
编译有五大步骤,本篇笔记将继续讲解编译的第一步:词法分析。内容主要涉及:1. 正规式、正规文法、有限自动机三者的转换;2. 确定有限自动机的化简
1. 正规式和正规文法的等价性
① 为何等价?
正规文法(四元式)定义了某种正规语言,正规式表示了某个正规集,它也定义了某种正规语言,因此可以说正规式和正规文法是等价的。即:
对于任意一个正规文法,存在一个定义同一语言的正规式;对任意一个正规式,存在一个生成同一语言的正规文法。
② 正规式转换为正规文法
将正规式 r 转换为正规文法 G,核心是将正规式拆分为正规文法的多个产生式,这是一个由一到多的过程。正规文法最终必须有一个开始符号,于是我们选定 S 作为开始符号,令 S → r,然后逐步对 r 进行拆分,生成多个产生式。
拆分规则如下:
-
A → xy可拆分为A → xB,B → y -
A → x*y可拆分为A → xA,A → y -
A → x|y可拆分为A → x,A → y
对于规则二,实际我们知道 x*y 是形如 xxxxxxy 的,所以需要进行循环替换,必须有 A → xA;符号串最后有个 y,所以必须有 A → y。
以 R = a(a|d)* 这个正规式为例,将其转换为正规文法的过程如下:
S → R → a(a|d)*
S → aA,A → (a|d)*
S → aA,A → (a|d)*ε
S → aA,A → (a|d)A,A → ε
S → aA,A → aA,A → dA,A → ε
所以,正规文法中的 P = {S → aA,A → aA,A → dA,A → ε},Vn = {S,A},Vt = {a,d,ε}。正规文法为 G = {Vn,Vt,P,S}
以 R = (ab|a)* 这个正规式为例,它的正规文法是什么呢?可能会有下面这种写法:
S → R → (ab|a)* → (ab|a)*ε
S → (ab|a)S,S → ε
S → AS,A → (ab|a),S → ε
S → AS,A → ab,A → a,S → ε
S → AS,A → aB,B → b,A → a,S → ε
这种写法是错误的,因为它没有严格按照规则进行转化。问题出在从 S → (ab|a)S 到 S → AS,A → (ab|a) 这一步,规则其实是:A → xy 可拆分为 A → xB,B → y ,右部第一个正规式必须保留,不能被替换,被替换的应该是第二个正规式。
正确写法如下:
S → R → (ab|a)* → (ab|a)*ε
S → (ab|a)S,S → ε
S → abS,S → aS,S → ε
S → aA,A → bS,S → aS,S → ε
