最困难的事情就是认识自己!个人网站,欢迎访问!
前言:
本篇文章主要是阐述下 联合索引 在 B+Tree 上的实际存储结构。
本文主要讲解的内容有:
- 联合索引在B+树上的存储结构
- 联合索引的查找方式
- 为什么会有最左前缀匹配原则
在分享这篇文章之前,我在网上查了关于MySQL联合索引在B+树上的存储结构这个问题,翻阅了很多博客和技术文章,其中有几篇讲述的与事实相悖。具体如下:很多博客中都是说:联合索引在B+树上的 非叶子节点 中只会存储 联合索引 中的第一个索引字段 的值,联合索引的其余索引字段的值只会出现在 B+树 的 叶子节点 中 。(其实这句话是不对的)
如下图,就是 错误的 联合索引的 B+树 存储结构图:
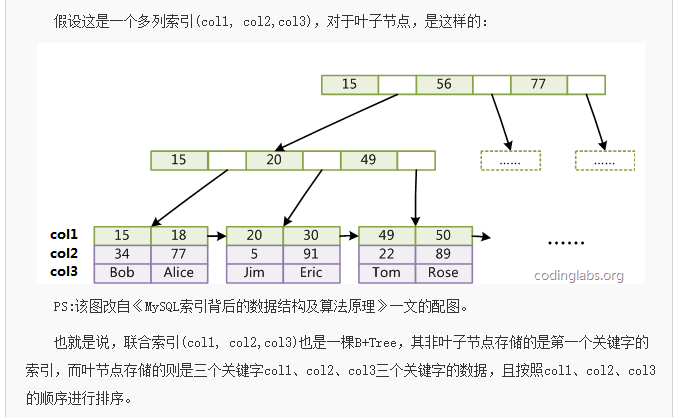
庆幸的是通过不断查询发现有一条是来自思否社区的关于【联合索引 在 B+Tree 上的存储结构?】问答,有答主回答了这个问题,并贴出了一篇文章和一张图以及一句简单的描述。PS:贴出的文章链接已经打不开了。所以在这样的条件下本篇文章就诞生了。
联合索引存储结构:
下面就引用思否社区的这个问答来展开我们今天要讨论的联合索引的存储结构的问题。来自思否的提问,联合索引的存储结构
(https://segmentfault.com/q/10...
有码友回答如下:联合索引 bcd , 在索引树中的样子如下图 , 在比较的过程中 ,先判断 b 再判断 c 然后是 d :
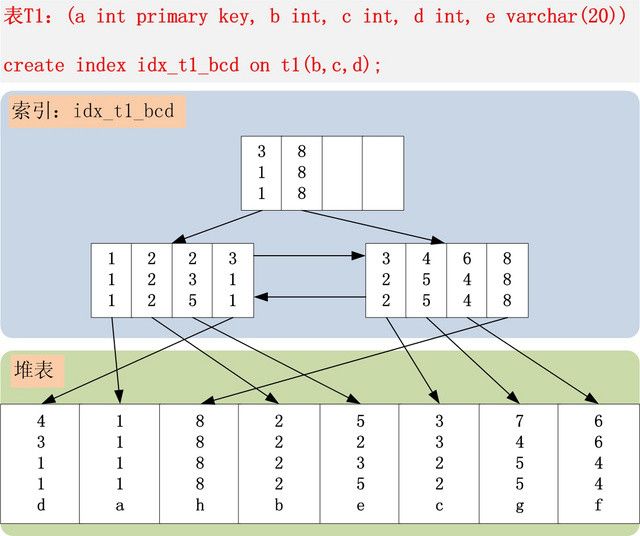
由于回答只有这么一张图一句话,可能会让大家有点看不懂,所以我们就借助前人的肩膀用这个例子来更加细致的讲探寻一下联合索引在B+树上的存储结构吧。
首先,有一个T1表, 然后表T1有字段a,b,c,d,e,其中a是主键,除e为varchar其余为int类型,并创建了一个联合索引idx_t1_bcd(b,c,d),然后b、c、d三列作为联合索引,在B+树上的结构正如上图所示。联合索引的所有索引列都出现在索引数上,并依次比较三列的大小。上图树高只有两层不容易理解,下面是假设的表数据以及我对其联合索引在B+树上的结构图的改进。 PS:基于InnoDB存储引擎。
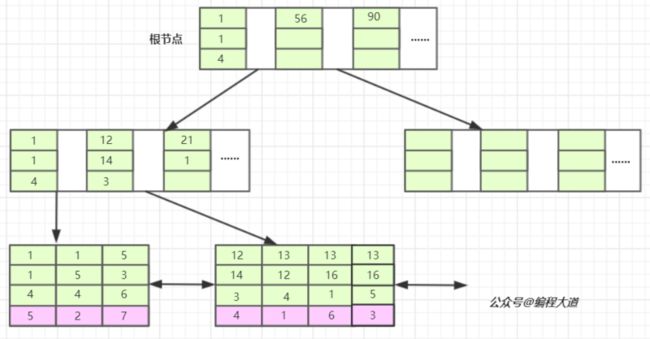
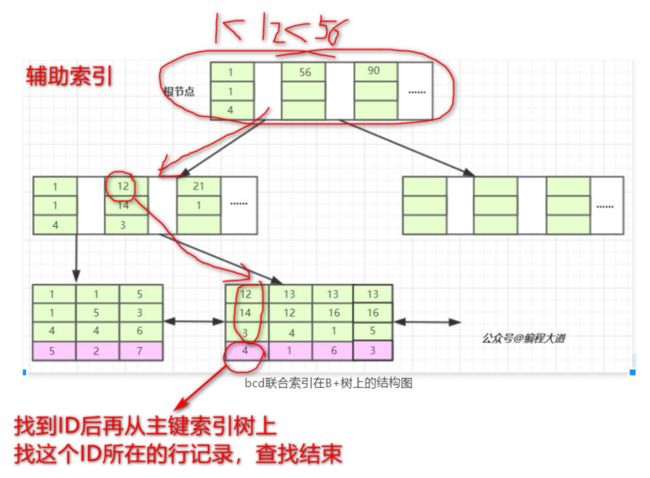
index(b、c、d)联合索引在B+树上的结构图如下:
T1表中的数据如下图:( 上图 B+树 中的数据就来自下图 )
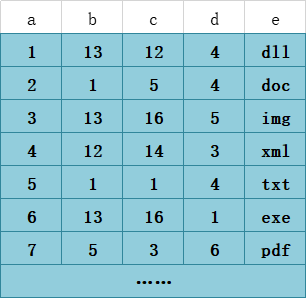
通过这俩图我们心里对联合索引在B+树上的存储结构就有了个大概的认识。下面用我的语言为大家解释一下吧。
