怕自己忘系列————mxnet中DataLoader和Dataset的详细解读(以《动手学深度学习》中的9.12为例)
列出的代码的顺序是代码的实际执行顺序, 不是文件中的先后顺序。
demo = True
if demo:
import zipfile
for f in ['train_tiny.zip', 'test_tiny.zip', 'trainLabels.csv.zip']:
with zipfile.ZipFile('D:\\mxnetLearn\\data\\kaggle_cifar10\\' + f, 'r') as z:
z.extractall('D:\\mxnetLearn\\data\\kaggle_cifar10\\')首先是选择是否使用demo就是说是否使用样例进行先行调参。上端代码首先将三个zip压缩包给解压了。
if demo:
train_dir, test_dir, batch_size = 'train_tiny', 'test_tiny', 5
else:
train_dir, test_dir, batch_size = 'train', 'test', 128
data_dir, label_file = 'D:\\mxnetLearn\\data\\kaggle_cifar10\\', 'trainLabels.csv'
input_dir, valid_ratio = 'train_valid_test', 0.1
将训练文件和测试文件以及batchsize初始化。这里,input_dir就是所有的train中的数据,valid_ratio是验证率,应该也可以理解为每十个就拿出一个作为验证。label_file里面是一个用逗号分割为两列的文件,第一列是图片的编号也就是他的名字,第二列是对应的标签。
reorg_cifar10_data
该函数是在进行原始数据集的处理,目的就是整理出一个以文件夹为分类存放的结构如下图所示,可能是一个现在做分类任务的通用手法,为了迎合后来的Dataset类的处理方式。

接下来,详细说一下reorg_cifar10_data()函数的内容。
def reorg_cifar10_data(data_dir, label_file, train_dir, test_dir, input_dir,
valid_ratio):
n_train_per_label, idx_label = read_label_file(data_dir, label_file,
train_dir, valid_ratio)
reorg_train_valid(data_dir, train_dir, input_dir, n_train_per_label,
idx_label)
reorg_test(data_dir, test_dir, input_dir)data_dir 是根目录,到kaggle_cifar10\\,label_file 是源文件中的那个trainLabels.csv文件,train_dir 和 test_dir 是对应的train_tiny和test_tiny input_dir是train_valid_test文件夹,valid_ratio 是验证比率。
read_label_file()
def read_label_file(data_dir, label_file, train_dir, valid_ratio):
with open(os.path.join(data_dir, label_file), 'r') as f:
lines = f.readlines()[1:]
tokens = [l.rstrip().split(',') for l in lines]
# rstrip()是将字符串末尾所有的空格、制表符等全部删掉
idx_label = dict(((int(idx), label) for idx, label in tokens))
labels = set(idx_label.values())
n_train_valid = len(os.listdir(os.path.join(data_dir, train_dir)))
n_train = int(n_train_valid * (1 - valid_ratio))
assert 0 < n_train < n_train_valid
return n_train // len(labels), idx_labelwith语句打开标签文件,按行读取,逗号分割前面是id后面是对应id,rstrip()是将字符串前后的空格制表符都删掉,获得的tokens就是一个包含所有训练数据的id和对应标签列表。
idx_label是形成了一个字典。
set()语句是为了去重得到一个集合,这个集合就是所有的类别,n_train_valid是训练+验证数据,n_train是训练数据,按比率从训练数据中抽出训练数据最后返回了两个对象,一个是训练数据数量(例如,每九个同样标签的数据就抽取一个出来作为验证数据,n_train=90,len(labels)=10),一个是id和标签对应的dict。
assert是断言的意思,就是检查n_train的大小,以防在后续程序中崩溃或者报错。
这样就得到了n_train_per_label和idx_label,接着执行如下函数:
def reorg_train_valid(data_dir, train_dir, input_dir, n_train_per_label,
idx_label):
label_count = {}
for train_file in os.listdir(os.path.join(data_dir, train_dir)):
idx = int(train_file.split('.')[0])
label = idx_label[idx]
mkdir_if_not_exist([data_dir, input_dir, 'train_valid', label])
shutil.copy(os.path.join(data_dir, train_dir, train_file),
os.path.join(data_dir, input_dir, 'train_valid', label))
if label not in label_count or label_count[label] < n_train_per_label:
