这部分接着上一部分,主要分析日志的同步和安全性,以及成员变更等,在server成为leader后,会立即更新维护follower的信息:
72 void Peer::UpdatePeerInfo() {
73 for (auto& pt : (*peers_)) {
74 pt.second->set_next_index(raft_log_->GetLastLogIndex() + 1);
75 pt.second->set_match_index(0);
76 }
77 }
这两个字段的作用会在后面讲,然后立即primary_->AddTask(kHeartBeat, false);
89 void FloydPrimary::LaunchHeartBeat() {
90 slash::MutexLock l(&context_->global_mu);
91 if (context_->role == Role::kLeader) {
92 NoticePeerTask(kNewCommand);
93 AddTask(kHeartBeat);
94 }
95 }
140 void FloydPrimary::NoticePeerTask(TaskType type) {
141 for (auto& peer : (*peers_)) {
142 switch (type) {
143 case kHeartBeat:
146 peer.second->AddRequestVoteTask();
147 break;
148 case kNewCommand:
151 peer.second->AddAppendEntriesTask();
152 break;
153 default:
156 }
157 }
158 }
当新成为一个leader后(正常的同步会在后面完善起来),会同步一个空entry log而不是立即同步客户端的请求,为什么这么做,后面会分析。
然后开始向各follower同步,重要代码如下:
220 void Peer::AppendEntriesRPC() {
221 uint64_t prev_log_index = 0;
222 uint64_t num_entries = 0;
223 uint64_t prev_log_term = 0;
224 uint64_t last_log_index = 0;
225 uint64_t current_term = 0;
226 CmdRequest req;
227 CmdRequest_AppendEntries* append_entries = req.mutable_append_entries();
228 {
229 slash::MutexLock l(&context_->global_mu);
230 prev_log_index = next_index_ - 1;
231 last_log_index = raft_log_->GetLastLogIndex();
232 if (next_index_ > last_log_index && peer_last_op_time + options_.heartbeat_us > slash::NowMicros()) {
233 return;
234 }
235 peer_last_op_time = slash::NowMicros();
236
237 if (prev_log_index != 0) {
238 Entry entry;
239 if (raft_log_->GetEntry(prev_log_index, &entry) != 0) {
240 } else {
241 prev_log_term = entry.term();
242 }
243 }
244 current_term = context_->current_term;
246 req.set_type(Type::kAppendEntries);
247 append_entries->set_ip(options_.local_ip);
248 append_entries->set_port(options_.local_port);
249 append_entries->set_term(current_term);
250 append_entries->set_prev_log_index(prev_log_index);
251 append_entries->set_prev_log_term(prev_log_term);
252 append_entries->set_leader_commit(context_->commit_index);
253 }
254
255 Entry *tmp_entry = new Entry();
256 for (uint64_t index = next_index_; index <= last_log_index; index++) {
257 if (raft_log_->GetEntry(index, tmp_entry) == 0) {
258 Entry *entry = append_entries->add_entries();
259 *entry = *tmp_entry;
260 } else {
261 break;
262 }
263
264 num_entries++;
265 if (num_entries >= options_.append_entries_count_once
266 || (uint64_t)append_entries->ByteSize() >= options_.append_entries_size_once) {
267 break;
268 }
269 }
270 delete tmp_entry;
271
272 CmdResponse res;
273 Status result = pool_->SendAndRecv(peer_addr_, req, &res);
对于新成为的leader,执行pt.second->set_next_index(raft_log_->GetLastLogIndex() + 1);,此时prev_log_index和last_log_index相等;代码行241〜250去取最新一个已持久化的entry log,关键的是prev_log_index和prev_log_term,然后同步从next_index_到last_log_index处的日志;新成为leader的那刻要同步的日志为空;代码行252〜258是rpc;
当follower收到append entry log rpc后,如下:
789 int FloydImpl::ReplyAppendEntries(const CmdRequest& request, CmdResponse* response) {
790 bool success = false;
791 CmdRequest_AppendEntries append_entries = request.append_entries();
792 slash::MutexLock l(&context_->global_mu);
793 // update last_op_time to avoid another leader election
794 context_->last_op_time = slash::NowMicros();
795 // Ignore stale term
796 // if the append entries leader's term is smaller than my current term, then the caller must an older leader
797 if (append_entries.term() < context_->current_term) {
798 BuildAppendEntriesResponse(success, context_->current_term, raft_log_->GetLastLogIndex(), response);
799 return -1;
