爬虫------scrapy 框架--Spider、CrawlSpider(规则爬虫)
scrapy 框架分为spider爬虫和CrawlSpider(规则爬虫)
官方文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/topics/shell.htmlScrapy()是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。不用自己去实现的异步框架
Scrapy常用命令

执行顺序
SPIDERS的yeild将request发送给ENGIN
ENGINE对request不做任何处理发送给SCHEDULER
SCHEDULER( url调度器),生成request交给ENGIN
ENGINE拿到request,通过MIDDLEWARE进行层层过滤发送给DOWNLOADER
DOWNLOADER在网上获取到response数据之后,又经过MIDDLEWARE进行层层过滤发送给ENGIN
ENGINE获取到response数据之后,返回给SPIDERS,SPIDERS的parse()方法对获取到的response数据进行处理,解析出items或者requests将解析出来的items或者requests发送给ENGIN
ENGIN获取到items或者requests,将items发送给ITEM PIPELINES,将requests发送给SCHEDULER
extract()转码并提取内容返回值为列表
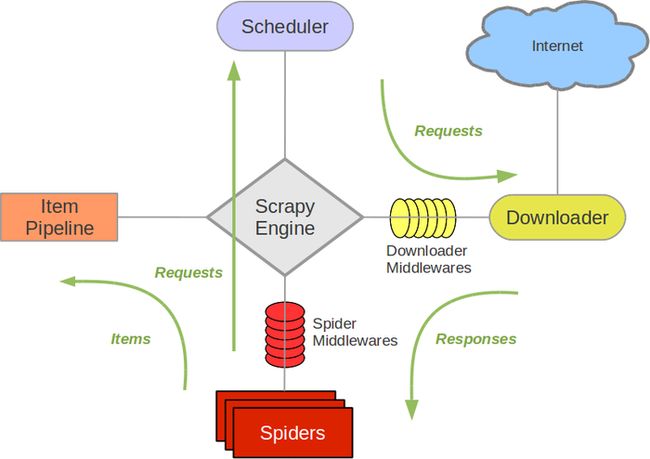
scrapy框架配置流程
1、创建一个新的Scrapy项目:scrapy startproject mySpider 。进入自定义的项目目录中 cd mySpider
2、在项目目录下输入命令,将在mySpider/spider目录下创建一个名为Atguigu的爬虫,
并指定爬取域的范围(要爬取网站的域名):scrapy genspider Atguigu "atguigu.com"
3、运行爬虫,在mySpider项目目录下执行:scrapy crawl Atguigu
4、明确目标 (编写items.py):明确你想要抓取的目标
5、制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
6、 存储内容 (pipelines.py):设计管道存储爬取内容
在pycham中打开项目在项目中创建main.py或start.py用于启动项目。
from scrapy import cmdline
cmdline.execute("scrapy crawl tencentPosition".split())scrapy框架内部执行流程(重点)
1、SPIDERS的yeild将request发送给ENGIN
2、ENGINE对request不做任何处理发送给SCHEDULER
3、SCHEDULER( url调度器),生成request交给ENGIN
4、ENGINE拿到request,通过MIDDLEWARE进行层层过滤发送给DOWNLOADER
5、DOWNLOADER在网上获取到response数据之后,又经过MIDDLEWARE进行层层过滤发送给ENGIN
6、ENGINE获取到response数据之后,返回给SPIDERS,SPIDERS的parse()方法对获取到的response数据进行处理,解析出items或者requests
7、将解析出来的items或者requests发送给ENGIN
8、ENGIN获取到items或者requests,将items发送给ITEM PIPELINES,将requests发送给SCHEDULER
在main.py中scrapy库中引入命令行cmdline函数使用execute方法
from scrapy import cmdline
#下面是执行scrapy程序的命令
#
cmdline.execute("scrapy crawl Atguigu".split())
cmdline.execute("scrapy crawl Atguigu -o atguigu.json".split())在运行时直接保存mySpider/spiders/ :存储爬虫代码目录。
在文件夹下面的py文件了写爬虫代码。在创建好的类中配start_urls请求网络。返回的数据response传给函数parse在函数中处理数据。在引入项目文件下items.py中的自创建类并在parse函数中实例化(字典类型)用yield返回实例化对象用于传递和储存数据
name = "" :这个爬虫的识别名称,必须是唯一的,在不同的爬虫必须定义不同的名字。
allow_domains = [] 是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页,不存在的URL会被忽略。
start_urls = () :爬取的URL元祖/列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成。
parse(self, response) :解析的方法,每个初始URL完成下载后将被调用,调用的时候传入从每一个URL传回的Response对象来作为唯一参数,主要作用如下:负责解析返回的网页数据(response.body),提取结构化数据(生成item)生成需要下一页的URL请求。
当有字段为空的时候用extract()取出内容为列表,用"".join( )转变为字符串防止有空列表报错报错
import scrapy,json
from letv.items import LetvItem
class LetvliveSpider(scrapy.Spider):
name = 'letvLive'
allowed_domains = ['letv.com'] #列表为空,就是任意域名都行
pages = 1
url = "http://dynamic.live.app.m.letv.com/android/dynamic.php?luamod=main&mod=live&ctl=liveHuya&act=channelList&pcode=010210000&version=7.10.1&channelId=2168&pages="+str(pages)+"&country=CN&provinceid=1&districtid=9&citylevel=1&location=%E5%8C%97%E4%BA%AC%E5%B8%82%7C%E6%9C%9D%E9%98%B3%E5%8C%BA&lang=chs®ion=CN"
start_urls = [url]
def parse(self, response):
item = LetvItem() #item用于传输数据
text =response.text