我们先看T1表,他的主键暂且我们将它设为整型自增的 ,InnoDB会使用主键索引在B+树维护索引和数据文件,然后我们创建了一个联合索引(b,c,d)也会生成一个索引树,同样是B+树的结构,只不过它的 data部分 存储的是联合索引所在行记录的主键值 (上图叶子节点紫色背景部分) 。为什么是 主键值,而不是 整个行记录呢? 因为这个 联合索引 是个 非聚簇索引 。
好了大致情况都介绍完了。下面我们结合这俩图来解释一下。
对于联合索引来说只不过比单值索引多了几列,而这些索引列全都出现在索引树上。对于联合索引,存储引擎会首先根据第一个索引列排序,如上图我们可以单看第一个索引列,如,1 1 5 12 13…它是单调递增的;如果第一列相等则再根据第二列排序,依次类推就构成了上图的索引树,上图中的1 1 4 ,1 1 5以及13 12 4, 13 16 1, 13 16 5就可以说明这种情况。
联合索引具体查找步骤:
当我们的SQL语言可以应用到索引的时候,比如 select * from T1 where b = 12 and c = 14 and d = 3 ;也就是T1表中a列为4的这条记录。
查找步骤具体如下:
- 存储引擎首先从根节点(一般常驻内存)开始查找,第一个索引的第一个索引列为1,12大于1,第二个索引的第一个索引列为56,12小于56,于是从这俩索引的中间读到下一个节点的磁盘文件地址(此处实际上是存在一个指针的,指向的是下一个节点的磁盘位置)。
- 进行一次磁盘IO,将此节点值加载后内存中,然后根据第一步一样进行判断,发现 数据都是匹配的,然后根据指针将此联合索引值所在的叶子节点也从磁盘中加载后内存,此时又发生了一次磁盘IO,最终根据叶子节点中索引值关联的 主键值 。
- 根据主键值 回表 去主键索引树(聚簇索引)中查询具体的行记录。
联合索引的最左前缀原则:
之所以会有最左前缀匹配原则和联合索引的索引构建方式及存储结构是有关系的。
首先我们创建的idx_t1_bcd(b,c,d)索引,相当于创建了(b)、(b、c)(b、c、d)三个索引,看完下面你就知道为什么相当于创建了三个索引。
我们看,联合索引是首先使用多列索引的第一列构建的索引树,用上面idx_t1_bcd(b,c,d)的例子就是优先使用b列构建,当b列值相等时再以c列排序,若c列的值也相等则以d列排序。我们可以取出索引树的叶子节点看一下。
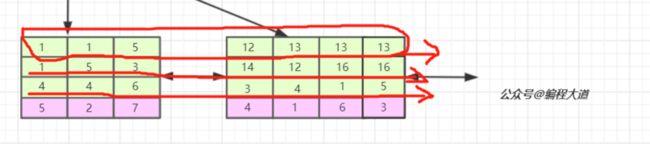
索引的第一列也就是b列可以说是从左到右单调递增的,但我们看c列和d列并没有这个特性,它们只能在b列值相等的情况下这个小范围内递增,如第一叶子节点的第1、2个元素和第二个叶子节点的后三个元素。
由于联合索引是上述那样的索引构建方式及存储结构,所以联合索引只能从多列索引的第一列开始查找。所以如果你的查找条件不包含b列如(c,d)、(c)、(d)是无法应用缓存的,以及跨列也是无法完全用到索引如(b,d),只会用到b列索引。
这就像我们的电话本一样,有名和姓以及电话,名和姓就是联合索引。在姓可以以姓的首字母排序,姓的首字母相同的情况下,再以名的首字母排序。
