本文来自OPPO互联网技术团队,转载请注名作者。同时欢迎关注我们的公众号:OPPO_tech,与你分享OPPO前沿互联网技术及活动。
图像修复又称为图像补绘&图像填充,指的是——重建图像中丢失或损坏部分的过程,是介于图像编辑和图像生成之间的一种技术。
- 图像补绘:Image Inpainting
- 图像填充:Region Filling
具体来说:图像修复通过替换&填充图像中指定区域的纹理/像素,使其与周围纹理/像素融为一体,达到自然和谐的修复效果。
图像修复技术有许多目标和应用,如:
- 修复及填充老照片中的裂缝、划痕和瑕疵区域;
- 消除照片上的日期、水印;
- 移除不需要的图像内容,并用合理的图像内容填补移除后的空缺。
1. 方法
图像修复方法按技术发展脉络可主要分为三大类:
- 逐像素填充;
- 逐区块填充;
- 基于深度学习的填充。
1.1 逐像素填充
该类修复方法的代表性算法为基于Fast Marching Method的补绘算法,由Alexandru Telea于2004发表的论文
《An Image Inpainting Technique Based on the Fast Marching Method》中提出。
其基本思想为:从需要进行补绘区域的边界开始,由边界到中心逐渐填充待补绘区域中的所有像素,待填充像素由其邻域中所有已知像素的加权和得到。
其中权重的选择很重要,对于靠近待填充点、靠近边界法线及位于边界轮廓上的那些像素给予较大的权重。
当一个像素被填充后,算法使用fast marching method找到下一个最邻近像素并对其进行填充。FMM是种启发式的搜索算法,确保首先修复已知像素周围的像素。
该类方法的特点是运算速度快,适合小区域修复,对复杂背景及大区域缺失修复存在模糊及填充纹理不自然的问题。
1.2逐区块填充
该类方法每次填充待补绘区域的一个patch,其核心思想就是利用图像本身的冗余性(redundancy),用图像已知部分的信息来补全未知部分。
代表性论文是《Region Filling and Object Removal by Exemplar-Based Image Inpainting》。
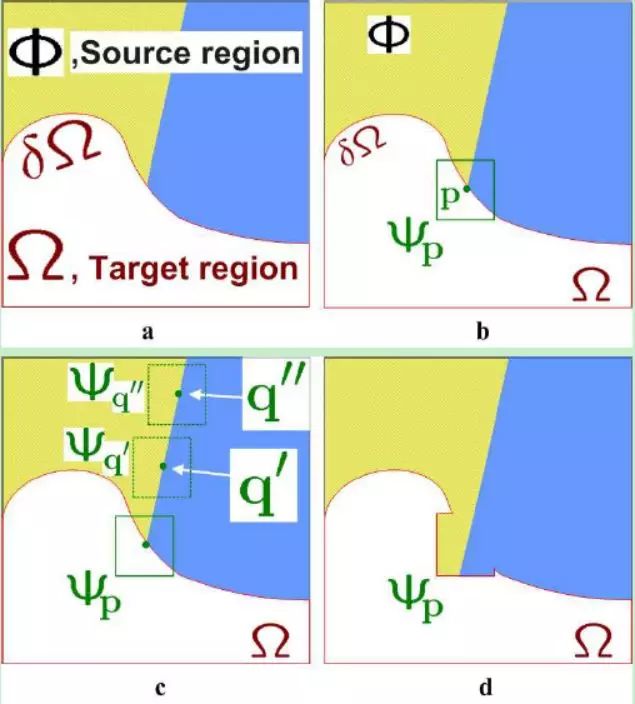
其流程由计算优先级,搜索及复制三个部分组成,与逐像素填充的步骤类似。不过这里是以patch为单位进行处理的。
1.2.1 计算优先级
优先级决定了移除顺序,保证图像中的线性结构传播,目标边界连通。
具体操作为:对待补全区域边界的像素依次计算补绘顺序的优先度(priority)。
这个优先度主要考虑两个方面的因素:
- 周围像素可信度高的位置要优先补;
- 位于图像梯度变化剧烈的位置要优先补。
综合二者得到优先度之后,挑选优先度最高的像素来补。
1.2.2 搜索
根据纹理相似度在已知区域中为待填充patch在找到最佳匹配块:对于上一步找到的待补全像素,考虑它周围的一个小patch(比如3*3)。在图像已知部分搜索所有的patch,找到最相似的patch。
1.2.3 复制
将最佳匹配块复制到对应的目标区域位置,并更新目标区域的边界与置信度值。
下图为该流程示意图:
其效果如下所示:

该类方法相对逐像素的修复方法,能修复更大范围的区域,填充效果也更加自然一些。但因需在整副图像上搜索相似的patch,计算复杂度较高。
1.3基于深度学习的填充
图像补绘可以看成一种特殊的图像生成问题,其生成的是图像的局部(待填充区域),利用的是图像已知部分的纹理。
得益于GAN在图像生成领域的快速发展与优异表现,基本上基于深度学习的图像修复技术都是用GAN来做的,下面介绍几篇典型的论文。
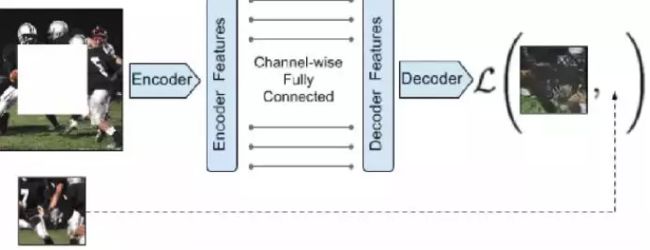
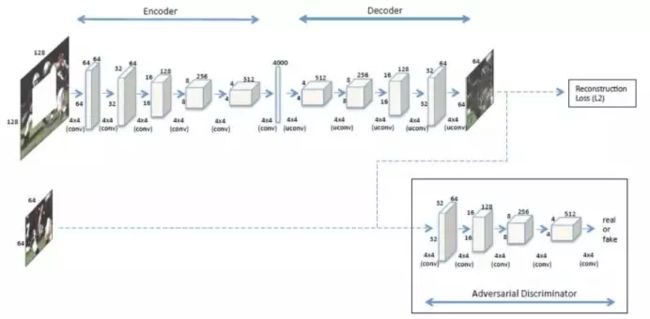
CVPR 2016的Context-Encoders[1]是使用DL做inpainting的开山之作。主要思路是结合Encoder-Decoder 结构和GAN模型。
Encoder-Decoder 阶段用于学习图像特征和生成图像待修补区域对应的预测图;
GAN部分用于判断预测图是模型生成的还是来自真实的GroundTruth。当生成的预测图与GroundTruth在图像内容上达到一致,并且GAN的判别器无法区分时,就认为网络模型参数达到了最优状态。
网络训练的过程中损失函数都由两部分组成:
- Encoder-decoder 部分的图像内容约束(Reconstruction Loss);
- GAN部分的对抗损失(Adversarial Loss)。
Context Encoders 采用最简单的整体内容约束,也就是预测图与原图的L2 距离。
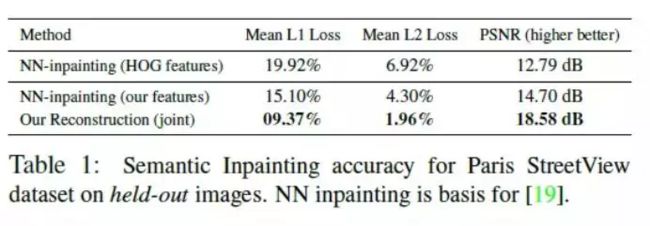
以下表格显示了该方法相较于之前方法的优越性:
在Context-Encoders论文的基础上,后续又出现了大批的基于DL来做图像修复的论文。比如:
- CVPR 2017《High-resolution image inpainting using multi-scale neural patch synthesis》[2]:结合了风格迁移的思路;
- ECCV 2018《Image Inpainting for Irregular Holes Using Partial Convolutions》[3]:引入了局部卷积,能够修复任意非中心、不规则的区域。
- ICCV 2019《Coherent Semantic Attention for Image Inpainting》[4]提出了一个全新的Attention模块,该模块不仅有效的利用了上下文信息,同时能够捕捉到生成patch之间的相关性。论文同时提出了一个新的损失函数配合Attention模块的工作,最后利用一个新的特征感知辨别器对细节效果进行加强。下图为该模型的架构图:

下面分别介绍这篇论文中使用到的三个重要模块:
连贯性语义注意力机制(Coherent semantic attention)
该模块分成两个部分——第一部分称为搜索阶段,第二部分称为生成阶段。

其中蓝色区域为待填充区域,灰色为上下文区域,需要针对蓝色区域中每一个点找到最相关的上下文区域并且替换进来,这样所有的马赛克区域就都被上下文区域填满,然后进行第二步生成阶段。生成阶段采用光标扫描的方式从上至下从左至右进行生成,详细的生成步骤可参考论文。