python_dict = json.loads(text,encoding="utf-8")
lists = python_dict["body"]['result']
for zhubo in lists:
nick_name = zhubo['nick']
data_link = zhubo['liveUrl']
image_link = zhubo['screenshot']
item["nick_name"] = nick_name
item["data_link"] = data_link
item["image_link"] = image_link
yield item
#请求下一页
if self.pages < 10:
self.pages += 1
self.url = "http://dynamic.live.app.m.letv.com/android/dynamic.php?luamod=main&mod=live&ctl=liveHuya&act=channelList&pcode=010210000&version=7.10.1&channelId=2168&pages=" + str(
self.pages) + "&country=CN&provinceid=1&districtid=9&citylevel=1&location=%E5%8C%97%E4%BA%AC%E5%B8%82%7C%E6%9C%9D%E9%98%B3%E5%8C%BA&lang=chs®ion=CN"
yield scrapy.Request(self.url,callback=self.parse)mySpider/items.py :项目的目标文件。里面要配置要保存数据的字段。
import scrapy
class LetvItem(scrapy.Item):
# define the fields for your item here like:
nick_name = scrapy.Field()
data_link = scrapy.Field()
image_link = scrapy.Field()
image_path = scrapy.Field()mySpider/settings.py :项目的设置文件
设置为不遵守爬虫协议

设置设置用户代理模拟浏览器
DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
"User-Agent": "MyWeiboJingXuan/4.5.9 (iPhone; iOS 11.2.5; Scale/2.00)",
}或者自己在任意写设置用户代理
USER_AGENT = "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"保存图片是要设置图片文件夹路径

设置管道文件类执行与保存数据顺序(创建新类时要添加并指定执行顺序。越小越先执行)
DoubanMongodbPipeline在process_item函数中不返回数据,级别低的将不会收到数据。
ITEM_PIPELINES = {
'letv.pipelines.MyImagePipeline': 300,
'letv.pipelines.LetvPipeline': 301,
}mySpider/pipelines.py :项目的管道文件用于数据创建新类时要在settings.py中添加类名。
保存文件
import scrapy,os,json
from scrapy.utils.project import get_project_settings
from scrapy.pipelines.images import ImagesPipeline
class LetvPipeline(object):
# 当爬虫开始工作的时候执行,只有一次
def open_spider(self, spider):
print("当爬虫执行开始的时候回调:open_spider")
def __init__(self):
# 创建保存的文件
# 这一次爬虫,写入
self.file = open("letvLive.json", "w", encoding="utf-8")
# 处理每条数据
def process_item(self, item, spider):
item_dict = dict(item)
# 第一个参数是python的字典类型
json_text = json.dumps(item_dict, ensure_ascii=False) + "\n"
# 保存数据到文件
self.file.write(json_text)
# 默认返回的
return item
# 爬虫结束的时候执行一次
def close_spider(self, spider):
print("当爬虫执行结束的时候回调:close_spider")
self.file.close()保存图片
导入 from scrapy.pipelines.images import ImagesPipeline 在ImagesPipeline类源码中找到get_media_requests函数
#保存图片的
class MyImagePipeline(ImagesPipeline):
IMAGES_STORE = get_project_settings().get("IMAGES_STORE")
print(IMAGES_STORE+"******")
def get_media_requests(self, item, info):
image_path = item["image_link"]
yield scrapy.Request(image_path)
# return [Request(x) for x in item.get(self.images_urls_field, [])]图片下载好后重命名
在ImagesPipeline类源码中找到item_completed函数 。用os模块的os.rename(old_image_name,new_imgae_name)方法
#图片重命名
def item_completed(self, results, item, info):
image_path = [x["path"] for ok, x in results if ok]
old_image_name = self.IMAGES_STORE+image_path[0]
new_imgae_name = self.IMAGES_STORE+item["nick_name"]+".jpg"
os.rename(old_image_name,new_imgae_name)
item["image_path"] = new_imgae_name
return itemCrawlSpider(规则爬虫)
