条件随机场学习笔记
条件随机场学习笔记
前言
这是在《统计学习方法》中学习到的最后一个方法了,不像其他统计方法,学完精气神超足,都能让我继续振奋好几日。然学完该方法,我陷入了沉思与迷茫。首先,对条件随机场的【提出】和【应用场景】一片混沌,其次,说说它的思想吧,无非加入了【空间属性】,相比最大熵模型,多加入了【边特征函数】,而随机变量【X,Y】的联合概率分布的表达式并没有发生本质变化,所以说,它还是一个我认为的【概率模型】。既然是【概率模型】,那么它依旧可以用【对数似然函数】进行迭代求解,事实也是这样做的。但我所不解的是为何概率表达式清一色的表示为exp和规范化因子呢?难道仅仅因为exp在求导和概率计算中有很好的性质么?
在知乎上【如何用简单易懂的例子解释条件随机场(CRF)模型?它和HMM有什么区别?】提到了一篇经典论文,对上述有疑问的童鞋们,可以参考一下,本人暂且不研读。
from Sutton, Charles, and Andrew McCallum. “An introduction to conditional random fields.” Machine Learning 4.4 (2011): 267-373.
条件随机场进阶一
这里先简单叙述下条件随机场的几个基本概念,方便后续理解。首先,【条件随机场】其实分为两个关键词【条件】和【随机场】,他俩需要明确区分,咱们分别叙述下。【条件】对应于【条件概率】,说起条件概率,我们就需要扯一扯【联合概率】,所以待会先来谈谈【联合概率】问题。其次,【随机场】对我来说是一个全新的概念,参考相关资料发现,它是单独定义的。所以,条件+随机场 = 条件随机场。
条件随机场的由来
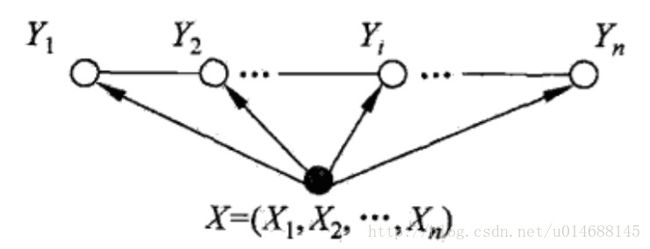
如果参看《统计学习方法》第11章节的话,你会发现一个很有趣的现象。书中首先提到的是图,图有个很有趣的特性,你会发现每个节点都是平铺在一个平面上的,所以每个节点都有可能与另外一个结点阐述【联系】,也就是所谓的【E or 边】。有了图的定义,便开始定义【联合概率】分布下,各随机变量的图结构,并对每个节点进行约束,所谓的三种性质【成对马尔科夫性】、【局部马尔科夫性】和【全局马尔科夫性】,节点的约束一步步增强。定义完这些后,便在此基础上有了马尔科夫随机场的概念,我就呵呵了,你给我一堆定义,我怎么知道谁和谁是【组合】,谁是谁的【递进】关系啊。
好吧,还是按照自己的思路来重新梳理下吧。之前学习过隐马尔可夫模型的话,我们知道它是一个时间序列模型。起初对这个【时间】不以为然,隐马尔可夫模型中的节点,不就是一个个状态么,何必叫时间序列模型,还不如更名为状态序列模型。学到条件随机场,发现了HMM和CRF的一个显著区别,即节点与节点之间的边,HMM是有向的,而CRF是无向的。而时间序列,能很好的表达当前状态与之前状态有关而和后续状态无关这一特性,即在图中的有向性,因此时间序列模型相比状态模型更合适。而CRF则可以成为一个HMM的扩展,称为状态序列模型更合适,从【有向边】升级到【无向边】。
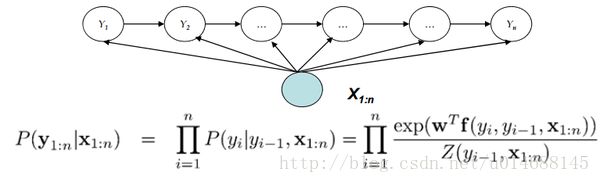

这张图很好的描述了HMM和CRF之间的差异,暂且不去关注底下的公式和随机变量X,单独看 Y1∼Yn 的联合概率在图中的表现形式。是不是很有爱,有数学之美。
对于条件随机场是不有个简单的认识了,再来看看wiki上关于Random Field的定义。
A random field is a generalization of a stochastic process such that the underlying parameter need no longer be a simple real or integer valued “time”, but can instead take values that are multidimensional vectors, or points on some manifold.