mkdir_if_not_exist([data_dir, input_dir, 'train', label])
shutil.copy(os.path.join(data_dir, train_dir, train_file),
os.path.join(data_dir, input_dir, 'train', label))
label_count[label] = label_count.get(label, 0) + 1
else:
mkdir_if_not_exist([data_dir, input_dir, 'valid', label])
shutil.copy(os.path.join(data_dir, train_dir, train_file),
os.path.join(data_dir, input_dir, 'valid', label))该函数目的为:整理原始训练数据为三个部分,train_valid,train和valid,在三个文件夹中分别按图像标签类别建立了十个文件夹,每个文件夹中存放的是该类别的图片。
整体函数的逻辑是,首先从原始训练数据中读出图片,首先按照类别存到train_valid中,然后在if语句中,判断当前的图片是不是已经在label_count中出现过或者该类别的图片是不是已经达到了9个,要是出现过而且达到了九个就需要把当前这个放在valid文件夹中。
idx是通过获取文件名然后切割获得的,label是通过在那个idx_label字典里面找的。
shutil.copy()是用来复制文件的,将第一参数所指文件复制到第二参数所指文件中。
此函数执行完后就会建立起可以用来做预测的数据文件夹结构了。下面这个函数是建立文件夹用的。
def mkdir_if_not_exist(path):
if not os.path.exists(os.path.join(*path)): # *可以理解为 存放一个或多个值的list
os.makedirs(os.path.join(*path))接下来会执行到建立测试文件夹,原理和上面的一样。
def reorg_test(data_dir, test_dir, input_dir):
mkdir_if_not_exist([data_dir, input_dir, 'test', 'unknown'])
for test_file in os.listdir(os.path.join(data_dir, test_dir)):
shutil.copy(os.path.join(data_dir, test_dir, test_file),
os.path.join(data_dir, input_dir, 'test', 'unknown'))整理原始数据的步骤就到此结束了,接下来就是构造Dataset和DataLoader了,这里是难点。
transform_train = gdata.vision.transforms.Compose([
gdata.vision.transforms.Resize(40),
gdata.vision.transforms.RandomResizedCrop(32, scale=(0.64, 1.0),
ratio=(1.0, 1.0)),
gdata.vision.transforms.RandomFlipLeftRight(),
gdata.vision.transforms.ToTensor(),
gdata.vision.transforms.Normalize([0.4914, 0.4822, 0.4456],
[0.2032, 0.1994, 0.2010])])上面这段代码是在对图片进行微调,这里是在定义一个处理方法的组合方法,注意其中的 gdata.vision.transforms.ToTensor(),在该语句之后,图片就变成了我们要的NDarray形式了。后面的Normalize()是在进行标准化,两个list对应均值和方差,均值越大图片越亮,方差越大对比度越大,每个list三个值代表的是RGB三通道值。训练数据转换完就是到了测试数据了。
transform_test = gdata.vision.transforms.Compose([
gdata.vision.transforms.ToTensor(),
gdata.vision.transforms.Normalize([0.4914, 0.4822, 0.4456],
[0.2032, 0.1994, 0.2010])])测试数据的处理只是进行了转换ToTensor和标准化,没有进行图片增强。下面执行到了数据集的构建。
train_ds = gdata.vision.ImageFolderDataset(
os.path.join(data_dir, input_dir, 'train'), flag=1)该模型用的是ImageFolderDataset,可以理解为构建具有文件夹结构的数据集,后续我自己的项目需要构建出一个非文件夹结构的,而且我的数据要比这个复杂,因此在此仔细分析一下该模型,然后构建自己的模型。下面仔细记录下ImageFolderDataset的执行过程。
通过Ctrl+b 进入到该函数中,首先翻译下他的注释。
用于加载存储在文件夹结构中的图像文件的数据集,like.....
flag:用来区别灰度图和RGB图的。
transform:一个获取数据和标签并转换它们的函数
attributes:属性
synsets:类别名列表
items:元组对象(路径,标签)
class ImageFolderDataset(dataset.Dataset):
"""A dataset for loading image files stored in a folder structure.
like::
root/car/0001.jpg
root/car/xxxa.jpg
root/car/yyyb.jpg
root/bus/123.jpg
root/bus/023.jpg
root/bus/wwww.jpg
Parameters
----------
root : str
Path to root directory.
flag : {0, 1}, default 1
If 0, always convert loaded images to greyscale (1 channel).
