文章转载自:https://ververica.cn/develope...
作者:邱从贤(山智)
Apache Flink 是一个有状态的流计算框架,状态是作业算子中已经处理过的内存状态,供后续处理时使用。状态在流计算很多复杂场景中非常重要,比如:
- 保存所有历史记录,用来寻找某种记录模式
- 保存最近一分钟的所有记录,用于对每分钟的记录进行聚合统计
- 保存当前的模型参数,用于进行模型训练
有状态的流计算框架必须有很好的容错性,才能在生产环境中发挥用处。这里的容错性是指,不管是发生硬件故障,还是程序异常,最终的结果不丢也不重。
Flink 的容错性从一开始就是一个非常强大的特性,在遇到故障时,能够保证不丢不重,且对正常逻辑处理的性能影响很小。
这里面的核心就是 checkpoint 机制,Flink 使用 checkpoint 机制来进行状态保证,在 Flink 中 checkpoint 是一个定时触发的全局异步快照,并持久化到持久存储系统上(通常是分布式文件系统)。发生故障后,Flink 选择从最近的一个快照进行恢复。有用户的作业状态达到 GB 甚至 TB 级别,对这么大的作业状态做一次 checkpoint 会非常耗时,耗资源,因此我们在 Flink 1.3 中引入了增量 checkpoint 机制。
在增量 checkpoint 之前,Flink 的每个 checkpoint 都包含作业的所有状态。我们在观察到状态在 checkpoint 之间的变化并没有那么大之后,支持了增量 checkpoint。增量 checkpoint 仅包含上次 checkpoint 和本次 checkpoint 之间状态的差异(也就是“增量”)。
对于状态非常大的作业,增量 checkpoint 对性能的提升非常明显。有生产用户反馈对于 TB 级别的作业,使用增量 checkpoint 后能将 checkpoint 的整体时间从 3 分钟降到 30 秒。这些时间节省主要归功于不需要在每次 checkpoint 都将所有状态写到持久化存储系统。
如何使用
当前,仅能够在 RocksDB StateBackend 上使用增量 checkpoint 机制,Flink 依赖 RocksDB 内部的备份机制来生成 checkpoint 文件。Flink 会自动清理掉之前的 checkpoint 文件, 因此增量 checkpoint 的历史记录不会无限增长。
为了在作业中开启增量 checkpoint,建议详细阅读 Apache Flink 的 checkpoint 文档,简单的说,你可以像之前一样开启 checkpoint,然后将构造函数的第二个参数设置为 true 来启用增量 checkpoint。
Java 示例
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new RocksDBStateBackend(filebackend, true));Scala 示例
val env = StreamExecutionEnvironment.getExecutionEnvironment()
env.setStateBackend(new RocksDBStateBackend(filebackend, true))Flink 默认保留一个成功的 checkpoint,如果你需要保留多个的话,可以通过下面的配置进行设置:
state.checkpoints.num-retained原理解析
Flink 的增量 checkpoint 以 RocksDB 的 checkpoint 为基础。RocksDB 是一个 LSM 结构的 KV 数据库,把所有的修改保存在内存的可变缓存中(称为 memtable),所有对 memtable 中 key 的修改,会覆盖之前的 value,当前 memtable 满了之后,RocksDB 会将所有数据以有序的写到磁盘。当 RocksDB 将 memtable 写到磁盘后,整个文件就不再可变,称为有序字符串表(sstable)。
RocksDB 的后台压缩线程会将 sstable 进行合并,就重复的键进行合并,合并后的 sstable 包含所有的键值对,RocksDB 会删除合并前的 sstable。
在这个基础上,Flink 会记录上次 checkpoint 之后所有新生成和删除的 sstable,另外因为 sstable 是不可变的,Flink 用 sstable 来记录状态的变化。为此,Flink 调用 RocksDB 的 flush,强制将 memtable 的数据全部写到 sstable,并硬链到一个临时目录中。这个步骤是在同步阶段完成,其他剩下的部分都在异步阶段完成,不会阻塞正常的数据处理。
Flink 将所有新生成的 sstable 备份到持久化存储(比如 HDFS,S3),并在新的 checkpoint 中引用。Flink 并不备份前一个 checkpoint 中已经存在的 sstable,而是引用他们。Flink 还能够保证所有的 checkpoint 都不会引用已经删除的文件,因为 RocksDB 中文件删除是由压缩完成的,压缩后会将原来的内容合并写成一个新的 sstable。因此,Flink 增量 checkpoint 能够切断 checkpoint 历史。
