载
2、OpenCv的安装
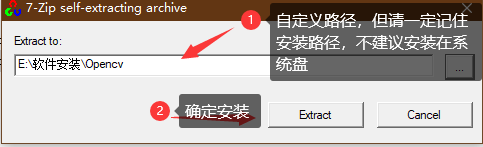
1)、点击下载好的OpenCv-3.4.1.exe进行自定义安装

2)、双击,自定义路径暗转
3)、安装成功
3、查看是否具有模型训练环境
1)、找到opencv的安装路径,然后查到路径 \opencv\build\x64\vc14\bin下是否具有下图标记的的两个exe文件
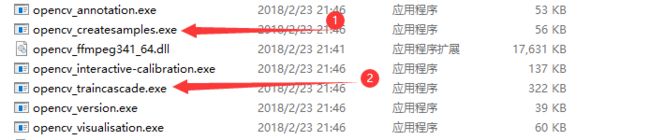
2)、如果具有上面两个工具,我们便可以进行下一步,当然,如果安装林君学长推荐的OpenCv-3.4.1,一定会有以上两个模型训练exe文件的,接下来,我们便进入下一步,口罩数据集的下载吧!
二、人脸口罩数据集的下载及处理
人脸口罩数据集主要是为了进行模型训练,OpenCv通过神经网络进行模型训练,通过网络查找而言,口罩数据集的正负比例为1:3,及解释为,500张戴口罩的数据集,需要1500张不戴口罩的数据集进行模型训练,在这里,林君学长已经准备好了我们需要的大致为1:3正负样本比例的数据集,小伙伴可以通过如下链接进行下载。
1、人脸口罩数据集下载
1)、通过如下链接进行人脸口罩数据集的下载,包括600张正样本(戴口罩)和1800多张负样本(不带口罩)
https://download.csdn.net/download/qq_42451251/12566250
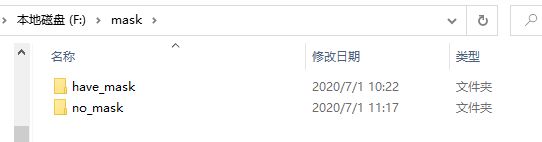
2)、CSDN下载后的样本如下所示,我们解压后将里面的mask文件夹放在F盘或者其他方便操作的盘下面;

提取到F盘之后如下所示:

2、数据集重命名为连续序列
通过样本,我们可以发现,数据集里面的图片是不连续的,,因此,我们需要将正负样本数据集重命名,命名为连续增加的图片格式,为了后面的图片像素调整
1)、通过如下python代码对正负样本进行重命名
#对数据集重命名
#coding:utf-8
import os
path = "F:\\mask\\have_mask" #你的路径
filelist = os.listdir(path)
count=1000 #开始文件名1000.jpg
for file in filelist:
Olddir=os.path.join(path,file)
if os.path.isdir(Olddir):
continue
filename=os.path.splitext(file)[0]
filetype=os.path.splitext(file)[1]
Newdir=os.path.join(path,str(count)+filetype)
os.rename(Olddir,Newdir)
count+=1
正样本重命名结果如下所示:

2)、同样的,在上面修改路径,为负样本同样重命名
#对负样本数据集重命名
#coding:utf-8
import os
path = "F:\\mask\\no_mask" #你的路径
filelist = os.listdir(path)
count=10000 #开始文件名10000.jpg
for file in filelist:
Olddir=os.path.join(path,file)
if os.path.isdir(Olddir):
continue
filename=os.path.splitext(file)[0]
filetype=os.path.splitext(file)[1]
Newdir=os.path.join(path,str(count)+filetype)
os.rename(Olddir,Newdir)
count+=1
负样本重命名结果如下所示:

值得注意的是,当我们设置的开始命名需要大于数据集中最后一张图片的数据,不然会报错,例如,数据集中最后一张为1000.jpg,那我们设置的count应该大于1000
当数据集重命名成功之后,我们便可以对图片的的像素进行处理了!看下面步骤吧!
3、正负样本数据集像素处理
官方推荐,正样本数据集的像素最好设置为20x20的像素,让训练的模型精度更高;而负样本数据集应该不低于50x50的样本,这样设置的原因是方便OpenCv加快模型训练,因此我们需要对刚刚的数据集进行 像素修改,具体操作如下;
1)、通过如下python代码,修改正样本数据集的像素为20x20
#修改正样本像素
import pandas as pd
import cv2
for n in range(1000,1606):#代表正数据集中开始和结束照片的数字
path='F:\\mask\\have_mask\\'+str(n)+'.jpg'
# 读取图片
img = cv2.imread(path)
img=cv2.resize(img,(20,20)) #修改样本像素为20x20
cv2.imwrite('F:\\mask\\have_mask\\' + str(n) + '.jpg', img)
n += 1
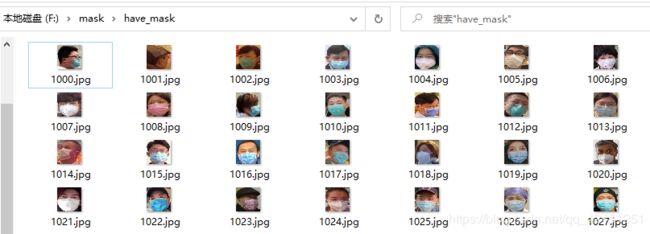
正样本数据集修改后如下所示:
2)、同样的,修改负样本的像素为60x60,知道大于50x50便好
#修改负样本像素
import pandas as pd
import cv2
for n in range(10000,11790):#代表负样本数据集中开始和结束照片的数字
path='F:\\mask\\no_mask\\'+str(n)+'.jpg'
# 读取图片
img = cv2.imread(path)
img=cv2.resize(img,(60,60)) #修改样本像素为60x60
cv2.imwrite('F:\\mask\\no_mask\\' + str(n) + '.jpg', img)
n += 1
负样本数据集修改后像素如下所示:
4、创建正负样本数据集路径txt文档
创建正负样本路径的txt文档是为了后面模型训练而使用,接下来我们便通cmd终端命令行进行路径文档创建吧!
1)、正样本数据集路径文档创建
(1)、打开打开cmd,进入到存放正样本的have_mask文件夹
F:
cd mask\have_mask
(2)、cmd终端输入如下命令创建路径文档
dir /b/s/p/w *.jpg > have_mask.txt

这时候,在正样本数据集的末尾,你就会发现已经创建一个have_mask.txt的路径正样本文件,文件内容如下所示:
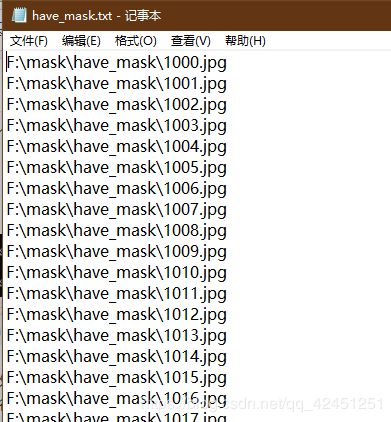
2)、负样本数据集路径文档创建
对于负样本路径文档的创建,和上面方式一下如下:
(1)、进入负样本文件夹
cd /mask/no_mask/
(2)、输入如下命令,创建负样本路径txt文档
dir /b/s/p/w *.jpg > no_mask.txt