③ 正规文法转换为正规式
将正规文法 G 转换为正规式 r,核心是将正规文法的多个产生式合并为一个正规式,这是一个由多到一的过程。
合并的规则如下:
-
A → xB,B → y可合并为A → xy -
A → xA,A → y可合并为A → x*y -
A → x,A → y可合并为A → x|y
以下面这个正规文法为例:
S → aA
S → a
A → aA
A → dA
A → a
A → d
- 先观察,将相似的进行两两合并,所以有
S = aA|a,A = aA|dA,A = a|d。 - 后两个都是
A,所以合并,有:A = (aA|dA)|(a|d) = (a|d)A(a|d) = (a|d)*(a|d) - 将
A代入S = aA|a,有:S = aA|a = a((a|d)*(a|d))|a = a(a|d)+|a = a(a|d)+|aε = a((a|d)+|ε) = a(a|d)*
所以,有:S = a(a|d)*。需要注意中间推导过程中的 (a|d)+|ε,实际上可以看作是正则闭包与空符号串的并集,所以替换为一个闭包。
2. 正规式和有限自动机的等价性
正规式表示了某种语言,有限自动机也表示了某种语言,这两者也具有等价性:
- 对于有限自动机
M,可以构造一个正规式R,使得L(R) = L(M)。 - 每个正规式
R,可以构造一个有限自动机M,使得L(M) = L(R)。
① 有限自动机转化为正规式
有限自动机转化为正规式,核心是构造一个开始状态 X 和一个终止状态 Y,之后不断简化与合并状态转化的过程,使得从 X 到 Y 只需要经过一步。
合并规则如下:
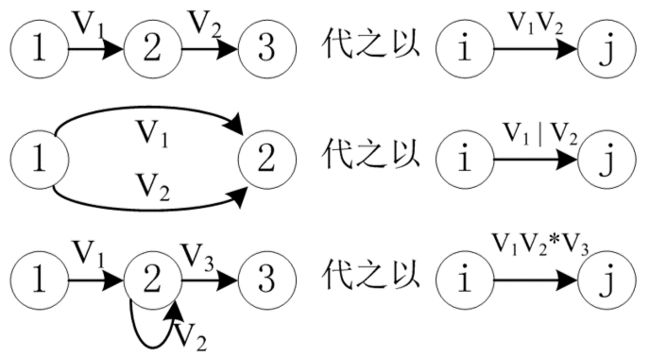
以下面这个有限自动机为例:
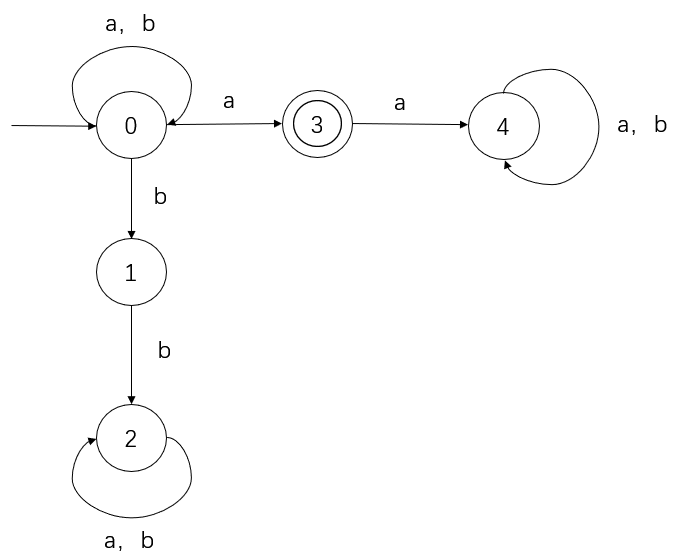
首先构造开始符号 X 和终结符号 Y,并与原有限自动机的开始符号和终结符号进行连接:
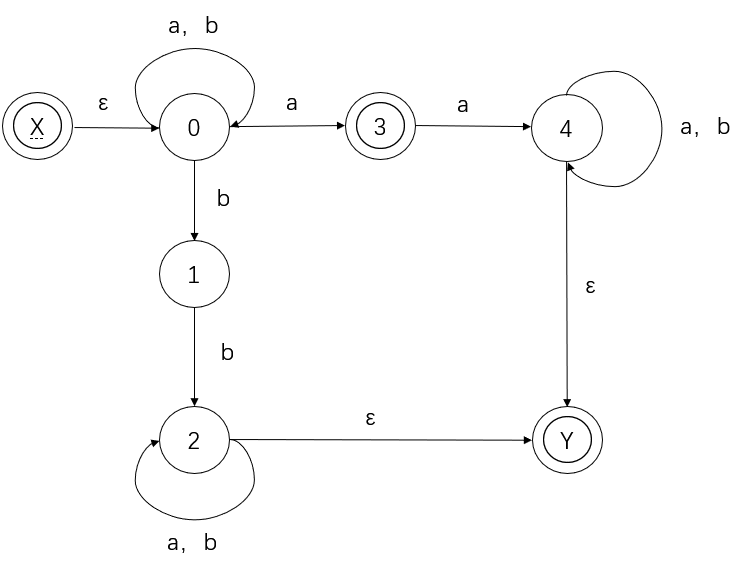
按照规则逐步进行合并:
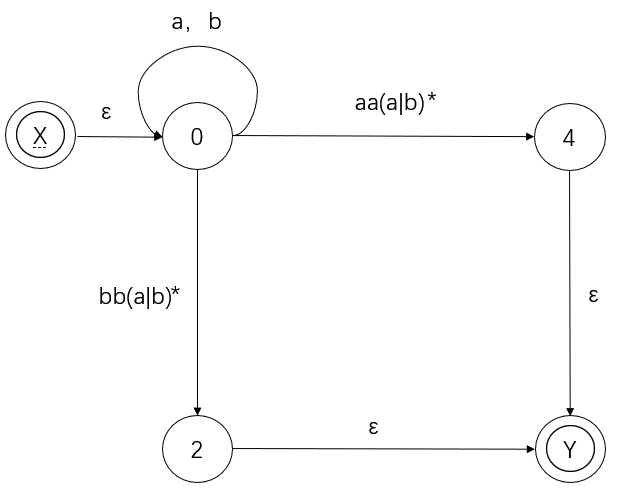
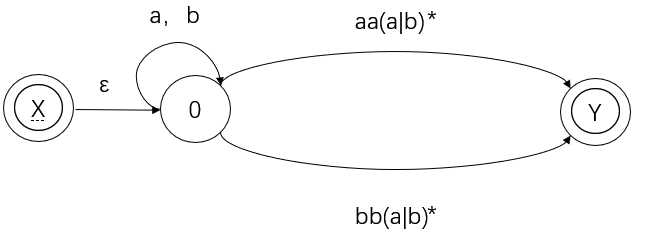
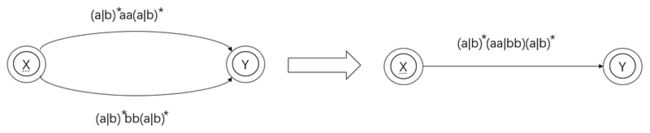
当 X 到 Y 一步到位的时候,说明转换已经完成。最终我们得到的正规式即:
L(R) = (a|b)*(aa|bb)(a|b)*
注意:这里的转化务必严格按照规则进行,虽然 0 自转和 aa(a|b)* 先合并,最后得到的正规式也是一样的,但这并不是基于基本规则进行的合并,因此必须先合并 aa(a|b)* 和 ε(这是基于基本规则进行的合并)。