注意我标黑的字词,我这里就大胆猜测下概率论研究的一个阶段成果,无实际根据,纯属个人臆想。在Demon同学的世界里,概率论现分为两个阶段,有向概率论和无向概率论。起初,为了研究现实生活中大量的【数据现象】,诸如统计欧洲黑死病每年死亡人数,通过数据判断黑死病是否逐年严重or维持在某个稳定状态。在那个时代,统计学者们收集到的大量数据,都存在一个明显的特征即随机变量的先后顺序,所以从维度上来看,对这些数据的研究,完全可以映射到二维的横轴和纵轴,横轴表示随机变量,而纵轴表示当前随机变量的出现概率。所以对概率密度函数的积分,你也会发现,它一定是从负无穷累加到当前时间点t,而不会继续积下去了。它对随机变量时间的统计是有向的。
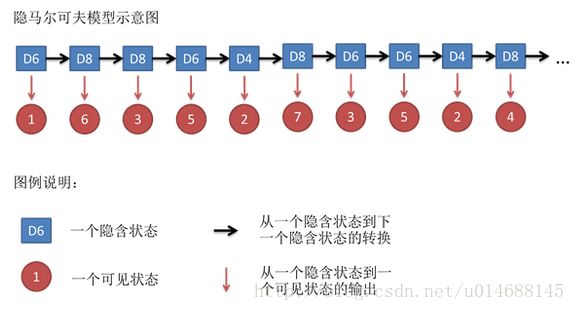
这是一张经典的隐马尔可夫模型图,我们关注隐含状态的序列,你会发现在同一时刻,只有一个状态指向下一个状态,不会出现多个状态同时指向一个状态的情况发生,这是因为隐马尔可夫模型做了一个基本假设,即在同一时刻,不存在两个或者多个状态同时发生的情况,起初这的确合理,比如掷骰子的过程,一定是一次次投掷得出的结果,但对一维的时间如此,但对二维空间就一定是这样子么?
参看《统计学习方法》词性标注的例子
输入:At Microsoft Research, we have an insatiable curiosity and the desire to create new technology that will help define the computing experience.
输出:At/O Microsoft/B Research/E, we/O have/O an/O insatiable/B curiosity/E and/O the/O desire/BE to/O create/O new/B technology/E that/O will/O help/O define/O the/O computing/B experience/E.
这一内容在博文【隐马尔可夫学习笔记(一)】引出过,这里就不在详细叙述了。HMM所做的就是统计当前状态与前一状态在整个序列中出现的频次,从而估算出转移概率矩阵。它有个很明显的特征在于,假设语句是按时间顺序一个一个生成的,所以可以不用考虑当前单词与下一单词的关系,而只需统计与上一单词的联系。但在真正的训练过程当中,所有句子的训练集,并非单纯的一维时间啊,我们完全可以映射到二维空间中去,统计当前单词和上一单词以及前一单词的关系,这是完全可以做到的,因为程序在训练语料时,它把握了全局信息,而且从语义上来看,更加符合句子的构成。
所以说,条件随机场是隐马尔可夫模型的加强版,无非从原先的【时间维度】上升到了【空间维度】,而后者更加合理,每个状态所依赖的信息更多。
在这里引用博文【随机场(Random field)】中关于马尔科夫随机场的形象例子,它说
随机场包含两个要素:位置(site),相空间(phase space)。当给每一个位置中按照某种分布随机赋予相空间的一个值之后,其全体就叫做随机场。我们不妨拿种地来打个比方。“位置”好比是一亩亩农田; “相空间”好比是种的各种庄稼。我们可以给不同的地种上不同的庄稼,这就好比给随机场的每个“位置”,赋予相空间里不同的值。所以,俗气点说,随机场就是在哪块地里种什么庄稼的事情。
好了,明白了上面两点,就可以讲马尔可夫随机场了。还是拿种地打比方,如果任何一块地里种的庄稼的种类仅仅与它邻近的地里种的庄稼的种类有关,与其它地方的庄稼的种类无关,那么这些地里种的庄稼的集合,就是一个马尔可夫随机场。
马尔可夫随机场,描述了具有某种特性的集合。拿种地打比方,如果任何一块地里种的庄稼的种类仅仅与它邻近的地里种的庄稼的种类有关,与其它地方的庄稼的种类无关,那么这些地里种的庄稼的集合,就是一个马尔可夫随机场。
