Hbase2.1.5集群环境搭建
序言
Hbase跟基于Hadoop和Zookeeper. 同时Hbase的版本跟Hadoop的版本密切相关.一定要下载对应的Hadoop版本.此文章只介绍如何搭建Hbase的环境.
启动hbase前先启动Hadoop和Zookeeper.
整体介绍
Hbase的集群拓扑图
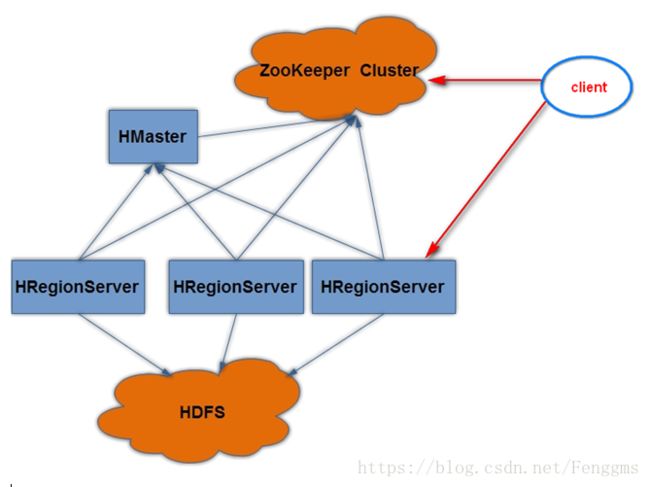
Client
包含访问Hbase的接口,并维护cache来加快对Hbase的访问,比如region的位置信息。
HMaster
Client访问HBase上的数据并不需要master参与(寻址访问zookeeper和region server,数据读写访问region server),master仅仅维护table和region的元数据信息(table的元数据信息保存在zookeeper上),负载很低。(只能保证集群的region的个数进行负载,如果region的大小不同,不能根据数据的大小进行负载)。
- 管理用户对Table表的增、删、改、查操作;
- 管理HRegion服务器的负载均衡,调整HRegion分布;
- 在HRegion分裂后,负责新HRegion的分配;
- 在HRegion服务器停机后,负责失效HRegion服务器上的HRegion迁移。
RegionServer
HRegionServer存取一个子表时,会创建一个HRegion对象,然后对表的每个列族创建一个Store实例,每个Store都会有一个MemStore和0个或多个StoreFile与之对应,每个StoreFile都会对应一个HFile, HFile就是实际的存储文件。因此,一个HRegion有多少个列族就有多少个Store。
一个HRegionServer会有多个HRegion和一个HLog。
- 维护master分配给他的region,处理对这些region的io请求
- Regionserver负责切分在运行过程中变得过大的region
- Region server 服务节点,从 hdfs 上加载 N 个 region 到内存服务。
Region
Region是HBase数据存储和管理的基本单位.Region为物理存储单元,在 hdfs 上保存。
Zookeeper
首先HMaster和RegionServer都需要和Zookeeper交互,因为RegionServer上线了还需要交互,之后Zookeeper知道了告诉HMaster,而下线或断开了Zookeeper知道了也告诉HMaster;同时HMaster还管理RegionServer,HMaster还会在HDFS上写Region数据。
- 通过选举,保证任何时候,集群中只有一个活着的HMaster,HMaster与RegionServers 启动时会向ZooKeeper注册
- 存贮所有Region的寻址入口
- 实时监控Region server的上线和下线信息。并实时通知给HMaster
- 存储HBase的schema和table元数据
- Zookeeper的引入使得HMaster不再是单点故障。
环境搭建
[[email protected]@slave2 ~]$ wget http://mirrors.tuna.tsinghua.edu.cn/apache/hbase/2.1.5/hbase-2.1.5-bin.tar.gz
[[email protected]@slave2 ~]$ tar -zxvf hbase-2.1.5-bin.tar.gz
[[email protected]@slave2 ~]$ cd hbase-2.1.5/conf/
修改hbase-env.sh的配置文件内容如下
#这里路是jdk的路径,不要用系统自带的
export JAVA_HOME=/usr/java/jdk1.8.0_211
#不适用hbase自带的zookeeper
export HBASE_MANAGES_ZK=false
修改hbase-site.xml内容如下:
hbase.rootdir
hdfs://jed/user/hbase
hbase.cluster.distributed
true
hbase.zookeeper.quorum
192.168.2.108:2181,192.168.2.109:2181,192.168.2.110:2181
修改regionservers配置文件,加入RegionServer节点列表
## 默认有一行localhost,删除
192.168.2.108
192.168.2.109
192.168.2.110新建backup-masters文件,并做修改.就是hmaster的备份
# 添加备用hbase-master
192.168.2.109最重要一步,要把 hadoop 的 hdfs-site.xml 和 core-site.xml 放到 /data/hbase-2.1.5/conf 下
把hbase安装目录分发给其他节点
[[email protected]@slave2 ~]$ scp -r hbase-2.1.5 hadoop02:`pwd`
[[email protected]@slave2 ~]$ scp -r hbase-2.1.5 hadoop03:`pwd`
[[email protected]@slave2 ~]$ scp -r hbase-2.1.5 hadoop04:`pwd`在全部节点的环境变量配置文件中加入HBASE_HOME
vi ~/.bashrc
#HBase
export HBASE_HOME=/data/hbase-2.1.5/
export PATH=$PATH:$HBASE_HOME/binHBase 集群对于时间的同步要求的比 HDFS 严格,所以,集群启动之前千万记住要进行 时间同步,要求相差不要超过 30s
启动HBase
保证 ZooKeeper 集群和 HDFS 集群启动正常的情况下启动 HBase 集群 启动命令:start-hbase.sh,在哪台节点上执行此命令,哪个节点就是主节点.
如果哪一台没有启动成功也可以通过命令来手动启动(最好不要这样)
hbase-daemon.sh start master
hbase-daemon.sh start regionserver检验是否启动成功
- 通过jps查看相应的进程
- 访问网页http//ip:16010/master-status
- 使用命令hbase shell 验证
java操作Hbase功能大全
https://blog.icocoro.me/2017/11/02/1711-zhishidian-hbase03/index.html