split&concatenate&unstack&列表嵌套问题(循环,转换)
1. split
spilt是string的一个函数,一般是s.split(),其中s是一个字符串。
- spilt(seq, maxsplit):根据seq指定的原则返回一个列表,列表中每个元素仍未string
- seq是分隔符,\t:tab; \s:space; \n:enter以及其他指定标准,如按照&分离。默认是分隔所有的空字符,包含\t(制表符), \s, \n。
- maxsplit:最大分离次数,int型,即每次操作做多可以分离多少次,默认为-1,即分隔所有。
s1 = "a b c d 1 2 \
3 4" # \相当于是3的位置,如果\和2紧挨着,没有空格,则会显示23,非2 3
print('s1:', s1)
s2 = "a b c d 1 2\n3 4" # \n就相当于回车符号
print('s2:', s2)
s3 = 'a&b&c&d'
print('s3:', s3)
print(s1.split())
print(s2.split())
print(s3.split('&', 2))
s1: a b c d 1 2 3 4
s2: a b c d 1 2
3 4
s3: a&b&c&d
['a', 'b', 'c', 'd', '1', '2', '3', '4']
['a', 'b', 'c', 'd', '1', '2', '3', '4']
['a', 'b', 'c&d']
2. np.concatenate & pd.concat
concatenate是numpy中的一个api,这里与pd.concat做一个比较
- np.concatenate: concatenate((a1, a2, …), axis=0, out=None)沿着指定的axis拼接给定的array序列。多个array的行数或者列数或者其他维度数要有一个相同才能进行concatenate,且数组的维度必须相同(如一维向量与二维矩阵不能concatenate)。注:tf.concatenate与np.concatenate用法一样。
arr1 = [1, 2, 3]
arr2 = [4, 5, 6]
arr3 = [[1, 2, 3],
[4, 5, 6]]
arr4 = [[7, 8, 9],
[10, 11, 12]]
result1 = np.concatenate((arr1, arr2), axis = 0)# axis = 0 沿着行的方向拼接
print(result1)
result2 = np.concatenate((arr1, arr2), axis = 1) # 对于向量axis只能为0,因为arr本身只有第0维
[1 2 3 4 5 6]
---------------------------------------------------------------------------
AxisError Traceback (most recent call last)
in ()
1 result1 = np.concatenate((arr1, arr2), axis = 0)
2 print(result1)
----> 3 result2 = np.concatenate((arr1, arr2), axis = 1)
AxisError: axis 1 is out of bounds for array of dimension 1
result3 = np.concatenate((arr3, arr4), axis = 0)
print(result3)
result4 = np.concatenate((arr3, arr4), axis = 1)
print(result4)
[[ 1 2 3]
[ 4 5 6]
[ 7 8 9]
[10 11 12]]
[[ 1 2 3 7 8 9]
[ 4 5 6 10 11 12]
my_list = []
for i in range(2):
for i in range(2):
my_list.append(np.random.randint(1, 10, (1, 3, 5)))
result5 = np.concatenate(my_list) # 列表中每个元素是三维数组,concatenate时,构成列表形式的[]相当于参数(a1, a2, ...)中的小括号()
print(result5.shape)
(4, 3, 5)
- pd.concat: pd.concat(objs, axis=0, join=‘outer’, join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, copy=True)与np.concatenate有点类似,也是拼接给定的array(或者DataFrame)序列。但是concat拼接时会按照列或者行名进行填充、增加等。因此多个表的行数或者列数不一定相同
- objs是要进行拼接的对象,需要用列表表示,如[df1, df2],或元组表示,如(df1,df2)
- join是拼接的方式,有outer,inner。默认为outer。outer:所有表的信息都保留,inner:只保留表内共有的信息。
3. unstack & stack
unstack/stack在numpy、pandas、tensorflow、pytorch中均有出现,但四者作用有所差异,下面具体讲述。
3.1 np.stack & np.vstack & np.hstack
- np.stack: 堆叠的意思
官网解释中
参数: 数组:array_like的序列每个数组必须具有相同的形状。axis:int,可选输入数组沿其堆叠的结果数组中的轴。
返回: 堆叠:ndarray堆叠数组比输入数组多一个维。
从官方解释中,可以得到两条重要信息。一stack的数组形状要相同,二输出的维度比输入多1。可以看下面的例子:
a = np.array([1, 2, 3])
b = np.array([2, 3, 4])
c = np.array([3, 4, 5])
d = np.array([[1, 2], [3, 4]])
e = np.array([[4, 5], [5, 6]])
f = np.array([[6, 7], [7, 8]])
res1 = np.stack([a, b], axis = 0)
print(res1)
print('res1.shape:', res1.shape)
res2 = np.stack([a, b], axis = 1)
print(res2)
print('res2.shape:', res2.shape)
res3 = np.stack([a, b, c], axis = 0)
print(res3)
print('res3.shape:', res3.shape)
res4 = np.stack([a, b, c], axis = 1)
print(res4)
print('res4.shape:', res4.shape)
res5 = np.stack([d, e, f], axis = 0)
print(res5)
print('res5.shape:', res5.shape)
res6 = np.stack([d, e, f], axis = 1)
print(res6)
print('res6.shape:', res6.shape)
res7 = np.stack([d, e, f], axis = 2)
print(res7)
print('res7.shape:', res7.shape)
[[1 2 3]
[2 3 4]]
res1.shape: (2, 3)
[[1 2]
[2 3]
[3 4]]
res2.shape: (3, 2)
[[1 2 3]
[2 3 4]
[3 4 5]]
res3.shape: (3, 3)
[[1 2 3]
[2 3 4]
[3 4 5]]
res4.shape: (3, 3)
[[[1 2]
[3 4]]
[[4 5]
[5 6]]
[[6 7]
[7 8]]]
res5.shape: (3, 2, 2)
[[[1 2]
[4 5]
[6 7]]
[[3 4]
[5 6]
[7 8]]]
res6.shape: (2, 3, 2)
[[[1 4 6]
[2 5 7]]
[[3 5 7]
[4 6 8]]]
res7.shape: (2, 2, 3)
观察res1和res2,stack的a和b shape都是(3,),形状相同,且都为1维。最终结果为2维,由于a和b只有两个,所以在原来shape(3,)的基础上增加一维,且数为2。res3、res4都是拼接了三个形状一样的一维数组,故结果也是2维(比输入多一维),只是多的那一维上的数为3(因为拼接了a、b、c三个数组)。同理res5、res6、res7都是在原来的二维基础上变成了3维。多出的那一维,维数取决于拼接了几个array。但是多出的那一维应该加到什么位置呢,这由axis决定,当axis = 0时,多出的那一维加到第0维上;当axis=1时,多出的那一维加到第1维上。
数据的维度知道了,那么,数据stack后具体怎么排列呢,以res6为例,

对于三维,另一种简单记法:对于axis = 0,直接将多个array堆在一起;
对于axis = 1:a的第一行+b的第一行+c的第一行+…=第一个元素,a的第二行+b的二行+c的第二行+…=第二个元素
对于axis = 2:a的第一行+b的第一行+c的第一行+…=第一个元素的转置,a的第二行+b的二行+c的第二行+…=第二个元素的转置
- np.hstack(tup of array):h指horizontal水平的,将axis = 1的维度进行拼接,其余维度数要相同(二维矩阵就是增加列数),如
d1 = np.random.randint(1, 100, (4, 1, 2, 3, 4))
d2 = np.random.randint(1, 100, (4, 2, 2, 3, 4))
d3 = np.random.randint(1, 100, (4, 3, 2, 3, 4))
print(np.hstack([d1, d2, d3]).shape)
(4, 6, 2, 3, 4)
axis = 1的维度数=1+2+3,d1/d2/d3的其余维度数相同。
- np.vstack(tup of array):v指vertical垂直的,将axis = 0的维度进行拼接,其余维度数要相同(二维矩阵就是增加行数),如:
d1 = np.random.randint(1, 100, (4, 1, 2, 3))
d2 = np.random.randint(1, 100, (3, 1, 2, 3))
d3 = np.random.randint(1, 100, (2, 1, 2, 3))
print(np.vstack([d1, d2, d3]).shape)
(9, 1, 2, 3)
- numpy中没有unstack
3.2 pd.DataFrame.stack & pd.DataFrame.unstack
- pd.DataFrame.stack(level=-1, dropna=True):旋转列标签(列标签可能是分层的,最上层为level =0,往下依次为level=1,level=2),到行标签的内层。如下例:
index = pd.MultiIndex.from_tuples([('out1', 'c'), ('out1', 'd'),
('out2', 'c'), ('out2', 'd')])
column = pd.MultiIndex.from_tuples([('one', 'a'), ('one', 'b'),
('two', 'a'), ('two', 'b')])
s = pd.DataFrame(np.array([[1, 2, 3, 4],