If 1, always convert loaded images to colored (3 channels).
transform : callable, default None
A function that takes data and label and transforms them::
transform = lambda data, label: (data.astype(np.float32)/255, label)
Attributes
----------
synsets : list
List of class names. `synsets[i]` is the name for the integer label `i`
items : list of tuples
List of all images in (filename, label) pairs.
"""
def __init__(self, root, flag=1, transform=None):
self._root = os.path.expanduser(root)
self._flag = flag
self._transform = transform
self._exts = ['.jpg', '.jpeg', '.png']
self._list_images(self._root)
def _list_images(self, root):
self.synsets = []
self.items = []
for folder in sorted(os.listdir(root)):
path = os.path.join(root, folder)
if not os.path.isdir(path):
warnings.warn('Ignoring %s, which is not a directory.'%path, stacklevel=3)
continue
label = len(self.synsets)
self.synsets.append(folder)
for filename in sorted(os.listdir(path)):
filename = os.path.join(path, filename)
ext = os.path.splitext(filename)[1]
if ext.lower() not in self._exts:
warnings.warn('Ignoring %s of type %s. Only support %s'%(
filename, ext, ', '.join(self._exts)))
continue
self.items.append((filename, label))
def __getitem__(self, idx):
img = image.imread(self.items[idx][0], self._flag)
label = self.items[idx][1]
if self._transform is not None:
return self._transform(img, label)
return img, label
def __len__(self):
return len(self.items)
接下来仔细解析该函数:
def __init__(self, root, flag=1, transform=None):
self._root = os.path.expanduser(root) 获得根目录
self._flag = flag 初始化图片类型
self._transform = transform 图片格式转换函数初始化
self._exts = ['.jpg', '.jpeg', '.png'] 列出支持的图片格式
self._list_images(self._root) 列出所有的图片和其对应的标签
def _list_images(self, root):
self.synsets = [] 存储标签,这个变量会一直存在等到最后根据下标找出标签名称,在程序中
self.items = [] 始终以0-9这样的int数据类型代表标签,即synsets中的下标。
for folder in sorted(os.listdir(root)): 为了保证最终的synsets的正确性,需要将root中的不同标签类别文件夹进行排序
path = os.path.join(root, folder)
if not os.path.isdir(path):
warnings.warn('Ignoring %s, which is not a directory.'%path, stacklevel=3)
continue
label = len(self.synsets) 将长度作为了标签的int代号,例如有一个就是1,两个就是2分别代表airplane等等
self.synsets.append(folder)
for filename in sorted(os.listdir(path)):
filename = os.path.join(path, filename)
ext = os.path.splitext(filename)[1] 验证文件的扩展名是否符合要求,ext代表扩展名
if ext.lower() not in self._exts:
warnings.warn('Ignoring %s of type %s. Only support %s'%(
filename, ext, ', '.join(self._exts)))
continue
self.items.append((filename, label)) 最终在items里面存了(路径,标签id)这样一个元组列表
关于splitext()用法进行了查阅,如下: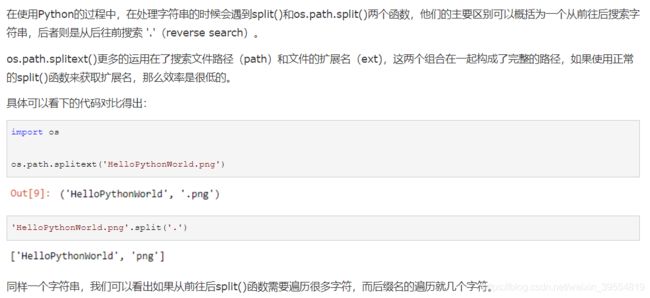
lower()函数就是用来将字符串转换成小写:返回所有ASCII字符转换为小写形式的副本。
def __getitem__(self, idx):
img = image.imread(self.items[idx][0], self._flag)
label = self.items[idx][1]
if self._transform is not None:
return self._transform(img, label)
return img, label
def __len__(self):
return len(self.items)
上面两个函数是在实现序列的协议,也就是说这个类(ImageFolderDataset)被实例化后将是一个可以被访问的序列,每次调用只要传入idx都会返回一个tuple(img,label),很像list的用法,给出下标,返回对应的值。只是这样一来可以避免了将全部图片都加载进来,而是要哪个就加载哪个,省去了内存的消耗。