② 正规式转化为有限自动机
这个过程实际上是有限自动机转化为正规式的逆过程,核心就是不断对正规式进行拆分,直到不可以再继续拆分为止。
基本的转换规则如下:
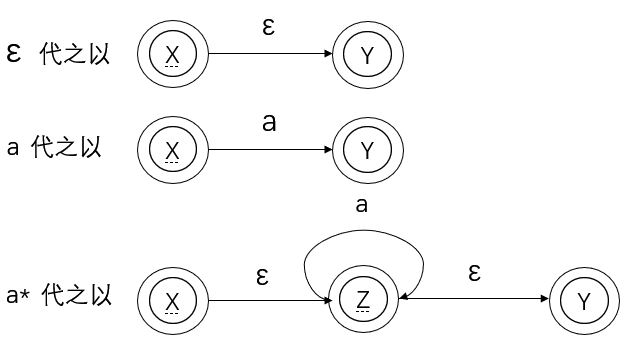
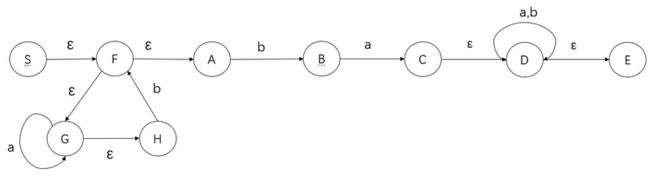
下面以正规式 R = (a*b)*ba(a|b)* 为例,将其转化为等价的有限自动机:
首先拆解为四个部分:(a*b)*,b,a,(a|b)*,以 S 作为开始符号。

将两个闭包进行拆解:
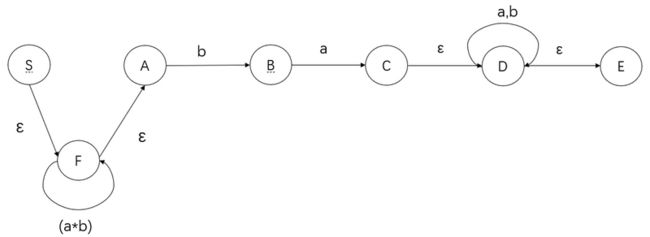
将最后一个笛卡尔积和闭包进行拆解,得到最终的有限自动机如下:
3. 确定有限自动机的化简
在上一篇笔记中,将非确定有限自动机 NFA 确定化之后,得到了确定有限自动机 DFA,接下来考虑 DFA 的化简。DFA 的化简指的是找到这么一个 DFA,它的状态数比原 DFA 更少,但是整体与原 DFA 是等价的。
第一步:删除无用状态
无用状态指的是从初态出发,不管输入的是什么符号都无法到达的那个状态,这个状态没有意义,直接删除即可。
第二步:合并等价状态
如果两个状态,不管输入的是什么符号,到达的状态的集合都是当前已划分的状态集合的子集,那么这两个状态就是等价的,既然是等价的,就可以进行合并;与之相反,则称两个状态可区别,两个可区别的状态,化简到最后还是分开的,不会进行合并。
用一个例子来说明:
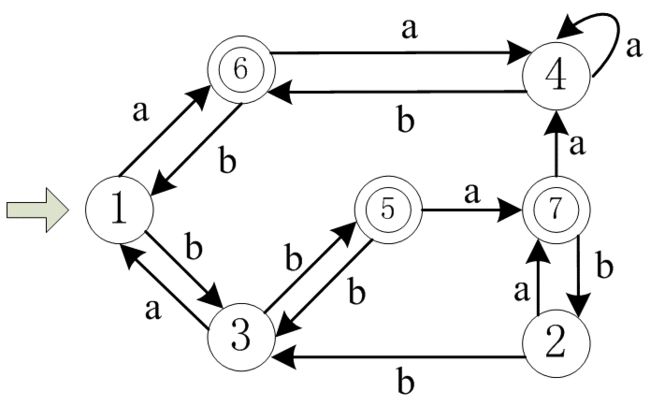
将这个 DFA 进行化简的步骤是这样的:
① 划分非终态集和终态集:
根据非终态和终态,划分出了两个集合:{1,2,3,4} 和 {5,6,7}。此时,当前已划分的状态集合就是这两个集合。
② 从 a 和 b 分别考察终态集:
{5,6,7}的各个状态经过输入 a 后,到达了其它状态,这些状态汇总的集合是 {4,7},该状态集合不是当前已划分的状态集合的子集,所以这里要进行划分。因为 6,7 经过输入 a 都是到达 4,但是 5 却是到达 7,所以划分为 {6,7} 和 {5}
那么 6,7 是不是就等价了,可以合并了呢?并不是,还需要看 b 弧。{6,7}的各个状态经过输入 b 后,到达了其它状态,这些状态汇总的集合是 {1,2},这个状态集合是当前已划分的状态集合 {1,2,3,4}的子集。所以 6,7不拆开,还是 {6,7}。
自此,当前已划分的状态集合为 {1,2,3,4} , {5},{6,7}。