为了追踪 checkpoint 间的差距,备份合并后的 sstable 是一个相对冗余的操作。但是 Flink 会增量的处理,增加的开销通常很小,并且可以保持一个更短的 checkpoint 历史,恢复时从更少的 checkpoint 进行读取文件,因此我们认为这是值得的。
举个栗子
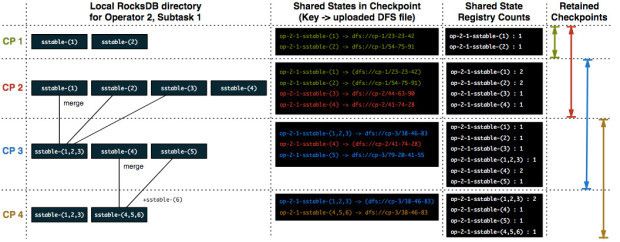
上图以一个有状态的算子为例,checkpoint 最多保留 2 个,上图从左到右分别记录每次 checkpoint 时本地的 RocksDB 状态文件,引用的持久化存储上的文件,以及当前 checkpoint 完成后文件的引用计数情况。
- Checkpoint 1 的时候,本地 RocksDB 包含两个 sstable 文件,该 checkpoint 会把这两个文件备份到持久化存储,当 checkpoint 完成后,对这两个文件的引用计数进行加 1,引用计数使用键值对的方式保存,其中键由算子的当前并发以及文件名所组成。我们同时会维护一个引用计数中键到对应文件的隐射关系。
- Checkpoint 2 的时候,RocksDB 生成两个新的 sstable 文件,并且两个旧的文件还存在。Flink 会把两个新的文件进行备份,然后引用两个旧的文件,当 checkpoint 完成时,Flink 对这 4 个文件都进行引用计数 +1 操作。
- Checkpoint 3 的时候,RocksDB 将 sstable-(1),sstable-(2) 以及 sstable-(3) 合并成 sstable-(1,2,3),并且删除了三个旧文件,新生成的文件包含了三个删除文件的所有键值对。sstable-(4) 还继续存在,生成一个新的 sstable-(5) 文件。Flink 会将 sstable-(1,2,3) 和 sstable-(5) 备份到持久化存储,然后增加 sstable-4 的引用计数。由于保存的 checkpoint 数达到上限(2 个),因此会删除 checkpoint 1,然后对 checkpoint 1 中引用的所有文件(sstable-(1) 和 sstable-(2))的引用计数进行 -1 操作。
- Checkpoint 4 的时候,RocksDB 将 sstable-(4),sstable-(5) 以及新生成的 sstable-(6) 合并成一个新的 sstable-(4,5,6)。Flink 将 sstable-(4,5,6) 备份到持久化存储,并对 sstabe-(1,2,3) 和 sstable-(4,5,6) 进行引用计数 +1 操作,然后删除 checkpoint 2,并对 checkpoint 引用的文件进行引用计数 -1 操作。这个时候 sstable-(1),sstable-(2) 以及 sstable-(3) 的引用计数变为 0,Flink 会从持久化存储删除这三个文件。
竞争问题以及并发 checkpoint
Flink 支持并发 checkpoint,有时晚触发的 checkpoint 会先完成,因此增量 checkpoint 需要选择一个正确的基准。Flink 仅会引用成功的 checkpoint 文件,从而防止引用一些被删除的文件。
从 checkpoint 恢复以及性能
开启增量 checkpoint 之后,不需要再进行其他额外的配置。如果 Job 异常,Flink 的 JobMaster 会通知所有 task 从上一个成功的 checkpoint 进行恢复,不管是全量 checkpoint 还是增量 checkpoint。每个 TaskManager 会从持久化存储下载他们需要的状态文件。
尽管增量 checkpoint 能减少大状态下的 checkpoint 时间,但是天下没有免费的午餐,我们需要在其他方面进行舍弃。增量 checkpoint 可以减少 checkpoint 的总时间,但是也可能导致恢复的时候需要更长的时间。如果集群的故障频繁,Flink 的 TaskManager 需要从多个 checkpoint 中下载需要的状态文件(这些文件中包含一些已经被删除的状态),作业恢复的整体时间可能比不使用增量 checkpoint 更长。
另外在增量 checkpoint 情况下,我们不能删除旧 checkpoint 生成的文件,因为新的 checkpoint 会继续引用它们,这可能导致需要更多的存储空间,并且恢复的时候可能消耗更多的带宽。
关于控制便捷性与性能之间平衡的策略可以参考此文档:
https://ci.apache.org/projects/flink/flink-docs-release-1.9/ops/state/large_state_tuning.html