到这里,Dataset就处理完了,接下来就是使用dataset的DataLoader。
代码篇幅太长,分段看:
先看他的注释部分
shuffle:是否随机打乱顺序
sampler:要使用的采样器。要么指定采样器,要么指定随机洗牌,而不是两者都指定。其实我们不用在执行过程中还是会用默认的 采样器,是一个一个采样,然后在使用Batch_sampler进行批量采样,最后输出。
last_batch:如果batch_size没有被均匀分割,如何处理最后一批len(数据集)。
保存-返回比前一批少的样品。
丢弃——如果最后一批不完整,则丢弃。
滚动-其余的样本被滚动到下一个纪元。
一般都会用keep
batch_sampler:一个批量采样,就是告诉你他和batch_size等参数不能同时指定。一般不会用这个。
batchify_fn:回调函数,允许用户指定如何合并样本进一批。默认为“default_batchify_fn”,一般就是用默认的。
在后面的参数就是和硬件相关的了,我没有进行深入的研究,都是用了默认的。
class DataLoader(object):
"""Loads data from a dataset and returns mini-batches of data.
Parameters
----------
dataset : Dataset
Source dataset. Note that numpy and mxnet arrays can be directly used
as a Dataset.
batch_size : int
Size of mini-batch.
shuffle : bool
Whether to shuffle the samples.
sampler : Sampler
The sampler to use. Either specify sampler or shuffle, not both.
last_batch : {'keep', 'discard', 'rollover'}
How to handle the last batch if batch_size does not evenly divide
`len(dataset)`.
keep - A batch with less samples than previous batches is returned.
discard - The last batch is discarded if its incomplete.
rollover - The remaining samples are rolled over to the next epoch.
batch_sampler : Sampler
A sampler that returns mini-batches. Do not specify batch_size,
shuffle, sampler, and last_batch if batch_sampler is specified.
batchify_fn : callable
Callback function to allow users to specify how to merge samples
into a batch. Defaults to `default_batchify_fn`::
def default_batchify_fn(data):
if isinstance(data[0], nd.NDArray):
return nd.stack(*data)
elif isinstance(data[0], tuple):
data = zip(*data)
return [default_batchify_fn(i) for i in data]
else:
data = np.asarray(data)
return nd.array(data, dtype=data.dtype)
num_workers : int, default 0
The number of multiprocessing workers to use for data preprocessing.
pin_memory : boolean, default False
If ``True``, the dataloader will copy NDArrays into pinned memory
before returning them. Copying from CPU pinned memory to GPU is faster
than from normal CPU memory.
pin_device_id : int, default 0
The device id to use for allocating pinned memory if pin_memory is ``True``
prefetch : int, default is `num_workers * 2`
The number of prefetching batches only works if `num_workers` > 0.
If `prefetch` > 0, it allow worker process to prefetch certain batches before
acquiring data from iterators.
Note that using large prefetching batch will provide smoother bootstrapping performance,
but will consume more shared_memory. Using smaller number may forfeit the purpose of using
multiple worker processes, try reduce `num_workers` in this case.
By default it defaults to `num_workers * 2`.
thread_pool : bool, default False
If ``True``, use threading pool instead of multiprocessing pool. Using threadpool
can avoid shared memory usage. If `DataLoader` is more IO bounded or GIL is not a killing
problem, threadpool version may achieve better performance than multiprocessing.