Consistency loss
要保证编码器和解码器对应层需要语义一致性,并且要让Coherent semantic attention层能够更好的工作,文章利用VGG提取原图的特征空间,并将这个特征空间作为CSA(Coherent semantic attention)层和其对应的解码器层的标签并计算L2距离,这样就能够保证编码器和解码器对应层需要语义一致性并且提升CSA的效果。
Feature patch discriminator
使用VGG提取图片的特征空间,并在这个特征空间上利用patch discriminator进行对抗损失计算,这样能够更加好的帮助生成器理解图像信息,同时稳定辨别器训练。
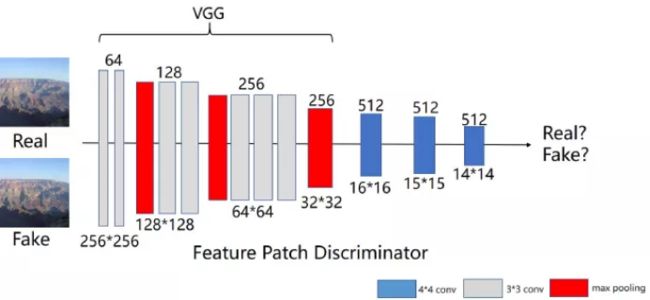
以下为该论文的效果图(第4列为论文提出的方法,第5列为GroundTruth):



2. 总结
传统的图像修复方法,一般来说都使用图像剩余部分的统计信息来填补空缺,但这种方法受限于可用的图像统计信息,且不具备视觉语义学的概念,因此修复效果不够自然,其优点是速度快。
而使用深度学习技术的方法结合图像生成模型GAN,有更好的修复效果,但较为耗时,可结合网络模型压缩技术进行提速。具体使用场景中可根据实际需要选择相应的方法进行使用。
参考文献
[1] Pathak D, Krahenbuhl P, Donahue J, et al. Context encoders: Feature learning by inpainting[C]//Proceedings of the IEEE conference
[2] Yang C, Lu X, Lin Z, et al. High-resolution image inpainting using multi-scale neural patch synthesis[C]//Proceedings of the IEEE Conference
[3] Liu G, Reda F A, Shih K J, et al. Image inpainting for irregular holes using partial convolutions[C]//Proceedings of the European Conference
[4] Liu H, Jiang B, Xiao Y, et al. Coherent Semantic Attention for Image Inpainting[J]. arXiv preprint arXiv:1905.12384, 2019.
[5]知乎-结合深度学习的图像修复:https://www.zhihu.com/questio...
[6]图像修复论文笔记- Context Encoders: Feature Learning by Inpainting:https://www.jianshu.com/p/e1b...
[7] 知乎专栏-图像修复:https://zhuanlan.zhihu.com/p/...