负样本路径文档内容如下所示:
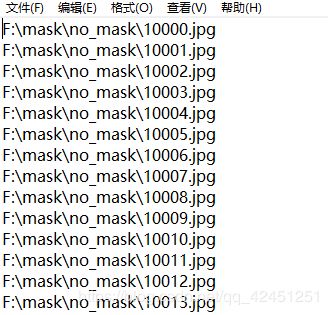
5、将正负样本txt文档复制到数据集同级目录
将上面我们创建的路径文档分别复制到数据集的同级目录,如下所示:
三、口罩数据集的模型训练
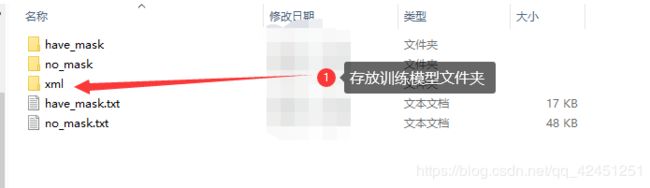
1、创建XML文件夹
1)、创建xml文件夹,存放OpenCV训练好的模型
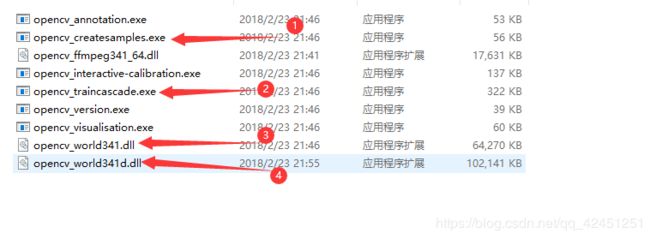
2、复制训练模型的exe文件
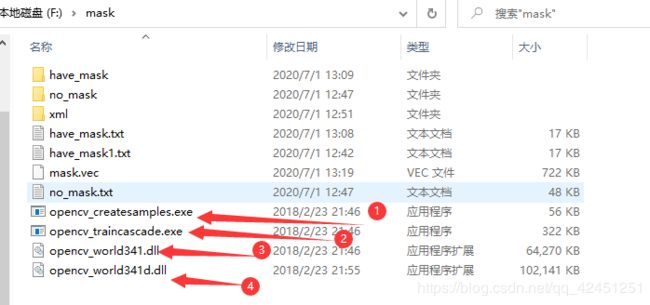
1)、将OpenCV安装路径 \opencv\build\x64\vc14\bin下的opencv_createsamples.exe可执行文件和opencv_traincascade.exe可执行文件及另外两个下图文件复制到数据集同级目录,如下所示:
3、对正负样本txt文档进行预处理
1)、由于正负样本需要生成 .vec格式的文档进行模型训练,因此,我们需要通过对txt文档进行预处理,向have_mask.txt文件没行中加入 1 0 0 20 20,通过如下代码添加:
#正样本文件预处理 没行目录结尾加入 1 0 0 20 20
#coding:utf-8
import os
#Houzui="_Apple"
Houzui=r" 1 0 0 20 20" #后缀
filelist = open('F:\\mask\\have_mask.txt','r+',encoding = 'utf-8')
line = filelist.readlines()
for file in line:
file=file.strip('\n')+Houzui+'\n'
print(file)
filelist.write(file)
2)、该代码由于不会覆盖之间的文件,只能添加到文件末尾,所以添加之后需要打开该文件将之前的删除然后保存即可,如果小伙伴能够改进以上代码就更好哦,改正之后希望能够给学长说啦!
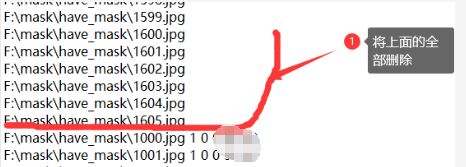
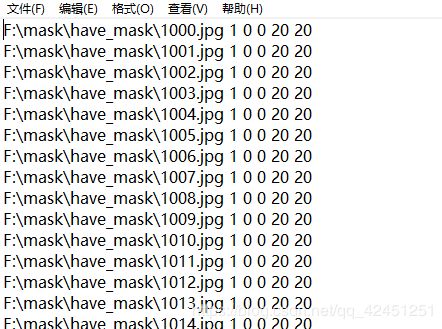
这里1表示当前图片重复出现的次数是1, 0 0 20 20表示目标图片大小是矩形框从(0,0)到(20,20)。
3)、再次将have_mask目录下的have_mask.txt复制出来,命名为have_mask1.txt,后面训练会需要,如下所示:
该内容是没有预处理的哦,只有路径内容:

4)、对负样本同样执行以上操作
#负样本文件预处理 没行目录结尾加入 1 0 0 60 60
#coding:utf-8
import os
#Houzui="_Apple"
Houzui=r" 1 0 0 60 60" #后缀
filelist = open('F:\\mask\\no_mask.txt','r+',encoding = 'utf-8')
line = filelist.readlines()
for file in line:
file=file.strip('\n')+Houzui+'\n'
print(file)
filelist.write(file)
(1)、再次将no_mask目录下的no_mask.txt复制出来,命名为no_mask1.txt,后面训练会需要,如下所示:
4、生成正样本mask.vec文件和负样本mask1.vec文件
1)、在刚刚的cmd终端,输入一下命令,生成mask.vec文件
cd /mask/
opencv_createsamples.exe -vec mask.vec -info have_mask.txt -num 605 -w 20 -h 20
- info,指样本说明文件
- vec,样本描述文件的名字及路径
- num,总共几个样本,要注意,这里的样本数是指标定后的30x30的样本数,数据集中有605张照片,因此选择605
- w -h指明想让样本缩放到什么尺寸。这里的奥妙在于你不必另外去处理第1步中被矩形框出的图片的尺寸,因为这个参数帮你统一缩放!(我们这里准备的样本都是20*20)
2)、运行出现如下错误:

这表明,数据集中可用模型只有410张,因此,我们将上面的命令中num改为410再次执行
3)、执行成功如下所示:
opencv_createsamples.exe -vec mask.vec -info have_mask.txt -num 410 -w 20 -h 20
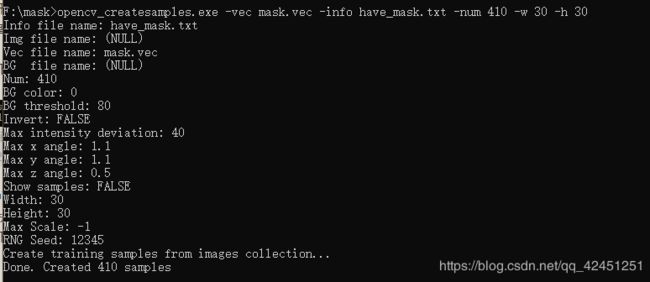
4)、mask.vec 文件已经创建
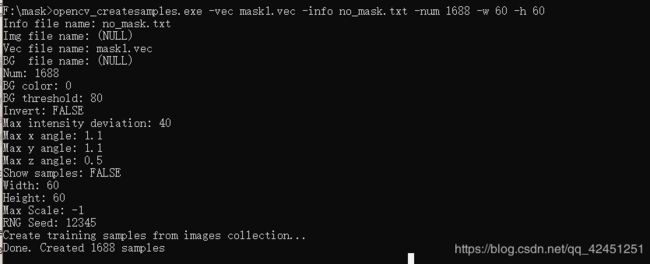
5)、同样生成负样本的mask1.vec
opencv_createsamples.exe -vec mask1.vec -info no_mask.txt -num 1688 -w 60 -h 60
5、进行模型训练
1)、在数据集同级目录创建一个txt文档,写入如下内容,写入后保存然后关闭:
opencv_traincascade.exe -data xml -vec mask.vec -bg no_mask.txt -numPos 385 -numNeg 400 -numStages 20 -w 20 -h 20 -mode ALL
pause
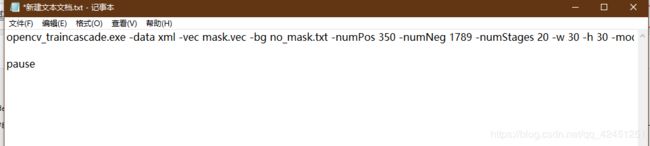
- numPos:只正样本数据集张数,上面是411张,但设置应该比他小,不然会报错,建议设置成350
- numNeg:负样本数据集张数,数据集为1688张
2)、各个参数含义如下所示:

3)、重命名刚刚创建的txt名称为traincascade.bat

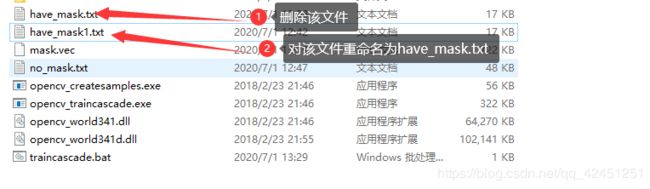
4)、删除之前的have_mask.txt和no_mask,txt,然后将have_mask1.txt和no_mask1.txt该为have_mask.txt和no_mask.txt,如下所示:
5)、双击traincascade.bat文件,进行人脸口罩模型训练
(1)、出现如下图则表示为正在进行模型训练
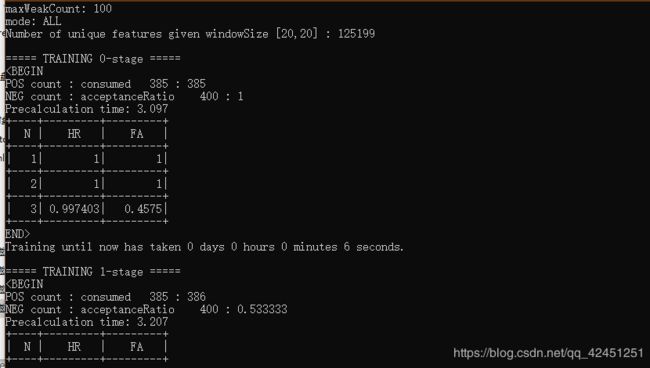
在训练途中,程序可能会暂停,当不动的时候,在cmd终端按一下键盘的回车键就好!
(2)、该模型训练需要花费的时间较长,由于需要训练20层,因此花费大量时间,到这里,小伙伴可以静静等待就好,大约需要50分钟左右,模型便会训练完成!
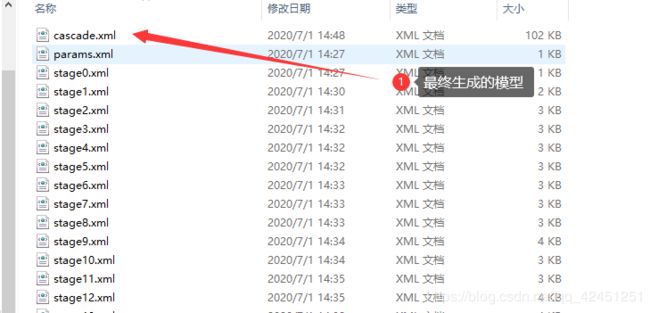
(3)、训练结束后会在xml目录下生成如图文件(其中cascade.xml就是我们训练得到的分类器)如下所示:
四、戴口罩检测
1、通过如下python代码,进行口罩模型训练的监测
1)、python代码如下所示:
import cv2
detector= cv2.CascadeClassifier('D:/python/python1/Lib/site-packages/cv2/data/haarcascade_frontalface_default.xml')
mask_detector=cv2.CascadeClassifier('F:/mask/xml/cascade.xml')
cap = cv2.VideoCapture(0)
while True:
ret, img = cap.read()
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = detector.detectMultiScale(gray, 1.1, 3)
for (x, y, w, h) in faces:
#参数分别为 图片、左上角坐标,右下角坐标,颜色,厚度
face=img[y:y+h,x:x+w] # 裁剪坐标为[y0:y1, x0:x1]
mask_face=mask_detector.detectMultiScale(gray, 1.1, 5)
for (x2,y2,w2,h2) in mask_face:
cv2.rectangle(img, (x2, y2), (x2 + w2, y2 + h2), (0, 0, 255), 2)
cv2.imshow('mask', img)
cv2.waitKey(3)
cap.release()
cv2.destroyAllWindows()
上面D:/python/python1/Lib/site-packages/cv2/data/haarcascade_frontalface_default.xml是opencv-python下载得时候里面的一个xml模型,自带的人脸识别模型文件,当然还有自带其他的xml文件,比如笑脸识别,猫脸识别,眼睛识别等等,在python安装路径下就能够找到该文件,前提你安装了opencv-python库哦!
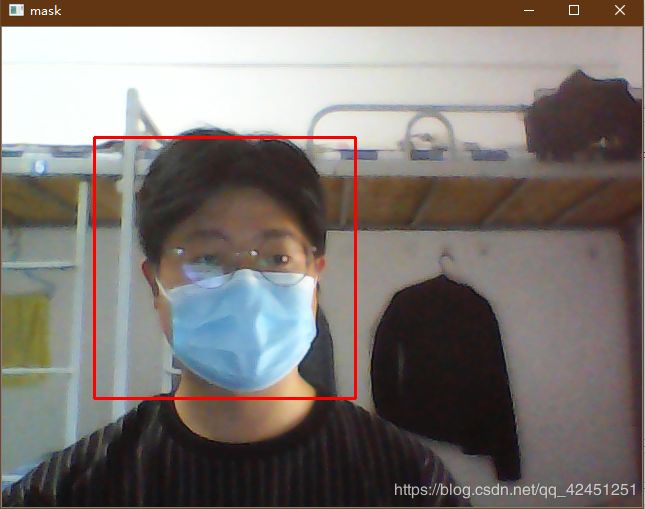
2)、运行结果如下所示:
(1)、佩戴口罩识别出人脸
(2)、不佩戴口罩便不能识别出来

哈哈,经过以上多次试验的发现,林君学长给的数据集数目过少,识别效率实在是过低,错误大,因此,小伙伴在进行口罩识别的时候,请务必提升数据集中图片的数量哦!
以上就是本次博客的全部内容,整体过程在熟悉之后便不会太复杂,相对简单,难点是对于环境的搭建,和在cmd中操作的不熟悉,但如果熟悉Ubuntn系统的操作,便不会反感在Win上的cmd中使用命令操作;遇到问题的小伙伴记得留言评论,学长看到会为大家进行解答的,这个学长不太冷!
天没降大任于我,照样苦我心智,劳我筋骨^ _ ^
陈一月的又一天编程岁月^ _ ^