"""接下来,看DataLoader的实现部分:
初始化部分:__init__()
我们先看一下我们传入了哪些参数
train_iter = gdata.DataLoader(train_ds.transform_first(transform_train),
batch_size, shuffle=True, last_batch='keep')我们将数据集dataset,batch_size,shuffle, last_batch 传了进去。
def __init__(self, dataset, batch_size=None, shuffle=False, sampler=None,
last_batch=None, batch_sampler=None, batchify_fn=None,
num_workers=0, pin_memory=False, pin_device_id=0,
prefetch=None, thread_pool=False):
self._dataset = dataset 初始化dataset
self._pin_memory = pin_memory 我们均采取了默认
self._pin_device_id = pin_device_id
self._thread_pool = thread_pool
if batch_sampler is None: 我们的参数是None,进入if语句
if batch_size is None: 我们的batch_size给了
raise ValueError("batch_size must be specified unless " \
"batch_sampler is specified")
if sampler is None: 我们没给sampler
if shuffle: 选择了 shuffle
sampler = _sampler.RandomSampler(len(dataset)) 进入到了随机化类,得到一个采样器sampler,该类具体详解在
else: 下方
sampler = _sampler.SequentialSampler(len(dataset))
elif shuffle:
raise ValueError("shuffle must not be specified if sampler is specified")
batch_sampler = _sampler.BatchSampler( 上面代码已经给构造出一个能够单个返回的随机采样
sampler, batch_size, last_batch if last_batch else 'keep') 器,这里把这个采样器再装饰成一个批量采样器,详
elif batch_size is not None or shuffle or sampler is not None or \ 细代码在下方。
last_batch is not None:
raise ValueError("batch_size, shuffle, sampler and last_batch must " \
"not be specified if batch_sampler is specified.")
self._batch_sampler = batch_sampler //初始化了批量采样器
self._num_workers = num_workers if num_workers >= 0 else 0
self._worker_pool = None
self._prefetch = max(0, int(prefetch) if prefetch is not None else 2 * self._num_workers)
if self._num_workers > 0: //我们默认是0
if self._thread_pool:
self._worker_pool = ThreadPool(self._num_workers)
else:
self._worker_pool = multiprocessing.Pool(
self._num_workers, initializer=_worker_initializer, initargs=[self._dataset])
if batchify_fn is None: //我们是None
if num_workers > 0:
self._batchify_fn = default_mp_batchify_fn
else: //我们没有指定合并函数,所以在这里采用了默认的
self._batchify_fn = default_batchify_fn //该函数详细执行过程在下方
else:
self._batchify_fn = batchify_fn
RandomSampler()如下:
从[0,长度]中随机采样元素,不进行替换。
其实就是把一个长度为n的序列进行了打乱,每次访问他的时候他都给你返回一个随机的x∈[0,n)
class RandomSampler(Sampler):
"""Samples elements from [0, length) randomly without replacement.
Parameters
----------
length : int
Length of the sequence.
"""
def __init__(self, length):
self._length = length
def __iter__(self):
indices = np.arange(self._length)
np.random.shuffle(indices)
return iter(indices)
def __len__(self):
return self._lengthBatchSampler()如下:包装上另一个“采样器”,返回小批量的样品。
可以看到我们的 last_batch 在这里起作用了。
该类实现了__iter__()方法,所以他是个迭代器。
class BatchSampler(Sampler):
"""Wraps over another `Sampler` and return mini-batches of samples.
Parameters
----------
sampler : Sampler
The source Sampler.
batch_size : int
Size of mini-batch.
last_batch : {'keep', 'discard', 'rollover'}
Specifies how the last batch is handled if batch_size does not evenly
divide sequence length.
If 'keep', the last batch will be returned directly, but will contain
less element than `batch_size` requires.
If 'discard', the last batch will be discarded.
If 'rollover', the remaining elements will be rolled over to the next
iteration.
