Pytorch(三):Dataset和Dataloader的理解
目录
1.可迭代对象,迭代器
2.数据集遍历的一般化流程
3.Dataset
4.TensorDataset
5.Dataloader
1.可迭代对象,迭代器
首先,我们要明白python中的两个概念:可迭代对象,迭代器。
- 可迭代对象:
- 实现了
__iter__方法,该方法返回一个迭代器对象。
-
迭代器:
-
一个带状态的对象,内部持有一个状态,该状态用于记录当前迭代所在的位置,以方便下次迭代的时候获取正确的元素。
-
迭代器含有
__iter__和__next__方法。当调用__iter__返回迭代器自身,当调用next()方法的时候,返回容器中的下一个值。 - 迭代器就像一个懒加载的工厂,等到有人需要的时候才给它生成值返回,没调用的时候就处于休眠状态等待下一次调用。

- iter()函数:
1. 用法一:iter(callable, sentinel)
不停的调用callable,直至其的返回值等于sentinel。其中的callable可以是函数,方法或实现了__call__方法的实例。
2. 用法二:iter(collection)
1)iter()直接调用可迭代对象的__iter__(),并把__iter__()的返回结果作为自己的返回值,故该用法常被称为“创建迭代器”。
2)iter函数可以显示调用,或当执行“for i in obj:”,Python解释器会在第一次迭代时自动调用iter(obj),之后的迭代会调用迭代器的next方法,for语句会自动处理最后抛出的StopIteration异常。
3)但iter函数获取不到 __iter__方法时,还会调用 __getitem__方法,参数是从0开始能获取值就是可迭代的。
2.数据集遍历的一般化流程
for i, data in enumerate(dataLoader):enumerate(
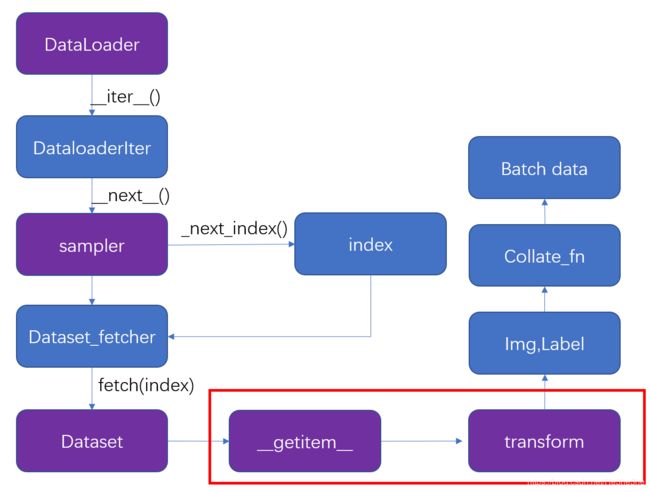
dataloader)会调用dataloader的__iter__()方法, 产生了一个DataLoaderIter(迭代器),这里判断使用单进程还是多进程,调用DataLoaderIter的__next__()方法来得到batch data。 在__next__()方法方法中使用_next_index()方法调用sampler(采样器)获得索引,接着通过dataset_fetcher的fetch()方法根据index(索引)调用dataset的__getitem__()方法, 然后用collate_fn来把它们打包成batch。当数据读完后,__next__()抛出一个StopIteration异常,for循环结束,dataloader失效.
3.Dataset
torch.utils.data.Dataset是代表这一数据的抽象类(也就是基类)。我们可以通过继承和重写这个抽象类实现自己的数据类,只需要定义__len__和__getitem__这个两个函数
如果在类中定义了__getitem__()方法,那么实例对象(假设为P)就可以这样P[key]取值。当实例对象做P[key]操作时,就会调用类中的__getitem__()方法。
class Dataset(object):
"""An abstract class representing a Dataset.
All other datasets should subclass it. All subclasses should override
``__len__``, that provides the size of the dataset, and ``__getitem__``,
supporting integer indexing in range from 0 to len(self) exclusive.
"""
def __getitem__(self, index):
raise NotImplementedError
def __len__(self):
raise NotImplementedError
def __add__(self, other):
return ConcatDataset([self, other])- 通过复写 __getitem__ 方法可以通过索引index来访问数据,能够同时返回数据和对应的标签(label),这里的数据和标签都为tensor类型
- 通过复写 __len__ 方法来获取数据的个数。
比如:
class MyDataset(Dataset):
""" my dataset."""