简单总结下概念,什么是马尔科夫随机场,首先随机变量由图中各节点表示,每个节点至少有一条边与其另一个节点相连(不会出现孤立节点,孤立节点毫无意义)。那么整个图由 Y1,Y2,...,Yn 节点,图所代表的物理含义为 P(Y1,Y2,...,Yn) 的联合概率,一定是联合概率,否则表示成图也没有任何意义。马尔科夫性在于当前节点只与相邻节点有关,它的概率受邻居影响。何谓随机场?从随机变量【一维时间序列】上升到了随机变量【二维空间图结构】,【有向】到【无向】的飞跃在于维度的上升,个人觉得拿它做区分欠妥,容易产生误解。
其实说了一大堆,我们只是在阐述隐马尔可夫模型和马尔科夫随机场的区别,根本还未涉及条件随机场的概念。刚才说了随机场一定表现为【联合概率】,因此随机变量一定是作为一个整体出现的,我们可以用图去刻画,这点很明确了,给你某个马尔科夫随机场吧,用图来表示各节点与边的关系,记作 G(V,E) 。那么 P(Y1,...,Yn) 表示该图的值咯,所以简单点
好了,条件随机场是什么?很显然,对于每个随机变量 Yn 是否还需要做些限定呢?否则怎么能叫条件随机场呢?所以对于每个单独的随机变量 Yn 都有一个条件 Xn 做限定,条件概率为 P(Yn|Xn) ,限定约束在节点上即可。图结构参考如下:
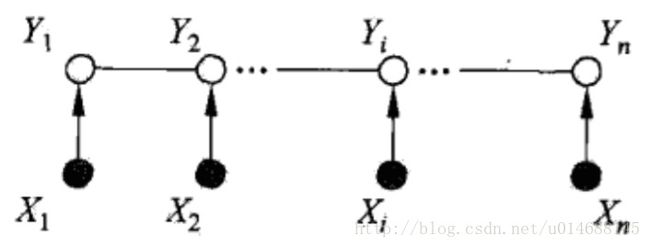
这才是我们真正的条件随机场,已知一堆样本数据,无非求 P(Y|X) 在输入序列为 X 的情况下,最有可能输出序列 Y 。
条件随机场进阶二
怎么说呢,看了“An introduction to conditional random fields.” Machine Learning 4.4 (2011): 267-373.的第二章内容,发现一张图就能完全概括条件随机场的由来。见下图:
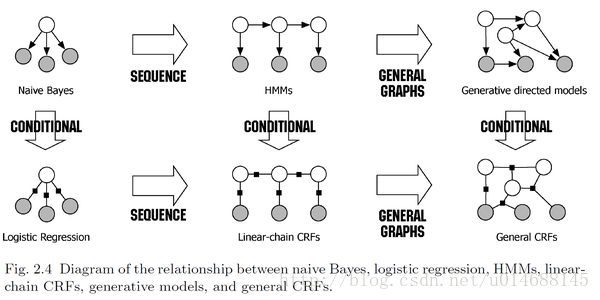
从图中你能找到CRF所处的位置,它可以从朴素贝叶斯方法【用于分类】经过【sequence】得到HMM模型,再由HMM模型【conditional】就得到了CRF。或者由朴素贝叶斯方法【conditional】成逻辑斯蒂回归模型,再【sequence】成CRF,两条路径均可。
在该论文中,它提出了两个模型分别叫做【generative model】和【discriminative model】,中文分别是【生成模型】和【判别模型】。朴素贝叶斯和隐马尔可夫模型被归为生成模型,而逻辑斯蒂回归模型和条件随机场被归为判别模型。它们有何区别?这里我拿朴素贝叶斯模型和逻辑斯蒂回归模型举例,来说说自己的看法。
首先来看看朴素贝叶斯的模型:
其中X可以是特征向量, X=(x1,x2,...,xn) ,朴素贝叶斯的一个假设在与每个特征独立同分布,所以 P(X|Y)=P(x1|Y)P(x2|Y)⋯P(xn|Y) 。整理得:
而逻辑斯蒂回归模型长什么样?同样的,对于分类问题,有输入空间 X=(x1,x2,...,xn) ,那么整个模型为:
其中,Z为规范化因子。如果特征函数 fi(X,Y)=xi 情况下,就是一般形式的逻辑斯蒂回归模型了。
对于这两个模型有何区别么?不急,先来看看这张图。
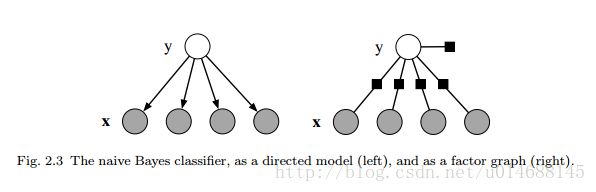
怎么说呢,我找了很久的区别,但始终没有发现朴素贝叶斯和逻辑斯蒂回归模型的本质,令我更加头疼的是,即时发现了一些区别,但始终无法理解这些区别如何作用于数据集,如何影响预测结果。
先来说说朴素贝叶斯吧,在朴素贝叶斯中,它的模型是以联合概率 P(Y,X) 体现的,从图中也能看出,只要我们求出了每个特征随机变量x的分布,如在《统计学习方法》第四章的例4.1所示,有两个特征,分别表示为 x1,x2 且 x1∈1,2,3,x2∈S,M,L ,那么朴素贝叶斯的做法是,给你一堆数据集,分别求出 P(x1|Y=1)和P(x1|y=−1) 的分布,注意,这里是随机变量 x1 ,同理,也能求得随机变量 x2 的分布,又由于朴素贝叶斯各特征之间独立同分布的假设,所以联合概率 P(Y,X) 就是两个随机分布的乘机再乘以标签 Y 的分布。
什么意思呢,如果从逻辑斯蒂回归模型的角度去表示朴素贝叶斯,那么该怎么表示呢?