③ 从 a 和 b 分别考察非终态集:**
{1,2,3,4} 的各个状态经过输入 a 后,到达了其它状态,这些状态汇总的集合是 {1,4,6,7},该状态集合不是当前已划分的状态集合的子集,所以这里要进行划分。因为 1,2 到达 6,7,3,4 到达 1,4,所以这里划分为 {1,2} 和 {3,4}。
自此,当前已划分的状态集合为 {1,2} ,{3,4}, {5},{6,7}。
接着看 b 弧。{1,2} 的各个状态经过输入 b 后,到达了其它状态,这些状态汇总的集合是 {3},这个状态集合是当前已划分的状态集合 {3,4} 的子集,所以这里不拆开,还是 {1,2}
{3,4} 的各个状态经过输入 b 后,到达了其它状态,这些状态汇总的集合是 {5,6},注意这个状态集合并不是当前已划分的状态集合 的子集,所以这里要进行划分。因为 3 到达 5,4 到达 6,所以拆分为 {3} 和 {4}。
④ 确定最终已划分的状态集合
经过 ab 的测试后,当前已划分的状态集合为 {1,2} ,{3},{4} ,{5},{6,7}。
⑤ 等价状态的合并
在同一个集合中的状态都是等价的,要考虑将它们进行合并。还是来看这张图:
首先,6 和 7 是等价的,考虑去掉 7 与它的各条线。7--4 线与 6--4 线等价,把 7--4 线去除;5--7 线等价于 5--6 线,将 5--7 线替换为 5--6 线;7--2 线、2--7 线有等价的 6--1 线、1--6 线(因为 1 和 2 等价),可以将 7--2 线、2--7 线去除,同时把与 1 等价的 2 也去掉。最后还剩下 2--3 线,它等价于 1--3 线,因此可以把 2--3 线去掉。
最终化简得到的 DFA 如下:
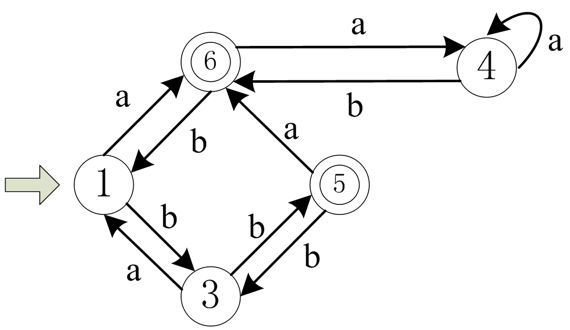
注意:
DFA 化简之后一定要进行检查,确定每一个状态集合的每一个状态经过 ab 后到达的状态的集合都是当前已划分集合的子集。比方说,在上面这个例子中,如果我们是先考察非终态集,那么最后划分得到的状态集合将是:为 {1,2} ,{3,4} ,{5},{6,7}。如果不做检查,就会按照这些集合进行最终的化简;但实际上,经过检查后会发现,{3,4} 的每一个状态经过 b 后到达的状态的集合为 {5,6},这个集合不是当前任何一个已划分集合的子集,所以 3 和 4 实际上不是等价的,不能放在一个集合中。但是为什么一开始会觉得 3 和 4 应该在一起呢?是因为我们当时先检查的是非终态集合,没有检查终态集合,终态集合在那个时候只有 {5,6,7} ,是暂时还没有划分的。