# Initialize your data, download, etc.
def __init__(self):
# 读取csv文件中的数据
xy = np.loadtxt('data-diabetes.csv', delimiter=',', dtype=np.float32)
self.len = xy.shape[0]
# 除去最后一列为数据位,存在x_data中
self.x_data = torch.from_numpy(xy[:, 0:-1])
# 最后一列为标签为,存在y_data中
self.y_data = torch.from_numpy(xy[:, [-1]])
def __getitem__(self, index):
# 根据索引返回数据和对应的标签
return self.x_data[index], self.y_data[index]
def __len__(self):
# 返回文件数据的数目
return self.len4.TensorDataset
TensorDataset是Dataset的子类,已经复写了__len__和__getitem__方法,只需传入张量即可。
class TensorDataset(Dataset):
"""Dataset wrapping tensors.
Each sample will be retrieved by indexing tensors along the first dimension.
Arguments:
*tensors (Tensor): tensors that have the same size of the first dimension.
"""
def __init__(self, *tensors):
assert all(tensors[0].size(0) == tensor.size(0) for tensor in tensors)
self.tensors = tensors
def __getitem__(self, index):
return tuple(tensor[index] for tensor in self.tensors)
def __len__(self):
return self.tensors[0].size(0)
- 比如:
可以看出我们把X和Y通过Data.TensorDataset() 这个函数拼装成了一个数据集,数据集的类型是【TensorDataset】
import torch
import torch.utils.data as Data
BATCH_SIZE = 5
x = torch.linspace(1, 10, 10)
y = torch.linspace(10, 1, 10)
torch_dataset = Data.TensorDataset(x, y)
loader = Data.DataLoader(
dataset=torch_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=0,
)
for epoch in range(3):
for step, (batch_x, batch_y) in enumerate(loader):
print('Epoch: ', epoch, '| Step: ', step, '| batch x: ', batch_x.numpy(), '| batch y: ', batch_y.numpy())
5.Dataloader
DataLoader是Pytorch中用来处理模型输入数据的一个工具类。组合了数据集(dataset) + 采样器(sampler),并在数据集上提供单线程或多线程(num_workers )的可迭代对象。
- 基本概念:
- epoch: 所有的训练样本输入到模型中称为一个epoch;
- iteration: 一批样本输入到模型中,成为一个Iteration;
- batchszie:批大小,决定一个epoch有多少个Iteration;
迭代次数(iteration)=样本总数(epoch)/批尺寸(batchszie)
- 函数原型:
torch.utils.data.DataLoader(dataset, batch_size=1,
shuffle=False, sampler=None,
batch_sampler=None, num_workers=0,
collate_fn=None, pin_memory=False,
drop_last=False, timeout=0,
worker_init_fn=None, multiprocessing_context=None)- 参数:
-
dataset (Dataset) – 决定数据从哪读取或者从何读取;
-
batch_size (python:int, optional) – 批尺寸(每次训练样本个数,默认为1)
-
shuffle (bool, optional) –每一个 epoch是否为乱序 (default:
False). -
num_workers (python:int, optional) – 是否多进程读取数据(默认为0);
-
drop_last (bool, optional) – 当样本数不能被batchsize整除时,最后一批数据是否舍弃(default:
False) -
pin_memory(bool, optional) - 如果为True会将数据放置到GPU上去(默认为false)
参考:
https://blog.csdn.net/u014380165/article/details/78634829
https://blog.csdn.net/zw__chen/article/details/82806900
https://www.cnblogs.com/yongjieShi/p/10456802.html
https://www.cnblogs.com/ranjiewen/p/10128046.html
Python 子类继承父类构造函数:https://www.runoob.com/w3cnote/python-extends-init.html
https://www.ziiai.com/blog/259
Python可迭代对象,迭代器,生成器的区别:https://blog.csdn.net/jinixin/article/details/72232604
完全理解Python迭代对象、迭代器、生成器:https://foofish.net/iterators-vs-generators.html
Pytorch中的数据加载艺术:http://studyai.com/article/11efc2bf
PyTorch 数据集(Dataset):https://geek-docs.com/pytorch/pytorch-tutorial/pytorch-dataset.html
https://www.cnblogs.com/marsggbo/p/11308889.html