[4, 5, 6, 7],
[1, 3, 4, 5],
[3, 4, 5, 6]]),
index = index, columns = column)
s

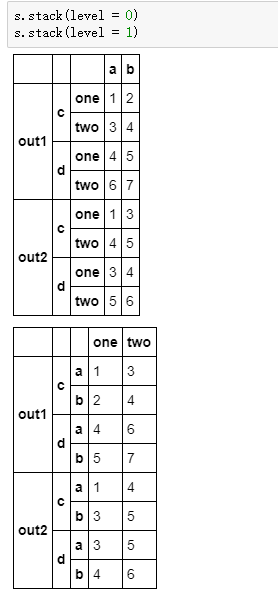
- pd.DataFrame.unstack(level=-1, fill_value=None):与pd.DataFrame.stack类似,将具有分层的行标签(index)旋转到列标签的内部:仍以上述的s为例:

3.3 tf.stack & tf.unstack
- tf.stack:同np.stack
x = tf.constant([[1, 2], [3, 4]])
y = tf.constant([[4, 5], [5, 6]])
z = tf.constant([[6, 7], [7, 8]])
res1= tf.stack([x, y, z], axis=0)
res2 = tf.stack([x, y, z], axis=1)
res3 = tf.stack([x, y, z], axis=2)
print(res1.shape)
print(res2.shape)
print(res3.shape)
(3, 2, 2)
(2, 3, 2)
(2, 2, 3)
- tf.unstack(value, num=None, axis=0, name=‘unstack’):是tf.stack的反向运算,如给定一个shape(A, B, C, D)的tensor,如果axis = 0,则result为A个shape=(B, C, D)的array,如果axis = 1,则result为B个shape=(A, C, D)的array,依次类推。返回的结果是一个由array构成的列表
a = tf.Variable([
[[1, 2, 3],
[4, 5, 6]],
[[7, 8, 9],
[10, 11, 12]]
])
result1 = tf.unstack(a, axis=0)
result2 = tf.unstack(a, axis=1)
result3 = tf.unstack(a, axis=2)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
res1, res2, res3 = sess.run([result1, result2, result3])
print(res1)
print('------------------------')
print(res2)
print('-------------------------')
print(res3)
print('------------------------')
[array([[1, 2, 3],
[4, 5, 6]], dtype=int32), array([[ 7, 8, 9],
[10, 11, 12]], dtype=int32)]
------------------------
[array([[1, 2, 3],
[7, 8, 9]], dtype=int32), array([[ 4, 5, 6],
[10, 11, 12]], dtype=int32)]
-------------------------
[array([[ 1, 4],
[ 7, 10]], dtype=int32), array([[ 2, 5],
[ 8, 11]], dtype=int32), array([[ 3, 6],
[ 9, 12]], dtype=int32)]
------------------------
3.4 torch.stack & torch.unstack
- torch.stack(seq, dim=0, out=None):与tf.stack作用一样,只是axis改成了dim

- torch 没有unstack
4. 列表嵌套问题
4.1 转化成array
# 对于列表套列表,内嵌列表维度相同
list1 = [[1, 2, 3], [4, 5, 6]]
arr1 = np.array(list1)
print(arr1)
print(arr1.shape)
[[1 2 3]
[4 5 6]]
(2, 3)
# 元素形状不同
list2 = [[1, 2], [1, 2, 3]]
arr2 = np.array(list2)
print(arr2)
print(arr2.shape)
[list([1, 2]) list([1, 2, 3])]
(2,)
list3 = [
[[1, 2, 3],
[4, 5, 6]],
[[7, 8, 9],
[1, 2, 3]]
]
arr3 = np.array(list3)
print(arr3)
print(arr3.shape)
[[[1 2 3]
[4 5 6]]
[[7 8 9]
[1 2 3]]]
(2, 2, 3)
for i in list3:
print(i)
print('one is finished')
for j in i:
print(j)
print('two is finished')
[[1, 2, 3], [4, 5, 6]]
one is finished
[1, 2, 3]
[4, 5, 6]
two is finished
[[7, 8, 9], [1, 2, 3]]
one is finished
[7, 8, 9]
[1, 2, 3]
two is finished
list4 = [
[[1, 2, 3],
[4, 5, 6]],
[[7, 8],
[1, 2]]
]
arr4 = np.array(list4)
print(arr4)
print(arr4.shape) # 取出第三维的数据格式不统一,故结果为二维
[[list([1, 2, 3]) list([4, 5, 6])]
[list([7, 8]) list([1, 2])]]
(2, 2)