其中 θy=logP(yc),θyi=logP(xi|yc) , [X=xi|Y=yc] 表示指示函数,当且仅当方括号中的条件满足时,取值为1否则为0,也就是最大熵模型中的特征函数 fi(xi,yc) 。如果式子写到这里,想比较两者的区别,是得不到任何有趣的东西,这点我想了很久,在于忽略了一个重要的因素,仔细观察条件概率 P(xi|yc) ,X是一个特征向量,而在每个特征向量中,还有随机变量 xi ,所以,式子到这还没有结束,应为
很可惜,这里只选中第 i 个随机变量的第 k 个值,所以式子又进一步简化为:
这就是从逻辑斯蒂回归模型看贝叶斯模型,我们能得到一个什么样的结论?对于输入空间 X ,每个特征的分布我们都会求出来,如特征 x1 的条件分布 p(x1|yc) 。所以朴素贝叶斯根据给定的训练集求的是 P(X|Y=yc) 的整体分布。从图来看的话,每个随机变量 xi 的节点值为1,而边权值代表了每个节点 xi 的分布。
总结完朴素贝叶斯,回过头来看看逻辑斯蒂回归模型的定义,我们参考《统计学习方法》第六章的内容。
首先,逻辑斯蒂回归模型最终模型表达为条件概率,而非联合概率,这是一个区别,其次仔细对比exp中的内容,你会发现参数 θyi 后的【特征函数】有区别,没错,这是我能看到的最大区别。如果说之前 xi 为随机变量,那么这里就不再考虑输入空间 xi 的状态数了,而是直接作为值输入到模型中进行训练,从图中可以发现,节点 xi 的值并不是1,而是具体的某个任何可能的实数。逻辑斯蒂回归模型,并不计算 P(xi|yc) 的分布,而是把每个特征的实际值代入模型,进行整体训练。虽然是这么说,但我不知道怎么整体训练,难道是把所有的特征组合的联合概率 P(X|yc) 都看成一个黑盒?这点着实不太明白。但逻辑斯蒂回归模型相比朴素贝叶斯方法,它的模型更加灵活,因为特征函数可以选取指示函数,也可以是 q(xi) 的实数映射,可以说是朴素贝叶斯的推广吧。
以上虽然能看出两者的一些区别,但却不知道这些区别对模型训练有何影响,只作为单纯的个人思考笔记,知识有限,暂且不解答了。接下来咱们继续条件随机场的内容。
可以明确的是,条件随机场是从最大熵模型那里衍化过来的,所以它们的条件概率表达式清一色的为exp函数与规范化因子。
在最大熵模型中或者说是逻辑斯蒂回归模型中,exp里只包含 f(y,x) 的联合特征函数,而在CRF中,多了一项所谓的标签之间的关系,也就是 tk(yi−1,yi,x,i) ,所以自然求的也是序列的联合概率。那么问题有回到了HMM所提出的三个问题,该式的联合概率该怎么求,式中的参数该怎么训练得到。
条件随机场进阶三
概率计算问题
节点在图中的概率计算
条件随机场的概率计算和HMM的概率计算没有本质区别,可以说是完全一样的,这里就不再赘述了,详细的可以参考博文【隐马尔可夫学习笔记(一)】中的前向算法以及【隐马尔可夫模型之Baum-Welch算法详解】中的前向后向算法。
这里就阐述下大致思路,此处都是为了计算每个节点的概率,如书中提到的 P(Y=yi|x) 的概率,对于这类概率计算,从图的模型该怎么得到呢?这类问题我们用个前向算法或者后向算法其中的任何一个就可以解决了。前向or后向算法,都是扫描一遍整体的边权值,计算图的 P(X) ,指示它们扫描的方向不同,一个从前往后,一个从后往前。所以书中的公式:
这里的计算和HMM模型没什么两样。有了 P(x) ,那么 P(Y=yi|x) 的概率也就显而意见了,无非是联合概率 P(yi,x)/P(x) ,而某个i状态的联合概率,很容易求解,分别从前向和后向扫描至i状态,对应的i状态的每个随机变量的联合概率就求出来了,如书上所示:
而条件概率,稍许有些麻烦,但看一张图就明白了,如下图所示:
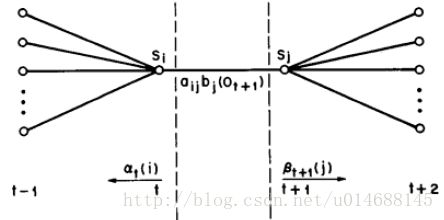
公式如下:
中间无非有一条边需要考虑下,用 Mi(yi−1,yi|x) 表示。
期望的计算
书中介绍了两种期望值的计算,分别是联合分布 P(X,Y) 和条件分本 P(Y|X) 的数学期望,对谁期望,这里是对特征函数求期望,具体的用处暂时还不明了。(为何对特征函数求期望?)
从公式理解的话,对特征函数求期望,就是对图中的每条边求期望,边的值变成了随机变量,而一条边的出现跟连接两个边的节点有关系,如对特征 fk(yi−1,yi,x,i) 第i时刻的某条边,那么能出现这种情况的条件概率为 P(yi−1,yi|x) ,所以对 P(Y|X) 的期望如下,即所有边的期望和。
内累加和表示对第i-1个状态和第i个状态的所有 yi−1,yi 的边值求期望,外累加和是对整个序列求期望,总和即为整个 P(Y|X) 关于特征函数 fk 的期望。
第二个期望利用了经验分布 P^(X) ,可以求得特征函数关于 P(Y,X) 的数学期望:
这里不明白为什么求联合分布的时候,用的是经验分布 P^(x) 而不是直接用 Z(x) 代替,难道是说 P(X,Y) 的分布是不知道的? P(x) 的分布是不知道的?
参数学习算法
参数模型算法与最大熵模型算法的理论推导没有什么区别,就是对训练的对数似然函数
求极大的过程,具体的算法思想可以参看博客【 最大熵模型与GIS ,IIS算法】。
预测算法
维特比算法采用了经典的动态规划思想,该算法和HMM又是完全一致的,所以也不需要重新再推导一遍,可直接参看博文【隐马尔可夫学习笔记(一)】的维特比算法。但这里重新回顾一遍的同时,有了一些新的感悟,为什么需要使用维特比算法,而不是像最大熵模型那样,直接代入输入向量x即可。简单来说,是因为在整个图中,每个节点都是相互依赖,所以单纯的代入 P(Y|X) 是行不通的,你没法知道,到底哪个标签与哪个标签是可以联系在一块,所以必须把这个问题给【平铺】开来,即计算每一种可能的组合,但一旦平铺你会发现,如果穷举,那么运行时间是 O(kT) ,k为标签数,T为对应的序列状态数。算法的开销相当大,而采用动态规划的一个好处在于,我们利用空间换时间,在某些中间节点直接记录最优值,以便前向扫描的过程中,直接使用,那么自然地运行时间就下去了。
Code Time
分析并实现CRF源码,是一项大工程,所以这篇博文暂且不去实现了,后续会专门开几篇文章来介绍相关的迭代算法,条件随机场涉及的迭代算法有【IIS算法】、【拟牛顿法】、【BFGS算法】,下回分析。
参考文献
- 李航. 统计学习方法[M]. 北京:清华大学出版社,2012
- 如何用简单易懂的例子解释条件随机场(CRF)模型?它和HMM有什么区别?
- Sutton, Charles, and Andrew McCallum. “An introduction to conditional random fields.” Machine Learning 4.4 (2011): 267-373.
- 隐马尔可夫学习笔记(一)
- 随机场(Random field)
- 隐马尔可夫学习笔记(一)
- 隐马尔可夫模型之Baum-Welch算法详解
- 最大熵模型与GIS ,IIS算法