800 } else if ((append_entries.term() > context_->current_term)
801 || (append_entries.term() == context_->current_term &&
802 (context_->role == kCandidate || (context_->role == kFollower && context_->leader_ip == "")))) {
803 context_->BecomeFollower(append_entries.term(),append_entries.ip(), append_entries.port());
804 raft_meta_->SetCurrentTerm(context_->current_term);
805 raft_meta_->SetVotedForIp(context_->voted_for_ip);
806 raft_meta_->SetVotedForPort(context_->voted_for_port);
807 }
808
809 if (append_entries.prev_log_index() > raft_log_->GetLastLogIndex()) {
810 BuildAppendEntriesResponse(success, context_->current_term, raft_log_->GetLastLogIndex(), response);
811 return -1;
812 }
814 // Append entry
815 if (append_entries.prev_log_index() < raft_log_->GetLastLogIndex()) {
816 raft_log_->TruncateSuffix(append_entries.prev_log_index() + 1);
817 }
818
819 // we compare peer's prev index and term with my last log index and term
820 uint64_t my_last_log_term = 0;
821 Entry entry;
822 if (append_entries.prev_log_index() == 0) {
823 my_last_log_term = 0;
824 } else if (raft_log_->GetEntry(append_entries.prev_log_index(), &entry) == 0) {
825 my_last_log_term = entry.term();
826 } else {
827 BuildAppendEntriesResponse(success, context_->current_term, raft_log_->GetLastLogIndex(), response);
828 return -1;
829 }
830
831 if (append_entries.prev_log_term() != my_last_log_term) {
832 raft_log_->TruncateSuffix(append_entries.prev_log_index());
833 BuildAppendEntriesResponse(success, context_->current_term, raft_log_->GetLastLogIndex(), response);
834 return -1;
835 }
837 std::vector entries;
838 for (int i = 0; i < append_entries.entries().size(); i++) {
839 entries.push_back(&append_entries.entries(i));
840 }
841 if (append_entries.entries().size() > 0) {
842 if (raft_log_->Append(entries) <= 0) {
843 BuildAppendEntriesResponse(success, context_->current_term, raft_log_->GetLastLogIndex(), response);
844 return -1;
845 }
846 } else {
847 }
848 if (append_entries.leader_commit() != context_->commit_index) {
849 AdvanceFollowerCommitIndex(append_entries.leader_commit());
850 apply_->ScheduleApply();
851 }
852 success = true;
853 // only when follower successfully do appendentries, we will update commit index
854 BuildAppendEntriesResponse(success, context_->current_term, raft_log_->GetLastLogIndex(), response);
855 return 0;
856 }
情况一)当follower收到同步日志后,行797〜814,如果leader的term比自己小,说明出现了分区的情况(比如a/b/c/d/e/f/g,此时abcd一个分区,defg为一个分区,a为old leader,e为new leader,d的term更高于a的term);还有处理的是状态问题;一般情况在leader任期内term是相等的,那种网络波动收不到心跳转换角色或者其他问题是需要处理的;
情况二)行817〜822,同步当前日志,带上上一条已commit的日志term和index,如果follower的日志落后leader的,需要同步这些,只有这样,才能保证这整个log链是完全相同的;
然后行826〜831要删除(truncate suffix)append_entries.prev_log_index() + 1到raft_log_->GetLastLogIndex()处的日志,为什么删除,后面会说;
情况三)行835〜858用leader的prev log和自己最新的entry log比较,会存在不匹配的情况,比如获取不到prev index所对应的日志,再或者同样index的日志,但term不一致需要删除;
情况四)行861〜893开始写log到磁盘,并根据leader的commit index值选择性移动commit index的值,最后apply于状态机ApplyStateMachine(),last_applied < commit_index;
回到上面,当leader收到follower的append entry log response后,如下:
297 // here we may get a larger term, and transfer to follower
298 // so we need to judge the role here
299 if (context_->role == Role::kLeader) {
300 /*
301 * receiver has higer term than myself, so turn from candidate to follower
302 */
303 if (res.append_entries_res().term() > context_->current_term) {
304 context_->BecomeFollower(res.append_entries_res().term());
305 raft_meta_->SetCurrentTerm(context_->current_term);
306 raft_meta_->SetVotedForIp(context_->voted_for_ip);
307 raft_meta_->SetVotedForPort(context_->voted_for_port);
