知道什么是B树,那你知道什么是R树吗?

B树是一棵平衡树,它是把一维直线分为若干段线段,当我们查找满足某个要求的点的时候,只要去查找它所属的线段即可。依我看来,这种思想其实就是先找一个大的空间,再逐步缩小所要查找的空间,最终在一个自己设定的最小不可分空间内找出满足要求的解。
一个典型的B树查找如下:
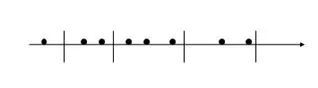
要查找某一满足条件的点,先去找到满足条件的线段,然后遍历所在线段上的点,即可找到答案。
B树是一种相对来说比较复杂的数据结构,尤其是在它的删除与插入操作过程中,因为它涉及到了叶子结点的分解与合并。由于本文第一节已经详细介绍了B树和B+树,下面直接开始介绍我们的第二个主角:R树。
简介
1984年,加州大学伯克利分校的Guttman发表了一篇题为“R-trees: a dynamic index structure for spatial searching”的论文,向世人介绍了R树这种处理高维空间存储问题的数据结构。本文便是基于这篇论文写作完成的,因此如果大家对R树非常有兴趣,我想最好还是参考一下原著:)。为表示对这位牛人的尊重,给个引用先:
Guttman, A.; “R-trees: a dynamic index structure for spatial searching,” ACM, 1984, 14
R树在数据库等领域做出的功绩是非常显著的。它很好的解决了在高维空间搜索等问题。
举个R树在现实领域中能够解决的例子:查找20英里以内所有的餐厅。如果没有R树你会怎么解决?
一般情况下我们会把餐厅的坐标(x,y)分为两个字段存放在数据库中,一个字段记录经度,另一个字段记录纬度。这样的话我们就需要遍历所有的餐厅获取其位置信息,然后计算是否满足要求。
如果一个地区有100家餐厅的话,我们就要进行100次位置计算操作了,如果应用到谷歌地图这种超大数据库中,这种方法便必定不可行了。
R树就很好的解决了这种高维空间搜索问题。它把B树的思想很好的扩展到了多维空间,采用了B树分割空间的思想,并在添加、删除操作时采用合并、分解结点的方法,保证树的平衡性。因此,R树就是一棵用来存储高维数据的平衡树。
OK,接下来,本文将详细介绍R树的数据结构以及R树的操作。至于R树的扩展与R树的性能问题,可以查阅相关论文。
R树的数据结构
如上所述,R树是B树在高维空间的扩展,是一棵平衡树。每个R树的叶子结点包含了多个指向不同数据的指针,这些数据可以是存放在硬盘中的,也可以是存在内存中。
根据R树的这种数据结构,当我们需要进行一个高维空间查询时,我们只需要遍历少数几个叶子结点所包含的指针,查看这些指针指向的数据是否满足要求即可。
这种方式使我们不必遍历所有数据即可获得答案,效率显著提高。下图1是R树的一个简单实例:
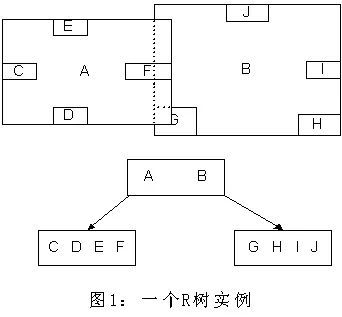
我们在上面说过,R树运用了空间分割的理念,这种理念是如何实现的呢?R树采用了一种称为MBR(Minimal Bounding Rectangle)的方法,在此我把它译作“最小边界矩形”。
从叶子结点开始用矩形(rectangle)将空间框起来,结点越往上,框住的空间就越大,以此对空间进行分割。有点不懂?没关系,继续往下看。
在这里我还想提一下,R树中的R应该代表的是Rectangle(此处参考wikipedia上关于R树的介绍),而不是大多数国内教材中所说的Region(很多书把R树称为区域树,这是有误的)。
我们就拿二维空间来举例。下图是Guttman论文中的一幅图:
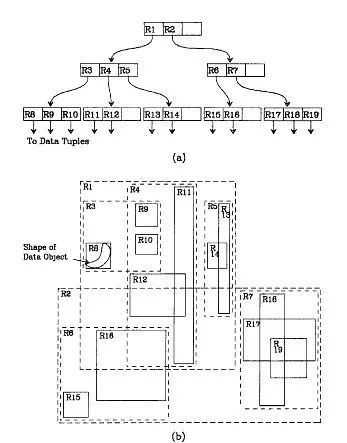
我来详细解释一下这张图。
先来看图(b)
A)首先我们假设所有数据都是二维空间下的点,图中仅仅标志了R8区域中的数据,也就是那个shape of data object。别把那一块不规则图形看成一个数据,我们把它看作是多个数据围成的一个区域。
为了实现R树结构,我们用一个最小边界矩形恰好框住这个不规则区域,这样,我们就构造出了一个区域:R8。R8的特点很明显,就是正正好好框住所有在此区域中的数据。其他实线包围住的区域,如R9,R10,R12等都是同样的道理。
这样一来,我们一共得到了12个最最基本的最小矩形。这些矩形都将被存储在子结点中。
B)下一步操作就是进行高一层次的处理。我们发现R8,R9,R10三个矩形距离最为靠近,因此就可以用一个更大的矩形R3恰好框住这3个矩形。
C)同样道理,R15,R16被R6恰好框住,R11,R12被R4恰好框住,等等。所有最基本的最小边界矩形被框入更大的矩形中之后,再次迭代,用更大的框去框住这些矩形。
我想大家都应该理解这个数据结构的特征了。用地图的例子来解释,就是所有的数据都是餐厅所对应的地点,先把相邻的餐厅划分到同一块区域,划分好所有餐厅之后,再把邻近的区域划分到更大的区域,划分完毕后再次进行更高层次的划分,直到划分到只剩下两个最大的区域为止。要查找的时候就方便了。
下面就可以把这些大大小小的矩形存入我们的R树中去了。根结点存放的是两个最大的矩形,这两个最大的矩形框住了所有的剩余的矩形,当然也就框住了所有的数据。下一层的结点存放了次大的矩形,这些矩形缩小了范围。每个叶子结点都是存放的最小的矩形,这些矩形中可能包含有n个数据。
在这里,读者先不要去纠结于如何划分数据到最小区域矩形,也不要纠结怎样用更大的矩形框住小矩形,这些都是下一节我们要讨论的。
讲完了基本的数据结构,我们来讲个实例,如何查询特定的数据。又以餐厅为例,假设我要查询广州市天河区天河城附近一公里的所有餐厅地址怎么办?
1 打开地图(也就是整个R树),先选择国内还是国外(也就是根结点)。
2 然后选择华南地区(对应第一层结点),选择广州市(对应第二层结点),
3 再选择天河区(对应第三层结点),
4 最后选择天河城所在的那个区域(对应叶子结点,存放有最小矩形),遍历所有在此区域内的结点,看是否满足我们的要求即可。
怎么样,其实R树的查找规则跟查地图很像吧?对应下图:

一棵R树满足如下的性质:
1. 除非它是根结点之外,所有叶子结点包含有m至M个记录索引(条目)。作为根结点的叶子结点所具有的记录个数可以少于m。通常,m=M/2。
2. 对于所有在叶子中存储的记录(条目),I是最小的可以在空间中完全覆盖这些记录所代表的点的矩形(注意:此处所说的“矩形”是可以扩展到高维空间的)。
3. 每一个非叶子结点拥有m至M个孩子结点,除非它是根结点。
4. 对于在非叶子结点上的每一个条目,i是最小的可以在空间上完全覆盖这些条目所代表的店的矩形(同性质2)。
5. 所有叶子结点都位于同一层,因此R树为平衡树。
叶子结点的结构
先来探究一下叶子结点的结构。叶子结点所保存的数据形式为:(I, tuple-identifier)。
其中,tuple-identifier表示的是一个存放于数据库中的tuple,也就是一条记录,它是n维的。I是一个n维空间的矩形,并可以恰好框住这个叶子结点中所有记录代表的n维空间中的点。I=(I0,I1,…,In-1)。其结构如下图所示:

下图描述的就是在二维空间中的叶子结点所要存储的信息。
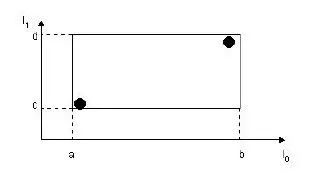
在这张图中,I所代表的就是图中的矩形,其范围是a<=I0<=b,c<=I1<=d。有两个tuple-identifier,在图中即表示为那两个点。这种形式完全可以推广到高维空间。大家简单想想三维空间中的样子就可以了。这样,叶子结点的结构就介绍完了。
非叶子结点
非叶子结点的结构其实与叶子结点非常类似。想象一下B树就知道了,B树的叶子结点存放的是真实存在的数据,而非叶子结点存放的是这些数据的“边界”,或者说也算是一种索引(有疑问的读者可以回顾一下上述第一节中讲解B树的部分)。
同样道理,R树的非叶子结点存放的数据结构为:(I, child-pointer)。
其中,child-pointer是指向孩子结点的指针,I是覆盖所有孩子结点对应矩形的矩形。这边有点拗口,但我想不是很难懂?给张图:

D,E,F,G为孩子结点所对应的矩形。A为能够覆盖这些矩形的更大的矩形。这个A就是这个非叶子结点所对应的矩形。
这时候你应该悟到了吧?无论是叶子结点还是非叶子结点,它们都对应着一个矩形。树形结构上层的结点所对应的矩形能够完全覆盖它的孩子结点所对应的矩形。根结点也唯一对应一个矩形,而这个矩形是可以覆盖所有我们拥有的数据信息在空间中代表的点的。
我个人感觉这张图画的不那么精确,应该是矩形A要恰好覆盖D,E,F,G,而不应该再留出这么多没用的空间了。但为尊重原图的绘制者,特不作修改。
END

今日学习推荐
【人工智能极简入门】
人人都需要学的AI算法思维课
开课时间:2019年4月20日
特惠价99元,三人成团:49元
咨询/报名/组团可添加微信客服
julyedukefu_02
扫描下方二维码
免费试听
☟

长按识别二维码


●什么?互联网人恋爱调查报告,程序员竟成最大赢家?
●金融风控面试十二问
●一次面试让你知道数据结构与算法对前端的重要性
●人工智能人才争抢白热化?学好数学才能C位出道!
●哪些机器学习算法不需要做归一化处理?
●一文详解:什么是B树?
●机器学习中的数学基础(微积分和概率统计)
●34个最优秀好用的Python开源框架
●【实战分享】电影推荐系统项目实战应用
●Python打牢基础,从19个语法开始!
扫描下方二维码 关注:七月在线实验室
后台回复:100 免费领取【机器学习面试100题】
后台回复:干货 免费领取【全体系人工智能学习资料】
后台回复: 领资料 【NLP工程师必备干货资料】
▼更多精彩推荐,请关注我们▼ 把时间交给学习
把时间交给学习

 戳“阅读原文”我们一起进步
戳“阅读原文”我们一起进步
 在看点一下
在看点一下