Examples
--------
>>> sampler = gluon.data.SequentialSampler(10)
>>> batch_sampler = gluon.data.BatchSampler(sampler, 3, 'keep')
>>> list(batch_sampler)
[[0, 1, 2], [3, 4, 5], [6, 7, 8], [9]]
"""
def __init__(self, sampler, batch_size, last_batch='keep'):
self._sampler = sampler
self._batch_size = batch_size
self._last_batch = last_batch
self._prev = []
def __iter__(self):
batch, self._prev = self._prev, []
for i in self._sampler:
batch.append(i)
if len(batch) == self._batch_size:
yield batch
batch = []
if batch:
if self._last_batch == 'keep':
yield batch
elif self._last_batch == 'discard':
return
elif self._last_batch == 'rollover':
self._prev = batch
else:
raise ValueError(
"last_batch must be one of 'keep', 'discard', or 'rollover', " \
"but got %s"%self._last_batch)
def __len__(self):
if self._last_batch == 'keep':
return (len(self._sampler) + self._batch_size - 1) // self._batch_size
if self._last_batch == 'discard':
return len(self._sampler) // self._batch_size
if self._last_batch == 'rollover':
return (len(self._prev) + len(self._sampler)) // self._batch_size
raise ValueError(
"last_batch must be one of 'keep', 'discard', or 'rollover', " \
"but got %s"%self._last_batch)这里我们单独把__iter__()实现过程拿出来分析一下
def __iter__(self):
batch, self._prev = self._prev, [] // 初始化了batch,是个记录内容的计数器,到了我们规定的batch_size他就清零了
for i in self._sampler: //开始迭代我们一开始定义的那个单个采样器 sampler
batch.append(i) // 迭代完一个就存一个
if len(batch) == self._batch_size: //一个批量的数量够了,就清零。
yield batch // yield 迭代器的标志,等待外部程序获取 batch 获取后才会继续他的下一轮循环
batch = [] //清空batch,为下一轮迭代做准备
if batch: //如果for循环结束了,但是batch里面还有东西,那就要看我们想如何处理不满一个
if self._last_batch == 'keep': //batch的数据了,然后给出了三种方法
yield batch
elif self._last_batch == 'discard':
return
elif self._last_batch == 'rollover':
self._prev = batch
else:
raise ValueError(
"last_batch must be one of 'keep', 'discard', or 'rollover', " \
"but got %s"%self._last_batch)
__len__()就比较简单了,就是返回批量迭代器的迭代数量,比如100个原始数据,batch_size我们用10,那么他的长度就是100/10=10
要是没整除,比如我们是105个数据,batch_size是10,last_batch 使用keep,那么长度就是105+10-1 // 10 = 11 思想就是不管最后有没有不够一个batch_size的数据,都给他加上一个不足一个batch_size的数,然后除以batch_size取整,这样就可以得到准确的batch个数。
在这里截了个图

可以看到,我的batch_size设置的是5,他在随机取了5个数据样本的id后就开始yield了,等待后续的default_batchify_fn()调用它
并整理真正的数据和标签。在下面函数执行之前,在DataLoader中一直没有触碰真实的图像数据,都是在和数据集中的下标打交道
default_batchify_fn() 方法如下:
将数据整理成批
def default_batchify_fn(data):
"""Collate data into batch."""
if isinstance(data[0], nd.NDArray):
return nd.stack(*data)
elif isinstance(data[0], tuple):
data = zip(*data)
return [default_batchify_fn(i) for i in data]
else:
data = np.asarray(data)
return nd.array(data, dtype=data.dtype)这里我们传给函数的数据类型是一个tuple,第一位置是个图像数据,第二个位置是他的标签。
这里需要详细记录的是zip()函数,这个函数有两个功能,压缩zip()和解压zip(*zipped),因为这个我困惑了好久才看懂上面的代码,当传入zip()是两个list的时候他会给你按照每个列表的元素顺序成对打包,当你给了一个元组列表时,那么他就给你解压了,但是输入变量必须加*,解压成两个元组,为了搞清楚我写了个能说明他用法的几行代码如下以及结果:
lst_1 = [1,2,3]
lst_2 = ['a','b','c']
lst = zip(lst_1,lst_2)
print('lst1',lst_1,'\n','lst2',lst_2)
for i in lst:
print('压缩lst1,lst2:',i)
data = [(1,'a'),(2,'b'),(3,'c')]
print('data:',data)
data_zip = zip(*data)
for i in data_zip:
print('解压*data:',i)
data_no_zip = zip(data)
for i in data_no_zip:
print('不解压data',i)
这样我们就可以解开default_batchify_fn() 中神秘的面纱了,其实这里他进行了一个解压过程,而不是压缩过程,他将我们的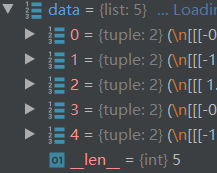 这样一个传入的data(一个包含五个元素的列表,每个元素是一个tuple(img,label)),经过第二条条件语句,变成了这样的
这样一个传入的data(一个包含五个元素的列表,每个元素是一个tuple(img,label)),经过第二条条件语句,变成了这样的 和这样的
和这样的 ,也就是我们在上一个小例子中看到的,解压成两个元组,一个元组包含了五个NDarray,一个元组包含了五个int类型的label,在这里需要着重注意一下stack()函数的使用,然后呢,还有个要注意的地方:return [default_batchify_fn(i) for i in data]中的这两个元组被迭代进了default_batchify_fn()函数,分别执行了第一个条件语句和最后一个,也就是if对应的那个语句和else对应的那个,目的是啥呢目的就是把两个tuple转换成我们想要的list类型,哇,default_batchify_fn()函数的逻辑和其中的函数困扰了我好久啊,终于弄明白了。。。。
,也就是我们在上一个小例子中看到的,解压成两个元组,一个元组包含了五个NDarray,一个元组包含了五个int类型的label,在这里需要着重注意一下stack()函数的使用,然后呢,还有个要注意的地方:return [default_batchify_fn(i) for i in data]中的这两个元组被迭代进了default_batchify_fn()函数,分别执行了第一个条件语句和最后一个,也就是if对应的那个语句和else对应的那个,目的是啥呢目的就是把两个tuple转换成我们想要的list类型,哇,default_batchify_fn()函数的逻辑和其中的函数困扰了我好久啊,终于弄明白了。。。。
stack()函数的功能:沿新轴联接数组序列。当我们在stack之前,进行print(*data),发现将五元组中的每个NDarray解开了,但是我们网络模型需要的是(5,3,32,32)的数组而不是5个分散的(3,32,32),因此使用了stack()进行连接
即:将
的
 变成了
变成了
接下来就是DataLoader的剩余实现部分:
def __iter__(self):
if self._num_workers == 0:
def same_process_iter():
for batch in self._batch_sampler:
ret = self._batchify_fn([self._dataset[idx] for idx in batch])
if self._pin_memory:
ret = _as_in_context(ret, context.cpu_pinned(self._pin_device_id))
yield ret
return same_process_iter()
# multi-worker
return _MultiWorkerIter(self._worker_pool, self._batchify_fn, self._batch_sampler,
pin_memory=self._pin_memory, pin_device_id=self._pin_device_id,
worker_fn=_thread_worker_fn if self._thread_pool else _worker_fn,
prefetch=self._prefetch,
dataset=self._dataset if self._thread_pool else None,
data_loader=self)
def __len__(self):
return len(self._batch_sampler)
def __del__(self):
if self._worker_pool:
# manually terminate due to a bug that pool is not automatically terminated
# https://bugs.python.org/issue34172
assert isinstance(self._worker_pool, multiprocessing.pool.Pool)
self._worker_pool.terminate()可以看到上面那些函数弄懂了,这些就迎刃而解了,首先是我们的num_workers为零,直接进入第一个条件语句,通过batch_sampler获得了一个包含五个id值的list,然后在通过调用self._dataset[idx]得到一个包含五个tuple(img,label)的list,进一步传给batchify_fn(),得到了我们要的ret : [img_lst,label_lst]如下图,。
最后形成了两个list,一个是图片数据,一个是label,然后就直接被拿出来放进神经网络里面了
这就是Dataset和DataLoader到生成train_iter的全部执行过程。
虽然自己研究这些代码研究了三天,但是觉得很值得,和这些写框架的大牛学了好多代码逻辑和思想,收获很大。
感觉读大牛的代码就像读书一样,虽然不能面对面交流,但是我们可以在不同的时空不同的地点进行精神的交流、请教和学习。
路漫漫其修远兮,吾将上下而求索......