通过下面的命令可以快速创建 CrawlSpider爬虫 的代码:scrapy genspider -t crawl tencentPosition2 hr.tencent.com
可以从response中获取:url = response.url
千万记住 callback 千万不能写 parse,再次强调:由于CrawlSpider使用parse方法来实现其逻辑,如果覆盖了 parse方法,crawl spider将会运行失败。
rules: 是Rule对象的集合,用于匹配目标网站并排除干扰
start_url: 用于爬取起始响应,必须要返回Item,Request中的一个。
allow:满足括号中“正则表达式”的值会被提取,如果为空,则全部匹配
deny:与这个正则表达式(或正则表达式列表)不匹配的URL一定不提取
allow_domains:会被提取的链接的domains。
deny_domains:一定不会被提取链接的domains。
link_extractor:是一个Link Extractor对象,用于定义需要提取的链接。
callback: 从link_extractor中每获取到链接时,参数所指定的值作为回调函数,该回调函数接受一个response作为其第一个参数。
注意:当编写爬虫规则时,避免使用parse作为回调函数。由于CrawlSpider使用parse方法来实现其逻辑,如果覆盖了 parse方法,crawl spider将会运行失败。 #follow=True,将会匹配所以的链接,深度匹配;ollow=False只匹配当前页的
follow:是一个布尔(boolean)值,指定了根据该规则从response提取的链接是否需要跟进。 如果callback为None,follow 默认设置为True ,否则默认为False。
process_links:指定该spider中哪个的函数将会被调用,从link_extractor中获取到链接列表时将会调用该函数。该方法主要用来过滤链接,把错误的连接修改过啦。
process_request:指定该spider中哪个的函数将会被调用, 该规则提取到每个request时都会调用该函数。 (用来过滤request)
restrict_xpaths:使用xpath表达式,和allow共同作用过滤链接。
匹配链接的规则
rules = (
#process_links可以指定处理链接的函数,把所以的匹配r'type=4'正在的链接以集合的方式传入handle_links函数(如果发送链接有不能请求的情况写handle_links函数)
Rule(LinkExtractor(allow=r'type=4'),process_links="handle_links"),
#符合r'/question/\d+/\d+.shtml这个正在表达式的链接,去请求得到数据后并且回调方法parse_item,
Rule(LinkExtractor(allow=r'/question/\d+/\d+.shtml'), callback='parse_item', follow=False),
) #allow在当前页面匹配路径,请求该路径后将请求内容返回response
#如果发送链接有不能请求的情况可以进行处理,
def handle_links(self,links):
for link in links:
#在这里进行处理,变成正确的请求地址
#网站发现有爬虫再爬网站,有可能会故意返回错误的数据
print(link.url)
return links
#某个帖子里面的数据Logging配置日志并保存
在配置文件settings.py中设置,可以通过logging 模块使用。可以修改配置文件settings.py,任意位置添加下面两行,
LOG_FILE = "TencentSpider.log"
LOG_LEVEL = "DEBUG"Scrapy提供5个logging级别Log levels
CRITICAL - 严重错误(critical) --严重程度最高
ERROR - 一般错误(regular errors)
WARNING - 警告信息(warning messages)
INFO - 一般信息(informational messages)
DEBUG - 调试信息(debugging messages)--最低程度,一般用这个级别的
logging设置说明
通过在setting.py中进行以下设置可以被用来配置logging:
1. LOG_ENABLED 默认: True,启用logging
2. LOG_ENCODING 默认: 'utf-8',logging使用的编码
3. LOG_FILE 默认: None,在当前目录里创建logging输出文件的文件名
4. LOG_LEVEL 默认: 'DEBUG',log的最低级别
5. LOG_STDOUT 默认: False 如果为 True,进程所有的标准输出(及错误)将会被重定向到log中。例如,执行 print "hello" ,其将会在Scrapy log中显示。
scrapy.cfg :项目的配置文件,不能删除
mySpider/ :项目的Python模块,将会从这里引用代码
from scrapy.utils.project import get_project_settings
获得图片的地址 IMAGES_STORE = get_project_settings().get("IMAGES_STORE")
allowed_domains包含了spider允许爬取的域名(domain)的列表,可选。

start_urls初始URL元祖/列表。当没有制定特定的URL时,spider将从该列表中开始进行爬取
start_requests(self)该方法必须返回一个可迭代对象(iterable)。该对象包含了spider用于爬取(默认实现是使用 start_urls 的url)的第一个Request。
parse(self, response)当请求url返回网页没有指定回调函数时,默认的Request对象回调函数。用来处理网页返回的response,以及生成Item或者Request对象。当spider启动爬取并且未指定start_urls时,该方法被调用。
scrapy保存信息的最简单的方法主要有七种,-o 输出指定格式的文件
命令 ('marshal', 'pickle', 'jsonlines', 'json', 'jl', 'csv', 'xml')
# json格式,默认为Unicode编码
scrapy crawl Atguigu -o atguigu.json
#
json lines格式,默认为Unicode编码
scrapy crawl Atguigu -o atguigu.jsonlines
# csv 逗号表达式,可用Excel打开
scrapy crawl Atguigu -o atguigu.csv
# xml格式
scrapy crawl Atguigu -o atguigu.xml