如:
M
毛 不易 178********
马 化腾 183********
马 云 188********
Z
张 杰 189********
张 靓颖 138********
张 艺兴 176******** 我们知道名和姓是很快就能够从姓的首字母索引定位到姓,然后定位到名,进而找到电话号码,因为所有的姓从上到下按照既定的规则(首字母排序)是有序的,而名是在姓的首字母一定的条件下也是按照名的首字母排序的,但是整体来看,所有的名放在一起是无序的,所以如果只知道名查找起来就比较慢,因为无法用已排好的结构快速查找。
到这里大家是否明白了为啥会有最左前缀匹配原则了吧。
实践:
如下列举一些SQL的索引使用情况:
select * from T1 where b = 12 and c = 14 and d = 3;-- 全值索引匹配 三列都用到
select * from T1 where b = 12 and c = 14 and e = 'xml';-- 应用到两列索引
select * from T1 where b = 12 and e = 'xml';-- 应用到一列索引
select * from T1 where b = 12 and c >= 14 and e = 'xml';-- 应用到一列索引及索引条件下推优化
select * from T1 where b = 12 and d = 3;-- 应用到一列索引 因为不能跨列使用索引 没有c列 连不上
select * from T1 where c = 14 and d = 3;-- 无法应用索引,违背最左匹配原则
后记:
到这里MySQL索引的联合索引的存储结构及查找方式就讲完了,本人能力有限,也是站着前人的肩膀上创作的此文,因为看到搜索引擎的搜索结果前几个技术文章中有存在讲述不清或讲述有误的地方,所以自己才总结出这篇文章分享给大家,如有不对的地方一定要指正哦,谢谢了。
这篇文章断断续续利用工作之余画图加写作用了两三天,主要内容就是上面这些了。不可否认,这篇文章在一定程度上有纸上谈兵之嫌,因为我本人对MySQL的使用属于菜鸟级别,更没有太多数据库调优的经验,在这里高谈阔论实属惭愧。就当是我个人的一篇学习笔记了。
另外,MySQL索引及知识非常广泛,本文只是涉及到其中一部分。如与排序(ORDER BY)相关的索引优化及覆盖索引(Covering index)的话题本文并未涉及,同时除B-Tree索引外MySQL还根据不同引擎支持的哈希索引、全文索引等等本文也并未涉及。如果有机会,希望再对本文未涉及的部分进行补充吧。
❤不要忘记留下你学习的足迹 [点赞 + 收藏 + 评论]嘿嘿ヾ
一切看文章不点赞都是“耍流氓”,嘿嘿ヾ(◍°∇°◍)ノ゙!开个玩笑,动一动你的小手,点赞就完事了,你每个人出一份力量(点赞 + 评论)就会让更多的学习者加入进来!非常感谢! ̄ω ̄=