308 } else if (res.append_entries_res().success() == true) {
309 if (num_entries > 0) {
310 match_index_ = prev_log_index + num_entries;
311 // only log entries from the leader's current term are committed
312 // by counting replicas
313 if (append_entries->entries(num_entries - 1).term() == context_->current_term) {
314 AdvanceLeaderCommitIndex();
315 apply_->ScheduleApply();
316 }
317 next_index_ = prev_log_index + num_entries + 1;
318 }
319 } else {
320 uint64_t adjust_index = std::min(res.append_entries_res().last_log_index() + 1,
321 next_index_ - 1);
322 if (adjust_index > 0) {
323 // Prev log don't match, so we retry with more prev one according to
324 next_index_ = adjust_index;
325 AddAppendEntriesTask();
326 }
327 }
328 } else if (context_->role == Role::kFollower) {
329 } else if (context_->role == Role::kCandidate) {
330 }
331 return;
332 }
因为在同步log的时候,是有可能发现状态变更的,比如从leader转变为candidate或follower;如果还是leader的话,行305〜313因为收到更大term,从leader转变为follower;如果收到true了,如果num_entries大于0,更新match_index的值,表示已同步到哪儿;其中最重要的:
318 if (append_entries->entries(num_entries - 1).term() == context_->current_term) {
319 AdvanceLeaderCommitIndex();
320 apply_->ScheduleApply();
321 }
178 uint64_t Peer::QuorumMatchIndex() {
179 std::vector values;
180 std::map::iterator iter;
181 for (iter = peers_->begin(); iter != peers_->end(); iter++) {
182 if (iter->first == peer_addr_) {
183 values.push_back(match_index_);
184 continue;
185 }
186 values.push_back(iter->second->match_index());
187 }
190 std::sort(values.begin(), values.end());
191 return values.at(values.size() / 2);
192 }
193
194 // only leader will call AdvanceCommitIndex
195 // follower only need set commit as leader's
196 void Peer::AdvanceLeaderCommitIndex() {
197 Entry entry;
198 uint64_t new_commit_index = QuorumMatchIndex();
199 if (context_->commit_index < new_commit_index) {
200 context_->commit_index = new_commit_index;
201 raft_meta_->SetCommitIndex(context_->commit_index);
202 }
203 return;
204 }
只commit当前任期内的log或间接提交之前term的log,而不能直接提交,引用一下原因“commitIndex之后的log覆盖:是允许的,如leader发送AppendEntries RPC请求给follower,follower都会进行覆盖纠正,以保持和leader一致。
commitIndex及其之前的log覆盖:是禁止的,因为这些已经被应用到状态机中了,一旦再覆盖就出现了不一致性。而上述案例中的覆盖就是指这种情况的覆盖。
从这个案例中我们得到的一个新约束就是:当前term的leader不能“直接”提交之前term的entries必须要等到当前term有entry过半了,才顺便一起将之前term的entries进行提交”[https://yq.aliyun.com/articles/62425],然后统计并排序,看是否过半,如果是的话则把最新的entry log进行ScheduleApply,后面再同步给follower进行apply;
回到上面留下的坑,为什么server成为新的leader后会同步一条新的空entry呢(NOP)?出于安全性,必须要确保新的leader提交新的entry时把上一个term未提交的entry一起提交,而不是通过大多数去(直接)单独提交上一个term的entry[http://catkang.github.io/2017/11/30/raft-safty.html];另外,在对成员变更的情况下,由于代码中使用的是第一种方式,即每次只增加/减少一个server,引用如下链接中的说明“ Raft中成员变更如果保证是只变一个server这个前提,就不会出现双主问题。如果在同一term下,可以由leader确定这件事,但是如果有两个并发的成员变更,并且同时发生了切主,就有可能保证不了这一前提。
问题在于新主接收到客户端下一次成员变更请求的时候,可能集群中还可能有未确认的之前的成员变更日志,这个日志在将来可能会确认。
修复方案:Raft中,新主上任前要先确认一条NOP日志,然后才开始对外提供服务。
一旦新主在本term内确认了一条日志,那么说明新主已经确认了最新的成员组,并且集群中不会出现未确认的成员变更日志将来会被确认的情况了,在NOP确认后再开启成员变更就能保证每次只变一个server的前提。”[http://loopjump.com/raft_one_server_reconfiguration/]
从其他文章中复制两张ppt:

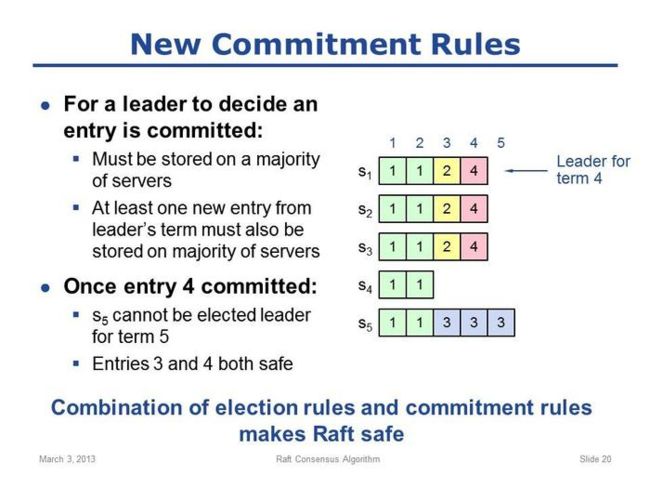
大概分析就到这里了,可能说的比较粗糙,更详细的建议看论文,最后一篇想结合代码分析下server的增加及减少的过程及可能出现的问题,及整个Floyd框架性的东西。
最近因工作非常忙,后面想慢慢的分析下leveldb里的实现和前面说的协程。
https://www.jianshu.com/p/10bdc956a305
https://www.jianshu.com/p/ee7646c0f4cf#
https://cloud.tencent.com/developer/article/1005803
https://cloud.tencent.com/developer/article/1005804
http://catkang.github.io/2017/06/30/raft-subproblem.html [Raft和它的三个子问题]
http://catkang.github.io/2017/11/30/raft-safty.html [Why Raft never commits log entries from previous terms directly]