pytorch 数据读取机制中的Dataloader与Dataset
版权声明:本文为CSDN博主「努力努力努力努力」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_37388085/article/details/102663166
怎么建立一个预测模型呢?第一是数据,第二是模型,第三是损失函数,第四是优化器,第五个是迭代训练过程。
这里主要学习数据模块当中的数据读取,数据模块通常还会分为四个子模块,数据收集、数据划分、数据读取、数据预处理。
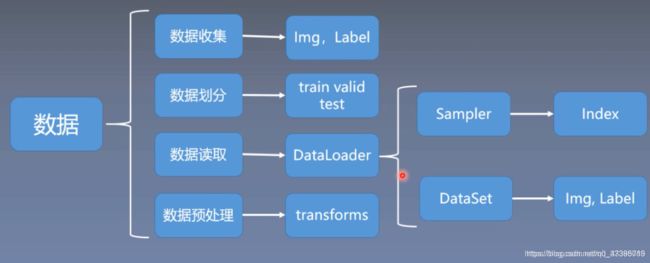
在进行实验之前,需要收集数据,数据包括原始样本和标签;
有了原始数据之后,需要对数据集进行划分,把数据集划分为训练集、验证集和测试集;训练集用于训练模型,验证集用于验证模型是否过拟合,也可以理解为用验证集挑选模型的超参数,测试集用于测试模型的性能,测试模型的泛化能力;
第三个子模块是数据读取,也就是这里要学习的DataLoader,pytorch中数据读取的核心是DataLoader;
第四个子模块是数据预处理,把数据读取进来往往还需要对数据进行一系列的图像预处理,比如说数据的中心化,标准化,旋转或者翻转等等。pytorch中数据预处理是通过transforms进行处理的;
第三个子模块DataLoader还会细分为两个子模块,Sampler和DataSet;Sample的功能是生成索引,也就是样本的序号;Dataset是根据索引去读取图片以及对应的标签;
这里主要学习第三个子模块中的Dataloader和Dataset;
这里主要学习第三个子模块中的Dataloader和Dataset;
2、DataLoader与Dataset
DataLoader和Dataset是pytorch中数据读取的核心;
2.1) DataLoader
(1)torch.utils.data.DataLoader
功能:构建可迭代的数据装载器;
dataset:Dataset类,决定数据从哪里读取及如何读取;
batchsize:批大小;
num_works:是否多进程读取数据;
shuffle:每个epoch是否乱序;
drop_last:当样本数不能被batchsize整除时,是否舍弃最后一批数据;
Epoch:所有训练样本都已输入到模型中,称为一个Epoch;
Iteration:一批样本输入到模型中,称之为一个Iteration;
Batchsize:批大小,决定一个Epoch中有多少个Iteration;
样本总数:80,Batchsize:8 (样本能被Batchsize整除)
1 Epoch = 10 Iteration
样本总数:87,Batchsize=8 (样本不能被Batchsize整除)
1 Epoch = 10 Iteration,drop_last = True
1 Epoch = 11 Iteration, drop_last = False
DataLoader(dataset,
batch_size=1,
shuffle=False,
sampler=None,
batch_sampler=None,
num_works=0,
clollate_fn=None,
pin_memory=False,
drop_last=False,
timeout=0,
worker_init_fn=None,
multiprocessing_context=None)
2)torch.utils.data.Dataset
Dataset是用来定义数据从哪里读取,以及如何读取的问题;
功能:Dataset抽象类,所有自定义的Dataset需要继承它,并且复写__getitem__();
getitem:接收一个索引,返回一个样本
class Dataset(object):
def __getitem__(self, index):
raise NotImplementedError
def __add__(self, other)
return ConcatDataset([self,other])
接着是Transform,用于对数据进行预处理,代码中的Resize是对数据进行缩放,RandomCrop是对数据进行裁剪,ToTensor是对数据进行转换,把图像转换成张量数据。代码具体如下
train_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
]) # Resize的功能是缩放,RandomCrop的功能是裁剪,ToTensor的功能是把图片变为张量
接着是重点,构建Dataset和DataLoader;Dataset必须是用户自己构建的,在Dataset中会传入两个主要参数,一个是data_dir,也就是数据的路径,就是三个问题中的第二个,从哪读数据;第二个参数是transform,transform是数据预处理,数据预处理之后会介绍,这里暂时不做分析;
# 构建MyDataset实例,MyDataset必须是用户自己构建的
train_data = RMBDataset(data_dir=train_dir, transform=train_transform) # data_dir是数据的路径,transform是数据预处理
现在了解一下上面代码中RMBDataset中的具体实现;按住Ctrl,然后单击RMBDataset函数或者类就可以跳转到具体函数实现的位置;
跳转到RMBDataset函数中后,可以发现其具体代码实现如下:
class RMBDataset(Dataset):
def __init__(self, data_dir, transform=None):
"""
rmb面额分类任务的Dataset
:param data_dir: str, 数据集所在路径
:param transform: torch.transform,数据预处理
"""
self.label_name = {"1": 0, "100": 1} # 初始化部分
self.data_info = self.get_img_info(data_dir) # data_info存储所有图片路径和标签,在DataLoader中通过index读取样本
self.transform = transform
def __getitem__(self, index): # 函数功能是根据index索引去返回图片img以及标签label
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB') # 0~255
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等
return img, label
def __len__(self): # 函数功能是用来查看数据的长度,也就是样本的数量
return len(self.data_info)
@staticmethod
def get_img_info(data_dir): # 函数功能是用来获取数据的路径以及标签
data_info = list()
for root, dirs, _ in os.walk(data_dir):
# 遍历类别
for sub_dir in dirs:
img_names = os.listdir(os.path.join(root, sub_dir))
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names))
# 遍历图片
for i in range(len(img_names)):
img_name = img_names[i]
path_img = os.path.join(root, sub_dir, img_name)
label = rmb_label[sub_dir]
data_info.append((path_img, int(label)))
return data_info # 有了data_info,就可以返回上面的__getitem__()函数中的self.data_info[index],根据index索取图片和标签
上面这段代码就是RMBDataset的具体实现;代码中构建了两个Dataset,一个用于训练,一个用于验证;
有了Dataset就可以构建数据迭代器DataLoader,DataLoader会传入一个参数Dataset,也就是前面构建好的RMBDataset;第二个参数是batch_size;在代码中可以看到,在训练集中的DataLoader中有一个参数是shuffle=True,它的作用是每一个epoch中样本都是乱序的,具体代码如下:
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True) # shuffle=True,每一个epoch中样本都是乱序的
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
————————————————
版权声明:本文为CSDN博主「努力努力努力努力」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_37388085/article/details/102663166